基于深度学习网络实现番茄病虫害检测与识别
2023-11-09王铭慧张怀清樊江川陈帮乾
王铭慧 张怀清 樊江川 陈帮乾 云 挺,5*
(1.南京林业大学 信息科学技术学院,南京 210037;2.中国林业科学研究院 资源信息研究所,北京 100091;3.国家农业信息化工程技术研究中心 数字植物北京市重点实验室,北京 100097;4.中国热带农业科学院 橡胶研究所,海口 571737;5.南京林业大学 林草学院,南京 210037)
在番茄培育过程中不可避免地会因为种植操作不当、防治措施不到位、环境污染等各种原因发生病虫害,影响番茄品质并导致产量降低,造成经济损失[1]。据调查,我国现有危害番茄的病虫害不少于30种,流行地区日趋扩大,成为番茄高产稳产的一大障碍[2]。近年来,新型番茄流行病害有所增加,如:褪绿病毒病[3]、番茄褐色皱纹果病毒病[4]等,目前还尚未有对应的番茄抗病品种育成,一旦流行往往损失严重,因此,构建一个智能检测、识别番茄病虫害的网络,及时发现问题,做到精准防治,对保障番茄生产有重要意义。
传统的病虫害防治耗时耗力,并且会由于外部干扰和人力限制,造成判断不准确或时间上的滞后,导致病虫害防治效率不高。随着计算机视觉技术的发展,机器学习方法在病虫害识别上得到应用,并大大提高了病虫害防治效率。经典的机器学习方法有支持向量机(Support Vector Machines,SVM)[5]、K-means聚类算法[6]、朴素贝叶斯[7]等。SVM可作为2值分类器,在番茄叶片病害的检测中,将灰度共生矩阵用于特征提取然后使用SVM将提取的特征进一步分为健康叶片和感染叶片2类[8],还可以结合方向梯度直方图特征和SVM,实现对水稻病害的检测和识别[9]。K-means聚类算法可以进行图像分割,然后结合神经网络工具进行分类,从聚类中提取的7个特征,如对比度、相关性、能量、同质性、均值、标准差和方差,作为神经网络的输入,用于识别和分类病害[10]。利用朴素贝叶斯可以实现自动识别、诊断作物病害的技术和方法,构造玉米叶部病斑分类识别模块[11]。针对图像质量低、存在噪声和阴影、背景杂乱、图像纹理不同等问题,首先对不同的特征进行预处理和选择提取,然后采用多层感知器(Multilayer perceptron,MLP)集成了4种分类器:随机森林(Random Forest,RF)、SVM、逻辑回归(Logistic Regression,LR)和K-近邻(K-nearest neighbor,K-NN),对田间和实验室条件下的番茄叶片病害图像进行分类,准确率达到95.98%[12]。但是由于图像具有高维度和复杂的特征结构,在使用机器学习算法进行图像分类时,有效地对特征进行提取和表示的过程相对复杂,并且机器学习算法在处理不同角度、距离、光照条件下的同类样本时会遇到困难。
近年来,深度学习技术被广泛研究应用到各领域,其中,卷积神经网络(Convolutional Neural Network,CNN)[13]在处理多维数组数据时效果较为突出,更适合图像、视频这类数据的检测与识别,得益于其强大的学习能力、自动提取图像特征的功能,使得深度学习技术在植物病虫害识别的应用上比传统的机器学习技术更准确高效。如在传统的AlexNet[14]模型上改进,采用批归一化与全局池化相结合的卷积神经网络模型识别多种叶片病害[15]、用2个著名的深度模型AlexNet和GoogleNet[16]构建病害分类器,与需要人工处理特征的浅层模型相比,该研究结果证明了CNN模型在番茄病害分类方面具有更好的性能[17];又如轻量级多分枝残差网络(LMBRNet)通过4个卷积核大小不同的分支,提取番茄叶片不同维度和感受野的多种病害特征,兼顾了番茄叶片病害识别的准确性和速度[18]。
