FAIR原则评估指标与评估工具研究*
2023-11-10姜恩波潘婷戴婷杨明芬高杨
姜恩波 潘婷 戴婷 杨明芬 高杨
(1. 中国科学院成都文献情报中心,成都 610299;2. 中国科学院大学信息资源管理系,北京 100190;3. 上海师范大学图书馆,上海 201400;4. 四川大学公共管理学院,成都 610065;5. 西藏自治区科技信息研究所,拉萨 850000)
1 FAIR原则的发展背景
FAIR原则是近年来由国外政府机构、国际组织、科研(资助)机构、软件企业等利益相关者共同提出的,机构在科研成果管理与服务过程中遵循的一种理念,即科研成果对于机器用户和自然人用户应该是可发现(Findable)、可访问(Accessible)、可互操作(Interoperable)和可重用(Reusable)的。这里的科研成果包括但不限于数据、软件代码、研究对象、工作流等。目前FAIR原则的研究与实践集中在研究数据管理领域。
众所周知,FAIR原则是在2014年“数据FAIR接口联合设计”(Jointly Designing a Data Fairport)专题研讨会上提出的。与会者意识到研究数据的开放共享本质上是一项全球范围的工作,各国需要共同定义一套最低限度的指标,并通过社区实践,让利益相关者能够更容易地发现、获取、整合和重用由数据密集型科学产生的大量信息。可见FAIR原则的建设内容、实施路径以及预期目标在最初始的阶段就已经比较清晰。2016年,Wilkinson等[1]在《科学数据》(Scientific Data)上发文,提出FAIR原则包括4个原则、10个二级属性和5个三级属性,其中:可发现原则有4个二级属性,可访问原则有2个二级属性和2个三级属性,可互操作原则有3个二级属性,可重用原则有1个二级属性和3个三级属性,见表1。也有将“原则”称为“维度”,将“属性”称为“子原则”的学者,本文采用“原则”与“属性”的叫法。

表1 FAIR原则及细分属性
FAIR所包含的可发现、可访问、可互操作以及可重用的理念其实并不是第一次被提出。关联数据五星原则、可信数字存储库(TDR)、CoreTrustSeal认证以及数据全生命周期理论都从不同的角度有所涉及,并且这些规范也在相关领域实施与应用,但是只有FAIR简明、宏观、独立地表达了相关理念。由于FAIR的广泛适用性以及研讨会参会者身份的多样性,FAIR的理念很快传播开去,逐步为部分政府机构、科研机构、科研资助者、出版商和服务提供商所接受,并开始出现一些实践案例。2016年G20杭州峰会召开,G20领导人发表声明,支持将FAIR原则应用于研究[2]。同时,国际科技数据委员会(Committee on Data for Science and Technology,CODATA)和研究数据联盟(Research Data Alliance,RDA)等活跃于研究数据生态系统的国际组织也支持其社区实施FAIR原则。欧洲研究图书馆协会(Association of European Research Libraries,LI BER)在报告《FA I R数据行动计划公开咨询》(Open Consultation on FAIR Data Action Plan)中建议使用FAIR原则[3]。其中,最有力的支持者就是欧盟委员会。