基于迁移学习的岩屑岩性识别*
2023-11-08董文豪张怀
董文豪,张怀
(中国科学院大学地球与行星科学学院 中国科学院计算地球动力学重点实验室, 北京 100049) (2022年1月21日收稿; 2022年3月31日收修改稿)
岩屑录井技术主要是指在钻井过程中,岩石碎片随钻井液返回地面,地面工作人员按照时间顺序、取样间距将返出井口的岩屑收集并进行分析;对岩屑的岩性识别,在地质构造及油气勘探等领域的研究中有重要作用[1-2]。工作人员主要是基于岩屑的颜色特征、纹理特征及颗粒大小等对岩屑进行分类[3-5],一般是通过人眼识别,费时费力,同时存在识别准确率不足、分类结果受主观因素影响等问题;而实际中要求工作人员能够快速准确地进行分类识别,这对工作人员提出了较高的技术要求,工作强度也非常大。如何开发一种快速准确的对岩屑岩性自动分类识别的方法成为一个急需解决的问题。
近年来,机器学习在图像识别中取得良好表现[6-7],研究人员尝试将其应用于岩屑图像的分类识别中并取得了较好的分类识别效果。万红吉等[8]基于模糊C均值聚类算法对泥岩、砂岩、页岩3类岩屑进行分类识别,识别精度达90%以上;陈超和李文藻[9]基于随机森林与颜色特征算法对泥岩和砂岩进行识别分类,识别精度达85%以上。但是这些机器学习算法结构简单,在分类识别复杂的岩屑图片时表现不佳。深度学习算法在图像识别中的优异表现[10-15]为复杂的岩屑识别提供了一种解决方法。
深度学习模型就是有很多层的神经网络模型[16]。万川等[17]基于改进P-Unet模型对岩屑颗粒进行识别;熊越晗等[18]基于岩样细观图像深度学习对岩性自动分类,训练集和验证集的分类准确率分别达到92.77%和76.31%。深度学习需要足够多的数据集学习以避免出现过拟合,但在实际应用中,研究者大多情况下获得特定问题的数据集是非常有限的,这严重影响了深度学习模型的构建[19]。
为解决数据集不足时产生的深度学习模型构建困难问题,人们建立了一些开放的大数据集,如ImageNet[20]。ImageNet包含1 000多种类别,图片量达1 200万张。利用这些数据集,人们获得了一些深度学习参考模型,如Inception、VGG-16、VGG-19、ResNet模型等[21-22]。实际工作中数据集不足情况下,人们借助这些模型,提出迁移学习[23-24]。通过与Inception、ResNet等模型实验对比,结果表明VGG-16模型在图像识别中识别准确率更高,因此本文选用VGG-16模型[25]。VGG-16模型相较于VGG-19模型层数更少,计算效率更高,稳健性略好[26]。实际应用中,借用前人在ImageNet上训练好的深度学习模型如VGG-16模型作为中间层,学习岩屑图片分类时仅更新输出层中全连接层部分的参数[27]。