基于关联规则的铁路调度集中系统进路自动化搜索算法
2023-11-08牛林杰吴建军
牛林杰,吴建军
(1.陕西交通职业技术学院 轨道交通学院,陕西 西安 710018;2.柳州铁道职业技术学院,广西 柳州 545616)
1 概述
进路指列车进入铁路站台后的运行路径,车站道岔位置决定了列车进路情况。列车进路需要利用信号机作为防护机器,车站进路上有车或者列车道岔位置存在错误时,此条进路的信号机为闭合状态[1],此时列车无法进站,通过信号机保障列车进站和通行安全。铁路调度集中系统是控制列车进路的重要平台,联锁表是与车站站场众多信号设备连接的表格,是铁路列车运行与调度的重要依据[2]。车站内包含的车辆与设备过多、车站进站结构过于复杂时,提升了铁路调度集中系统安排车辆进站难度。铁路调度集中系统对列车进站的精准性要求较高,节点存在错误将造成严重后果[3],影响列车正常进站。
伴随我国交通行业快速发展,铁路运输行业受到众多研究学者重视,铁路调度集中系统具有处理列车进路、实现列车轨道与信号机联锁关系的重要作用[4],可以保障铁路可靠运输。铁路调度集中系统的进路搜索是实现铁路联锁控制的重要部分,铁路调度集中系统的进路自动化搜索实时性决定了列车进路的高效性与安全性。铁路车站列车的良好调度可以避免车辆冲突[5]、保障列车行车安全,列车进站前防护的封闭空间即列车进路。列车进路的自动化搜索性能可以体现铁路运输的智能化与信息化,是车站信号控制领域的研究重点。通过进路自动化搜索实现列车进站连锁控制[6]。列车通过铁路调度集中系统获取进站信号和进站路径,避免车辆之间的冲突。
目前针对列车调度的研究较多,韩忻辰等[7]和赵宏涛等[8]分别将Q-learning算法与云边协同方法应用于铁路列车动态调度中,具有较高的调度性能,但存在调度实时性差的缺陷。研究基于关联规则的铁路调度集中系统进路自动化搜索算法,利用关联规则挖掘算法挖掘铁路调度的路径信息,利用关联规则挖掘结果实现车辆进站的进路自动化搜索。通过实例分析结果验证所设计进路自动化搜索算法具有较高的智能化搜索性能,可以实现铁路进路的自动化搜索,提升铁路调度集中系统的工作效率,满足铁路不断提升的车辆运输需求。
2 铁路调度集中系统进路自动化搜索算法
2.1 铁路调度集中系统
铁路调度集中系统包括车站和调度中心两部分,车站和调度中心利用站间广域网实现信息的传输。系统的车务终端、车站自律机等设备位于车站内部。铁路调度集中系统总体结构图如图1所示。

图1 铁路调度集中系统总体结构图
铁路调度集中系统包含以下功能:
a.监视待入站场的列车运行状态与站场内调度车辆进路的众多信号设备,通过可视化显示界面展示列车不同区段和站间信息。
b.明确列车发车时间和到达时间,获取站场内全部列车的实际位置,明确列车的行驶轨迹。
c.具有列车调整计划的编制功能,可以实现智能化的车辆进场指挥调度[9],通过无线通信网络将调度命令和调整计划下发至车站。
d.列车调度模块利用进路自动化搜索算法,控制车站自律机依据车辆运行计划调度列车进路。
e.建立车站行车日志,形成车站运维报表。
f.系统调度中心具有全部车辆进路控制的联锁设备启动与关闭按钮,可以采用人工方式控制车辆行驶与调度车辆;依据车站调车作业计划、列车实际运行状况以及车辆进站请求[10],控制自律机自动控制车辆进路,监视车辆调度,发现车辆存在调度异常情况时及时报警。