除了识别番茄病虫害的类别,在番茄被病虫害危害的初期检测病虫害的部位、定位病斑或害虫的准确位置,并及时做出相对应的防治措施,可有效地避免番茄种植基地病虫害大规模的爆发。根据算法的流程可以将目标检测算法分为两大类:1种是以Faster R-CNN[19]为代表的两阶段算法,先由算法生成候选框作为样本,去搜索目标以及调整边界框;另1种是以SSD(Single Shot MultiBox Detector)[20]、YOLO(You Only Look Once)[21]为代表的单阶段算法,它是直接将目标边界定位问题转换成回归问题,模型仅需处理图像1次就能得到边界框坐标和类别概率。两阶段的病害检测算法有:将区域生成网络(RegionProposal Network,RPN)架构引入Faster R-CNN算法实时检测水稻叶病害,能够非常精确地定位目标位置[22]、使用改进的Mask R-CNN结合集成神经网络检测番茄叶片病害的类型和感染区域[23]。单阶段算法如:在YOLOv5模型中加入SE(Squeeze-and-Excitation)模块,运用注意力机制提取关键特征,有效地检测出番茄病毒病害区域[24]。2种方法的区别也导致其性能不同,两阶段在检测准确率和定位准确率方面更优,但是检测速度慢;单阶段放弃了高精度,但是换来了比两阶段算法快很多的速度。1种在单阶段目标检测YOLOv3算法的基础上,改进K-means算法的玉米病虫害检测方法,实现了平均损失值下降速度与目标检测精度的平衡[25]。然而用深度学习模型进行图像检测与识别时也存在一些局限,例如需要大量的多样性的数据集进行训练,并且由于图像的拍摄角度不同导致目标姿态异常,很容易造成错误的检测识别结果。
传统的目标检测方法虽然具有分类功能但是更侧重于物体搜索,研究大多致力于对目标的定位,分类功能没有得到更好的发展,而图像分类成绩较好的一些传统CNN却只有单一的分类功能。在番茄种植管理中,需要目标检测和分类识别同时应用。因此,为了在现实应用中得到更好的检测和识别效果,以受病虫害影响的番茄植株图像为研究对象,考虑番茄病虫害目标小而密且自然背景复杂的特点,拟采用Swin Transformer[26]作为主干网络构建改进的YOLOX[27]目标检测网络,以期实现更有效的小目标病虫害检测定位,提高计算效率。此外,在传统的CNN架构中添加1个旋转不变Fisher判别层构建旋转不变Fisher判别CNN分类网络,通过在网络的目标函数上加入2个正则化约束项训练新加层,来解决病虫害图像角度不同造成病虫害形状变化的问题以及不同病虫害之间相似度过高同类病虫害特征多变的问题。通过上述研究内容为番茄病虫害的智能防治提供依据,实现病虫害目标的检测定位与分类。
1 材料与方法
1.1 番茄病虫害数据集的整理
本研究选取叶霉病(病原Fulviafulva)、早疫病(病原Alternariasolani)、灰叶斑病(病原Stemphyliumsolani)、白粉虱(Bemisiatabaci)、美洲斑潜蝇(Liriomyzasativae)和棉铃虫(Helicoverpaarmigera)6种常见番茄病虫害图像作为研究对象,研究数据集由农业病虫害研究图库(IDADP,http:∥www.icgroupcas.cn/website_bchtk/index.html)中的番茄病虫害数据集和在连云港市草舍村番茄采摘基地拍摄的图片组成,典型的图片详见图1。对采集的图片使用工具进行标注:训练数据集用于目标检测任务时只需要将目标边界框标注为“目标(Object)”1类并标注位置;用于分类任务则需要标注6种具体病虫害类别和健康植株。为了保证模型的稳定性和泛化能力,对所有图像进行了resize操作,将像素调整为224×224。

图1 6种番茄病虫害和健康番茄植株的部分图像展示
为了丰富数据集同时训练分类网络的旋转不变性,对样本进行了4次随机角度旋转操作,实现旋转数据的增广,详见图2。经过旋转操作后,图像尺寸保持不变。表1列出了训练集和测试集的数量,将每个类别采集到的样本分出200张作为测试集(采集),剩余作为训练集(采集)并对其进行旋转数据增广处理得到训练集(增广)。
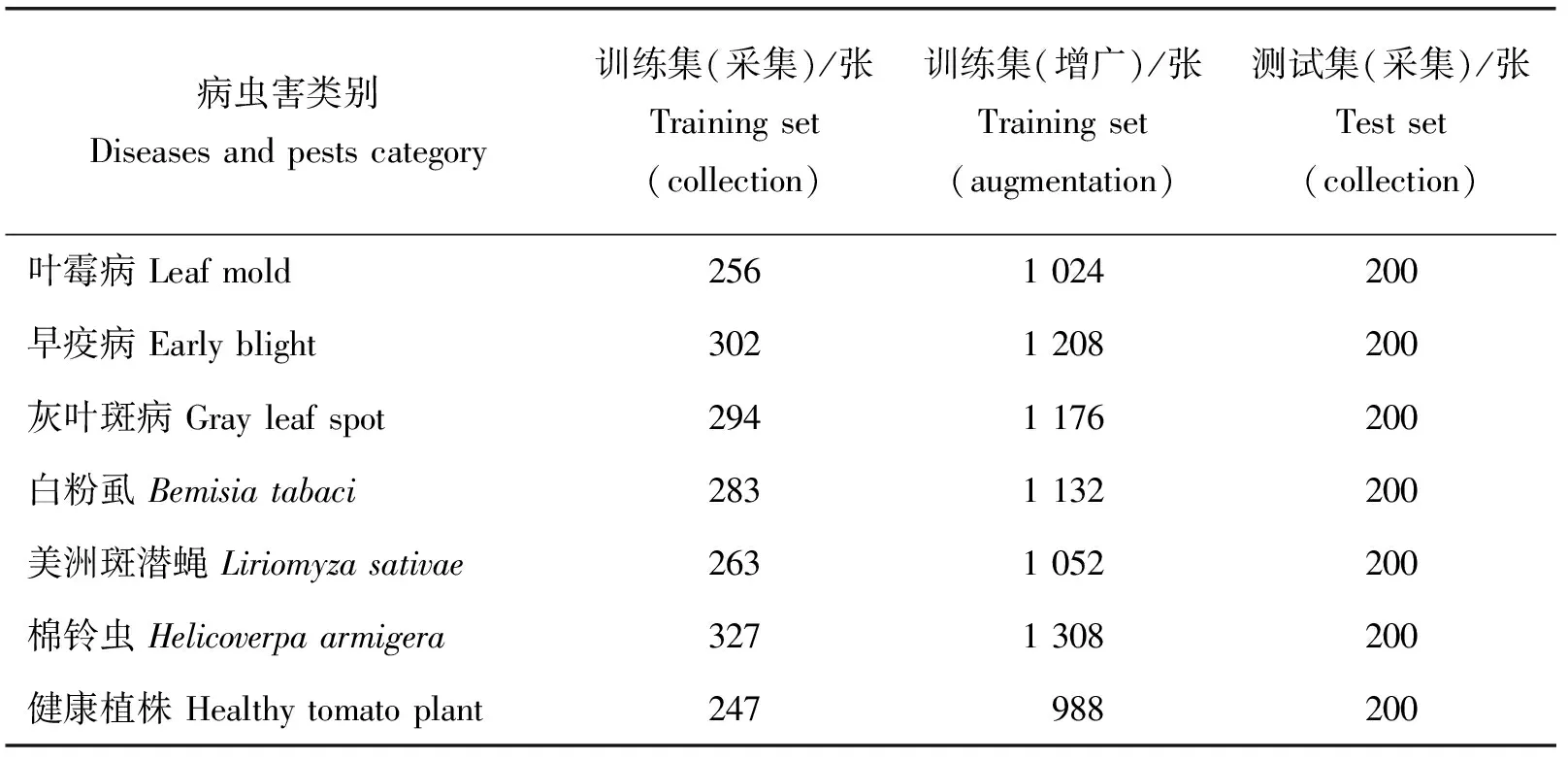
表1 番茄病虫害数据集各类别训练及测试样本数量

图2 对原始训练样本进行旋转得到增广训练样本过程示意图
1.2 番茄病虫害检测与识别的工作流程
本研究番茄病虫害检测与识别的工作流程如图3所示。该流程分为病虫害目标检测和病虫害分类识别两部分:首先基于Swin Transformer的YOLOX目标检测网络可以检测病虫害的区域并准确定位病虫害位置;然后旋转不变Fisher判别CNN网络可以对病虫害的类别具体分类。2个网络的主要作用不同,共同应用在番茄病虫害的防治中,精准控制病虫害对番茄的影响,减少损失。
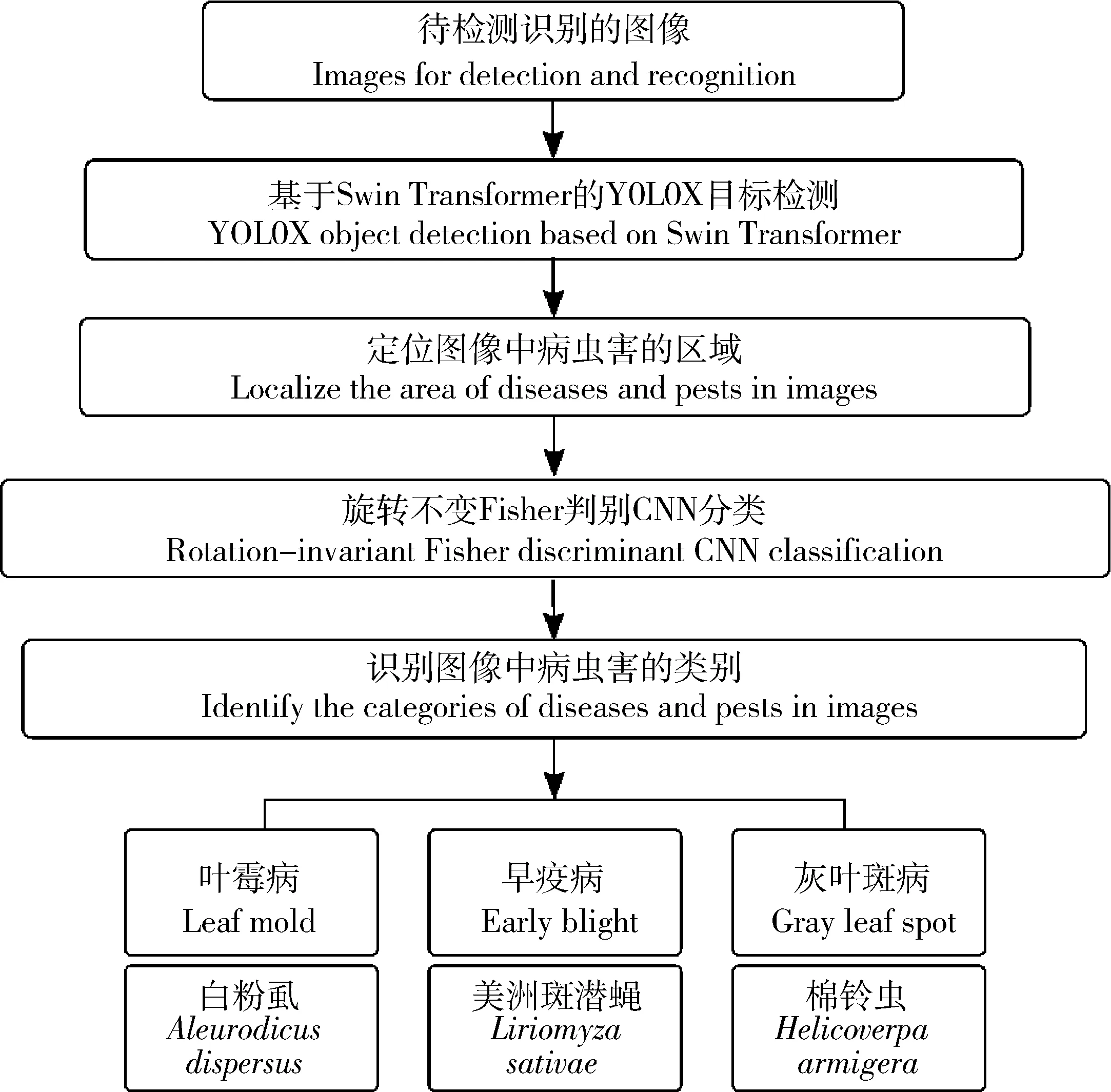
图3 番茄病虫害检测与识别的总体工作流程图