Liu等[28]开发了一种结合深度学习模型和聚类算法的增强型岩石矿物识别方法,对12种岩石矿物进行识别分类,模型的top-1和top-3准确率分别达74.2%和99.0%;许振浩等[29]基于岩石图像迁移学习对岩石的岩性进行识别,训练集准确率达90%以上;刘晨等[30]基于ResNet50建立迁移学习模型对7种岩屑进行岩性识别分类;范思萌等[31]开发了基于SVM-FTVGG16的岩屑检测方法来识别岩屑,准确率达到85.7%。
本文针对所采集的18种岩屑图像样本集,建立了基于在ImageNet图像数据集上训练好的VGG-16模型的岩屑图片迁移学习模型,通过提取岩屑特征对岩屑进行岩性识别分类。
1 深度学习方法概要
1.1 卷积神经网络
神经网络模型模仿人脑神经元的工作流程[32]。神经元接受到来自上一层神经元的输入信号,再向下一层输出。神经网络模型通常由输入层、(多个)中间层和输出层组成。神经网络模型的层是全连接层,每一个神经元都与上一层的所有神经元相连,用来综合前面提取到的所有特征。
最简单的神经网络模型数学公式[33]可以表示为
(1)
其中,xi表示输入信号,wi表示与输入信号xi连接的权重值,b表示神经元的偏置,y表示神经元的输出,f表示激活函数。本文使用如下ReLU激活函数[34]
(2)
卷积神经网络(convolutional neural network,CNN)将简单的神经网络中间层扩充为卷积层和池化层。卷积层(convolutional layer)用本层的卷积核与上一层的输出信号进行卷积运算[18],然后再通过激活函数传递给下一层。卷积层的计算公式[16]为
xt=f(Wxt-1+bt),
(3)
其中,t表示层数,xt表示第t层的输出信号,W表示卷积核,bt表示第t层偏置。
池化层(pooling layer)也称为下采样层,用于压缩数据,在保留有用特征信息的基础上减少数据的处理量[35]。本文采用最大池化层方法,给出相邻矩形区域内的最大值并向下一层输出。
神经网络的学习目标是获得使损失函数尽可能小的参数,本文采用交叉熵损失函数作为损失函数,其计算公式[36]为
L=-∑ktklnyk,
(4)
其中,yk是神经网络的输出,tk是正确解标签。计算损失函数关于各个权重参数的梯度,将权重参数沿梯度方向作更新,重复这个过程最终得到最优参数。
CNN具有稀疏权重、参数共享等优点[12];其卷积核的大小远小于本层输入信号的大小,同时卷积核的参数可以作用于本层输入信号的多个位置上,从而可以极大地减小模型参数量,提高计算效率。CNN模型本身需要足够多的数据集等进行训练学习,而当数据集不充分,模型会出现过拟合现象。现实工作中,很多问题不具备数据集充分的条件,于是人们基于在大数据集上训练得到的深度学习模型建立了迁移学习模型。