g.管理与登记车辆维修与进站具体明细。
2.2 关联规则挖掘车站进路数据
采用关联规则挖掘铁路调度集中系统中的车站进路数据,获取进路自动化搜索的路径节点。关联规则的挖掘算法指从铁路调度集中系统内包含的海量进路信息里挖掘进站自动化搜索事务隐藏的关联关系。用I=(i1,i2,…,in)表示待挖掘的进站自动化搜索数据项集,ik表示其中的一个进站自动化搜索数据项,利用众多事务建立进站自动化搜索数据库。所建立数据库的数据项集存在关联规则用X⟹Y表示,关联规则的支持度和置信度分别用Sup(X⟹Y)与Conf(X⟹Y)表示。该事务中存在事件X时,此时存在一定概率发生Y的情况,X与Y分别表示事务前件与后件,同时存在X⊂I,Y⊂I,X∩Y=φ。
关联规则支持度与置信度表达式分别如下:
Sup(X⟹Y)=Count(X∪Y)×100%/|D|=
P(X∪Y)
(1)
Conf(X⟹Y)=Sup(X∪Y)×100%/Sup(X)=
P(Y|X)
(2)
式中:P(X∪Y)与Count(X∪Y)分别表示进路自动化搜索数据库内,同时出现事件X与事件Y的概率和同时包含事件X与事件Y事务的数量;|D|与P(Y|X)分别表示事务库大小以及发生事件X时,事件Y的发生概率。
确定最小支持度Supmin和最小置信度Confmin后,存在Sup(X⟹Y)>Supmin且Conf(X⟹Y)≥Confmin时,此时的规则A⟹B为强关联规则;存在Sup(Ik)>Supmin时,此时称Ik为频繁项集,频繁项集的搜寻速度决定了采用关联规则实现数据挖掘的挖掘效率。
采用关联规则算法挖掘铁路调度集中系统海量数据中的有用信息,进路自动化搜索有用信息挖掘过程如下:
a.搜寻铁路调度集中系统中的历史数据,依据历史数据的经度与纬度划分历史数据为大小相同的网格单元。记录列车单次行驶的运输线路[11],将历史列车运输线路保留至网格中以节点形式呈现。利用单元网格序列展示列车的历史行驶轨迹。通过单元网格序列建立列车站场进路的拓扑运输路网。
b.关联铁路站场拓扑运输路网的静态信息,将拓扑运输路网中相关信息添加至单元节点中,建立不同网格的信息记录表,获取网格记录标识用GID={I1,I2,…,In}表示,其中Ii表示网格内车辆通行记录。
c.选取关联规则的数据挖掘算法对网格实施关联分析,获取各进路网格的支持度与置信度。
d.利用关联规则算法获取站场进路网格序列信息,计算网格中各节点的重要度[12],提取具有较高重要度的节点,将具有较高重要度的节点设置为蚁群算法进路自动化搜索算法的节点,为铁路调度集中系统进路自动化搜索提供路径数据基础。
2.3 蚁群算法的进路自动化搜索算法
选取蚁群算法将车站进路数据的关联规则挖掘结果作为数据基础,完成进路自动化搜索。采用图论方法将蚁群算法利用表达式G=(V,E)表示,其中E与V分别表示路径间的弧段以及全部路径集合,蚁群算法的目标是搜寻每个节点仅通行一次的最短路径。
采用蚁群算法完成进路自动化搜索时,蚁群算法中的蚂蚁需要遵循以下特征:
a.蚁群中的蚂蚁受不同节点间的距离及不同路径的信息素浓度决定下一个节点的选取概率。
b.蚁群算法搜索过程中,需要保障每个节点仅通行一次,已通行过的节点不再考虑[13]。通过设置禁忌表避免节点重复行进问题。
