结合注意力机制的HRNet图像语义分割算法
2023-11-14叶思佳杜韩宇邓金枝
叶思佳,魏 延,杜韩宇,邓金枝
(重庆师范大学计算机与信息科学学院,重庆 401331)
0 引言
语义分割[1-2]是计算机视觉领域中常见的任务之一,让计算机理解图像的信息,根据图像的信息来为每一个像素点进行分类,不同类别信息的像素点用不同的颜色区分开,语义分割本质是一种像素级的空间密集型预测任务。语义分割在地理信息系统[3-4]、无人车驾驶[5-6]、医疗影像分析[7-8]等领域都有着广泛的应用。目前语义分割领域依旧面临许多挑战,如分割精度不够、小尺度目标丢失、分割不连续等问题。
传统的语义分割方法通常是根据图像自身的低阶视觉信息来提取特征图,这种提取的方式特征图辨别性低从而影响分割精度。传统的语义分割算法主要包括阈值分割[9]、边缘分割[10]、聚类分割[11-12]等。目前语义分割领域中主流的是基于深度学习的方法。和传统方法相比,基于深度学习的图像语义分割能更好地提取图像的特征。基于深度学习的图像语义分割网络结构主要包括3 种,即基于编解码的网络结构、基于空间金字塔的网络结构和基于多分支的网络结构。在编解码网络结构中,通过编码器取得低分辨率图像,得到图像的抽象的语义信息,通过解码器取得高分辨率图像,得到像素级预测结果。典型编码器-解码器结构的网络主要有全卷积神经网络FCN[13]、U 型网络U-Net[14]以及SegNet[15]网络。空间金字塔网络结构就是在图片特征提取过程当中形成多个不同分辨率的特征图,再将不同分辨率的特征图进行融合,提高模型表征特征的能力。空间金字塔结构的实现目前主要分为2 种:一种是通过改变各分支的输入分辨率来捕获多尺度语义信息,如PSPNet[16]、PANet[17];另外一种是改变各分支卷积层的方式来提取多尺度语义信息,如DeepLab[18-21]系列。以上2 种网络结构在进行特征提取时都会经过一系列的下采样过程,大量的下采样和池化操作会使特征图由原先的输入图像大小(H,W)慢慢变成(H/16,W/16)甚至更小,这就会丢失掉原有分辨率的空间位置信息,导致空间和细节信息丢失。这个问题对于图像语义分割这种基于像素点的分类任务来说影响很大,因为特征图难以单独学习到下采样过程中丢失了的像素信息。基于多分支的网络结构能缓解下采样过程中像素信息丢失这一问题。多分支网络结构是将输入图像分别送入多个分支,每个分支具有不同的输出分辨率,由于网络过程中全程保持了图片分辨率比较高的分支,即保留了图片的空间信息和细节信息。HRNet[22]是一个典型的多分支网络结构,网络全程保持了较高分辨率的特征图,这也让其在像素级分类领域中有着更好的效果。