1.3 基于Swin Transformer的YOLOX病虫害检测
本研究的目标检测网络在YOLOX的基础上进行改进,采用Swin Transformer作为主干网络,Transformer[28]中的注意力机制可以综合考量全局的特征信息,Vision Transformer(ViT)[29]则将Transformer模型架构扩展到计算机视觉的领域中,Swin Transformer是在ViT的基础上使用滑动窗口(Shifted Windows,SW)进行改进,不同于ViT中固定大小的采样块,Swin Transformer按照4、8、16、32倍下采样分成4个阶段,用窗口(Window)来划分特征图,每一个窗口独立运算从而提高计算效率。同时将双向特征金字塔网络(Bi-Directional Feature Pyramid Network,BiFPN)[30]作为新的特征融合模块代替原来的路径聚合网络(Path Aggregation Network,PANet),提高定位精确率。本研究改进的基于Swin Transformer的YOLOX主要分为3个部分:1)Swin Transformer作为主干网络提取不同分辨率特征;2)BiFPN特征融合模块加强特征提取;3)解耦检测头(Decoupled Head)提高检测性能。基于Swin Transformer的YOLOX网络结构详见图4。
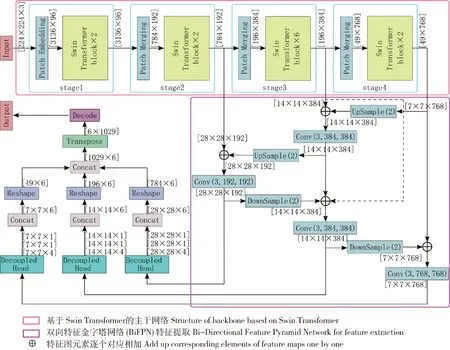
图4 改进的YOLOX总体网络结构
1.3.1基于Swin Transformer的主干网络
如图4所示,以尺寸为[224,224,3]的图像作为网络的输入,将Swin Transformer主干网络分为4个阶段,阶段1分为:(1)分块嵌入(Patch Embedding);(2)Swin Transformer模块(Swin Transformer block)。具体执行的操作如下:
1)分块嵌入通过卷积使实现下采样与维度变换,卷积核大小为4×4,步长为4,输入输出通道数分别为3和96(96是预设好的对于Transformer更容易接受的维度),输出特征图尺寸变成[56,56,96],再通过flatten操作将特征图形状变为[3 136,96]。
2)阶段1的Swin Transformer模块数量为2,第一个模块的具体操作如下:模块的输入大小为[3 136,96],首先对输入序列做层归一化操作(Layer Normalization,LN)[31],输出大小不变,之后对输出作形状转换将特征图形状变回[56,56,96],进入基于窗口的多头自注意力(Windows Multi-head Self-Attention,W-MSA)块。W-MSA块首先通过Window Partition操作,将大小为[56,56,96]的特征图划分为64个[7,7,96]大小的窗口,再经过形状变换得到64个尺寸为[49,96]的序列,对每个窗口内的49个元素进行多头自注意力计算,计算过程如下:
(1)
(2)
(3)
(4)

第一个模块输出后进入第二个模块,第二个Swin Transformer模块与第一个的不同之处在于将W-MSA块变成了基于滑动窗口的多头自注意力(Shifted Windows Multi-head Self-Attention,SW-MSA)块,滑动窗口的操作是将W-MSA块中划分的64个7×7大小的窗口同时在水平和垂直方向移动3个块的距离,实现不同窗口之间的信息交互,并且通过设置合理的掩码,让SW-MSA与W-MSA的窗口个数相同,达到等价的计算结果,除此之外其他计算过程与第一个模块基本相同。Swin Transformer模块的具体结构图参见文献[26]。Swin Transformer模块的输入输出大小不变,阶段1的输出大小为[3 136,96]。
阶段2分为:(1)分块合并(Patch Merging);(2)Swin Transformer模块。具体执行的操作如下:
1)阶段2的输入大小为[3 136,96],先将输入形状转换为[56,56,96],然后进行分块合并实现缩小分辨率、调整通道数,类似于池化操作,但是不会损失信息,具体操作见图5,经过步骤(b)得到大小为[28,28,96]的4个新的特征图,再经过步骤(d)得到大小为[28,28,384]的特征图,最后通过1个线性映射将通道数缩小为原来的2倍,所以Patch Merging层的输出大小变为[28,28,192],最后将形状转变为[784,192]。
