基于数据特征的配电网同期线损异常辨识方法
2023-11-09肖光旭岑炳成陈泉朱丹丹黄成
肖光旭, 岑炳成, 陈泉, 朱丹丹, 黄成
(1.国网江苏省电力有限公司南京供电分公司,江苏,南京 210019; 2.国网江苏省电力有限公司电力科学研究院,江苏,南京 211103;3.国网江苏省电力有限公司,江苏,南京 210024)
0 引言
目前我国电力公司使用的基于一体化电量与同期线损管理体系,致力于提高电力公司管理效率,避免电路故障发生。然而,就目前配电网运行情况来看,实际线损值相比于理论值来说差异较大。配电网同期线损管理依托全覆盖信号采集模式,以供、用电在线监测为核心,重点研究同期线损变化,使系统建设和运行控制变得越来越重要。为此,对配电网同期线损异常辨识对于优化配电网结构具有实际意义。
目前相关领域学者对配电网同期线损异常辨识进行了研究,并取得了一定的研究成果。文献[1]提出了基于孤立森林算法的判定方法,该方法首先使用k-means算法聚类不同负载工况,然后采用孤立森林算法计算异常分数,最后对异常数据进行阈值对比,得到最终判断结果,该方法具有较高的可靠性。文献[2]提出了基于负线损分析的辨识方法,首先应确定计量数值前后线损的变化情况,然后结合分析结果进行故障辨识,最终得到负线损超标原因,该方法具有一定的有效性。但上述方法的聚类中心相距较近,使得特征向量无法聚类,导致同期线损异常辨识结果不精准。针对上述问题,提出了基于数据特征的配电网同期线损异常辨识方法。
1 配电网同期线损数据近似相等特征分析
由于配电网同期线损数据较多,导致实际运行所产生的同期线损数据与理论数值存在一定偏差,该偏差数值具有随机性和分散性,分布在零值附近的区域内,因此差值序列也被称为秩值。秩值是呈对称关系的,因此,正“秩和”与负“秩和”绝对值近似基本一致。
正“秩和”与负“秩和”概率密度随误判概率变化情况,如图1所示。