2016年4月,欧盟委员会发布《地平线项目2020 FAIR数据管理计划指南》(Guidelines on FAIR Data Management in Horizon 2020),宣布计划推动由欧盟所资助的研究项目产生的科学数据实现FAIR,从而正式将FAIR原则纳入开放科学建设体系[4]。随后,欧盟在“地平线2020”、欧洲开放科学云(European Open Science Cloud,EOSC)等大型泛欧科研基础设施建设过程中积极推动FAIR落地。2018年,欧盟委员会FAIR数据专家组发布《推动FAIR成为现实》(Turning FAIR into Reality),提出了“FAIR生态系统”(FAIR Ecosystem)和“FAIR数字对象”(FAIR Digital Objects)的概念,计划通过3个步骤、15个优先实施建议(Priority Recommendations)来建设实现FAIR所需要的政策、文化、技术、评价、激励以及资助环境。《推动FAIR成为现实》形成了FAIR发展路线图,并把FAIR评估(FAIR Assessment)作为FAIR生态系统的重要组成部分,这也成为众多社区推动FAIR实施的出发点。
各方在积极推动FAIR落地的过程中都意识到,FAIR原则只提出了一个理想化的目标,其内容是高度概括性的,没有规定任何特定技术、标准或实施方案,而是描述了一系列特性、属性和行为。这种模糊性导致了对FAIR原则的主观、泛化解释与应用,对部分属性的理解也变得不清晰。同时,出于不同需要,不断有机构声称其资源和服务已实现FAIR。基于此,为了让FAIR评估更加规范化、正规化,一些机构相继推出自己的FAIR评估指标(FAIR Assessment Metrics)建议,并逐步应用于社区。
2 国际主要的FAIR评估模型
FAIR评估是指通过评估指标、评估工具与评估方法的建设与应用,了解被评估对象符合FAIR原则的程度,并制定相应的政策。2017年,Wilkinson等成立了FAIR指标小组。该小组对于FAIR评估的贡献在于:①于2018年7月提出了一套FAIR评估模型——FAIRness Maturity Indicators(MI)[5],见表2,主要包含了14个评估指标、指标编码规范等;②于GitHub发布了问卷模板[6],用于搜集社区及业内人员对评估模型的意见;③形成了一套用于自动评估的技术框架。MI是最早的FAIR评估模型。在此之后,荷兰数据存档与网络服务(DANS)[7]、澳大利亚研究数据共享组织(ARDC)[8]、RDA、促进欧洲FAIR数据实践项目(FAIRsFAIR)、EOSC都相继推出了自己的评估指标体系和评估工具。鉴于评估模型的完整性、可用性以及对后续工作影响力等因素,选取RDA、FAIRsFAIR和EOSC的评估指标模型进行介绍。
2.1 RDA FAIR数据成熟度模型
RDA FAIR评估工作组成立于2019年1月。2020年上半年,工作组推出了FAIR数据成熟度模型(FAIR Data Maturity Model,FDMM)。模型由评估指标、指标成熟度以及评估方法(工具)3个部分组成。
2.1.1 评估指标
FDMM设置了41个评估指标。相对于MI,细化了对15个属性的评估内容,大大增加了评估指标的数量,其中可发现原则包含7个指标、可访问原则包含12个指标、可互操作原则包含12个指标、可重用原则包含10个指标。除了增加指标数量,FDMM还细化了指标编码规范,区分属性元数据与数据,内容更加完整。后续FAIRsFAIR和EOSC也延续了这样的编码规范。