为了改善目前分割算法中小目标丢失、精度不够等问题,本文基于HRNet 网络模型进行改进。首先,针对不同分辨率的特征图,本文引入不同的注意力机制[23-25](Attention Mechanism),得到更多有效的图像特征信息。其次,本文通过使用深度可分离卷积[26]的方式减少参数、加速模型的训练。同时,本文提出用多级上采样机制替代原模型的上采样方式,得到更好的融合结果,提高了分割的准确度。
1 相关研究
1.1 HRNet网络模型
HRNet 是中科大和微软研究院提出的针对人体姿态检测的一个网络模型。不同于特征提取过程中常会用的下采样再上采样的方法,HRNet让网络在学习过程中全程保持了一个高分辨率,HRNet的结构如图1 所示。从图1 中可以看出HRNet 网络的2 个关键特点:1)高分辨率和低分辨率并行连接,同步推进;2)高低分辨率图之间不断地交换信息。高分辨率图的存在使得空间上更加精准,低分辨率图的存在使得语义上更充分。该网络由4 个阶段组成,通过反复的交换平行流中的信息来进行多分辨率的融合。HRNet是在低分辨率的帮助下,多次融合高分辨率。
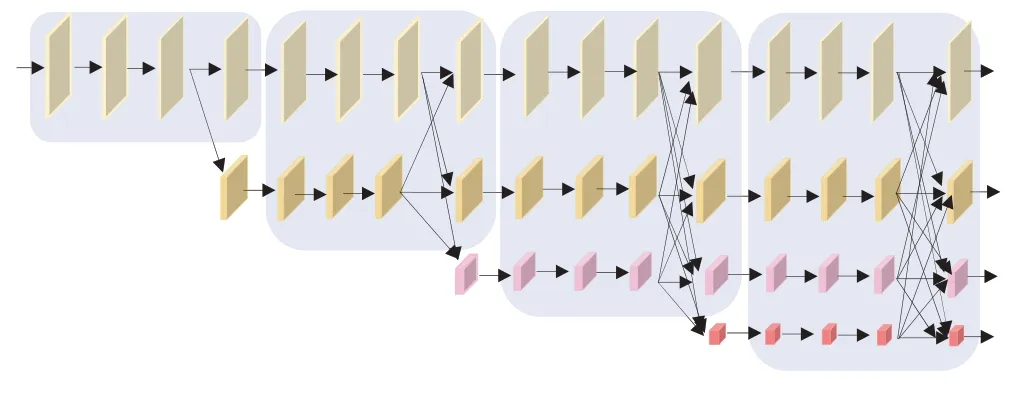
图1 HRNet模型结构
1.2 注意力机制
2014 年注意力机制提出后在深度学习中得到了广泛的使用。注意力机制其本身是符合人类的感知机制的,人们在观察一个新事物的时候,会自然地对该事物重要的区域给予更多的关注,再将其他区域的信息进行一个整合从而得到一个整体的印象。在深度学习中,模型的参数越多表示其存储的信息越丰富,通常来说模型的效果也就越好,但会占用更多的内存空间,可能会使得模型难以训练。所以本文引入注意力机制,这样模型会在大量的信息中找出对于当前这个任务更为关键的信息并且给予这些信息更高的权重,减少无关信息的权重,有利于提高处理任务的速度,加快模型的训练。普通模式的注意力机制总的可以分为2 种,软性注意力和硬性注意力。由于硬性注意力机制选择信息的方式不能进行求导,无法在深度学习中利用反向传播来进行训练,所以在深度学习中为了能够训练模型一般使用软性注意力。软性注意力是像素级的,目的是找出对于当前任务重要的像素点并给其赋予更高的权重。
1.3 深度可分离卷积
对于常规卷积来说,原始图像大小是12×12,有3个通道,即shape 为12×12×3,经过5×5 卷积核,输入图像有3 个通道,所以卷积核也应该有3 个通道。每经过一个这样的卷积核会产生一个通道的特征图,假设最后需要三通道的特征图,则需要3 个这样的卷积核,这时普通卷积的参数量是5×5×3×3=225,如图2(a)所示。与常规卷积不同,深度可分离卷积分为2步,首先进行通道分离,然后再进行通道的上升。用3 个5×5×1 的卷积对3 个通道分别做卷积使其图像的通道分离,再用1×1×3 的卷积对3 个通道再次进行卷积就得到了一个8×8×1的特征图,最后的特征图是三通道的,所以需要3个这样的卷积核,此时参数量是5×5×3+×1×1×3×3=84,如图2(b)所示。深度可分离卷积的使用减少了模型的参数量,缩短了模型训练的时间。
