面向天地融合网络的无线资源智能分配方法
2023-11-13魏强廖瑛徐潇审郝媛媛任术波张千缪中宇辛宁
魏强 廖瑛 徐潇审 郝媛媛 任术波 张千 缪中宇 辛宁
(1 国防科技大学 空天科学学院,长沙 410073)
(2 中国空间技术研究院通信与导航卫星总体部,北京 100094)
(3 中国人民解放军32039部队,北京 102300)
随着通信需求向多空间、多方位的不断扩展,以及天基、空基、海基、地基等各种网络服务的不断涌现[1],构建全球覆盖、随遇接入、按需服务的天地融合网络是通信发展的重要趋势[2]。天地融合网络充分利用天基网络和地基网络在不同空间维度上的优势,不断突破网络边界限制,在实现多维网络互联互通的同时为用户提供全时全域的信息服务。然而,建设天地融合网络需要大量的频谱资源来满足通信需求,而频谱资源是有限且不可再生的,因此,设计天地融合网络的无线资源智能分配方法,提高频谱资源利用率,成为天地融合通信系统中亟需解决的关键难题之一[3]。
为了对有限频谱资源进行高效利用,文献[4]中提出了天地融合网络中的认知无线电技术,通过卫星网络与地面网络之间的频谱资源共享提升频谱资源的利用率。认知无线电技术旨在根据无线电环境调整参数以动态接入可用频谱,具体来说,该技术允许未授权的卫星用户在不中断已授权地面用户通信的情况下访问未使用的频谱。根据授权用户(地面用户)和认知用户(卫星用户)的频谱资源占用情况,认知无线电技术可以分为覆盖(Overlay)模式、底垫(Underlay)模式,以及两者混合(Hybrid)模式[5]。Underlay模式允许授权用户与认知用户同时使用同一频段,但要求认知用户对授权用户的干扰处于一个可接受的范围;在Overlay模式下,认知用户通过频谱空洞探测结果来决定是否接入授权用户已经占用的信道,以避免对授权用户产生干扰;Hybrid模式即为Overlay模式与Underlay模式兼备的模式。为了最大程度地提高频谱利用率,本文采用Underlay模式实现天地融合网络中的可用频谱动态接入,即:如果卫星用户引起的干扰低于地面用户预定义的干扰阈值,则允许并行传输。但是,对于授权频谱的二次利用方式,可能会导致严重的同频干扰问题,这对资源分配提出了严峻的挑战。
近年来,利用认知无线电技术深入研究天地融合网络中的频谱资源利用问题,在一体化频谱感知、共享与管理方面已获得一定的研究成果。文献[6]中提出了一种基于卫星和基站协作的频谱感知方案,利用模糊神经网络确定最佳检测概率。文献[7]中研究了基于云的卫星和地面频谱共享网络,并提出了基于认知无线电的智能频谱共享方案,以减少用户阻塞率和等待概率。但是,在实时操作中,频繁的切换导致卫星网络的通信环境高度动态且复杂多变,难以用数学模型来建模和求解。为了解决该问题,有些研究尝试将强化学习与认知无线电网络集成,以获得最佳的资源管理策略。