2.1.2 指标成熟度
为每个指标赋予成熟度是FDMM的创新之处。指标成熟度实际上就是工作组基于当前社区发展情况所给出的特定指标的可用程度。FDMM使用了核心(Essential)、重要(Important)、有用(Useful)来衡量指标成熟度:如果数据不满足核心指标要求,则数据在相应属性上没有实现FAIR;如果数据满足重要指标要求,则数据整体的FAIR水平较高;有用指标能够发挥特定作用,但不是必不可少的。
由表3可以看出,这三类指标在4个FAIR原则中的分布也是不平均的[9]。RDA认为大部分数据已实现可访问,因此在可访问原则方面设计了8个核心指标。而对于可互操作原则,RDA认为该原则是目前FAIR原则中最难实现的,毕竟互操作是不同主体间(平台、系统、服务)的开放行为。因此,在FDMM中,可互操作原则方面没有核心指标。
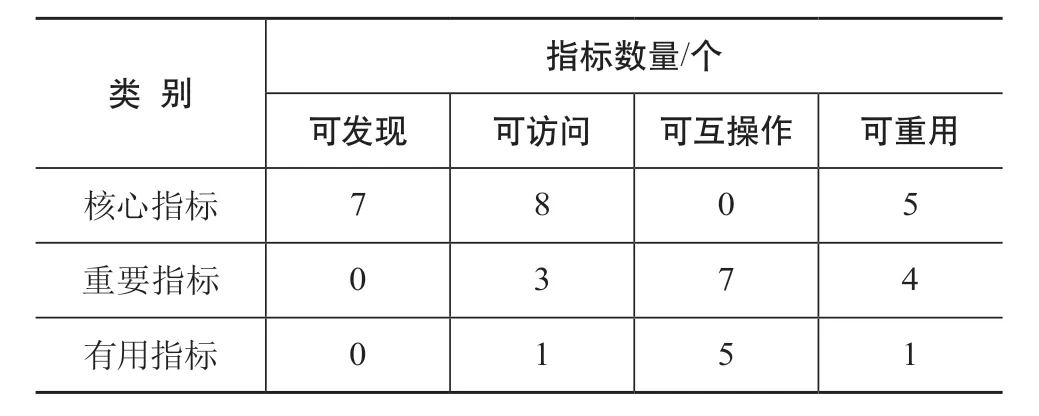
表3 FDMM评估指标分布
对于评估方法,RDA认为最终的发展方向肯定是面向机器用户的自动评估。但是目前来看,无论是从对FAIR数据管理的接受程度,还是从评估模型的成熟情况来看,完全的自动化评估都只是遥远的目标。当前可以开展的相关工作是采用问卷等方式了解各类机构和社区数据管理的实际情况。
2.2 FAIRsFAIR数据对象评估指标
FAIRsFAIR旨在为整个研究数据生命周期中FAIR原则的落地提供切实可行的方案。FAIRsFAIR聚焦于制定FAIR认证的全球标准,希望为欧洲研究数据服务机构和存储库提供实施FAIR原则的平台[10]。
FAIRsFAIR数据对象评估指标(FAIRsFAIR Data Object Assessment Metrics,FDOAM)是FAIRsFAIR在FAIRdat、FAIREnough、WDS/RDA数据评估清单、CoreTrustSeal以及FDMM的基础之上建立的一套FAIR评估指标模型[11]。FAIRsFAIR采用了快速迭代的方式来更新指标模型,从2020年2月25日—10月12日,该模型已经更新到第4版(Version 0.4)。相应地,指标数量也从13个增加到了17个。表4所示为FAIRsFAIR对特定指标的说明示例[11]。

表4 FDOAM评估指标示例
由于FDOAM 聚焦FAIR原则在可信存储库中的应用,FAIRsFAIR在制定评估指标的时候也希望能够与CoreTrustSeal进行映射。CoreTrustSeal是一套面向存储库的认证体系,目标是推广可持续和值得信赖的数据基础架构。CoreTrustSeal认证规则和管理工具从3个维度、16个角度对存储库进行评估。
FAIRsFAIR对RDA FDMM的指标进行了合并、修改和调整[12],设置了17个评估指标。例如,FDMM中有RDA-F1-01D和RDA-A1-03D两个指标,分别定义为“数据由持久标识符标识”和“数据标识符能够解析到一个数据对象”。FAIRsFAIR将这两个涉及持久性和可解析性的指标进行了合并,形成了FsF-F1-02D 指标——“数据被分配一个持久标识符”。再比如,FDMM中的RDA-F2-01M指标定义为“提供丰富的元数据从而让数据能够被发现”,FAIRsFAIR明确了其定义内容,制定了FsF-F2-01M指标——“元数据包括描述性核心元素(创建者、标题、数据标识符、发布者、发布日期、摘要和关键字),以支持数据可查找性”,更加便于后续评估。