1.2 迁移学习模型
在迁移学习中,训练数据和测试数据不需要服从独立同分布,不需要非常多的训练样本就可学习得到一个好的分类识别模型[37]。同时由于迁移学习利用前人的数据集,因而模型构建中不需要从头开始训练新的数据集,显著降低了深度学习模型在目标域内对训练样本量的需求,也就降低了计算成本[38]。
VGG-16模型[39]是牛津大学视觉几何小组(Visual Geometry Group)基于包含来自1 000多个类别约 120 万张图像的ImageNet图像数据集学习得到的。该模型由13个卷积层、5 个池化层和3个全连接层构成,模型结构如图1所示。本文将VGG-16模型的卷积层和池化层迁移到本文构建的迁移学习模型中,并重新构建了新的全连接层代替VGG-16模型的全连接层。如图2所示。将岩屑录井图片输入到模型中,经过卷积层和池化层提取特征后,进入输出层,最后得到岩屑类型的概率分布,概率最大的类别即模型识别的岩屑类别。模型学习过程中中间层的参数被冻结不再更新,只更新输出层的全连接层参数。本文在迁移学习模型的输出层输出前添加了1个Dropout层[16]以减少过拟合对模型学习的影响。

图1 VGG-16模型结构Fig.1 The structure of VGG-16 model
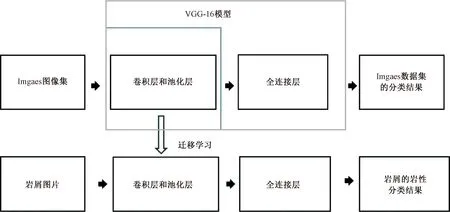
图2 迁移学习模型构建Fig.2 The construction of transfer learning model
2 实验设计
2.1 数据来源
本文收集了盘锦中录油气技术服务有限公司提供的岩屑录井的18种岩屑。将原岩屑照片裁剪并缩小为200像素×200像素,最终整理出5 877张岩屑图片,并将其按3∶1∶1的比例划分为训练集、验证集和测试集。为确保准确性并更具说服力,训练图像和测试图像是从岩屑图像数据集中随机选取的。相关岩屑种类-数量分布如表1所示,岩屑图片示例如图3所示。

表1 岩屑图片分类及数量Table 1 Classification and quantity of cuttings pictures
2.2 岩屑识别模型构建
在Windows10、64位系统下,CPU为Intel(R) Core(TM) i7-8700,基于Tensorflow2.5.0构建了CNN和迁移学习模型,并用于对岩屑岩性分类识别。
2.2.1 CNN模型