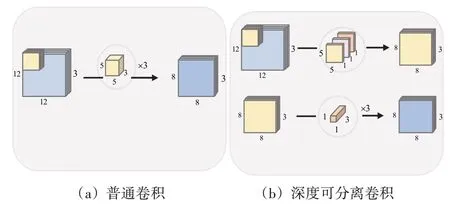
图2 普通卷积和深度可分离卷积
2 结合注意力机制的图像语义分割算法
2.1 总体框架
本文在HRNet[22]网络模型的基础上,使用深度可分离卷积,减少模型的参数,提高训练的速度。其次对经过HRNet 所产生的4 个不同分辨率的特征图都让其经过了一个空间注意力机制(Spatial Attention mechanism,SA)。SA 的使用让模型在进行特征提取时对图像空间尺度上重要的特征给予更多的关注。在上采样阶段,受多尺度认知机制的启发,本文提出一种多级上采样机制的方法,从最低分辨率特征图开始,两两进行融合,直到融合到最高分辨率特征图为止。并且在上采样过程当中,使用了BiCubic 插值算法,该算法能生成边缘更平滑的特征图,有利于后续提高分割的精确度。本文将上采样后得到的特征图经过一个高效的通道注意力机制(Efficient Channel Attention,ECA)。ECA 的使用让模型在进行特征提取时对重要的通道信息赋予更高的权重。本文改进的网络模型如图3所示。

图3 本文改进的网络模型
2.2 结合注意力机制的HRNet算法
2.2.1 SA空间注意力
在神经网络中,通常来说浅层网络的图像特征会存在图像的背景特征信息,若这时直接将图像特征进行上采样,会影响图像分割的效果。针对这一问题,本文采用空间注意力机制,空间注意力是在图像的空间尺度上关注哪里的特征是有意义的,对空间上重要的图像特征给予更高的权重。如图4 所示,首先对特征图在通道上进行压缩,特征图的长度和宽度不变,通道数压缩为1,再让其分别经过最大池化和平均池化,将这2 个池化结果拼接在一起后让其经过卷积层和激活函数。

图4 空间注意力机制
式中,和大小为1 ×H×W,σ表示sigmoid 函数,f7×7表示一个大小为7×7 的卷积运算。最后将Ms与输入的特征F'相乘,将该权重应用到原来的每个特征空间上,便得到经过空间注意力机制的新特征。
2.2.2 ECA通道注意力
对于特征图来说,有2 个方面的特征表示,一个是图像的空间尺度,另一个是图像的通道尺度。图像特征的每一个通道都代表着一个专门的检测器,通道注意力机制会对当前任务重要的通道分配更高的权重,简单并且有效。不同分辨率特征图融合之后,本文让其通过一个ECA 通道注意力机制,其结构如图5所示。首先在空间尺度上进行特征压缩,平均池化后空间大小变成1×1,特征图的通道数不变,然后再让其经过一个自适应大小为5×5 的卷积和一个激活函数,就可以得到通道维度上注意力的权重MC。