在评估实践上,FAIRsFAIR基于FDOAM开发了评估工具F-UJI,并测试了5个CoreTrustSeal认证存储库的数据集。另外,虽然FDOAM没有对指标的成熟度进行深入的探讨,但是通过其对FDMM指标的取舍,也可以看出FDOAM对指标的筛选意识。
2.3 EOSC FAIR评估指标
EOSC是欧盟开放科学的一项重要基础设施,其定位是基于可信的、开放的虚拟云环境存储、共享和重用数字对象。《EOSC 2019—2020年实施计划》(EOSC Work Plan 2019-2020)提出“通过定义EOSC服务开发相应要求来实现FAIR原则,以提升交叉学科数据互操作性”[13]。2021年,欧盟发布《EOSC FAIR指标建议》(Recommendations on FAIR Metrics for EOSC)、《EOSC互操作框架》(EOSC Interoperability Framework)。由此可见,EOSC对实施FAIR的需求是非常强烈的[14]。
在制定FAIR评估指标时,EOSC没有另立门户,而是积极联合FAIRsFAIR、RDA等国际组织和机构开展FAIR评估方面的研讨会、咨询会,汇总各方意见和建议,并在FDMM中选择了26个指标作为后续开展评估的基础[15]。同时,EOSC工作组提出了两个重要的理念。首先,与RDA不同,EOSC基于自身建设需要,着重考虑可互操作原则方面指标的完善与实施。毕竟,如果资源与服务不能互操作,那么知识的“泛在”与“开放”将无从谈起。其次,EOSC认为FAIR评估指标的制定是一个动态的、发展的过程,需要根据社区、学科对FAIR等理念的认同情况来调整和审核指标。基于此,EOSC提出了一些在若干年后可能需要新增的指标,同时表示,每隔一段时间应该对指标与社区需求的匹配度进行评估。这些理念都将会对FAIR评估工作起到整体推动作用。
2.4 FAIR评估指标对比分析
RDA、FAIRsFAIR、EOSC在研究数据共享的大环境下,基于各自的需求与理解,推出了不同的FAIR评估指标,并开展了评估实践。FAIR评估模型是各方对FAIR原则研究与实践的阶段性成果,是FAIR生态系统的重大进步,为FAIR评估工具的实施打下了牢靠的基础,也为FAIR与类似原则或模型的整合提供了更多的可能。
目前还很难对这些FAIR评估模型进行比较。首先,对FAIR原则中的一些概念仍然存在不同的解释[16],概念的模糊必将导致属性内涵的不确定性。其次,FAIR原则是一种普适性的、跨学科领域的框架,因此FAIR评估是一个非常复杂的过程,涉及不同类型社区的数据、元数据、服务模式、管理政策以及数据隐私等,在建设与实施FAIR评估模型时需要充分考虑这些因素。
FAIR各原则彼此相关又相互独立,因此在评估的时候可以针对被评估对象的不同情况,组合不同原则和属性进行评估,并逐步把越来越多的属性纳入评估过程。
3 国际主要的FAIR评估工具
FAIR原则说到底是一套规范,而这些规范的实施程度可通过FAIR评估工具来衡量。FAIR评估工具是包含评估方法、评估模型、评估结果的代码集合,其通用流程如图1所示。