文献[8]中提出一种认知无线电物联网(CR-IoTNet)框架,该框架将物联网与认知无线电技术融合,通过采用支持向量机(SVM)算法分析传输数据的潜在特征,以获取传输网络的频谱状态信息,更加智能地管理和优化频谱资源的利用。文献[9]中利用认知无线电技术提出一种卫星通信的动态频谱接入方法,采用双深度(Q-learning)神经网络来自主感知当前频谱资源状况并学习资源感知分配策略,实现频谱利用率的提升。但是,以上研究将通信环境视为完全未知的,忽视了网络拓扑结构信息的重要性,在大规模通信网络中可能会出现性能下降甚至是失效的情况。
针对上述问题,本文将天地融合网络建模为动态图结构,将信号链路视为节点,干扰链路视为边,利用图结构来保存通信环境中的时空拓扑信息,为资源分配提供先验知识。然后,提出一种应用图卷积网络深度强化学习的无线资源分配方法,利用智能体与通信环境之间的交互,自主感知频谱资源状态并探索最优的信道选择和功率调整策略,在实现卫星网络和地面网络之间频谱共享的同时提高天地融合网络的频谱资源利用率。
1 场景建模与问题优化
1.1 系统模型
本文针对天地融合网络的下行传输过程进行研究,系统模型如图1所示,由地面基站b∈{1,2,…,B}和每个基站服务的地面用户u∈{1,2,…,U}构成的地面网络为主网络,由地球静止轨道(GEO)卫星s∈{1,2,…,S}和每颗卫星服务的卫星用户v∈{1,2,…,V}构成的认知卫星网络为次网络,其中,B为地面基站数,U为地面用户数,S为卫星数,V为卫星用户数。地面用户作为主用户,通常配备单副天线与基站通信;卫星用户作为次级用户,采用定向天线与GEO卫星进行通信。此外,本文假设卫星用户采用Underlay模式与地面用户共享频谱资源,系统中的总带宽为W,频谱资源由集合n∈{1,2,…,N}表示,N为子信道的数量。
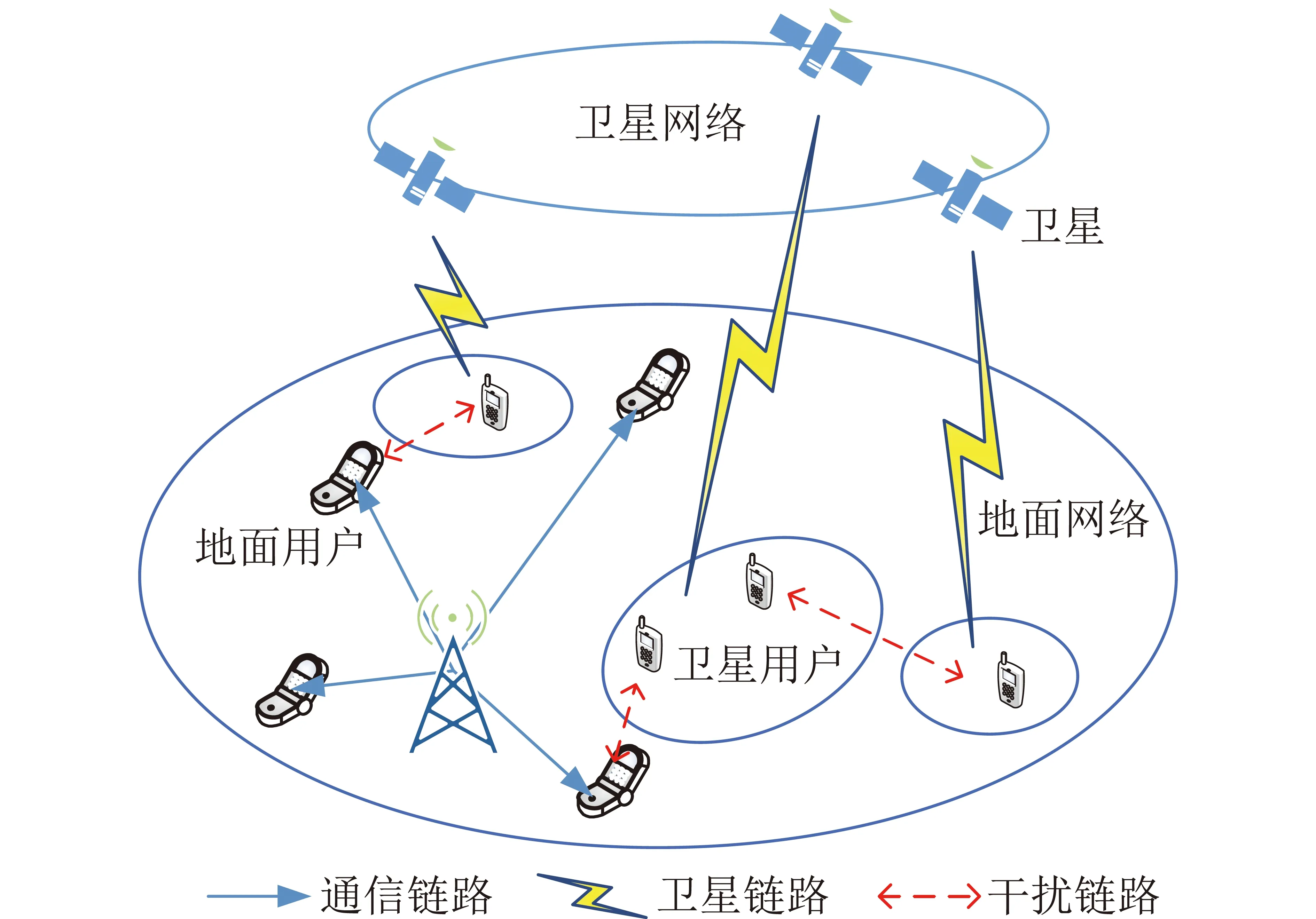
图1 系统模型Fig.1 System model
1.2 信道模型
在天地融合网络中存在2种类型的下行链路。①GEO卫星与卫星用户之间的传输链路,采用自由空间传播模型;②基站与地面用户之间的传输链路,采用对数正态(Log-normal)阴影模型。
1)卫星用户信道模型
考虑自由空间损耗的影响,卫星用户下行链路的信道增益表示为
(1)
式中:GR为用户接收天线增益;Gs,v为第s颗卫星到第v个用户的天线增益;ds,v为卫星与用户之间的距离;λ为工作波长。
2)地面用户信道模型
考虑到阴影衰落和路径损耗的影响,基站与用户下行链路信道增益可以表示为
(2)
式中:K为阴影效应的随机变量;f为信道的中心频率;L为信道模型的校正参数;db,u为用户和基站之间的距离;α为路径损耗指数。
3)系统容量
在天地融合网络中,卫星用户与地面用户共享同一信道时会相互干扰。对于地面用户来说,其主要干扰来源为次网络中的卫星用户。假设卫星用户和地面用户共享相同的资源块n,则地面用户u在资源块n上遭受的干扰为
(3)