图1 正“秩和”与负“秩和”关系示意图
由图1可知,以线损电量为例,对线损电量、输入电量和输出电量中“秩和”差异特征存在的位置为例,进行详细说明:
(1) 在获取的所有配电网同期线损数据中,部分数据为零值数据,正常数据减少,为了保证总的线损数据量不变,实际辨识向量与理论辨识向量之差为负值,即为负“秩和”[3]。
(2) 在获取的所有配电网同期线损数据中,部分数据为恒值数据,此时无法获取精准实际辨识向量与理论辨识向量之差,即无法确定秩值的正负。
(3) 在获取的所有配电网同期线损数据中,部分数据为突变数据,正常数据减少,为了保证总的线损数据量不变,实际辨识向量与理论辨识向量之差为正值,即为正“秩和”[4]。
基于上述内容可知,在获取的所有配电网同期线损数据中,部分数据为突变数据,则正“秩和”与负“秩和”相差较大;在获取的所有配电网同期线损数据中,全部数据为正常数据,则正“秩和”与负“秩和”近似相等。基于该特征,对同期线损异常数据辨识。
2 基于数据特征的配电网同期线损异常辨识方法
2.1 配电网同期线损异常情况分析
结合正“秩和”与负“秩和”概率密度,确定配电网同期线损异常因素,以此为导向,设计配电线路同期线损分析流程,实现配电网支线动态管控。配电线路同期线损分析流程如图2所示。
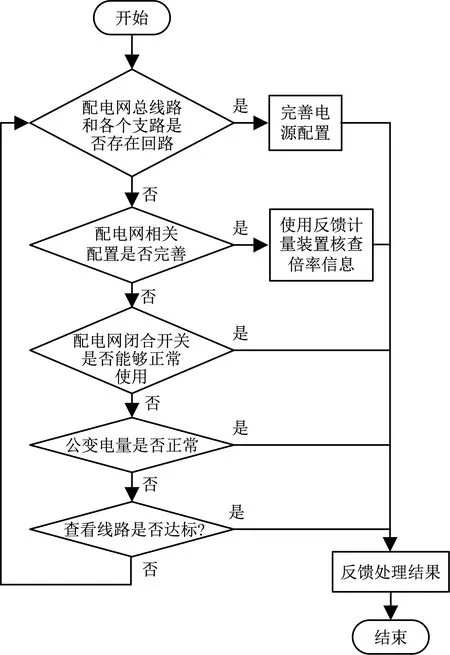
图2 配电线路同期线损分析流程
由图2可知,首先应查看配电网总线路和各个支路是否存在回路,如果是,则配电网线路正常;反之,则线路异常,查看配电网相关配置是否完善。如果配电网相关配置不完善,那么应先完善电源配置,查看配置反馈结果,并返回到支线上查看线路是否允许电流通过;如果配电网相关配置完善,那么应先检查配电网闭合开关是否能够正常使用[5]。如果不正常,使用反馈计量装置核查倍率信息,查看核查结果,并循环检查各个线路是否允许电流通过;如果配电网闭合开关能正常使用,那么应先检查线损变化数值是否与现场采集到的数值一致[6]。