基于多模态特征融合的抑郁症识别
2023-11-14谷明轩范冰冰
谷明轩,范冰冰
(华南师范大学计算机学院,广东 广州 510631)
0 引 言
抑郁症是一种常见的精神疾病,根据世界卫生组织(WHO)的不完全统计,全球约有3.4 亿人患有不同程度的抑郁症。据中国的统计数据显示,超过3000万中国公民患有抑郁症[1]。近年来,抑郁症患病年龄呈年轻化趋势,越来越多的青少年患有抑郁症。这是由于青少年处于生理与心理快速发展阶段,面对成长环境的压力和心理教育的缺乏,更容易产生各种心理问题[2]。研究表明,抑郁症会对个体的学习、认知和记忆能力造成很大影响,其主要特征包括持续地情绪低落、快感缺失以及认知障碍,患者难以控制自己的情绪且严重者可能出现自杀倾向并付诸行动[3]。
由于不清楚潜在的神经机制和病理学原理,抑郁症的临床诊断比较困难。精神疾病患者在外观表现上与正常人没有区别,因此临床医生只能根据患者的自我描述和相关信息进行主观诊断,诊断的结果往往取决于医生的经验[4-5],因此这种诊断方法具有较强的主观性和不准确性。另外,在临床上,医生的诊断更多依赖于抑郁量表,如抑郁筛查量表(PHQ-9)[6]、汉密尔顿抑郁评定量表(HDRS)或贝克抑郁量表(BDI)等。由于抑郁症筛查所使用的问卷涉及患者的主观描述,通过问卷筛查经常出现假阳性或假阴性的情况。综上所述,仅通过医生诊断和问卷筛查的抑郁症诊断方法是不严谨的。
面对抑郁症识别遇到的问题和挑战,计算机研究界开始使用行为线索来学习识别抑郁症、创伤后应激障碍等相关精神障碍[7]。面部表情、语音韵律等行为特征已经被证明是预测抑郁症的重要特征[8-9]。而且,人的自然语言和社交活动中也包含了重要的信息。例如人的面部表情和身体姿势[9]被用作抑郁症识别。另外,社交网络中文本数据、图片数据也可以被用于抑郁症识别[10],帮助心理学家和精神科医生评估患者的抑郁水平。
另外,研究者发现抑郁症与脑功能异常有着密切的关系[11]。许多成像技术被用于探索和辅助治疗抑郁症等精神疾病,如功能磁共振成像(fMRI)、正电子发射断层扫描(PET)和单光子发射计算机断层扫描(SPECT)等。其中PET 和SPECT 需要往受试者体内注射放射性物质,通过局部脑血流灌注断层显像技术进行分析[12]。脑电图(Electroencephalogram)是一种常见的无痛、无创的脑功能评估方法,常用于抑郁症、癫痫、阿尔兹海默症、精神分裂症等疾病的辅助诊断,其优点在于成本低、灵敏度高且便于记录大脑活动。研究表明,抑郁症患者的认知能力受到情绪变化的影响而变化[13],这些变化可以在一定程度上影响脑电图。因此,本文选择脑电模态数据作为多模态特征融合的其中一种模态进行研究。
传统的脑电研究都是使用脑电图中的线性特征和非线性特征来进行识别,如Erguzel 等人[14]提取脑电图频谱的线性特征,结合反向传播神经网络(BPNN)和遗传算法(GA)进行抑郁症患者的分类,准确率达到了89.12%。Hosseinifard 等人[15]提取了4 种非线性特征,包括去趋势波动分析、Higuchi 分形、相关维数和Lyapunov 指数对抑郁症患者和正常人进行分类,使用逻辑回归(LR)分类器,准确率达到了90.12%。
除了线性与非线性特征外,功能连通性也被作为判断抑郁症患者与正常人之间的差异的特征,并基于功能连通性进行区分。Orgo 等人[16]通过提取功能连通性特征以及相干性、聚类系数等图论特征,采用支持向量机(SVM)和遗传算法对64 名受试者进行分类,准确率达到了88.10%。Peng 等人[17]提取用相位滞后指数值(PLI 值),使用支持向量机和肯德尔秩相关系数进行分类,且分类效果理想。因此,本文借鉴Peng的方法进行特征提取,使用PLI值来描述EEG 通道间的功能连通性并用于训练。