地面用户u的数据速率为
(4)
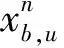
对于卫星用户来说,它会受到来自地面用户的干扰,以及其他次网络中的卫星用户的干扰。类似地,假设卫星用户和地面用户共享相同的资源块n,卫星用户v的干扰为
(5)
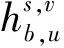
第v个卫星用户在资源块n上的数据速率为
(6)

综上所述,天地融合网络的系统总数据速率为
(7)
1.3 优化问题
本文的优化目标为:在保证主用户通信不受影响的前提下,最大化整体网络系统容量,因此优化问题可表达为
(8)

2 无线资源智能分配方法
本节提出了一种应用图卷积网络深度强化学习的无线资源智能分配方法,流程如图2所示。

图2 方法流程Fig.2 Method flow
在无线资源智能分配方法中,首先,初始化无线电网络环境,利用动态图结构来构建天地融合网络的拓扑结构模型和虚拟干扰链路;然后,设计应用图卷积网络的深度强化学习端到端模型,通过特征提取生成资源分配策略;接着,执行上述策略,得到当前的资源分配状态;最后,通过奖励计算判断是否满足优化目标,并重复上述过程直到学习到最优的资源分配策略。
2.1 应用动态图结构的通信环境拓扑模型构建
动态图结构G表示为一组顶点C和边E的集合,关系式为G={C,E}。为了更详细地描述图结构,使用邻接矩阵M=[mpq]来表示这种关联,即
(9)
式中:epq为2个相邻顶点cp和cq的边;mpq=1表示cp和cq之间存在边,反之,mpq=0。
动态图结构构建完成之后,使用图神经网络处理图结构数据,图神经网络通过聚集来自每个顶点的边和相邻顶点的特征,以迭代方式更新顶点的隐藏状态。在每个时间t,图中的每个顶点c的隐藏状态嵌入都被更新,表示为hc,c∈C。在时间t+1,顶点c的隐藏状态嵌入被更新为
(10)

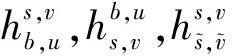
2.2 强化学习要素设计
本文将中央控制器视为智能体,负责调度认知天地融合网络中Underlay模式下主用户和次用户的频谱和功率资源。强化学习框架中的状态表示智能体可以从环境中获取的信息。由于认知无线电网络的总数据速率受到同信道干扰的影响显著,而同信道干扰包括卫星、用户之间的同层干扰,以及卫星用户和地面用户之间的跨层干扰,这些干扰是用户距离分布和资源占用的结果。
对于第i次迭代训练的时间t,有效状态oi,t主要由用户距离分布D(i,t)和资源占用情况X(i,t)组成。
oi,t={D(i,t),X(i,t)}
(11)