如果存在误差,则将结果反馈给运维检查部门进行现场维护;如果数值一致,则将检查公变电量是否正常。如果不正常,则需核查用电情况,并检查支线线路上是否允许通多电流;如果正常,则需查看线路是否达标,如果达标则直接反馈相关结果。反之,则需重新判断该线路是否存在回路,由此完成配电网同期线损异常情况分析。
2.2 基于近似相等特征的同期线损负荷聚类
通过分析配电线路同期线损所经过的各个环节,需对同期线损负荷进行聚类处理。聚类是将每个环节所产生的特征向量聚在一起的过程,确定一个中心点,根据数据密度计算特征向量中容易出现聚类中心点的概率[7-8]。因为在聚类中心附近存在较高的密度数据点,所以在选择第一个聚类中心后,继续寻找下一个节点,直到所有节点成为聚类中心的可能性小于设定的阈值。
设输入的n个特征向量为a1,a2,…,an,每个特征向量都可以作为聚类中心,由此构造的表征向量ai密度指峰函数如下:
(1)
式(1)中,r表示数据点的邻域半径。根据各个数据点密度计算结果,确定该点的领域点,即具有最高密度的数据点。
基于近似相等特征的同期线损负荷聚类过程,持续到剩下的其他节点成为聚类中心的可能性小于设定的阈值即可,由此终止聚类,避免出现相距较近的聚类中心,实现数据特征向量聚类。
2.3 配电网同期线损异常辨识流程设计
根据负荷聚类结果,设计配电网同期线损异常辨识流程,如图3所示。
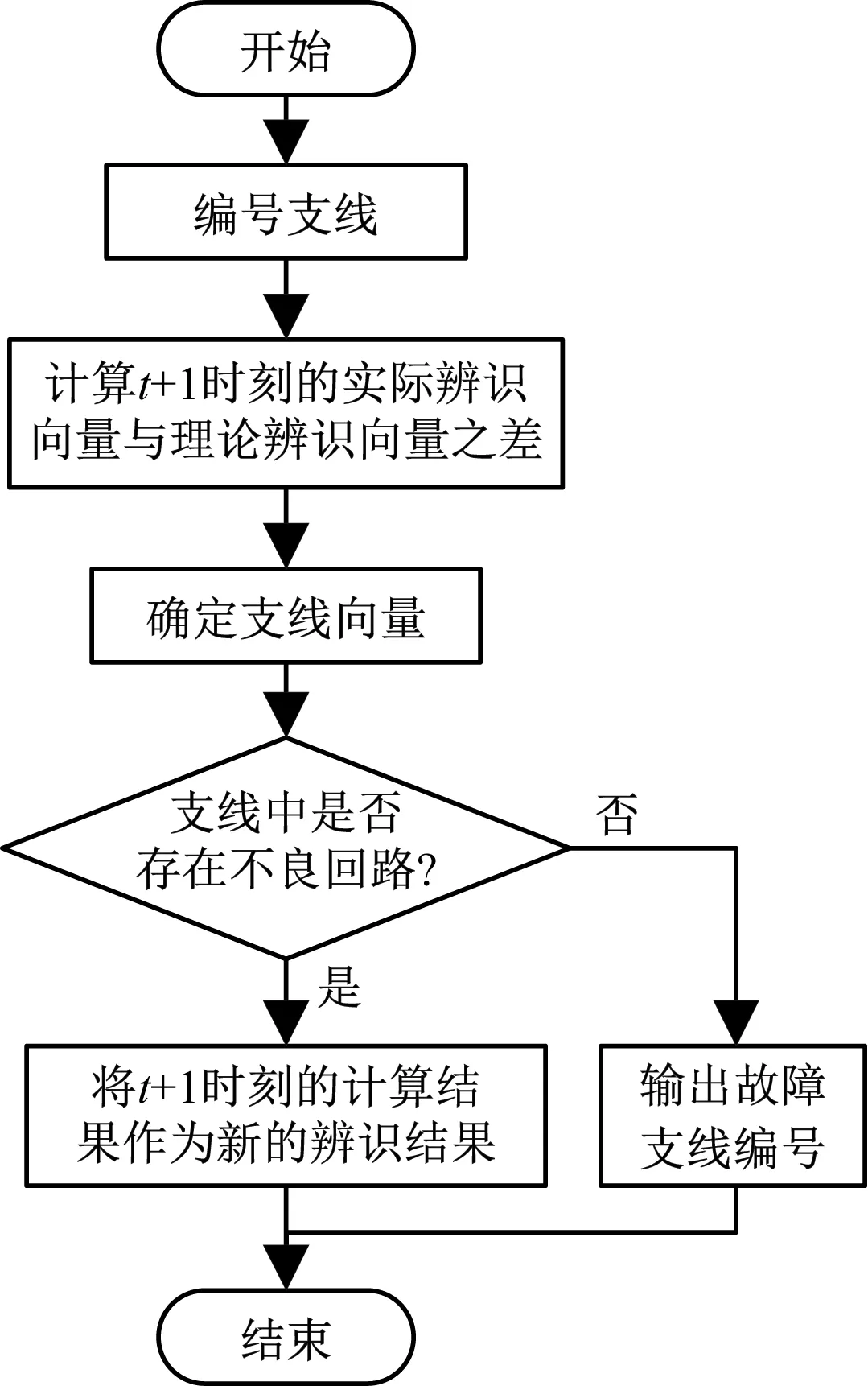
图3 配电网同期线损异常辨识流程
由图3可知,其具体操作流程如下。
步骤1:构建拓扑结构,简化基本参数,并对各个支线进行编号处理[9];
步骤2:构建配电网网络结构,确定支线向量;
步骤3:初始化t+1时刻的配电网潮流,以此作为量测值,根据如下公式计算实际辨识向量与理论辨识向量之差:
α=nt+1-mt+1
(2)