除了通过上述所说的文本、图片、脑电等方式识别抑郁症,语音识别也是一种广泛用于抑郁症识别的方式。语音能够反映人的情绪,因此可以通过分析语音的情感来识别抑郁症。如Balano 等人[18]分析了正常人与抑郁症患者之间的语音差异,发现抑郁症患者的声音更为沙哑、结巴、低沉。Flint 等人[19]发现抑郁症患者存在一定程度的语言障碍,他们的思维逻辑更为缓慢,停顿时间更长,停顿的次数更多。于是本文选择使用音频模态作为特征融合的另一种模态,提高抑郁症识别的准确率。
本文通过结合音频模态和脑电模态的信息进行抑郁症识别,从预处理后的脑电图数据中提取PLI 值作为脑电特征,从预处理后的音频数据中提取常用的语音识别系数如MFCC 等作为音频特征,以特征融合的方式识别抑郁症,并与单模态抑郁症识别的准确率进行对比,另外在对比实验中加入决策融合和机器学习的方法。
1 相关研究
本章将介绍多模态数据融合的常见方法。
多模态的融合方法大致可以分为2 大类,分别是模型无关的融合方法和基于模型的分类方法[20]。模型无关的分类方法是根据融合的时期进行分类,共分为特征融合(又称为早期融合)、决策融合(又称为晚期融合)和混合融合。本文所使用的就是其中的特征融合。
特征融合是指对各个模态的数据特征提取后对特征进行融合的一种方式,其优势在于可以在模型训练前充分利用各个模态特征之间的相关性,适用于模态高度相关的情况,如Cai 等人[21]对3 种模态下的EEG 数据(中性音频刺激、负性音频刺激和正性音频刺激)进行特征融合,将不同模态下提取的特征进行线性组合,并使用t 检验从组合后的特征矩阵中选出新的特征作为分类器的输入,通过使用多个分类器进行对比实验,最高分类准确率可达86.98%。
决策融合是指在每个模态都做出决策(分类或回归)后再进行融合,在深度学习模型中,决策融合的做法是先使用不同模态单独进行训练,训练后将训练的结果进行融合[22]。决策融合不需要模型之间有很强的相关性即可融合,其主要通过采用不同规则或采用深度学习模型来确定最终融合的方式,如最大值融合、平均值融合等融合方法[23]。Yang 等人[24]使用由深度卷积神经网络(DCNN)和深度神经网络(DNN)模型组成的多模态融合框架,通过融合音频、视频和文本的特征对患者的抑郁程度进行测量。首先对各个模态都通过DCNN 学习高级全局特征,然后将特征输入DNN 获得预测的PHQ-8 的分数,最后将3 个模态预测的PHQ-8分数使用DNN进行决策融合得到最终的PHQ-8分数。张迎辉等人[25]提出基于深度森林的多模态决策级融合方法,其通过选择出能够用于融合的特征进行基于深度森林的多粒度扫描和级联,实现了深度森林各级的决策融合,提高了抑郁症检测正确率。
混合融合既包含了特征融合,又包含了决策融合,在综合两者优点的同时也复杂化了模型的结构,增加了训练的难度,但由于其结构灵活和多样,在手势识别和多媒体[26]等领域应用广泛。Lan 等人[27]利用混合融合进行多媒体事件检测,结合了特征融合和决策融合的方法,捕捉模态间的特征关系,解决了模型过拟合的问题,这种混合融合的方式使模型达到88.10%的准确率。
上述3 种方法各有优缺点,考虑到音频模态和脑电模态之间的联系,本文基于深度学习使用全连接神经网络进行多模态的特征融合:先通过全连接神经网络分别对2 种模态数据进行单独训练,降低特征维度并得到2 种模态抽象的特征。其次,将2 种模态抽象的特征融合并使用前馈神经网络作为分类模型,将融合后的特征映射到分类空间进行分类,最终完成抑郁症的识别。
2 方 法
本文提出一种基于全连接神经网络的多模态特征融合方法,使用2 种模态进行研究:脑电模态和音频模态。脑电模态记录了受试者静息状态下的脑电信息,而音频模态则记录了受试者在访谈、阅读和图片描述过程中的语音信息。
由于模态包含的信息和特性具有一定的相关性,因此使用全连接神经网络分别对不同模态的特征进行训练并融合,对融合后的特征使用前馈神经网络进行抑郁症识别。模型的整体框架如图1 所示,整个模型主要由3 个部分组成:脑电模态特征提取与选择,音频模态的特征提取与选择以及对双模态融合的特征进行训练与分类。