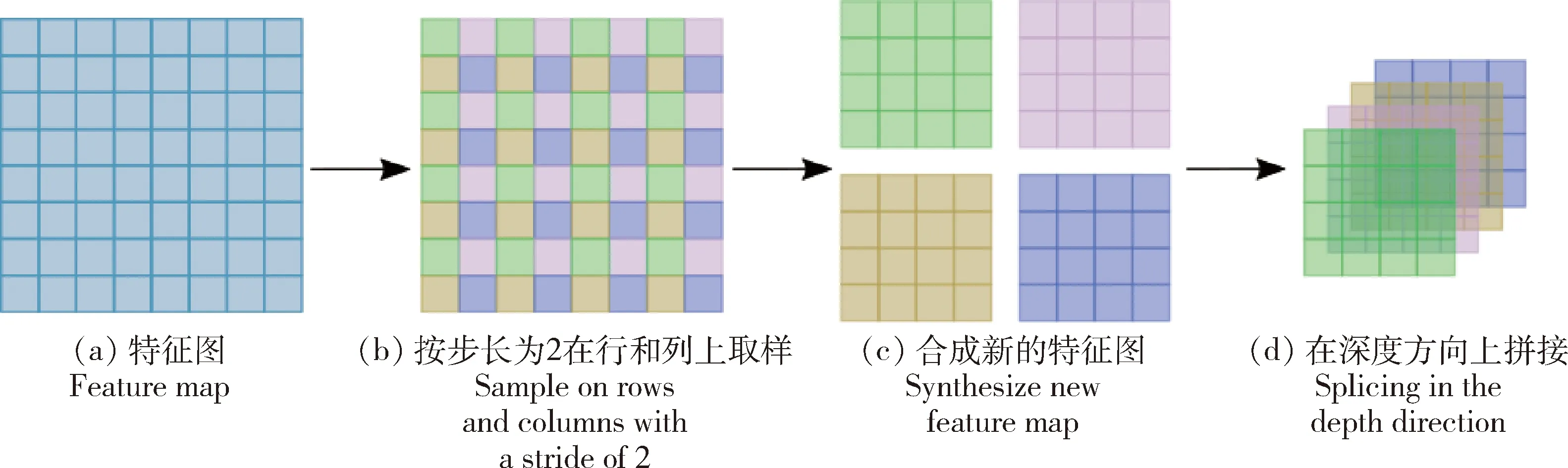
图5 Patch Merging下采样过程示意图
2)阶段2的Swin Transformer模块与阶段1基本相同,个数为2,输入输出大小是[784,192]。
阶段3、4与阶段2是相同的2个步骤,细节不同之处在于,阶段3的Swin Transformer模块由6个模块堆叠而成,阶段1、2、4的Swin Transformer模块数量都为2,Swin Transformer模块堆叠的方式是基于W-MSA与基于SW-MSA的2种模块成对交替出现。阶段1~4的输出大小分别为[3 136,96]、[784,192]、[196,384]和[49,768]。
1.3.2BiFPN加强特征提取
特征融合模块BiFPN是一种加权的双向特征金字塔网络,不同的输入特征具有不同的分辨率,BiFPN为每个输入增加1个额外的权重,让网络了解每个输入特征不同的重要性,还增加了简单的残差操作,增强特征的表示能力,实现自上而下与自下而上的深、浅层特征双向融合,增强不同网络层之间特征信息的传递,提升算法检测性能。
将主干网络的阶段2、3、4作为有效特征层,对这3层的输出做Reshape操作,将[784,192]、[196,384]和[49,768]变为[28,28,192]、[14,14,384]和[7,7,768]输入BiFPN,进一步进行特征提取。本研究中BiFPN的结构见图4,Upsample(2)为2倍的上采样,将特征图分辨率变为原来的2倍,通道数变为原来的一半,Downsample(2)为2倍的下采样,将特征图分辨率变为原来的一半,通道数变为原来的2倍。图中的Conv(3,192,192)为卷积操作,其中,3为卷积核的大小3×3,第一个192为卷积操作的输入通道数为192,第二个192为输出通道数,卷积步长为1,填充模式为“SAME”。
BiFPN的上采样路径由阶段4输出的深层低分辨率特征[7,7,768]作为输入,经过Upsample(2)调整分辨率和通道数后与中间特征层的输入[14,14,384]融合,然后经过Conv(3,384,384)的卷积操作提取特征,得到输出,大小为[14,14,384],对其进行Upsample(2)操作后,与最上层特征层的输入[28,28,192]融合,再对融合的结果做Conv(3,192,192)的卷积操作得到第一个有效特征层的输出,大小为[28,28,192]。下采样路径具体流程参见图4。
1.3.3Decoupled Head输出检测信息
YOLOX在最终输出时使用了解耦检测头(Decoupled Head),解耦检测头中对于预测目标类别、定位以及交并比(Intersection of Union,IoU)参数分别使用3个不同的分支,这样就将3者进行了解耦,提高检测性能。
Decoupled Head的具体操作如下:将BiFPN输出的特征图先通过1×1的卷积将通道数变为256,再经过标准化(Batch Normalization,BN)和SiLU激活函数激活,然后分成2个部分,1个预测特征点的类别,另1个负责特征点的位置和IoU预测。类别预测分支的过程为:经过卷积、标准化和SiLU激活后,再经过1层卷积然后输出,其中前1层的卷积核大小为3×3,步长为1,填充类型为“SAME”,输出通道数数为256,后1层所用的卷积核大小为1×1,步长为1,填充类型为“VALID”,输出通道数为1。位置和IoU预测分支的过程与类别预测分支相同,只有最后1层的卷积输出通道数不同,YOLOX关于位置直接预测4个值,即网格左上角的2个偏移量,以及预测框的高度和宽度,因此位置预测分支的输出通道数为4,IoU预测分支的输出通道数为1。Decoupled Head的具体结构图见文献[27]。
如图4所示,将Decoupled Head的3个分支的输出在深度方向上进行拼接,每个有效特征层的输出通道数都变为6,再经过形状转换将输出变成行数为元素个数、列数为6的2阶张量,3个Decoupled Head的输出经过处理后形状分别变为[784,6]、[196,6]和[49,6],将这3个输出再拼接然后转置(Transpose),最终输出结果大小为[6,1 029]。