式(2)中,nt+1表示t+1时刻的实际辨识向量,mt+1表示t+1时刻的理论辨识向量。
步骤4:根据计算结果,判断配电网线路中是否存在不良回路,如果有,则转到下一步,否则到步骤7;
步骤5:检查不良回路中是否存在大于实际辨识向量与理论辨识向量之差的值,如果没有,则反馈支线编号。反之,则转到下一步;
步骤6:将t+1时刻的计算结果作为新的辨识结果;
步骤7:构建关联矩阵,计算支线上实际辨识向量与理论辨识向量之差。
如果在关联矩阵模型图中,每条边都确定了一个正方向,那么经过确定方向的关联矩阵模型图被称为定向图。因此,通过对电路各个定向支路和回路关系分析,可描述定向图[10]。给定一个定向图,该图中存在k条支线,g个回路。规定每个回路正方向,描述所有回路和各个支线之间关系,设E表示回路编号,W表示支路编号,那么支线数量为:当支路编号中包含了全部的回路编号,且回路和各个支线的方向一致,此时支线数量是1条;当支路编号中包含全部的回路编号,且回路和各个支线的方向相反,支线数量是2条;当支路编号中不包含全部的回路编号,支线数量是0条。
支线上实际辨识向量与理论辨识向量之差,计算公式为
Δα=n′-m′
(3)
式(3)中,n′表示支线上实际辨识向量,m′表示支线上理论辨识向量。
当配电网正常运行时,实际辨识向量与理论辨识向量之差为0,可以忽略;当配电网异常运行时,实际辨识向量与理论辨识向量之差不为0,根据分析的非0数值可以对不良数据进行初步辨识。然而,由于实际辨识过程中,也可能存在不良数据,因此,必须通过计算支线上实际辨识向量与理论辨识向量之差,判断所有数据中是否含有不良数据。
步骤8:基于差值计算结果形成的不良回路中,存在大量支线数据,说明辨识结果为对应的支线故障辨识结果,由此完成配电网同期线损异常辨识。通过上述流程可知,构建的配电网网络拓扑结构,简化基本参数,确定支线向量,该辨识方法能够有效降低时间复杂度。
3 实验分析
3.1 配电网基本情况