图1 多模态特征融合框架
2.1 脑电模态
2.1.1 脑电预处理
本文使用兰州大学建立的MODMA数据集[28],数据通过128 通道HydroCel 传感器和Net Station 软件进行采集,采样率为250 Hz,参考电极为顶点电极(CZ电极)。针对原始数据,本文使用MATLAB 中的EEGLAB[29]工具包对数据进行预处理,主要流程如下:
1)进行电极重定位和重参考(全脑平均参考)。2)使用Sinc FIR 滤波器[30]进行滤波,带通为1~40 Hz,去除线噪声和电干扰。
3)对EEG 数据进行分段(每段长为2 s)并去除伪迹。
4)使用独立成分分析(ICA)去除眼电(EOG)和肌电(EMG)伪影。
2.1.2 脑电特征提取与特征选择
对预处理后的数据进行特征提取,计算相位滞后指数PLI。PLI值[31]用于估计EEG双通道之间相位差分布的不对称性,可以在一定程度上描述通道之间的功能连通性。对于给定的2 个EEG 信号x和y,PLI 值的计算方法如公式(1)所示:
其中,θx(h)表示该通道信号的瞬时相位,θx(h)-θy(h)表示信号x和y在频率h下的相位差,sign(·)代表符号函数。PLI 值的取值区间在0 到1 之间,0 表示不耦合,1 表示完全相位同步。通过上述计算方程,利用PLIxy值评估每对通道之间的功能连通性。因此,对于每个受试者,可以获得一个128×128 的功能连通矩阵F:
对于功能连通矩阵F,将矩阵的对角元素fii设为1,非对角元素fij(i≠j)设为PLIxy值。矩阵的每一列和每一行对应一个不同的通道,矩阵第i行第j列表示通道i和通道j之间连通性的强度。由于矩阵关于对角线对称,因此剔除无意义的对角元素和重复的下三角元素,提取矩阵的上三角元素作为分类特征。因此脑电特征提取后得到的特征维数为128×(128-1)/2=8128。
为了去除不相关和冗余的特征,提高模型的泛化能力,本文采用特征选择算法来对提取的特征进行降维。ReliefF[32]是一种特征权重算法,其不仅具有效果好、效率高的特点,还可以在一定程度上保留特征原有的物理意义。ReliefF算法的主要步骤如下:
1)从所有样本中随机取一个样本x。
2)从与样本x相同分类的样本集中取出k个最近邻样本。
3)从其他与样本x不同分类的样本集中也取出k个最近邻样本。
4)最后,计算特征的权重并从大到小进行排序,权重值越大,排名越靠前则代表该特征越重要,对样本的分类效果越好。
通过ReliefF 特征选择方法,本文提取权重排名前500维的特征用于多模态特征融合。
2.2 音频模态
2.2.1 音频数据预处理
本文使用的是兰州大学MODMA 数据集的音频部分,语音采集软件为Adobe Audition CS6,采样频率为44.1 Hz,采样深度为24 bit,单声道。音频内容为受试者对主试提出的问题作出的回答。针对原始数据,对数据进行的预处理流程如下:
1)对音频数据进行预加重[33],其作用就是在传输线的始端增强信号的高频成分,补偿其在传输过程中的衰减,提高输出信噪比。语音信号的预加重可以通过一阶FIR 高通数字滤波器来实现,设时刻n的语音信号采样值为X(n),则预加重的输出信号Y(n)的计算公式如下:
其中,预加重系数μ的值应介于0.9 和1.0 之间,本文中μ的值取为0.97。
2)对音频信号进行分帧,将原始语音信号分成大小固定的N段语音信号,将每一段语音信号称为一帧,帧长通常取10~30 ms 之间,本文帧长取25 ms。在分帧过程中,相邻的2 帧之间有所重叠,重叠部分被称为帧移,本文帧移取10 ms。
3)为了消除各帧两端可能存在的信号不连续问题,采用窗函数加权法对音频信号进行加窗,窗函数选用长度为L的汉明窗,设时刻n的窗函数输出为w(n),则窗函数公式如下:
将时刻n的窗函数w(n)与信号f(n)相乘,得到加窗后的语音信号fw(n):
2.2.2 音频特征提取与特征选择
对预处理后的数据进行特征提取,本文将音频分为沉默段和语音段,共提取1600 维特征。其中沉默段指的是音频信号中语音的沉默部分,即上一句话的结束到下一句话的开始之间的语音段。通过语音端点检测技术[34]提取8 个维度特征,包括最大沉默时间、总暂停时间等。通过Open Smile[35]提取语音段特征,共1582 维特征,其中包括梅尔频率倒谱系数(MFCC)等重要特征,使用配置文件为emobase2010。
对于音频特征,本文同样使用ReliefF 特征选择方法进行特征选择,提取权重排名前500 维的特征用于多模态特征融合。
2.3 多模态决策融合模型
决策融合是子模型做出决策后再融合的方法,其特点在于可以选择合适的模型对不同的模态进行训练,然后根据子模型的训练结果选择合适的方式进行融合。本文设计一种多模态决策融合方法来作为对比实验。对于不同的模态,本文使用2 种不同的子模型分别进行训练,然后使用线性加权的方式进行决策融合,决策融合的网络结构如图2所示。

图2 多模态决策融合网络结构
对于音频模态数据,本文在特征提取后使用全连接神经网络进行训练,其中包括1层输入层、5层全连接层和1 层Softmax 输出层。其中全连接层神经元数目分别为1200、1200、850、600和500。由于实验数据较少,而神经网络参数较多,因此在神经网络中加入了Dropout,如图2 中虚线部分所示。在每次训练过程中,每个神经元都会以一定概率被停止,这样就使得一个神经元的训练不依赖于另一个神经元,因此可以减少过拟合现象并提升模型的泛化能力。
对于脑电模态,由于其是关于时间序列记录的数据,且经过实验发现对于脑电数据引入长短期记忆神经网络(LSTM)比全连接神经网络表现更好,因此在决策模型中,本文对脑电模态引入LSTM 网络进行训练,其中包括1 层输入层,2 层LSTM 层、1 层线性层和1层Softmax输出层。
音频模态数据和脑电模态数据经过各子模型训练和Softmax 层分类后,得到单一模态下,受试者是否患有抑郁症的概率。分类概率如公式(6)所示:
其中:Pi表示输出为第i类的概率,zi表示最后一层神经元中第i个值,分母为对所有神经元的值指数求和。得到各子模型的分类概率Pi之后,在Softmax 层使用线性加权的方式融合,最终得到抑郁症识别的概率。
实验共设置2 个权重参数w1和w2,Softmax 层线性加权如公式(7)所示:
2.4 多模态特征融合模型
多模态特征融合是指对各个模态数据特征先进行融合,再用于分类任务的一种融合方式。其优势在于可以充分结合模态间的相关性信息,更好地提升模型的分类效果。多模态特征融合的做法主要是将不同模态的特征向量经过特定的映射后形成一个新的特征向量[36]。由于音频数据记录了受试者访谈、阅读等任务下的语音信息,而脑电数据记录了同一名受试者进行音频任务前静息状态下的脑电信息,2 种数据之间存在一定的互补性,因此可以对这2 种模态进行特征融合。
神经网络的本质是通过一层层隐藏层的线性和非线性变换对输入的数据特征进行计算和变形,直至可以很容易地区分不同的类别。神经网络的逐层计算,就是对原始数据的逐层抽象,后一层神经元的输入是前一层神经元输出的加权和,前一层的特征在后一层就被抽象出来。因此,神经网络学习的过程就是调节和优化权重和阈值,并不断抽象的过程。
综上,本文提出一种基于全连接神经网络的多模态特征融合模型,模型的具体结构如图3所示。
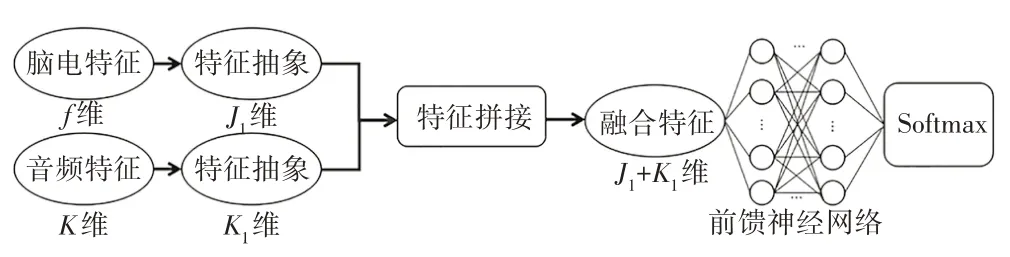
图3 多模态特征融合网络结构
首先,分别将2 种模态的特征使用全连接神经网络进行抽象。由于神经网络的层数越多,输入特征抽象的层次就越深,对其理解的准确度也就越深。因此,本文先对2种模态数据进行抽象,使用3层隐藏层进行训练,均得到200 维的抽象特征,并将其用于特征融合。