式中,Fsavg大小为1 × 1 ×H,σ表示sigmoid 函数,k代表计算出的自适应卷积核的大小,γ和b分别设为2和1,f5×5表示一个大小为5×5的卷积运算。最后将得到的权重MC与输入的特征图F相乘,便得到经过通道注意力机制的新特征。
2.2.3 多级上采样机制
上采样是语义分割领域中一个重要的环节,原HRNet 使用的是bilinear 算法进行上采样,该算法会使特征图的高频分量受损,这会影响特征图像轮廓的清晰度,所以本文使用BiCubic 双三次插值算法来进行上采样。原HRNet 网络中不同分辨率的特征图进行融合的方式是将低分辨率的图像直接上采样到最高的分辨率,然后再进行融合。但这种简单、直接的融合方式会影响特征图的质量,所以本文提出一种多级上采样机制的方法,按照特征图分辨率从低到高的顺序,两两依次进行融合,如图6 所示。这种更加平滑的上采样方式改善了融合结果,提高了特征图质量,并且可以产生更加清晰的特征图边缘,有利于提高分割精确度。

图6 多级上采样机制
3 实验结果与分析
3.1 数据集及实验参数配置
本文实验采用的是PASCAL VOC2012 增强版数据集,由PASCAL VOC2012[27]数据集和SBD 数据集合并而成,包括人、飞机、船、摩托车、沙发等20 个类别,加上1个背景类别,总共21个类别,不同类别的像素点用不同的颜色区分开。该数据集数据量更多,是语义分割领域中常用的数据集之一,总共有13487 张图片,用10582 张图片进行模型的训练,1449 张图片进行模型的验证。实验使用Pytorch 深度学习框架,操作系统为Windows 10,基于英特尔i9-10920X CPU,NVIDIA GeForce RTX 3080Ti 12 GB 显卡。本文训练模型时将输入图片的大小设置为480×480,batchsize设置为12,epoch设置为300。
3.2 实验评价指标
平均交并比(mean Intersection over Union,mIoU)是语义分割算法中最常用的一个评价指标,本文采用mIoU 来评价模型分割效果的好坏。mIoU 是计算分割结果图和输入图像标签图的重合程度,重合程度越高,mIoU 的值就越趋近于1,表示模型的分割效果越准确。
式中,n指的是数据集中的类别数,Pii表示实际为i类预测为i类的像素数量,Pij表示实际为i类但预测为j类的像素数量,Pji表示实际为j类但预测为i类的像素数量。
3.3 实验结果分析
为了验证本文改进后的模型的有效性,在相同的实验环境下对原HRNet 模型和本文改进后的模型在验证集进行测试,其mIoU值对比如图7所示。图7中本文模型的mIoU 值达到了80.87%,分割精度比原模型提升了1.54个百分点,说明本文所提出的改进是有效的。
