基于轻量化YOLOv5的安全帽检测
2023-11-14李延满王必恒赵羚焱
李延满,王必恒,赵羚焱
(1.国电南瑞科技股份有限公司,江苏 南京 210000;2.南京信息工程大学计算机学院,江苏 南京 210044)
0 引 言
随着物联网、人工智能等技术的飞速发展,配电网运维施工安全监控逐步走向智能化[1]。它可以监控设备故障、违规操作、非法闯入以及火灾隐患等,极大降低了劳动密集程度,并有效防止人身事故的发生。安全帽检测是常规检查项目,与工人的安全息息相关。
传统的安全帽检测方法主要依赖于多特征融合,通过图像处理技术获取肤色、头部以及面部等信息,然后进行相应的检测。例如,Waranusast 等人[2]提出了一种基于K 近邻的摩托车头盔自动检测系统。Li等人[3]应用霍夫变换确定安全帽的形状,并利用相应的直方图训练支持向量机,进而进行检测。传统的安全帽检测方法往往不考虑复杂的背景环境,存在大量误检和漏检的问题,对中、小物体敏感,导致较高的误报率,同时速度较慢,很难做到实时检测[4]。
近年来,深度学习在目标检测领域取得了突破性进展,使目标检测的精确度和效率得到了较大提升。
文献[5]在Faster R-CNN 基础上进行改进,将在线挖掘与多部分检测相结合,识别工人是否佩戴安全帽。张业宝等人[6]提出了一种基于改进SSD 的安全帽佩戴检测方法,通过综合不同卷积层的特征图,在多个特征图上生成多个候选框,提升对小目标的检测效果。这2 种方法都属于双阶段的目标检测方法,识别效果好,但是速度慢,不适于视频处理。马小陆等人[7]通过减小模型、改进分类损失、输出端引入跳跃连接等方法,改进YOLOv3 算法,增强对安全帽佩戴中小目标的检测。Filatov 等人[8]则在YOLOv4 基础上,将SqueezeDet 和MobileNets 组合,显著提升安全帽检测算法的精确度。Li 等人[9]在YOLOv5 基础上,提出一种分层正样本选择机制,提高模型的拟合度。文献[10-11]通过引入注意力机制和多级特征提高模型的识别率。以上算法均基于视频进行实时安全帽检测,但对于嵌入式系统来说,过于复杂,时间过长。在Jestson Xavier NX 设备上,文献[12]提出外接圆半径(Circumcircle Radius Difference,CRD)损失函数和轻量化的特征融合层,提高了模型的处理速度,但是模型的误报率较高。
常用深度学习模型包含大量的参数设置和计算量,存在占用网络带宽、延迟高、实时性差等问题,不适于高速率、低成本的移动设备、微型计算机以及嵌入式应用场景。因此,本文基于海思Hi3559A的嵌入式平台,对YOLOv5 算法进行轻量化改进,提出SNAM-YOLOv5 模型,进行配电网运维施工安全的智能监控。
1 基于深度学习的目标检测算法
当前,基于深度学习的目标检测算法是主流算法,分为双阶段和单阶段。通常,双阶段检测方法准确度较高,单阶段检测方法速度更快。
双阶段检测算法分为2 个阶段,首先产生候选区域,然后对候选区域分类。典型算法主要有RCNN[13]、SPP-Net[14]、Fast R-CNN[15]、Faster RCNN[16]、FPN[17]、R-FCN[18]等。其中,Faster R-CNN是其中比较经典的算法,应用RPN 网络进行候选区域的提取,以此用来代替之前的选择性搜索,将候选框提取合并到深度网络中,从而使检测速度大大提高。RPN 网络的特点在于通过滑动窗口的方式实现候选框的提取,用于目标分类和边框回归。该算法由2 个模块组成,包括产生区域推荐的RPN 和使用推荐区域的Fast R-CNN检测器。