最后对网络的输出进行解码,即将这些输出翻译成对应的预测框,回归的位置信息映射到原图位置,就可以在图中找到病虫害的具体位置。在定位图中病虫害区域的之后,需要识别病虫害的具体类别,即运用1.4节所介绍的旋转不变Fisher判别CNN,对病虫害的类别正确分类。
1.4 旋转不变Fisher判别CNN网络
本节目标是学习旋转不变Fisher判别CNN,以提高图像特征提取的性能,提高番茄病虫害种类的识别准确率。通过优化目标函数,针对旋转不变性与判别准确性来提升模型性能。其中旋转不变性是通过在模型的目标函数上加入正则化约束项来训练,该约束项强制旋转前后的训练样本的共享相似的特征,从而实现旋转不变。判别准确性则通过对网络特征施加Fisher判别准则,同样是在模型的目标函数上加入正则化约束项,使其类内分散小,类间分散大,提高判别能力。
1.4.1旋转不变Fisher判别CNN网络结构
如图6所示,旋转不变Fisher判别CNN由5个卷积层、1个3层的全连接层、1个旋转不变Fisher判别层和1个Softmax输出层构成,前6层的层与层之间使用最大池化层分开,所有隐藏层的激活单元都采用ReLU函数。
图中第一层的Conv(3,3,64)为卷积操作,第一个3为卷积核大小3×3,第二个3为输入通道数,64为输出通道数,卷积步长为1,填充模式为“SAME”,以大小为[224,224,3]的图像作为网络的输入,经过Conv(3,3,64)操作后特征图大小变为[224,224,64],第一层经过Conv(3,3,64)和Conv(3,64,64)2次卷积得到输出特征图大小为[224,224,64]。
所有最大池化操作的池化核大小都为2×2,步长为2,填充模式为“VALID”,最大池化层用于减小特征图分辨率,简化网络计算复杂度并压缩特征信息,第一层输出经过最大池化操作后特征图大小变为[112,112,64]。
如图6所示,前5层所有卷积核大小、卷积步长与填充模式都相同,只输入输出通道数有变化,第六层的第一个卷积Conv(7,512,4 096)对大小为[7,7,512]的输入处理后,得到输出[1,1,4 096],再先后经过Conv(1,4 096,4 096)和Conv(1,4 096,7)2次卷积,将输出通道数调整到7,即6种番茄病虫害的图像和无病虫害的番茄植株图像共7种类别,得到第六层的输出大小为[1,1,7]。
第七层为旋转不变Fisher判别层,其实是1个全连接层,输出大小为[1,1,7],其中所用的权重与偏置是经过添加了旋转不变正则化约束与Fisher判别准则的目标函数所训练出来的(具体介绍参见1.4.2节)。
第八层为最后1层Softmax输出层,经过Softmax非线性激活函数,输出大小为[1,1,7],Softmax将输出值进行归一化操作,输出是0到1之间的实数,并且,Softmax函数的输出值的总和是1,所以可以把输出值看作分类概率判断分类结果。
1.4.2旋转不变Fisher判别优化目标函数
如图6所示,为了避免过拟合并降低训练成本,第六层以及其前面的卷积层和全连接层的所有参数(权重和偏差),在ImageNet数据集[33]上预训练,并进行参数调整,然后转移到旋转不变Fisher判别CNN。对于1个训练样本xi∈XRI,XRI为经过旋转数据增广后的所有训练样本集合,设O6(xi)为第六层的输出特征,O7(xi)为第七层旋转不变Fisher判别层的输出特征,O8(xi)为第八层Softmax分类层的输出,大小都为[1,1,7]。
给定数据增广后的训练样本XRI={xi|xi∈X∪f(X)}和它们对应的标签YRI={yxi|xi∈XRI},其中,X为初始训练样本集合,f为旋转增广操作,f(X)为所有初始样本经过旋转处理得到的样本,假设初始训练样本的总数为N,则XRI的大小为N×5,yxi为第i个样本xi的真实类别标签向量,使用One hot编码,大小为7。
用输入(XRI,YRI)训练旋转不变Fisher判别CNN分类网络,除了要求模型在训练数据集上的分类误差最小外,还要求该模型对任意训练样本具有旋转不变性和强大的类别辨别能力。为此,在Softmax分类层提出1个新的目标函数,见式(5),通过该公式来学习参数:
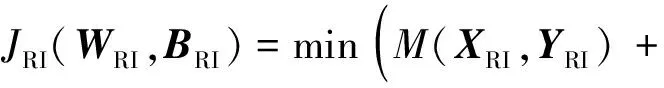
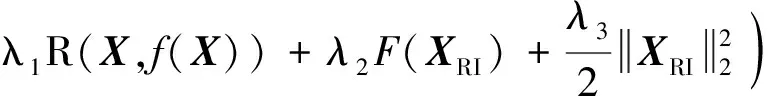
(5)