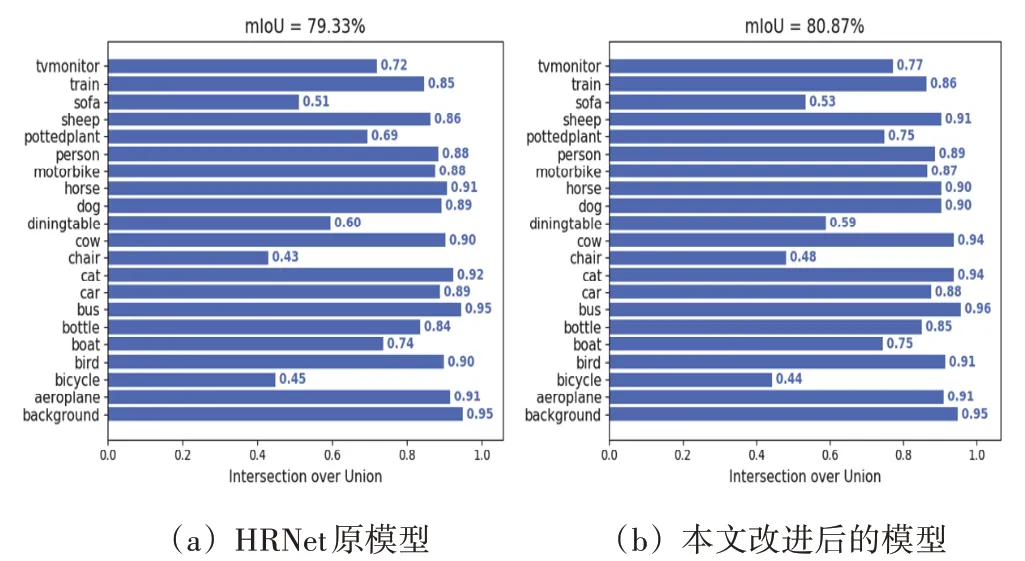
图7 HRNet原模型和本文模型的对比
为了验证SA空间注意力、ECA通道注意力和多级上采样机制的有效性,本文设置了消融实验,其结果如表1所示。从表1中可以看出,用多级上采样机制这种更平滑的方式对不同分辨率的特征进行融合,可减少特征图质量的损失,mIoU值比原模型增加了0.43个百分点。通过使用SA、ECA,特征图在空间域和通道域获得了更有效的语义信息,降低了图像噪音对分割效果的影响,mIoU值比原模型增加了1.12个百分点。
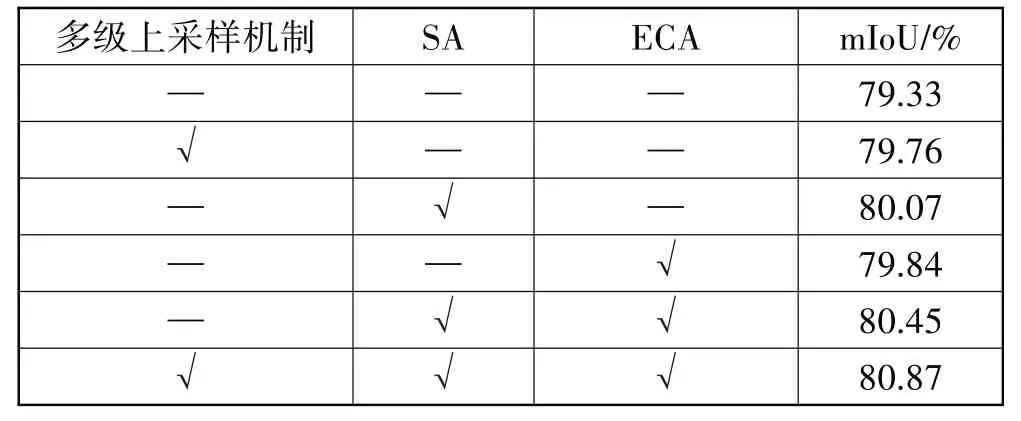
表1 不同模块性能结果
本文使用深度可分离卷积对HRNet 的主干网络进行优化,减少了模型总参数量和总计算量,图像每秒传输帧数(Frame Per Second,FPS)也有了一定的提升。表2是模型性能的对比结果。
为了验证本文模型的先进性,所以除了和原模型相比,本文还将改进后的模型与目前主流的分割模型,如PSPNet[16]、DeepLab[18-21]系列进行了比较,其对比结果如表3 所示。从表3 中可以看出,PSPNet 的mIoU 值为78.56%,DeepLabv3 的mIoU 值为77.21%,DeepLabv3+融入了编解码机制,mIoU达到了79.15%。本文方法全程保持了高分辨率的特征图,有效地保留了图像的空间信息,能更好地捕获小尺寸目标。引入注意力机制对图像空间域和通道域的重要信息进行了有效提取。使用多级上采样机制让4 个不同分辨率的特征图得到了更好的融合。本文算法的分割精度比PSPNet 网络模型的高了2.31 个百分点,比Deep-Labv3+网络模型高了1.72个百分点。
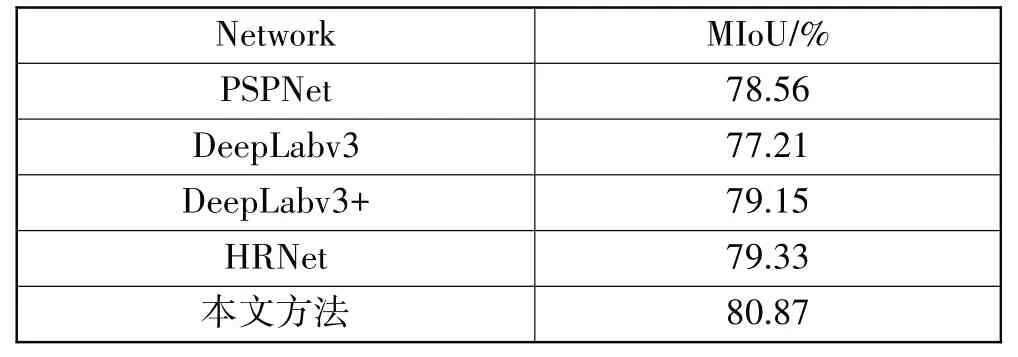
表3 不同网络模型的测试结果
本文改进的模型和原模型分割结果的对比如图8所示。图8(a)是模型的输入图像,图8(b)为输入图像对应的标签图,图8(c)是输入图像在HRNet 网络上的分割结果,图8(d)为输入图像在本文改进后的模型上的分割结果。从图8 中可以看出本文方法对人、自行车、瓶子等类别能够进行更加精准的分割,对于小尺寸目标能进行更加有效的识别。

图8 分割结果对比图
4 结束语
为了能够提取更有效的图像特征,本文在HRNet的基础上融入了注意力机制,在通道和空间维度上提取更加有效的特征图,使用了深度可分离卷积,在不影响分割精度的情况下减少了模型的参数,并且使用多级上采样机制减少了图像质量的损失。实验结果表明,本文方法在PASCAL VOC2012 增强版数据集上mIoU 值达到了80.87%。但网络全程保持了高分辨率使模型参数量和计算复杂度较高,所以如何进一步降低模型参数量并且保持算法的分割精度是后续研究的关键。