在特征融合部分,本文使用特征拼接的方法,即将200 维脑电特征[x1,x2,…,x200]与200 维音频特征[y1,y2,…,y200]直接拼接成400 维的特征[x1,x2,…,x200,y1,y2,…,y200]。由于神经网络可以自动训练特征之间的权重值,因此本文将融合后的特征直接输入前馈神经网络中,让网络自动学习权重之间的关系。在前馈神经网络中,使用ReLU 激活函数为模型加入非线性因素,使用反向传播算法收敛损失值并更新网络参数。网络中共添加3 层隐藏层,神经元个数分别为300、200 和100,epoch 设置为350。网络多次训练和迭代后,经过Softmax 层的输出得到最终的模型分类结果。
3 实验
3.1 实验数据
本文采用兰州大学MODMA 数据集,该数据集包括53 例受试者静息状态下的128 电极脑电图信号以及52 名受试者在访谈、阅读和图片描述过程中记录的音频,其中每个受试者包含29 个音频文件。由于数据集中采集静息态数据的受试者与采集音频数据的受试者并不完全相同,而对非同一对象的多模态数据的训练没有意义,因此剔除其中只有单个模态数据的受试者,保留38名受试者的数据用于训练和分类。
3.2 实验参数与设置
本文使用基于全连接神经网络的模型来进行多模态特征融合,使用Adam 作为优化器,NLLLoss 作为损失函数,学习率设置为0.00001。由于数据集样本的数量较少,可能会对模型的分类准确率产生一定影响,因此本文所有的实验均采用留一交叉验证法(LOOCV)[37]来评估模型的泛化能力,即对于每一次实验均使用37个样本作为训练集,1个作为测试集。
本文通过设置机器学习和深度学习的多个对比实验来验证多模态特征融合的效果。采用支持向量机SVM 和K 近邻算法(KNN)来设置机器学习的对比实验,采用多模态决策融合来设置深度学习的对比实验。其中SVM 类型为C-SVC,核函数为线性核函数,KNN 中K的取值为3。在进行上述分类之前,将所有的特征进行归一化。
3.3 实验结果与分析
为了验证模型的效果,本文对数据集设计了对比实验。首先对单个模态,分别计算在KNN、SVM 以及全连接神经网络下抑郁症识别的准确率,其次计算多模态决策融合下抑郁症识别的准确率,最后计算多模态特征融合模型的抑郁症识别准确率,所有实验的对比结果如表1与表2所示。
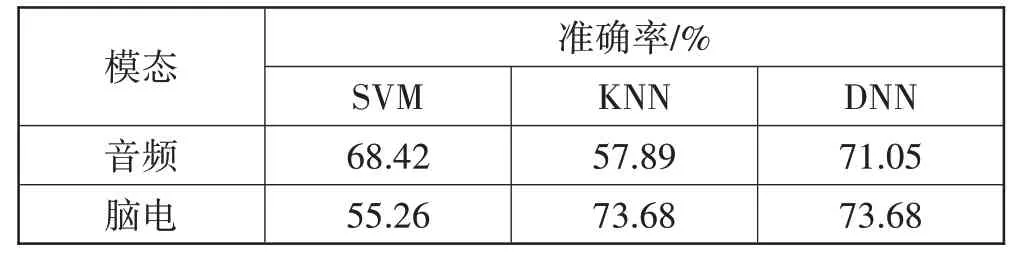
表1 单模态机器学习方法与深度学习方法准确率对比

表2 多模态特征融合与其他方法准确率对比
由表1与表2可知,对于单模态抑郁症识别,使用深度学习方法的准确率相较于机器学习的方法来说有所提升,其中在音频模态上表现更为明显,而在脑电模态上KNN 也表现较好,与全连接神经网络有相同的准确率。
而对于多模态抑郁症识别,特征融合具有最高的准确率,且明显高于其他融合方法,而决策融合的方法与之相比表现较差。
通过上述实验对比,基于全连接神经网络的特征融合模型相较于其他方法在准确率方面有不同程度的提升,表明了该方法的有效性,说明了特征融合的思想可以应用于脑电和音频模态的抑郁症识别。同时表明了简单加权求和方式下的决策融合表现较差,当模态之间相关性较强时,特征融合的效果更好。
4 结束语
本文针对抑郁症临床诊断困难的问题,在深度学习的基础上提出了基于全连接神经网络的多模态特征融合模型,融合音频和脑电模态的抽象特征并用于训练,保留了模态间的相关性。并且通过在MODMA数据集上的对比验证,特征融合模型相对于单模态抑郁症识别和决策融合模型具有更高的准确率。
由于本文只使用MODMA 多模态抑郁症数据集,且数据集数据较少,因此本文所提出的方法只局限于音频和脑电这2 种模态。在接下来的研究中,可以对数据集的数据量进行扩充或者对其他的模态领域进行探索,增加多模态特征融合的适用性。