式中:WRI和BRI为整个网络的所有权重与偏置;λ1、λ2和λ3为权衡参数,控制其所在项的相对重要性。
式(5)的第一项是Softmax分类损失函数,由7类多项负对数似然函数定义。对于给定的训练样本xi∈XRI,它寻求最小的误分类误差,计算方法为:
(6)
式中:
式(5)的第二项是1个旋转不变正则化约束,其被施加在旋转前后的训练样本X和f(X)上,以确保它们共享相似的特征。将正则化约束项定义为:
(7)
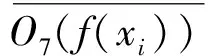
(8)
由式(7)可见,这1项使每个训练样本的特征接近对应的所有旋转样本的平均特征表示。如果这个项的输出值较小,即表示特征图对旋转变换的近似不变性。
式(5)的第三项是对网络特征的判别正则化约束。类内散度表示为SW(XRI),类间散度表示为SB(XRI),定义如下:
SW(XRI)=
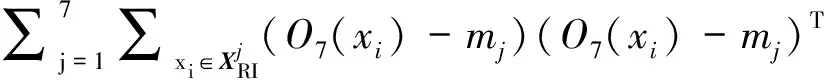
(9)
(10)
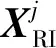
(11)
(12)
式中:O7(xi)、mj和m的大小都为7,所以SW(XRI)和SB(XRI)是大小为7×7的矩阵。直观上,将判别正则化项F(XRI)定义为:
F(XRI)=tr(SW(XRI))-tr(SB(XRI))
(13)
式中:tr为矩阵的迹,表示矩阵对角线元素之和。
式(5)的第四项是1个权重衰减项,控制权重WRI的大小,有助于防止过拟合。
将式(6)、(7)、(9)、(10)和(13)代入式(5),有如下目标函数:
JRI(WRI,BRI)=
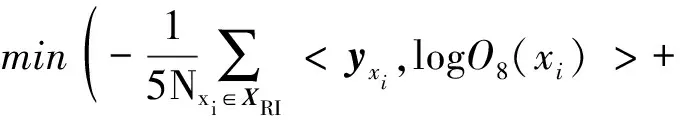
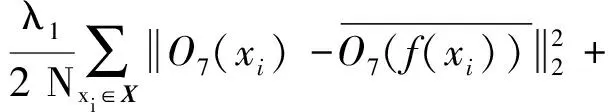
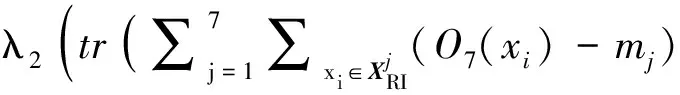
(O7(xi)-mj)T)-
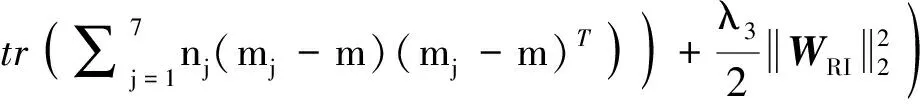
(14)
可见,定义的目标函数不仅使分类损失最小化,而且通过2个正则化约束来实现旋转不变性,同时使学习到的网络特征更具判别性。
1.5 模型评价指标
本研究通过精确率(Precision)、召回率(Recall)、交并比(Intersection of Union,IoU)和准确率(Accuracy)作为网络模型的评价指标,公式如下:
(15)
(16)
(17)
(18)
式中:TPi为第i种病虫害的测试样本目标检测定位正确的边框数量;FPi为第i种病虫害的测试样本被目标检测定位错误的边框数量;FNi为第i种病虫害样本中被漏检的病虫害边界框数量。IoU可以评价对病虫害目标定位是否正确;A为检测目标的预测边框位置,B为目标实际边框位置。选取0.5作为阈值,当A与B间的IoU大于0.5时,检测定位结果正确,否则属于错误的定位。准确率用于分类任务。Ci,i为真实类别为第i类,模型预测为第i类的样本数量;∑jCi,j为真实类别为第i类的所有样本数量。
2 结果与分析
表2为构建的基于Swin Transformer的YOLOX目标检测网络在番茄病虫害测试数据集上的目标检测效果,及其与经典的目标检测网络Faster R-CNN、SSD和基于Transformer的DETR[34]比较检测效果。可见:本研究的目标检测网络采用Swin Transformer作为YOLOX的主干网络,不仅具有层次性,还兼顾了全局信息与局部信息,对大物体和小物体的检测都能达到更高的精确率,在病虫害定位上有着不俗的表现,对6种病虫害整体的检测精确率达到了86.3%,召回率(77.2%)也比其他3种网络(73.6%,69.7%,75.1%)更高。
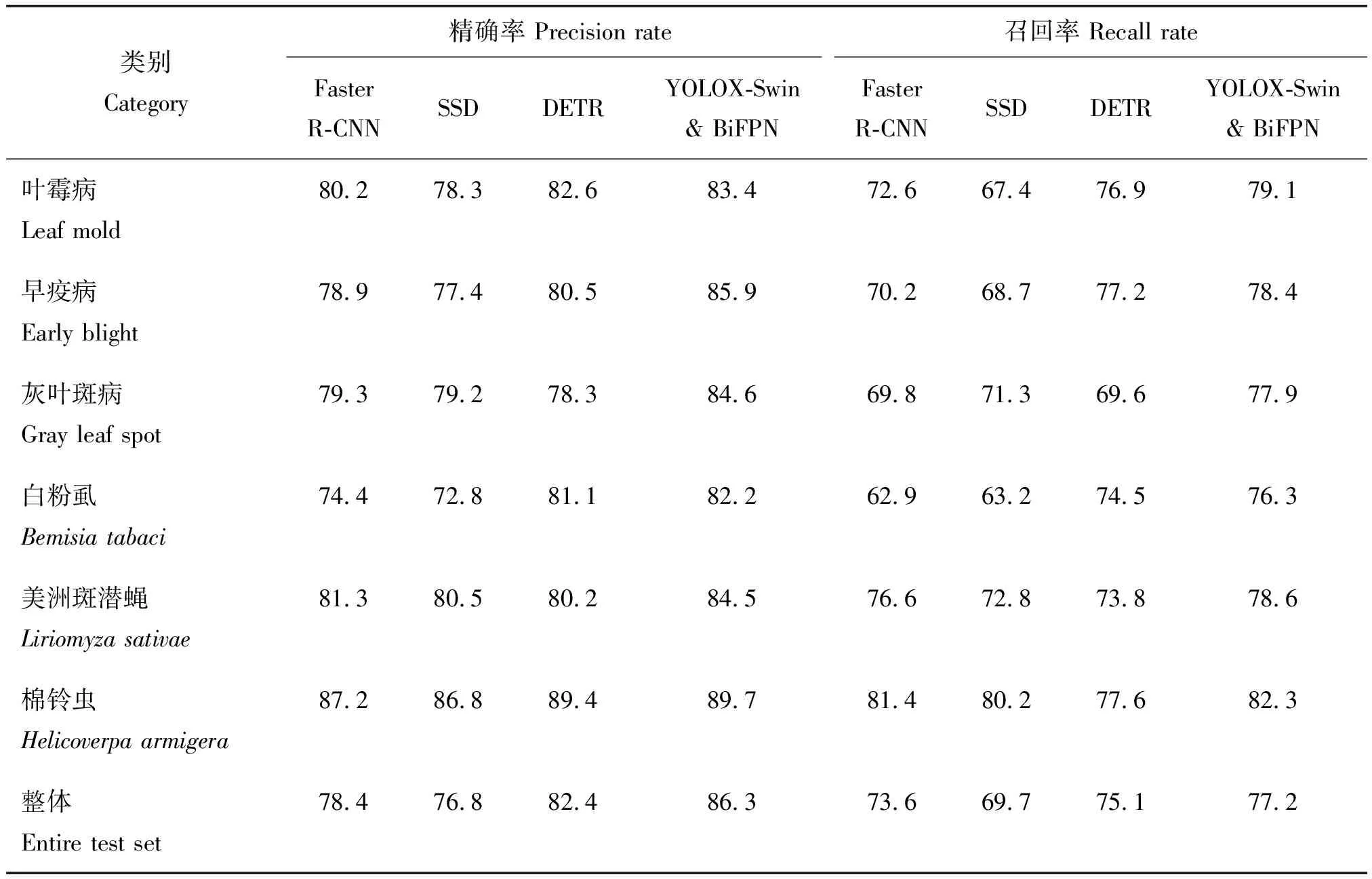
表2 不同目标检测网络模型在番茄测试集上的准确率和召回率