(12)
(13)
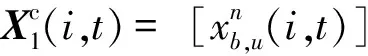
奖励定义为认知网络的系统数据速率r(oi,t,ai,t)=Ctotal。
2.3 端到端的策略学习模型
在解决资源分配和干扰减缓问题中,认知无线电网络拓扑的空间特征至关重要。图4为应用图卷积网络的端到端模型,用来联合学习环境表示与资源分配策略。为了提取认知无线电网络拓扑上的特征,采用图卷积网络作为基础,使用阶数索引为1的2个图卷积层,有效提取干扰特征,防止因堆叠层过少导致顶点缺失相邻的特征信息或者堆叠层过多导致所有的顶点都被判断为邻点的问题。此外,使用3个全连接层作为局部输出函数,生成动作的概率分布,为了将输出解释为概率分布,本文在输出层使用Softmax函数将实数向量映射为0~1范围内的向量。在学习模型中,每个动作有2个子目标,即信道选择和功率调整,通过共享该模型的图卷积网络层和完全连接层实现这2个子目标,并且将这2个子目标的损失和设置为整个模型的总损失函数,使得权重可以通过反向传播同时学习信道选择和功率调整的策略。通过权重共享方法,能避免设计2个独立学习模型的复杂性,使得模型更加高效。
通过构建应用图卷积网络的端到端学习模型,将表示学习和任务学习融合在一起,解决复杂的认知无线电网络资源分配问题。该模型不仅避免了顶点特征在连接中的不连贯性,还保持了强化学习框架的奖励引导。通过多层特征提取,自动获取最具代表性的空间特征,支持精确的资源分配决策。同时,模型通过整体奖励驱动,实现了表示学习和任务学习的同时进行。
2.4 应用策略梯度算法的学习过程
(14)
(15)

总损失与网络参数更新公式为
(16)
(17)
式中:η为学习率。
最小化损失函数即为最大化累积奖励,根据r(oi,t,ai,t)=Ctotal的奖励设置,表明本文的优化目标为最大化系统数据速率,并且智能体在损失函数(累积奖励)的驱动下不断更新网络参数,直到学习到最优的信道选择和功率调整策略。
3 仿真结果与分析
在本节中,通过试验来评估本文提出的资源分配方法,该方法是应用图卷积网络的深度强化学习框架(GCN+DRL)实现的,仿真参数如表1所示。
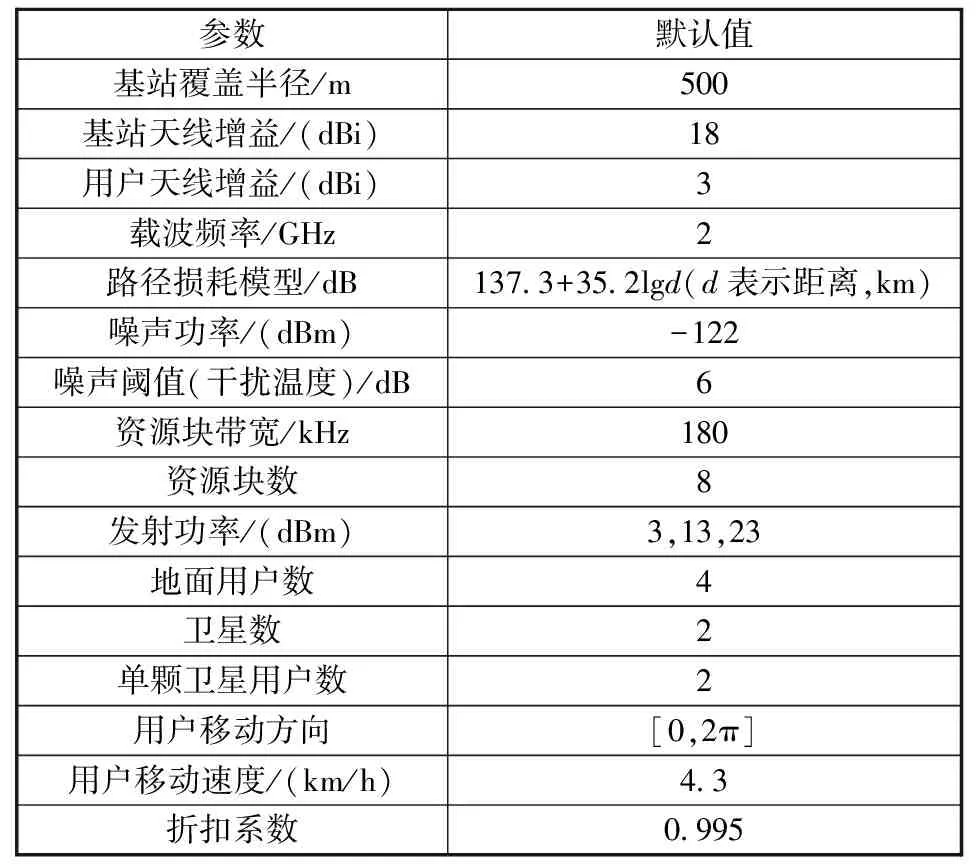
表1 仿真参数Table 1 Simulation parameters
将本文提出的GCN+DRL与以下几种方法进行比较:①随机法(Random Strategy);②策略梯度法(PG Algorithm);③应用卷积神经网络的深度强化学习法(CNN+DRL)。其中:Random Strategy以随机策略选择信道占用;PG Algorithm采用全连接网络,并利用梯度信息来改进策略;CNN+DRL采用卷积神经网络与全连接网络的混合结构,并利用PG Algorithm更新策略。此外,本文提出的GCN+DRL将通信环境的网络拓扑结构转换为图形式,并且采用图神经网络与全连接网络的混合设计来挖掘环境中潜在的干扰信息,以实现更高效的资源利用。
图5展示了不同方法可达到的数据速率。在下行链路干扰受限的认知网络中,GCN+DRL表现最好。相比之下,Random Strategy收敛速度较快,但其实现的资源分配方案并不是最优的;PG Algorithm在40000次迭代后收敛,但由于用户移动而存在较大波动;CNN+DRL在收敛速度和资源分配性能上均次于GCN+DRL。