图1 FAIR评估工具通用流程
3.1 评估方法
评估方法主要是指人工评估(Manual Assessment)和自动评估(Automated Assessment)[17],基于这两类评估方法形成了两类评估工具。人工评估工具主要表现为调查问卷。通常来说,调查问卷对每个原则设计几个问题。为了避免开放式问答,问卷还会设计相应的答案选项。用户回答完毕后,问卷汇总结果,得到一个分数来表示特定机构或者特定平台数据管理FAIR化的现状。目前自动评估工具多以在线平台或命令工具的形式存在,按“输入(元)数据标识符—收割(元)数据—分析(元)数据—生成报告”的流程工作[10]。
人工评估方法的优点在于设计与实施的流程较为简单,问卷只需要确定需要评估的指标并且针对指标提出对应的问题。但是问卷是宏观性的,只能大体衡量数据管理主体的情况,而无法涉及(元)数据本身的一些细节,比如所用的词表、元数据的数量等,这就会造成信息的遗漏和丢失。自动评估方法的优点是能够针对每个数据集进行精准评估,并且能够对大量的数据开展批量评估,而其缺点就是开发周期长,并且对评估工具的灵活性有较高的要求。因此,这两类评估方法各有所长。
3.2 评估模型
评估模型包含评估工具所要测试的FAIR评估指标及实现方法,评估模型的设计和选择决定了评估工具功能强大与否。不同评估工具所选取的评估模型很有可能是不同的,而同一个工具为了适应不同的需求,也有可能嵌入多个模型。即使评估工具采用了相同的评估模型,也会因为评估方法不同而可能呈现不同结果。此外,由于算法的不同,不同的工具在相同的评估指标上,对同一个数据集可能形成相互矛盾的评估结果。不同学科领域对于数据管理与数据开放的理解和需求在客观上就存在着很大的差异,这也会使得同一个评估工具在实施不同领域的数据评估时会采用不同的评估模型以及实现算法。同时,FAIR各原则内容存在重叠,“可重用的标准可以毫无问题地被其他3个原则的标准描述,因此前3个原则分数的平均值可以作为可重用的分数”[18]。目前,FAIR评估工具的设计和开发者也意识到了这一点,收集大量的反馈意见,并根据FAIR评估的最新发展以及用户建议优化甚至重新设计评估工具。
3.3 输入输出
评估工具的输入是指用户根据提示提供给工具的各类信息。在人工评估时,用户通过回答问卷问题向评估工具提供信息,形式有单项选择、多项选择、自评分等。自动评估工具则通常让用户提供数据的标识符,如PID、GUID、URI等。FAIR评估工具的输出内容详略不一,通常有4类:第一类输出是问卷对用户提交答案的统计和计算结果,主要是数字或者百分比;第二类输出在常规输出之外,还包含一些改进建议,例如DANS的SATIFYD工具提供优化建议(见图2);第三类输出是自动评估工具提供的对特定数据集检测结果的反馈以及过程性分析信息(见图3);第四类输出在文字信息之外,还提供一些可视化的图表来让输出结果更易于分析。
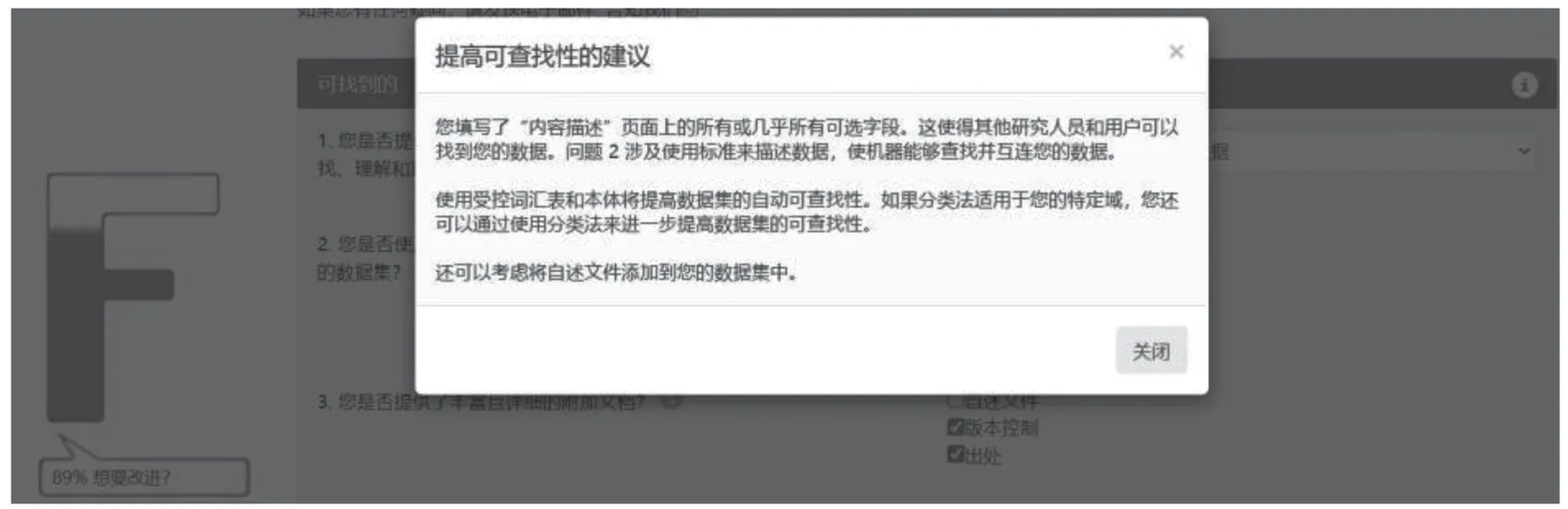
图2 SATIFYD评估结果优化建议信息

图3 FAIR evaluator评估反馈结果
3.4 FAIR评估工具总结