c.蚁群中的蚂蚁每完成一次旅行后,更新蚁群算法的信息素。
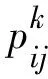
(3)
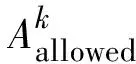
蚁群算法中的蚂蚁具有可记住已经过节点的记忆力,蚁群算法设置了禁忌表,禁忌表中记录蚂蚁前进过程中经过的全部节点。伴随蚁群算法中蚂蚁不断前进,禁忌表需要实时更新。当α=0或β=0时,蚁群算法分别呈现贪心算法或正反启发式算法特性。蚂蚁完成一次行走路径即铁路调度集中系统进路自动化搜索的路径[14]时,蚁群算法更新路径信息素浓度表达式如下:
ξij(t+1)=ρ·ξij(t)+ρΔξij
(4)
式中:ρ与Δξij分别表示信息素残留因子以及信息素增量。伴随蚂蚁不断前进,信息素衰减程度用(1-ρ)表示。信息素增量Δξij表达式如下:
(5)
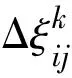
选取蚁周模型作为蚁群算法的信息素的增加方式,蚁周模型表达式如下:
(6)
式中:P与Lk分别表示完成一次路径更新时蚁群算法的信息素总量与蚂蚁停止前进时该只蚂蚁前进的总路径长度。蚁周模型具有较高的整体性,可以依据蚁群算法中各蚂蚁的前进路线总体长度获取路径中蚂蚁释放的信息素浓度。
铁路调度集中系统采用蚁群算法自动化搜索铁路站场进路时,蚁群算法中的蚂蚁依据路径中存在的信息素浓度快速获取目标节点。
为了保障获取最优的进路自动化搜索结果,设置约束条件如下:
a.为了避免蚁群算法由于收敛速度过快陷入局部最优,蚁群算法搜索时,蚂蚁从初始节点随机搜索至终点,完成一次前进时,更新全部路径中的信息素浓度。
b.设置蚁群算法中蚂蚁同时从初始节点及终点前进。
c.设置蚁群算法搜索最短路径的目标函数是经过站场有限图权重值最小,路径权重相同时,选取对平行进路具有最小影响的路径。
d.路径搜索过程中存在悬挂节点时,不将该路径计入最终搜索结果。
采用蚁群算法自动化搜索铁路调度集中系统进路流程如下:
a.释放蚂蚁,依据初始化原则令蚂蚁通过进路随机路径前进至终点,保存蚂蚁前进的全部进路路径。
b.完成蚁群算法的进路全部路径搜索后,更新铁路站场全部路径的信息素浓度。
c.重复以上过程完成蚁群算法内全部蚂蚁的随机搜索。
d.依据随机搜索结果确定各节点被选择的概率,将各蚂蚁分别设置于初始节点以及终点[15],令蚂蚁从两个方向分别搜索,依据搜索路径中的信息素浓度选取蚂蚁待行进的下一节点。依据蚁周模型更新铁路站场的信息素浓度。
e.重复以上过程,直至满足终止条件,导出最优路径,此时结果即铁路调度集中系统的进路自动化搜索结果。
3 实例分析
为了验证所研究基于关联规则的铁路调度集中系统进路自动化搜索算法自动化搜索站场进路有效性,选取某列车车站作为测试对象。该车站是我国重要的交通枢纽部位,每天需要经过众多列车,站场的进路自动化搜索性能决定了铁路调度集中系统的调度性能。将该车站历史运行30 d数据作为关联规则挖掘的数据集,该数据集中包含事务数量为658 415 661个,包含项集数量15 684个。
统计不同支持度与置信度阈值时,本文算法的数据挖掘提升度,统计结果如图2所示。