为了验证基于数据特征的配电网同期线损异常辨识方法的有效性,结合江苏电网同期线损作业情况,利用配电网同期线损异常辨识流程,验证线损异常辨识情况。首先,构建节点系统网络拓扑结构,并对各个支线进行编号处理,确定支线向量,节点系统网络拓扑结构如图4所示。

图4 节点系统网络拓扑结构图
由图4可知,该系统包含了11个节点,其中,节点0是发电源点,其余节点为负荷节点。然后,初始化配电网潮流作为量测值,根据式(2)计算实际辨识向量与理论辨识向量之差,进而判断配电网线路中是否存在不良回路。最后,忽略各条支路线损情况,系统在正常运行状态下,将这些接地支路作为独立回路连接,并在两个节点之间增设树支,此处的回路相当于电流。系统的独立回路构成,如表1所示。
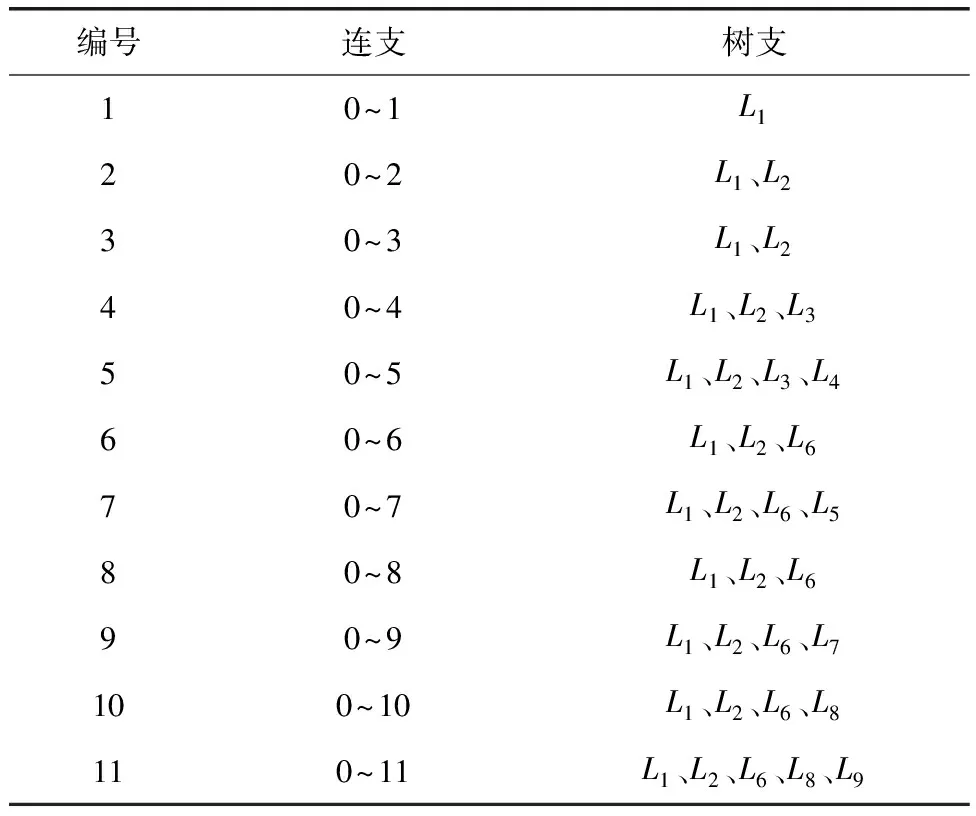
表1 系统独立回路构成
根据配电网环境,对异常数据进行辨识。其中,异常数据主要包括线路损耗、配变损耗等数据。该数据的分布较为复杂,且初始数据不易收集。
3.2 待辨识故障数据分析
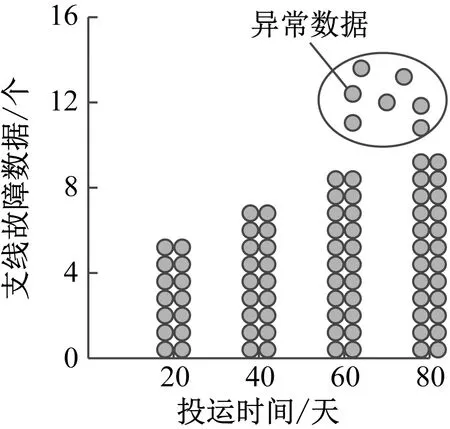
配电网在投运初期,从0节点到8、9、10、11节点过程中进行数据传输容易出现故障问题,因此绘制在不同情况下的待辨识故障数据,如图5所示。
(a) 0~8节点
由图5可知,当配电网投运初期,各类故障数据特征变量值变化较为规律情况下,出现了处于数量较多的异常数据。如图5(a)可知,当投运时间大于60天后,支线出现了故障数量大于10个的情况;如图5(b)可知,当投运时间大于20天后,支线出现了故障数量大于5个的情况;如图5(c)可知,当投运时间大于40天后,支线出现了故障数量大于7个的情况;如图5(d)可知,当投运时间到20天时,支线出现了故障数量大于11个的情况。由此说明,随着配电网投运时间的增加,对支线故障有一定影响,因此,将这部分变量作为线损异常特征变量。