图7(a)~(d)分别是显示了经典分类网络AlexNet、VGGNet[35]、ViT和旋转不变Fisher判别CNN在番茄病虫害测试集上的分类效果的混淆矩阵图,由矩阵和式(18)可以计算出网络对所有测试样本的分类准确率,分别是74.1%、77.6%、78.5%和82.8%。图中每列的数字为每类病虫害测试集中识别为6种病虫害的所占比例,蓝紫色方块为所占比例在5%以下,粉色为所占比例在5%以上、60%以下,绿色为所占比例60%以上,4张混淆矩阵图的绿色方块都集中在对角线,表示病虫害分类正确的测试样本所占比例。可见:图7中(d)的蓝紫色方块最多,粉色方块最少,表示本研究旋转不变Fisher判别CNN取得了更优的结果,与VGGNet、AlexNet、ViT相比有更少的错误分类,旋转不变Fisher判别CNN分类网络在深度足够的同时进行了旋转不变与Fisher判别优化,在每种病虫害测试集上的正确分类数相较于其他3种网络都有一定的提高。
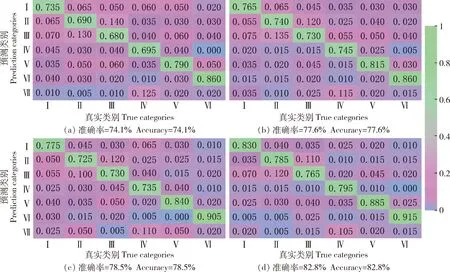
图中罗马数字代表的含义如下:Ⅰ-叶霉病,Ⅱ-早疫病,Ⅲ-灰叶斑病,Ⅳ-白粉虱,Ⅴ-美洲斑潜蝇,Ⅵ-棉铃虫,Ⅶ-健康。
图8展示了基于Swin Transformer的YOLOX目标检测网络和旋转不变Fisher判别CNN分类网络对6种番茄病虫害的检测与识别结果,其中图8(a)~(f)为分类正确的结果示例,图8(g)~(i)为分类错误的示例。结合表2与图8可见:6种番茄病虫害中,棉铃虫的检测效果最好,棉铃虫会蛀食番茄花果和茎叶,造成腐烂,其目标单一、特征明显且形态固定,所以棉铃虫比较容易检测;白粉虱的检测是最有挑战性的,由于它目标小,颜色浅,在光照较强的环境下,容易与背景融为一体,给目标检测和分类识别任务都带来很大的挑战,白粉虱在Faster R-CNN网络的目标检测任务中漏检的问题尤其严重(Recall=62.9%),而基于Swin Transformer的YOLOX目标检测大大提高了召回率(Recall=76.3%);美洲斑潜蝇的幼虫和成虫都会危害番茄叶片,幼虫取食叶片正面叶肉,形成弯曲缠绕的虫道,成虫具有一定的飞翔能力,会吸取叶片汁液,危害番茄植株前期发育,所以判断为美洲斑潜蝇虫害的方式有2种,1种是白色的弯曲虫道,1种是有飞行能力的成虫附着在植株表面,前者存在复杂背景造成的检测识别的困难,本研究提出的目标检测方法有效地提高了检测美洲斑潜蝇的精确率和召回率,分别为84.5%和78.6%。结合图7与8可见:AlexNet、VGGNet与ViT对叶霉病的识别错误率都达到了20%以上,这是因为叶霉病会使番茄叶面出现椭圆形或不规则的淡黄色褪绿病斑,而叶背面会产生白霉层,病害严重时又有不同的特征,针对这一点,旋转不变Fisher判别CNN通过降低类内散度来解决同种病虫害形态多变的问题,即使同类病虫害的特征大相径庭,旋转不变Fisher判别网络能使其与真实类别的联系更紧密,提高识别准确率;此外,AlexNet、VGGNet与ViT对灰叶斑病与早疫病的分类准确率也不理想(68%~74%),在分类错误的情况中,这2种病害互相混淆的结果最多,这是因为灰叶斑病与早疫病危害叶片时都可能呈现褐色、深褐色的类似圆形的斑点,病症十分相似,图8(h)和图8(i)给出了这2种病害分类错误的例子,针对这一点,本研究构建的分类网络加入了增强类间分散的训练任务,减少了病症相似的病虫害之间的分类错误率。
为了研究在目标检测网络中改进的主干网络与特征融合模块对番茄病虫害目标定位效果的影响,进行了消融试验,通过将原始的YOLOX网络和分别替换主干网络和特征融合模块的YOLOX网络用于测试,结果见表3。可见:这3个模型的精确率分别下降了6.1%、3.9%和7.6%;只替换主干网络的情况下,虽然获得了较高的精确率,但是召回率明显下降,没有达到较好的平衡。上述结果说明了本研究改进的目标检测网络对番茄病虫害进行定位的可行性。
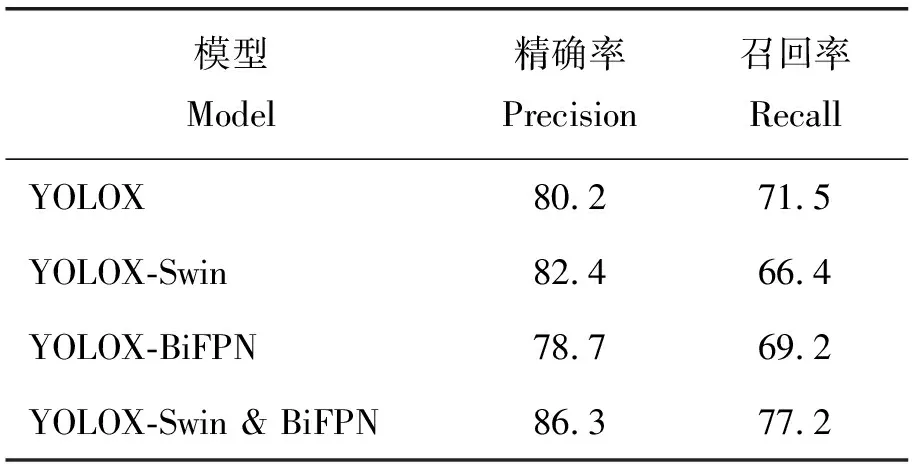
表3 采用不同的主干网络和特征融合模块的YOLOX模型对番茄病虫害的检测性能
表4为不添加正则化的分类网络和分别添加旋转不变和Fisher判别正则化的网络试验结果比较,同时比较网络使用旋转数据增广和不使用旋转数据增广在测试集上的表现。可见:对目标函数做旋转不变和Fisher判别优化是可以提高病虫害分类准确率的;旋转数据增广可以使模型分类准确率提升1.5%~4.9%;将旋转不变和Fisher判别优化与旋转数据增广结合起来,可以得到测试中最好的分类准确率(82.8%),充分发挥了优化网络的优势。
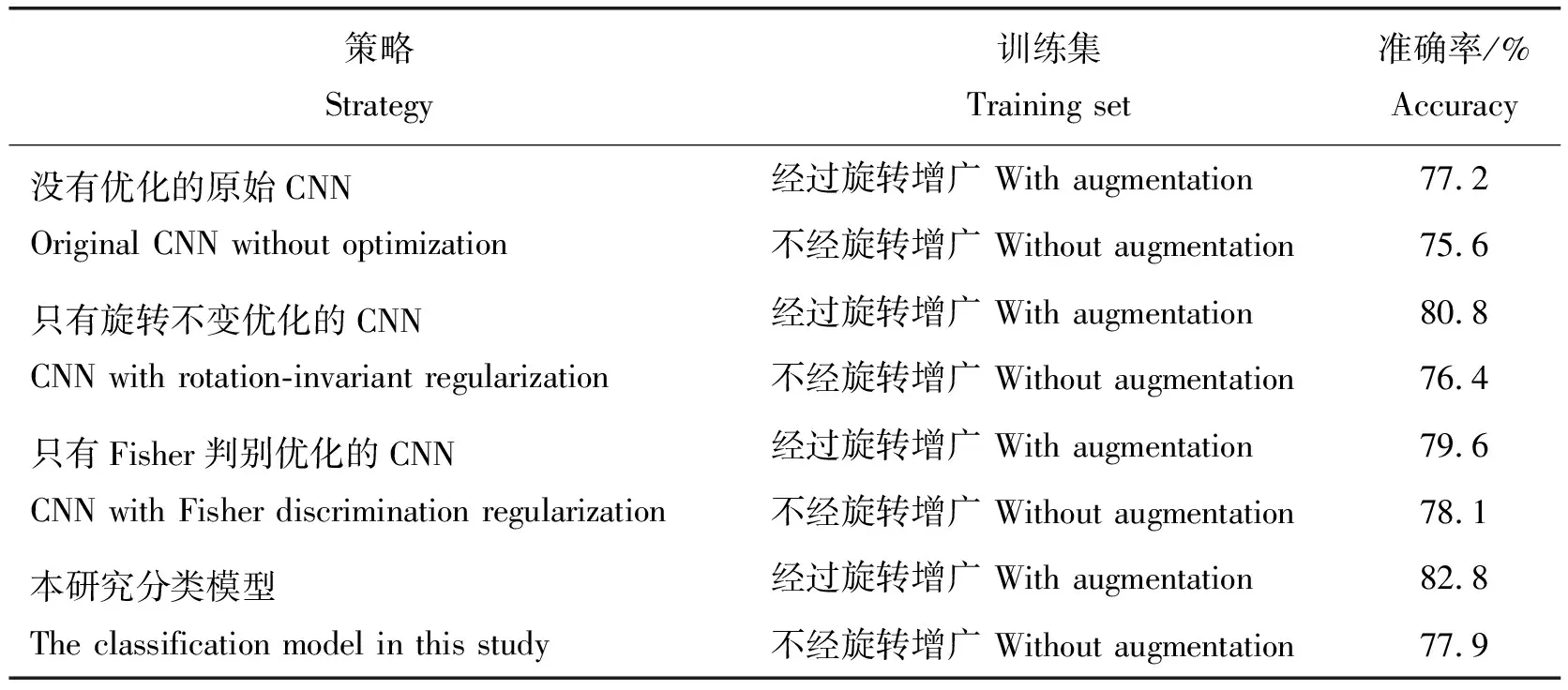
表4 不同优化策略和不同训练集下对番茄病虫害的识别准确率对比
3 讨 论