有代表性的FAIR评估工具如表5所示,目前尚处在起步阶段。工具主要来自两类机构:第一类是对于数据管理和服务有较高要求的数据中心;第二类是面向社区,在开放数据领域制定标准规范的组织机构。这些机构把自身对FAIR的理解融入软件工具,并逐步开始在一些社区实践,在促进数据开放共享、提升数据质量和数据可重用性方面取得了一些成绩,也提供了一些有价值的经验和教训。同时,这些评估工具展现出了极好的开放性,这表现为几乎所有的评估工具都开放源代码,并且所采用的开源协议也给使用者留下了很大的发展空间,使用者能够基于现有的功能进行扩展与优化。理论化的FAIR原则落实到具体化的FAIR评估工具,这是一个进步,也是一种必然,毕竟FAIR原则是面向研究数据管理这一理论与实践并重的领域而产生的,它也必须要在这个领域充分发挥作用,形成社会与经济的双重效益,从而为更广泛范围内的用户所接纳。
当然,FAIR评估工具目前仍然存在较大的提升空间。首先,最为突出的问题就是缺少统一的评估模型和实现算法,无法对不同工具的评估结果进行对比和分析,对同一对象的评估结果可能相互矛盾。众多机构需要共同确定统一的评估模型,形成“负熵”因素,降低混乱程度。其次,目前的FAIR评估工具的规划与开发还没有商业公司的参与,因此评估工具的界面美观性、用户亲和度以及定制灵活性不足。毕竟FAIR评估后续会有极为广泛的应用领域,涉及海量数据,商业机构的介入能够较好地提升软件工具的规范性、易用性和稳定性,让评估工具的用户从图书馆员、数据管理员、IT技术人员扩展到数据管理机构、数据发布机构人员甚至科研人员。再次,FAIR评估工具要在各个社区中发挥作用。因此,评估工具也必须更多地满足社区对研究数据管理和开放服务的需求,并通过实践来检验自身的可用性、易用性、稳定性、灵活性和完备性,形成更多的评估最佳实践。最后,FAIR评估工具内嵌了FAIR原则及指标。用户如果不了解工具中的FAIR内容,将无法很好地实施评估,同时也无法很好地对评估结果进行分析和解读。因此,还需要继续加大在各个领域、社区中对FAIR原则的宣传、推广与实施力度,从侧面有力推动FAIR评估工具的应用。
4 对FAIR评估发展的思考
从最初的评估理念到指标框架再到不同类型的评估工具和实践案例,FAIR评估已经逐渐成为数据管理和共享领域中的重要措施,越来越多的机构、社区和学者开始关注和使用FAIR评估体系。以下是笔者对于FAIR评估发展的一些思考。
4.1 FAIR评估的标准化
虽然FAIR原则被广泛认可,但是对于每个原则与属性的具体实现方式仍存在不同的解释和理解,缺乏共识可能会影响实施和推广。FAIR评估标准化有两方面的含义:首先是评估指标的标准化,虽然权威机构已经相继推出不同的FAIR评估指标体系,但是这些评估体系在指标的数量、内涵以及权重上都有所差异;其次是评估工具的标准化,评估工具在输入输出、工作流程、计算方法以及评估结果方面也都呈现不同的特征。要提高FAIR评估的标准化水平,就要从评估指标的标准化入手:首先,对比不同机构的评估指标,找出共同点和差异点,确定需要协调的内容;其次,对评估指标进行整合,将评估指标整合到一个共同的框架中,同时确保其与FAIR原则的一致性;再次,与研究者、出版商、政策制定者、数据存储机构等利益相关方讨论,以确保评估指标能够满足其需求,并提供实际的支持和帮助;最后,组织利益相关方定期审查和更新评估指标,以确保其与最新的技术和实践保持一致。
4.2 FAIR评估与社区的关系