图5 不同方法的可实现数据速率Fig.5 Achievable data rates for different methods
图6描述了提出的联合信道选择和功率调整方法的收敛性,展示了随着训练迭代次数的增加,每个训练步骤的预期回报。当学习网络刚开始训练时,预期回报值相对较小,并且方法处于探索阶段。随着培训过程数量的增加,预期回报值逐渐增加。训练20000次迭代后,预期回报值稳定下来,这意味着本文方法将自动更新其决策策略并收敛到最优。此外,表2给出了不同方法的收敛时间对比,Random Strategy虽然实现了快速的收敛,但是其系统数据速率性能较差;与其他方法相比,GCN+DRL具有更短的收敛时间,因为其利用图神经网络可以挖掘通信环境中的潜在干扰信息,实现干扰避免并获得较高的数据速率。

表2 不同方法收敛时间Table 2 Convergence time of different methods

图6 方法收敛性Fig.6 Convergence of the proposed method
图7研究了本文方法分别在0.00001,0.00003,0.00005,0.00007学习率下的收敛性能。从图7中可以看出:不同学习率的曲线之间存在相同的趋势,但收敛时间略有不同。就趋势而言,早期智能体主要负责尝试,所以预期回报值较低;就收敛时间而言,学习率为0.00001的曲线收敛大约22000次迭代,学习率为0.00003的曲线收敛大约20000次迭代,学习率为0.00005和0.00007的曲线收敛迭代次数相对较小,大约18000次迭代,因此相对较大的学习率可以加速学习过程。但是,为了收敛到最优学习策略,本文更倾向于牺牲收敛时间,选择相对较小的学习率,得到较大的回报。

图7 不同学习率的收敛性Fig.7 Convergence for different learning rates
4 结束语
本文基于认知无线电技术提出一种应用图卷积网络深度强化学习的资源分配方法,在保证主用户服务质量的前提下最大化系统数据速率。为了建模认知无线电网络的底层拓扑结构,本文考虑地面网络为主网络,卫星网络为次网络,将通信网络建模为动态结构,使用随机行走模型来模仿用户的动作,利用结构中包含的用户距离分布来估计信道质量信息,并且通过图卷积网络提取关键的干扰特征。最后,采用深度强化学习框架进行模型学习,探索最优资源分配策略。试验结果表明:本文方法在保证授权用户遭受的干扰小于其噪声阈值的前提下,显著提升了天地融合网络的系统数据速率。