单阶段目标检测算法则将2 个步骤合二为一,在特征图上进行密集抽样,产生大量先验框(Prior Box),然后进行分类和回归。常见的单阶段目标检测算法包括YOLO[19]、SSD[20]、RetinaNet[21]等。YOLO系列算法借鉴了GoogLeNet[22]分类网络结构,包括卷积层和全连接层。其中,卷积层用来提取图像特征,全连接层用来预测图像位置和类别概率值。YOLOv5[23]于2020 年6 月提出,目前该模型实现了速度和准确度的平衡,并得到广泛应用。
基于YOLOv5 的网络模型包含大量的参数设置和计算量,不适于嵌入式应用场景。一些轻量级的网络模型相继提出,例如MobileNet[24]、ShuffleNet[25]、GhostNet[26]等。这些模型的运行速度快,占用内存小,但是检测性能相对较低。基于此,本文借鉴ShuffleNet 模型,对YOLOv5 进行轻量化改进,应用于海思Hi3559A 的嵌入式平台,并进行配电网运维施工安全的智能监控。
2 SNAM-YOLOv5模型
YOLOv5 的速度和检测率性能俱佳,但是在小目标和遮挡目标识别方面性能有所下降,体量对于嵌入式应用较大。因此,本文拟从3 个方面对YOLOv5 进行改进,提出SNAM-YOLOv5(ShuffleNet and Attention Mechanism-You Only Look Once version 5)模型。具体如下:1)Backbone 部分融合轻量型ShuffleNet 结构,Neck 部分在FPN 模块增加Attention 机制;2)应用Hard-swish 激活函数和CRD 损失函数;3)采用改进K-means算法聚类先验框。
2.1 轻量化改进的YOLOv5结构
YOLOv5 网络结构中包含Input、Backbone、Neck和Prediction 这4 个部分,这里给出YOLOv5 的基本结构,如图1 所示。其中Backbone 部分是特征提取,Neck部分是特征融合。
ShuffleNet 是一种针对移动设备而设计的轻量化网络,结合深度可分离卷积(Depthwise Separable Convolution,DW Conv)、通道划分(Channel Split)、通道混合(Channel Shuffle)等操作来提升网络计算效率,减小模型的计算复杂度和参数数量,从而降低内存占用率。对于YOLOv5 Backbone 中的CSP1,参考文献[26]结合ShuffleNet 中的结构进行改进,得到IS Block(Improved ShuffleNet Block)。这里,在IS Block 中还融合了GhostNet 中的Ghost模块,可以通过少量参数来产生更多有效特征,弥补ShuffleNet 融合特征的丢失[27]。
同时,结合DW Conv 对图1 中的CBL(Convn-BN-LeakyReLU)模块进行改进。DW Conv 最早在MobileNet 中提出,在ShuffleNet 中也采用,可以有效降低计算量并保持一定的性能。结合2.2 节中的Hard-swish 函数,将YOLOv5 中的部分CBL 改为DBH(DW Conv-BN-Hard-swish)模块,其他CBL 改为CBH(Convn-BN-Hard-swish)。