3.3 实验结果与分析
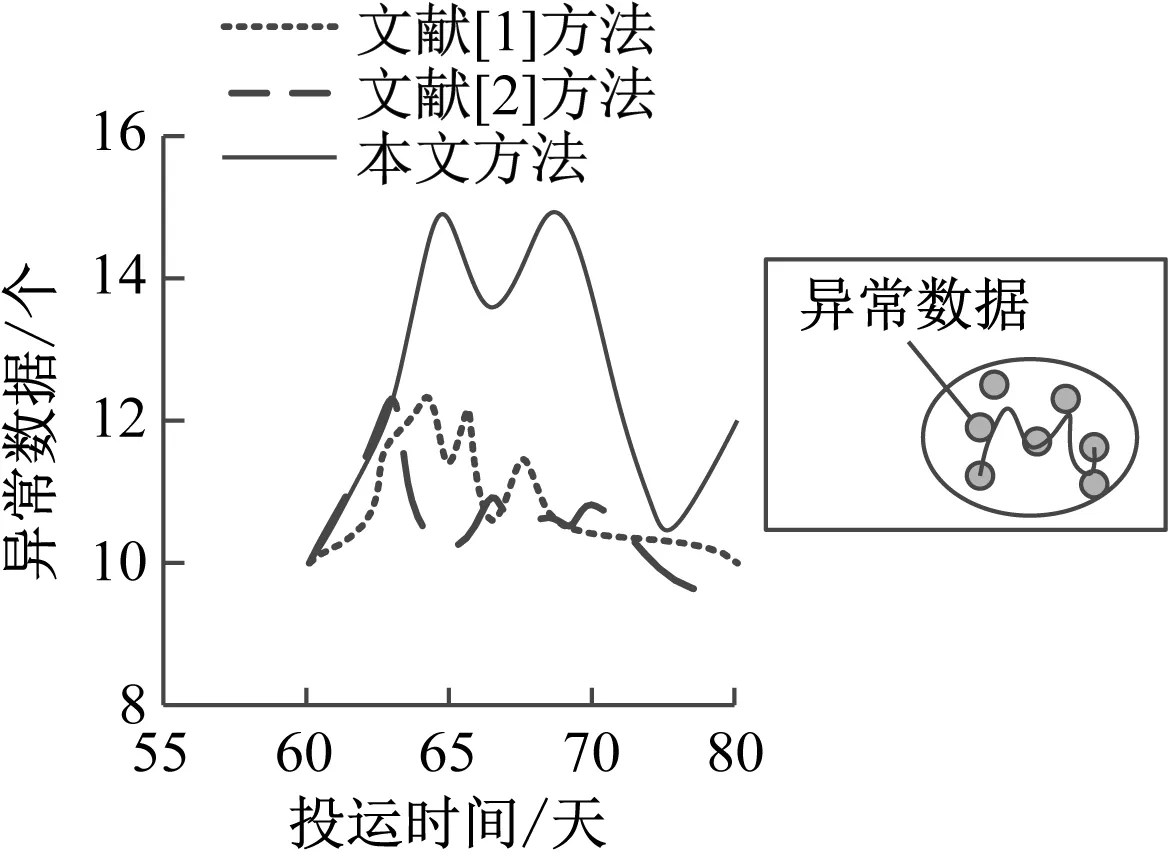
统计上述数据,分别使用文献[1]方法、文献[2]方法和本文方法进行对比,分析待辨识故障数据,如图6所示。
(a) 0~8节点
由图6可知,使用基于孤立森林算法的判定方法、基于负线损分析的辨识方法的异常数据变化曲线,与实际异常数据变化曲线不一致,尤其在0~8、0~9支线上,异常数据辨识结果与实际辨识结果相差较大。而使用基于数据特征的辨识方法异常数据变化曲线,与实际异常数据变化曲线一致,在0~8、0~9支线上,分别存在1个异常数据辨识误差。由此可知,基于数据特征的辨识方法能够有效减小异常数据辨识误差,准确辨识异常数据。
在此基础上,进一步验证所提基于数据特征的辨识方法的配电网同期线损异常辨识时间复杂度,分别使用文献[1]方法、文献[2]方法和本文方法进行对比,得到3种方法的配电网同期线损异常辨识时间如表2所示。
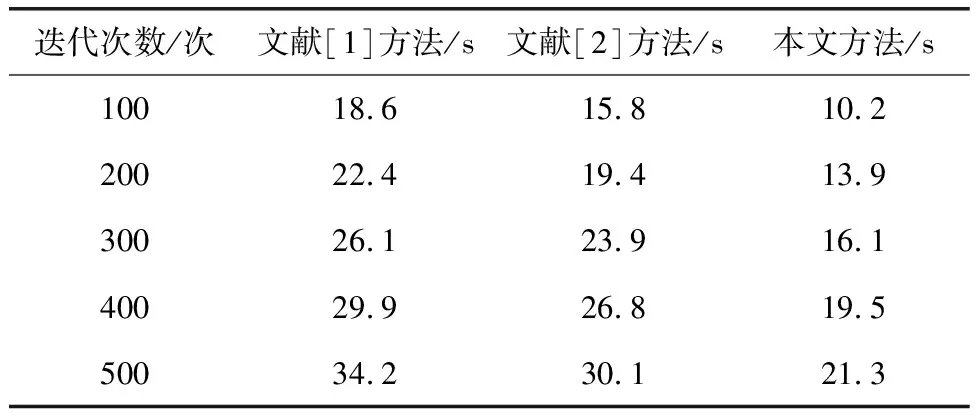
表2 3种方法的配电网同期线损异常辨识时间
从表2中可以看出,随着迭代次数的增加,3种方法的配电网同期线损异常辨识时间均随之增加。当迭代次数为500次时,文献[1]方法的配电网同期线损异常辨识时间为34.2 s,文献[2]方法的配电网同期线损异常辨识时间为30.1 s,而本文方法的配电网同期线损异常辨识时间仅为21.3 s。由此可知,本文方法的配电网同期线损异常辨识时间较短,其配电网同期线损异常辨识时间复杂度较好。
4 总结
本文提出的基于数据特征的配电网同期线损异常辨识方法,充分利用了同期线损异常数据信息,相对当前的辨识方法能够取得更加精准的辨识结果。经过实验发现,有些问题还有待解决,比如差值的边界问题,即实际辨识向量与理论辨识向量差值,一旦发生异常现象时,辨识结果不精准,有待进一步深入研究。