为了解决番茄病虫害检测目标较小、目标所在自然环境复杂造成的漏检误检的问题,本研究将Swin Transformer用于YOLOX作为主干网络,用BiFPN连接主干网络和检测头,融合多尺度的特征,并构建了旋转不变Fisher判别CNN分类的方法,解决目标角度变化、类间特征区别不明显和同类特征多样性造成的分类错误问题。与近几年提出的目标检测模型DETR[34]相比,本研究的目标检测网络在番茄病虫害上的检测精度依然是存在优势的,DETR是基于Transformer的端到端的目标检测模型,通过1个全局的Transformer编码器来对整个图像进行编码,这使DETR更加适合处理大尺寸目标或密集目标的检测,同时也导致了模型难以精确捕捉较分散的小目标的细节信息[36-37]。如表2所示,对于并不十分密集的早疫病与灰叶斑病,DETR的检测精度没有较明显的提升,且DETR的检测能力受到目标数量的限制,当数量较多时,DETR可能无法对所有对象进行准确的分类和边界框预测,本研究用Swin Transformer提取特征,能够有效地捕捉不同尺度下的空间信息和上下文信息,结合BiFPN提高目标检测的精确率。ViT是基于Transformer的分类模型,相比传统卷积神经网络更能适应各种不同的图像分类任务[38],ViT完全依赖于注意力机制来计算输入特征之间的关系,对结果的理解更加直观,但是对于分类错误的情况,难以准确地找到问题出现的原因,可解释性变得不理想[39],面对番茄病虫害特征类内分散大、类间分散小和旋转多变导致的错误分类问题,本研究的分类模型更具有优势。
本研究构建的网络都有针对的解决办法并取得了较好的结果,但是在番茄病虫害防治的现实应用中依然存在尚未解决的困难,有如下2个方面:
1)番茄种植过程中存在的病虫害种类、表现形式的多样性,番茄植株在感染同一种病害的初期、中期、后期所呈现的形状、颜色、纹理等特征是不同的,而不同的病害危害植株时也可能会呈现相似的性状。害虫在幼虫和成虫形态时会通过不同的方式危害番茄,并且病虫害影响不同的部位时特征存在差异,如叶片枯萎、果实腐烂或者根茎变形。同时本研究的试验中没有考虑到不止1种病害或者虫害同时存在于番茄植株上,并且可能会相互作用的情况。此外,复杂的自然背景也对检测和分类造成很大的影响,如光线的强弱、植株本身叶片根茎交错无序、互相遮挡等。基于此,则需要大量的样本来训练模型达到更好的效果,而番茄病虫害图像样本的采集也是一个难题。
2)为了提高精度,本研究将检测和分类分为2个网络,所以要对训练样本进行2次不同的标注并且分别训练网络,在面对田间番茄种植管理更多的病虫害种类以及大量样本时则需要耗费更多的时间和精力。
在未来的工作中对番茄病虫害数据集的扩展可以通过进一步细分类别实现,包含同类病害的不同时期,害虫的不同形态,以及增加在不同光线下拍摄的图像,拍摄角度多变,来提高训练样本的多样性。采集比较常见的多种病虫害共同危害番茄植株的图像,为后续的深入研究做准备。对网络进一步优化,研究更好的目标分割技术来帮助模型更好地检测和区分目标,调整训练数据集、模型架构和参数设置,以提高模型的可解释性来提高对更复杂的数据集的检测分类效果,研究有效的方法保证定位和分类的高准确率的同时实现检测模型和分类模型的结合简化处理过程。
4 结 论
本研究针对番茄病虫害检测识别存在的普遍问题,提出了基于Swin Transformer的YOLOX目标检测模型和旋转不变Fisher判别CNN分类模型,主要结论如下:1)测试结果表明,基于Swin Transformer的YOLOX目标检测对病虫害的定位取得了较好的结果,在番茄病虫害测试集上整体的检测精确率达到了86.3%,召回率也提高到了77.2%,旋转不变Fisher判别CNN在番茄病虫害的分类准确率上与其他网络相比也有明显的提高,对叶霉病、早疫病、灰叶斑病、白粉虱、美洲斑潜蝇和棉铃虫6种病虫害的分类准确率分别提升到了83%、78.5%、76.5%、79.5%、88.5%、91.5%。2)对训练样本进行旋转数据增广,实现了提高病虫害目标检测的精确率和召回率,同时也保障分类网络对番茄病虫害种类有较高的识别能力。下一步的研究致力于更高效更适用于病虫害防治现实应用的模型,丰富数据集的同时对网络也进行合适的优化,本研究将目标检测与分类识别分为2个模型来实现,虽然强调了模型各自的优点,但是在处理速率上没有较强的优势,所以检测与分类的速度也可以作为下一步研究改进的重点。