在目标检测中,为确保高分辨率输入特征接收完整,通常采取的累积卷层操作会增加网络结构的复杂度。因此,在不堆叠网络结构的前提下,在FPN 模块的基础上添加2 个模块:CEM(上下文抽取模块)和AM(注意力引导模块),即AC-FPN[28]。CEM 模块从多个感受野中探索大量上下文信息,AM 模块通过注意力机制来自适应提取显著对象周围的有用信息,其由2 个子模块构成,即上下文注意模块(CXAM)和内容注意模块(CNAM)。
改进后的轻量型SNAM-YOLOv5 模型如图2 所示,红框为本模型中的改进部分。

图2 SNAM-YOLOv5模型结构
2.2 激活函数和损失函数
YOLOv5 和ShuffleNet 中使用的激活函数均为Leakly ReLU[21]。它是一个单调的线性函数,其差为零,所以该函数不能保持负值,因此大多数神经元不能更新。为了解决该问题,Ramachandran 等用swish函数代替Leakly ReLU,然而,swish 函数的计算量较大。在文献[22]中首次采用了Hard-swish。该函数是非单调和平滑的。非单调性有助于保持一个小的负值,使梯度网络稳定,同时平滑函数也具有良好的泛化能力,并且,与swish 相比计算量较小。Hardswish函数可以表示如下:
这里,将ReLU6 的上限设为6。Hard-swish 函数可以使边界值更准确,这样有利于网络对小目标和被遮挡物体的检测。
在YOLO 系列算法中采用的损失函数有IoU、GIoU、CIoU 和DIoU。 YOLOv5 原算法中采用GIoU_Loss做边界框的的损失函数。这些损失函数具有尺度不变性、非负性和对称性等优点,但是在某些情况下会出现梯度消失的情况。这里,采用文献[11]中提出的CRD边界框回归损失函数,其公式如下:
其中,LossCCAR和LossRD的定义分别如下:
在公式(3)中,S(·)代表矩形框外接圆的面积计算式,B代表预测框外接圆,C代表目标框和预测框之间的最小外接矩形的外接圆。在公式(4)中,rA和rB分别表示目标框外接圆和预测框外接圆的半径。
可以看出,CRD 损失函数包括外接圆面积比损失函数LossCCAR和半径差损失函数LossRD。CCAR 损失函数用于指导预测框的回归方向,RD 损失函数则用于增强预测框与目标框的大小和形状相似性。
在目标检测的后处理过程中,针对很多目标框的筛选,通常需要NMS 非极大值抑制操作。YOLOv4在DIoU 的基础上采用NMS 的方式,而YOLOv5 中则采用加权NMS 的方式。DIoU_NMS 方式对于遮挡重叠物体的识别具有一定的改进作用。本文采用DIoUNMS进行后期处理。
2.3 改进K-means聚类算法
K-means 算法是聚类分析中使用最广泛的算法之一,是基于相似性的无监督算法,目标是将数据集划分为若干个簇,使得簇内的数据点相似度尽可能大,簇间的数据点相似度尽可能小。以各个样本与所在簇质心的均值误差平方和作为聚类效果的评价标准。假设簇划分为(C1,C2,…,CK),则最小化误差平方和可表示为:
其中,ui是簇Ci的均值向量,也称为质心,质心是对聚类中所有点的位置求平均值得到的点。其表达式为:
传统的聚类方法是使用欧氏距离来衡量差异,其计算表达式为:
本文希望在安全帽数据集上聚类提取先验框的尺度信息,以寻找尽可能匹配样本的边框信息,提高边界框的检出率。标准的K-means 算法可以直接聚类先验框的宽和高,产生K个宽、高组合的锚框,但尺寸比较大时,其误差也更大。因此引入IoU[29]使得误差和先验框的大小无关,距离度量表示为:
其中,c表示聚类时被选作中心的边框,b表示中心之外的其他边框。IoU 越大则距离越近聚类效果越好。改进K-means算法过程如下:
步骤1初始化K个聚类中心(从原始数据集中随机选择K个),然后计算所有的先验框到簇集中心的距离,把先验框划分至距离最近的聚类中心所在簇集,并求距离和J1,跳到步骤2。
步骤2根据所得簇集中位数作为新的聚类中心;同时计算新的距离和J2,跳到步骤3。
步骤3计算△J,判断△J是否小于阈值或循环次数是否大于设定值T,若满足条件,跳出循环,结束聚类;否则跳到步骤4。
步骤4根据所得簇集,得到新的聚类中心;同时计算新的距离和J1。
本文通过改进K-means 算法聚类边界框得到9个先验框,能很好地适应不同尺寸的安全帽,加速自适应anchor重计算,有效降低误检率。
3 实 验
3.1 基于海思Hi3559A的视频监控系统
基于海思Hi3559A 的配电网智能视频监控系统由Hi3559A、摄像头、通信模块、报警模块、SD 卡等部件构成,如图3所示。
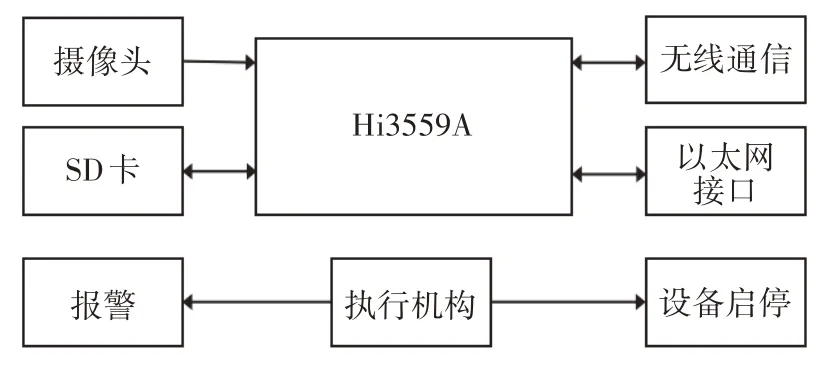
图3 基于Hi3559A的配电网运维施工安全智能监控系统结构图
配电网视频监控终端通过摄像头进行图像数据的采集,然后部署在Hi3559A 中的SNAM-YOLOv5 对监控图像进行分析,当出现设备故障、火灾隐患、违规操作(如未佩戴安全帽)等,立即通过执行机构对声光报警设备发出警报,作出后续处理。例如关停相关故障设备,将有关报警视频片段保存到SD 卡中。该过程可以直接在本地实时处理,只需将相关视频发送到配电网视频监控中心,留待工作人员进行处理。因此极大降低了数据传输量,并改善了配电网运维施工安全智能系统的实时处理速度。
3.2 数据集构建
为适应配电工程施工环境下的安全帽检测,本文自制一个相应的数据集,包括数据采集、数据清洗和数据标注3个步骤。
该数据集主要来源于一些配电工程施工场地的监控视频以及网络,经过数据清洗之后,包含佩戴安全帽和未佩戴安全帽2 种类型的图像。同时,采集的数据注意多样性以及泛化能力,包括不同的光照条件、分辨率、尺寸、颜色和背景等,并添加多组干扰图片,如警帽、棒球帽、草帽等,具体如图4所示。


图4 安全帽样本图像实例
之后对数据进行标签标注,格式为PASCAL VOC[30]。通过上述方法得到的数据集,包含较为复杂的工地背景。数据集共有10885 张图片,图片分辨率为640×640,按照8:2 的比例划分为训练集和测试集。测试集同时包括13个配电网监控视频。
3.3 实验设置
本文实验中的模型搭建、训练及测试均在Pytorch 框架下完成,使用CUDA11.1 并行计算架构,同时集成cu-DNN 加速库。系统为Ubuntu16.04,Python 3.7,显卡为RTX3090。 训练后的SNAMYOLOv5 模型在基于海思Hi3559A 开发板的配电网运维施工安全智能监控系统中进行实时检测。
在SNAM-YOLOv5 模型训练中,训练批次为16,初始学习率为0.003,权重衰减系数设置为0.0001,batchsize 大小为32,迭代次数为300 次。图5 给出了SNAM-YOLOv5 模型的收敛情况,可以看到在0 到240 次时损失函数值急剧下降,在240 到300 次时损失值缓慢下降,在经过300 次迭代后,损失值在0.015附近趋于稳定,模型达到最优状态。
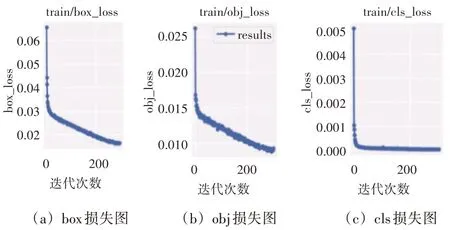
图5 SNAM-YOLOv5模型的收敛情况
3.4 实验结果分析