本文应用的CNN模型有5个卷积层,5个池化层。由于处理的是二维的图像数据,输入信号形状为(200, 200, 3),即每个分量有200×200=40 000个采样点,3个通道。第1层卷积层采用32个卷积核,每个卷积核过滤器尺寸为(3, 3),输出形状变为(200, 200, 32),卷积层的激活函数使用ReLU函数;最大池化层的尺寸为(2, 2),经过下采样,输出大小变为(100, 100, 32);经过3个卷积层和池化层后的输出为(6, 6, 512),再经过Flatten层将矩阵平铺成向量形式,则输出向量大小为6×6×256=18 432。之后又连接了2个全连接层,全连接层中插入1个Dropout层来降低过拟合造成的影响。第1个全连接层输出个数为512,最后1个全连接层输出个数为18,采用Softmax函数计算输出事件类别的概率分布。Softmax函数又称归一化函数,将多分类的结果以概率的形式输出,因此预测结果转化为非负数,并且预测结果之和为1。Softmax函数数学表达式[40]如下
(5)
用准确率ACC衡量模型的识别效果,其定义[33]为
ACC=(TN+Tp)/(TN+Tp+FP+FN),
(6)
其中,Tp表示模型识别正确的某类岩屑图个数,FP表示为其他种类岩屑图片被识别某类岩屑图片的个数。FN表示某类岩屑图片被错误预测为其他种类岩屑图片的个数(TN在计算时未使用到)。
在CNN训练中,将所有数据迭代完一遍称为一个epoch,本文计算一个epoch需要大约270 s。在训练100个epoch后,训练集、验证集、测试集的岩性识别准确率分别达到96.5%,72.2%和72.4%,CNN模型的泛化能力较差。
2.2.2 迁移学习模型
本文应用的迁移学习模型由VGG-16模型的卷积模块和2个全连接层构成,迁移学习模型结构如图4所示。输入信号形状为(200, 200, 3);设置2个卷积层,连接1个池化层;再设置2个卷积层,连接1个池化层;再设置3个卷积层,连接1个池化层;再设置3个卷积层,连接1个池化层;再设置3个卷积层,连接1个池化层。此时输出尺寸大小为(6,6,512)。经过Flatten层将矩阵平铺成向量形式。之后又连接2个全连接层,全连接层中插入1个Dropout层以降低过拟合造成的影响。第1个全连接层输出个数为512,最后1个全连接层输出个数为18,采用Softmax函数计算输出事件类别的概率分布。
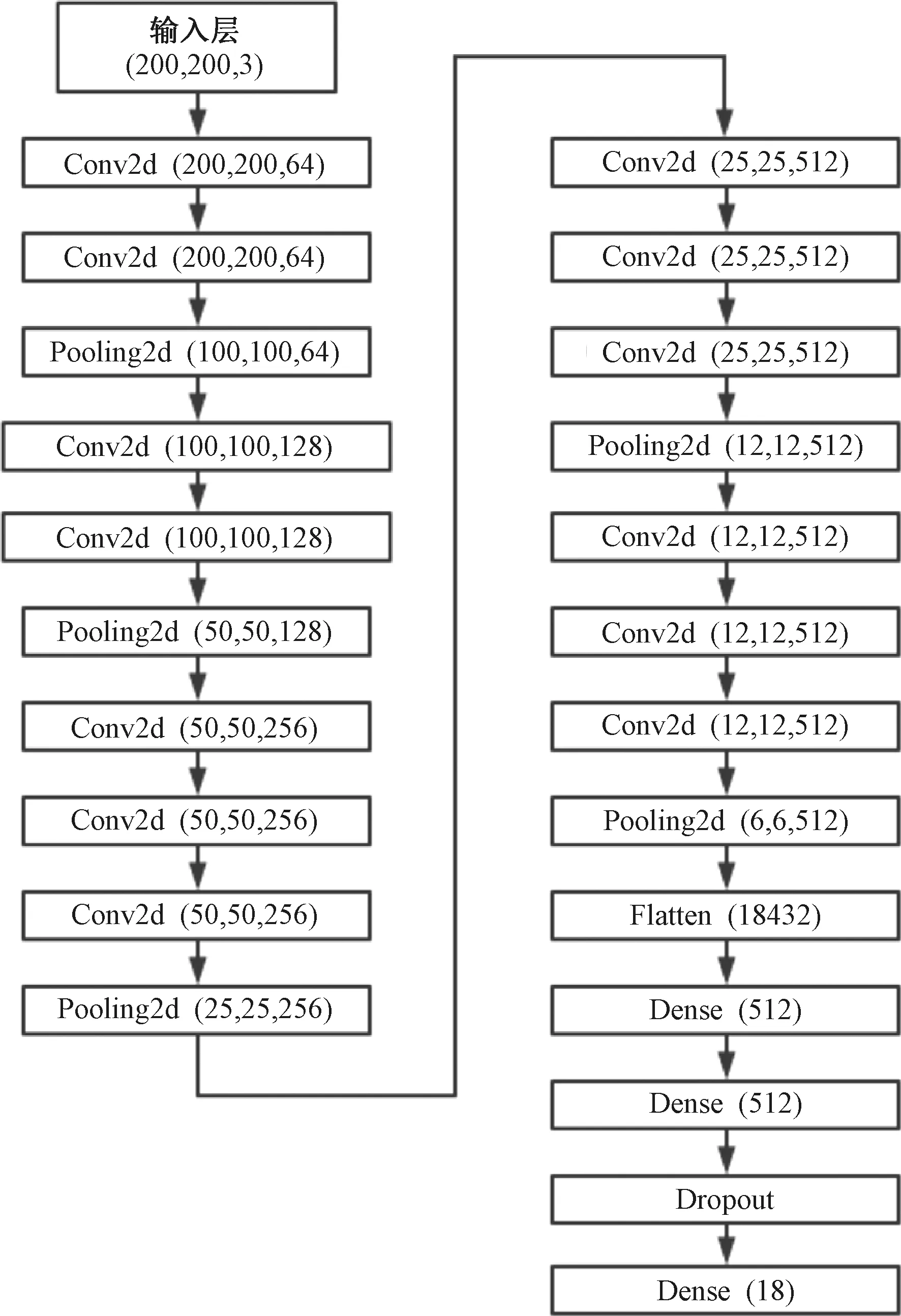
图4 迁移学习模型结构Fig.4 The structure of transfer learning model
在迁移学习模型训练中,将所有数据迭代完一遍称为一个epoch,计算一个epoch需要大约565 s,训练100个epoch后,训练集、验证集、测试集的岩性识别准确率分别达到99.7%,87.2%和87.3%。表2展示了迁移学习测试集中分类错误的岩屑图片分类及数量。
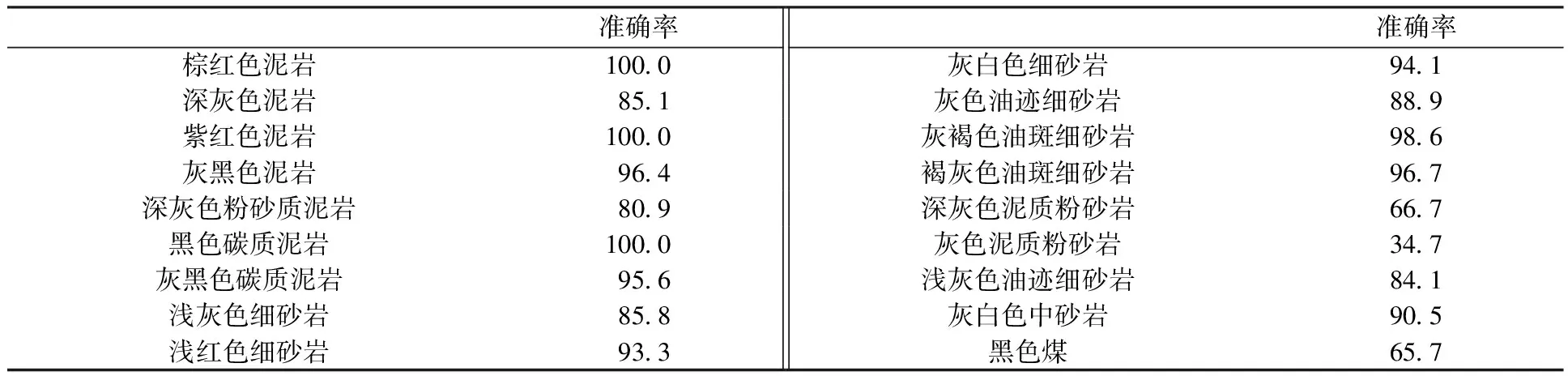
表2 迁移学习测试集准确率Table 2 Accuracy of transfer learning testing set %