逐步完善的FAIR评估体系是FAIR原则得以落地,与研究数据管理紧密融合的重要保障,这也是RDA、EOSC等以数据为研究核心的机构着手开展FAIR评估研究的原因。然而,有了评估体系还不够。目前FAIR评估体系独立于社区,其工作侧重于“评估什么”。而社区是产生、管理与应用研究数据的主体,并且不同类型的社区在发展特点、数据建设周期以及数据开放程度方面都存在较大差异。因此,需要通过“FAIR下社区”来检验评估体系,回答“怎么评估”的问题:通过下社区来检验评估体系的合理性、完备性、可用性、易用性等;通过下社区建立灵活的评估机制,为不同的领域建立不同的评估模型。具体包括以下措施。
(1)联合社区,共同推进。在评估体系建立之初就联合社区力量,引进社区思想,了解社区的实际发展状况和需求,与社区共同制定适合研究特点的FAIR评估指标。
(2)建立长期、活跃的社区FAIR组织。组织成员可以是FAIR评估人员、研究人员、数据管理人员、领域专家或数据使用者,能够代表学科领域内的不同利益相关者。通过这个组织向社区持续宣传和推广FAIR原则与FAIR评估的理念,逐步建立FAIR信任机制,并获取反馈,确定FAIR评估工具的缺陷和改进方向,不断更新和优化评估体系。
(3)与社区共同实施评估。评估应该是一个协作的过程,由评估人员和社区成员共同实施。评估人员可以为社区成员提供技术支持,帮助他们实施评估指标和工具,并与他们一起分析评估结果,提出改进建议,帮助数据管理者证明自己的数据符合FAIR原则,从而提升数据整体的可信度和可重复性。
4.3 FAIR评估国际化发展
当前,FAIR及FAIR评估的发展有较为明显的地缘特征。欧洲是开放科学发展最为迅速和活跃的地方,开放科学孕育了FAIR理念。目前主要的评估指标、评估方法以及评估工具来自于欧洲国家或者与欧盟密切相关的国际组织。大洋彼岸的美国也逐渐开始正视FAIR原则的作用和影响,美国国立卫生研究院(NIH)于2020年10月推出了《数据管理和共享政策》(Final NIH Policy for Data Management and Sharing),鼓励符合FAIR 原则的数据管理和数据共享实践,倡导和协调与FAIR原则相关的活动,通过协作项目、研讨会等来增强FAIR教育。2023年初,NIH发布了一项研究计划“支持现有数据存储库跟进 FAIR 和 TRUST 原则并评估使用情况、效用和影响”[29],其目标是加强由 NIH 资助的生物医学数据存储库的可发现性、互操作性和重用性。
研究数据的开放与共享是一项世界范围内的工作。因此,FAIR及FAIR评估的发展需要面向更加国际化的环境。要组建国际合作团队,联合开展FAIR评估相关研究和实践项目,共同制定FAIR标准和指南;通过举办国际研讨会的方式邀请来自不同国家和地区的专家学者分享经验和最佳实践,加强交流合作;通过开展技术交流和人才培训等活动,促进FAIR相关技术和知识的传播和应用,推动更大范围通用的FAIR评估指标和评估工具的建设与实践。
综上所述,目前虽然一些机构(RDA、EOSC等)已经开展FAIR评估实践,但是广泛开展基于FAIR原则的数据管理与服务评估是一个长期的过程,需要数据生产者、管理者、服务者以及第三方机构协同推进。EOSC把FAIR评估的发展比作一场旅行[15],这场旅行中的每个阶段有不同的任务。应该随时调整方向,保证最初的目标得以实现,即“良好的数据管理不是目标,利用数据的开放推动知识发现、技术创新以及数据与知识的融合才是最终的目标”[4]。