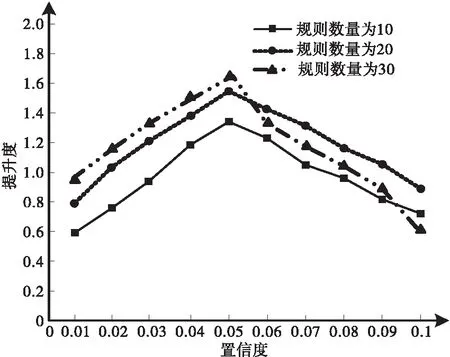
(a)置信度阈值
数据挖掘的提升度等于1时,挖掘的事务之间不具备关联关系;数据挖掘的提升度大于1时,表示挖掘的关联规则具有较高相关性;提升度小于1时,表示挖掘的规则前项和后项呈负相关状态,数据挖掘结果价值过低。从图2试验结果可以看出,置信度阈值和支持度阈值分别设置为0.05和0.35时,本文算法所采用的关联规则可以获取理想的数据挖掘结果。采用本文算法自动化搜索进路时,设置置信度阈值和支持度阈值分别设置为0.05和0.35。确定置信度与支持度阈值后,利用关联规则算法挖掘数据集,获取的数据集关联规则挖掘结果如表1所示。
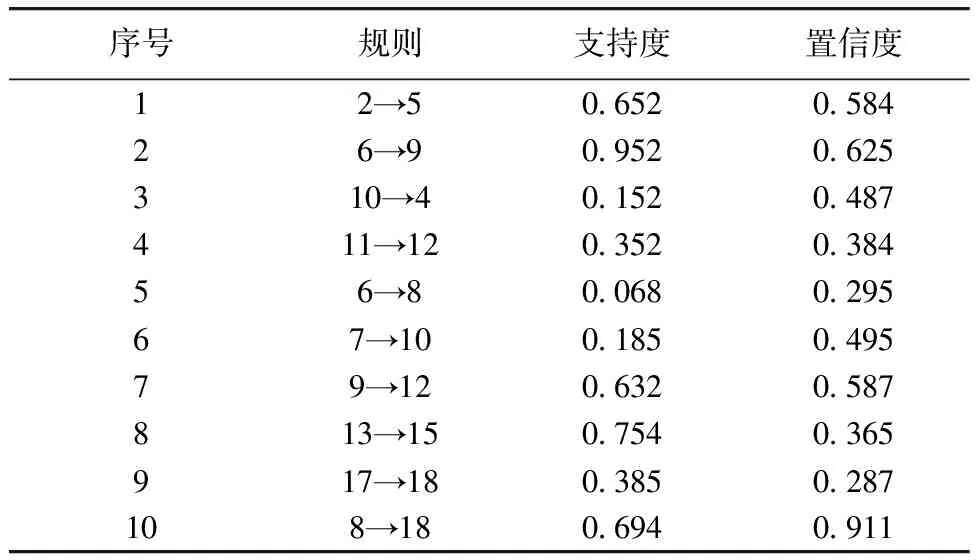
表1 关联规则挖掘结果
从表1试验结果可以看出,采用本文算法可以有效挖掘数据集中的关联规则。本文算法将采用关联规则获取的数据挖掘结果设置为进路自动化搜索的节点,不同规则间的关系作为网络的边,建立供蚁群算法自动化搜索进路的关联网络。
统计不同启发因子时,采用本文算法自动化搜索进路的路径长度与搜索耗时,统计结果如图3所示。

图3 启发因子对自动化搜索的影响
从图3试验结果可以看出,启发因子过大时,蚁群算法自动化搜索进路容易陷入局部最优情况;启发因子过小时,算法收敛速度过慢。综合考虑启发因子对进路自动化搜索的路径距离与搜索时间的影响,设置采用蚁群算法自动化搜索进路时的启发因子为3。
统计不同信息素残留因子时,采用本文算法自动化搜索进路时的路径长度与搜索耗时,统计结果如图4所示。

图4 信息素残留因子对自动化搜索的影响
从图4试验结果可以看出,信息素残留因子对进路自动化搜索影响较大。信息素残留因子为0.5时,可以获取最佳的自动化搜索结果。信息素残留因子过小时,蚁群算法信息素挥发较快,无法充分利用蚁群算法的启发信息,获取的自动化搜索结果并不理想;信息素残留因子过高时,虽然可以获取理想的进路自动化搜索结果,但搜索耗时过长。综合考虑进路自动化搜索需求,设置蚁群算法的信息素残留因子为0.5。
进路自动化搜索时,需要保证车辆进站的安全性。进路自动化搜索后,需要确定自动化搜索的初始节点和终端节点,差异进路类型的初始节点和终端节点的信息存在较大差异。依据表1挖掘出的节点置信度和支持度序列规则,获得车站进路自动化搜索结果如表2所示。

表2 车站进路自动化搜索结果
由表2布置车站站场进路节点如图5所示。

图5 车站站场进路节点布局
由表2和图5可以看出,采用本文算法可以实现车站站场进路的自动化搜索,保障铁路调度集中系统实现列车的有效调度。本文算法采用关联规则算法挖掘铁路调度集中系统海量数据中的有用信息,利用关联规则挖掘结果建立蚁群算法进路自动化搜索时的搜索节点,具有较高的自动化搜索有效性。
4 结论
铁路调度集中系统是利用自律机集中控制列车调度的重要系统,铁路调度集中系统的进路自动化搜索算法决定了车站的管理性能。利用进路自动化搜索算法实现列车进路的调度,提升车站的自动化管理程度。将关联规则算法应用于铁路调度集中系统的进路自动化搜索算法中,利用关联规则具有的高效数据挖掘性能,获取最优的进路自动化搜索结果,促进信号设备步入全面现代化发展,为铁路运输行业进一步发展发挥积极的作用。