图5展示了CNN模型和迁移学习模型训练过程,其中5(a)为CNN模型和迁移学习模型在训练学习岩屑图片时的精度曲线,5(b)为CNN模型和迁移学习模型在训练学习岩屑图片时的损失函数。通过比较,迁移学习模型的学习能力和泛化能力均优于CNN模型。
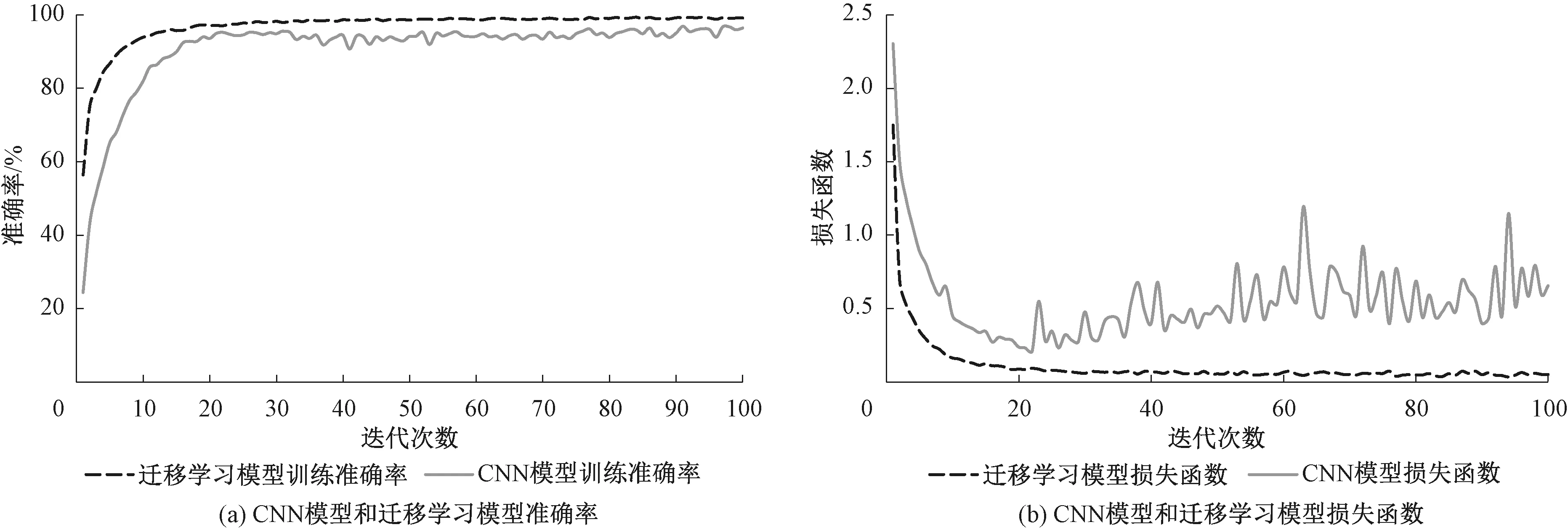
图5 CNN模型和迁移学习模型训练过程Fig.5 Train process of CNN model and transfer learning model
3 岩屑分类识别分析
本研究基于18种岩屑的5 877张岩屑图片建立训练集、验证集和测试集,使用卷积神经网络模型和岩屑图片迁移学习模型分别进行训练,再将训练好的模型分别对相同测试集进行验证,结果表明岩屑图片迁移学习模型能够更好地训练学习岩屑图片,并且有更好的泛化能力,即更好地分类识别新的岩屑图片。在识别测试集中的岩屑图片时,CNN模型的识别率较低,这是因为CNN模型需要足够的数据集进行学习,否则会出现过拟合的问题。而迁移学习模型事先学习训练过有相关性的图片数据集,所以初始的训练精度要更高,并且后续的训练精度也更高,在对测试集中的岩屑图片分类识别时岩性准确率能达到87.3%,有很好的泛化能力。本文对比了CNN模型和岩屑图片迁移学习模型的学习效率,迁移学习模型训练一次的时间更长。本文选用的VGG-16模型层数更多,参数更多,因此每一个epoch学习的时间更长。
表2展示了迁移学习在对岩屑图片测试集测试后的结果。模型对灰色泥质粉砂岩识别能力最差,准确率仅有34.7%,有一半被错划分为深灰色粉砂质泥岩,这是由于两种岩屑图片较像,可能在岩屑录井过程中有杂质渗入到灰色泥质粉砂岩中,对模型识别造成干扰。模型对深灰色泥质粉砂岩识别能力较差,准确率为66.7%,一方面是因为这类岩屑的图片太少,训练集仅有16张图片,导致了模型对该类岩屑识别不充分,造成过拟合,容易将它们错误分类到图片较多的那一类。模型对黑色煤的识别准确率也较差,因为黑色煤的图片质量较差,有大量杂质存在,对模型识别造成干扰。模型对泥岩的分类效果最好,识别率均能达到80%以上;对砂岩的分类效果较差,因为砂岩又分为细砂岩和中砂岩,粒径对模型的识别造成干扰。
4 结论
本研究基于18种岩屑的5 877张岩屑图片建立训练集、验证集和测试集,使用卷积神经网络模型和迁移学习模型分别进行训练,并用于相同测试集进行验证。结果表明,由于迁移学习模型使用了VGG-16模型,训练精度和识别效率均更高,避免了CNN模型的过拟合状况。迁移学习算法为岩屑分类识别提供了新思路和方案,同时模型通过计算机来提取图片特征,不需要工作人员手动分类处理,有效降低了主观因素对岩屑图片分类识别的影响,也大幅度降低了人工工作强度。