本文使用召回率(Recall,R)、误报率、平均准确度(Average Precision,AP)和均值平均精度(Mean Average Precision,MAP)对安全帽检测模型性能进行评估。在相同的配置条件下,与同类算法进行对比实验。这些算法包括双阶段的Faster R-CNN 和SSD、YOLO 系列算法(YOLOv3、YOLOv4、YOLOv5),以及在YOLOv5 中特征提取部分由ShuffleNet 替代的YOLOv5-ShuffleNet 和类似的YOLOv5-GhostNet 模型。这里,ShuffleNet 是指ShuffleNetV2。所有算法均在基于Hi3559A 的配电网运维施工安全智能监控系统中运行,相关数据对比见表1。其中,AP50 为IoU 阈值取0.5 时对应的AP 值,FPS 表示帧率,是检测模型每秒处理的帧数。同时给出推理时间和模型的大小。
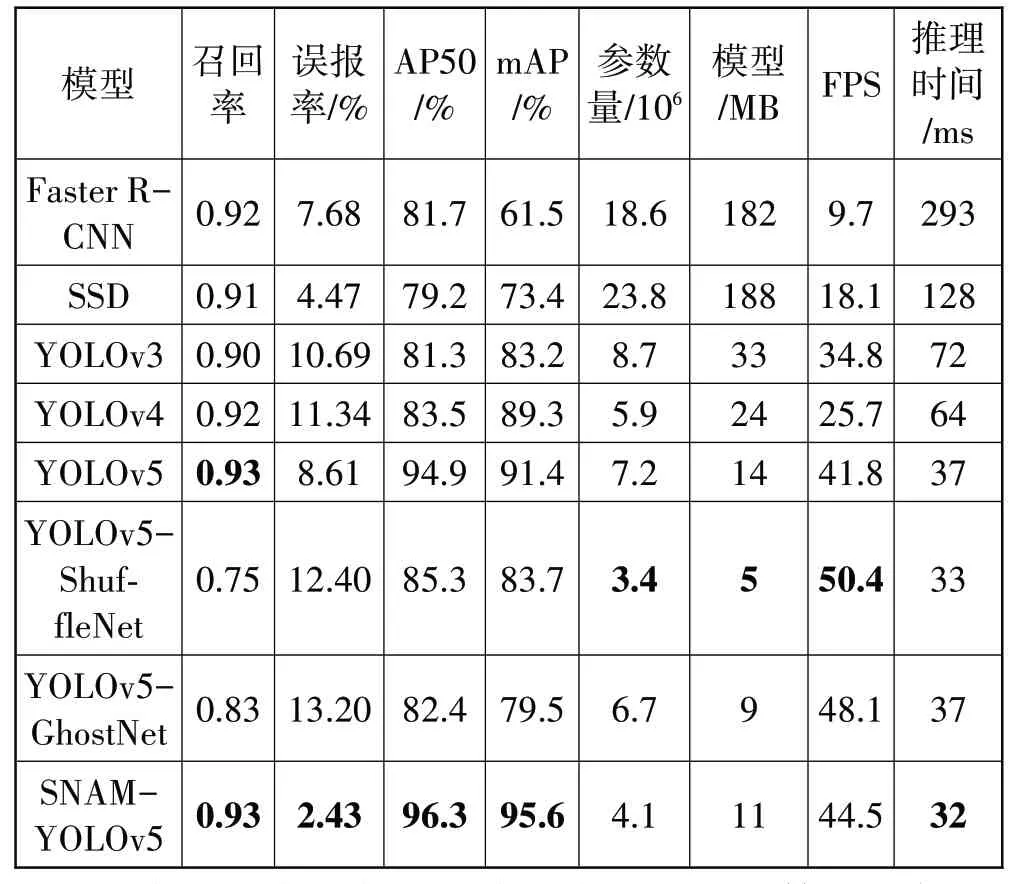
表1 SNAM-YOLOv5模型检测结果对比
根据表1 实验结果可知,本文提出的算法能够有效提高对安全帽以及未佩戴安全帽的施工人员的检测精度。本文算法对佩戴安全帽的施工人员检测AP为96.3%,mAP 达到95.6%,与YOLOv3、YOLOv4 以及原始YOLOv5相比,在AP50和mAP上均有一定提升。同时,SNAM-YOLOv5 模型在参数数量和模型上,是YOLO系列原算法中最小的,虽然大于YOLOv5-ShuffleNe 和YOLOv5-GhostNet,但是识别性能有较大提升。综合而言,本文所提SNAM-YOLOv5 模型,具有较好的性能和实时性,适用于嵌入式应用场景。
此外,为了更加直观地看出不同算法之间的检测差距,本文另外采集了300 张配电运维工程施工中的作业现场图片作为测试集,例如小目标、遮挡等。因为该测试集数量较小,结果不具有普适性,因此没有进行如表1 的检测结果对比,而只是对图像检测结果进行分析。
在这个测试集上使用YOLOv5和SNAM-YOLOv5进行检测,部分测试结果如图6 所示,其中图中佩戴安全帽的施工作业人员上方出现“hat”字样。图6(a)为不同尺寸目标的检测,近景的目标尺寸较大,远景的目标尺寸较小,YOLOv5 漏检了远景下的小目标;图6(b)为远距离施工场景下的小目标检测,对比可知,YOLOv5 原模型对佩戴安全帽的施工作业人员有出现漏检情况,而改进模型检测效果较好;图6(c)为钢筋遮挡施工场景的检测,由于钢筋的遮挡,YOLOv5对施工人员出现了漏检,而本文提出的算法则全部检测出来。由上述配电工程施工场景下的检测比较可知,SNAM-YOLOv5 在配电复杂作业环境下对安全帽检测效果较好。

图6 YOLOv5和SNAM-YOLOv5改进算法检测结果对比
4 结束语
在配电网运维施工安全智能监控系统中,采用基于海思Hi3559A 的轻量化的YOLOv5 模型进行实时监控并报警,可以改进传统监控系统中深度学习模型参数量大、速度慢、数据量传输多等不足。本文提出SNAM-YOLOv5模型,结合ShuffleNet思想和Attention机制,并对激活函数和损失函数进行了改进,同时应用K-means算法进行锚框聚类,令其更适于嵌入式开发平台,具有较好的泛化性。同时对小目标和遮挡情况的安全帽检测,性能良好。
由于SNAM-YOLOv5 模型有着较好的检测速度和精度,下一步可以将配电网监控视频中的时序信息加入,进一步提高模型的检测性能和泛化能力。
