基于希尔伯特相似度的云平台异常传输数据聚类方法
2023-11-07王宏杰徐胜超
王宏杰,徐胜超
(广州华商学院数据科学学院,广东 广州 511300)
0 引 言
在云平台高速发展下,对于大规模的数据传输和聚类需求也在不断增加。在这样的背景下,产生了以下2 个问题:1)传统的聚类算法已经无法满足当今的数据复杂度需求,对聚类算法的优化改进或者提出全新的算法迫在眉睫;2)在云平台传输数据的过程中会出现异常数据,因为相关数据差异化小,如何有效聚类异常传输数据也是一个难点问题。
国内相关专家针对云平台异常传输数据聚类方面的内容展开了大量研究[1-2],文献[3]提出了一种新的聚类算法,用于解决不确定数据流上的聚类问题,通过子窗口采样机制采集全部不确定流数据,统计网格内全部信息,为了获得高质量的聚类结果,它只存储新到达的数据,即“消除”过期数据;引入动态异常网格机制过滤离群点,完成数据流聚类。与同类算法相比,该算法具有更好的聚类效果和更快的聚类速度,并且具有更强的可扩展性,但是此方法对传输数据的聚类准确性较差。文献[4]提出了一种基于信息熵的加权块稀疏子空间聚类算法。引入信息熵权重与块对角约束,通过以上约束获取加权块稀疏子空间聚类参数,采用信息熵求得稀疏子空间中的最优近似解,此方法能够有效提升划分精度,但是此方法对传输数据的聚类划分耗时较长。文献[5]提出了一种K均值和马田系统相结合的聚类方法。优先通过K 均值聚类方法对全部数据聚类处理,得到K个初始类;检测全部初始类中的数据,删除异常数据,构建稳健马氏空间,经过计算得到各个数据在马氏空间对应的马氏距离,同时将其划分到距离最近的类中,最终实现聚类分析。此方法能够提升数据聚类分精度,但是使用范围具有一定局限性。
希尔伯特相似度相较于传统数据聚类方法,适用于高维面板数据,可利用傅里叶变换可视化样本间的差异。根据当前的数据聚类的优点与不足,本文提出一种基于希尔伯特相似度的云平台异常传输数据聚类方法。通过小波基分析云平台异常传输数据的敏感性,并进行对异常传输数据小波分解处理,实现云平台异常传输数据滤波。将数据映射到希尔伯特空间内,同时构建希尔伯特指数,获取指数的离散概率分布。计算数据的相似度取值,划分云平台异常传输数据,完成云平台异常传输数据聚类,有效提升了云平台异常传输数据的聚类效果。最后通过真实的实验数据验证了该方法的可行性和高效性。
1 云平台异常传输数据聚类研究
1.1 云平台异常传输数据采集
希尔伯特曲线是一个连续的分形空间填充曲线,在数据管理领域取得了十分广泛的应用。为了完成云平台异常传输数据聚类处理,首先需要获取云平台异常传输数据,将云平台异常传输数据映射到希尔伯特空间内,进而获取云平台异常传输数据集S,如公式(1):
通过公式(1)给出各个数据对象对应的希尔伯特指数计算式为:
其中,Ja,b代表希尔伯特指数;κ1和κ2代表不同子集;Gm,n代表数据集合的概率分布情况代表有限数据集的总数。
计算各个希尔伯特指数的离散概率ϖ()x,y,z的计算式为:
其中,x,y,z对应了希尔伯特空间内的3 个坐标轴位置数据,下文中x,y,z均代表此含义,故不在赘述。d(m,n)代表输入空间的巴氏距离;m,n分别表示数据节点位置。l(x)代表索引变量。就此,实现了云平台异常传输数据采集。
1.2 云平台异常传输数据滤波处理
为了更好完成云平台异常传输数据聚类处理[6-7],本文优先引入小波变换对云平台异常传输数据滤波处理[8-9]。小波变换是一种性能优越的去噪算法,在数据和图像领域均有应用,是通过伸缩和平移等相关操作实现云平台异常传输数据的多尺度细化处理,进而获取高低频部分,进一步对高低频部分细化处理,即可获取对应数据的细节信息。小波分析理论在信号以及语音分析等领域均取得了十分广泛的应用。
设定代表平方可积函数,则傅里叶变换β(x,y)需要满足公式(4)中的约束条件ψ:
其中,δ代表尺度因子;α代表平移因子。
为了全面简化计算机的计算流程,需要离散化处理全部连续小波。离散化处理主要是针对上述2 种不同的因子。将二进制动态网络应用于小波变换过程中[10-11],即可得到二进制小波变换R(i,j),对应的表达式为:
其中,τij(u,v)代表滑动因子系数。
现阶段,部分关于数据的去噪方法具有一定的局限性[12-13],主要是针对部分噪声。但是采用小波变换展开去噪方法处理不仅可以获取满意的去噪效果,同时运行速度也优于其它方法。优先对含有噪声的云平台异常传输数据展开小波变换操作,获取小波系数,对小波系数进一步处理,即可获取最新的小波系数,将小波系数重构就可以获取去噪后的数据。其中,云平台异常传输数据噪声检测模型ρ(i)可以表示为公式(7)的形式:
其中,t(i)代表含有噪声的云平台异常传输数据;ϑ(i)代表真实云平台异常传输数据。选择一个合适的小波基,通过小波基对云平台异常传输数据分解处理,分解过程如图1所示。

图1 云平台异常传输数据分解示意图
完成云平台异常传输数据分解处理后,选择合适的小波基确定分解层次,同时对数据展开多层次分解处理H(η),对应的计算公式为:
其中,η表示具体的层级,在确定阈值后,通过选定的阈值对全部高频系数展开软阈值量化处理ϖx,y,对应的计算公式为:
接着计算全部小波基分析云平台异常传输数据的敏感性,将其排序处理,选择敏感性最低的小波基云平台异常传输数据展开小波分解处理,进而重构高低频部分,最终实现云平台异常传输数据滤波处理[14-15]。
1.3 考虑希尔伯特相似度的数据聚类
根据1.2 节得到无滤波的平台异常传输数据处理。在云平台异常传输数据聚类中[16-17],希尔伯特相似度也是一项重要的指标,相似度计算结果的好坏会影响最终的聚类结果。由于数据属性不同,需要根据数据属性展开相似度计算,主要为:
1)如果确认数据为数值型数据,在数据对象属性值完全相同的情况下实施相似度计算,进而获取全部目标数据的空间距离相似度。
2)如果数据对象为二元型数据,数据对象1 和数据对象2 属性完全一致的情况下,两者的相似度取值为1;如果两者的属性值不同,则相似度取值为0。
3)如果数据为分类型数据,可以将其看做是二元型数据的拓展,可以同时包含多个不同的状态值,需要根据数据对象的维度取值确定最终的相似度计算结果[18-19]。
通过公式(7)中的数据集合,在数据集合中选取2 个数据对象,通过公式(10)计算两者的欧氏距离
其中,(xz,yz)表示希尔伯特空间内x、y轴映射在Z轴上的投影,在相同属性内,随机2 个数据属性值之间的耦合计算公式Z(e)为:
其中,ςmn代表属性集合总数;sl代表数据中心点迭代总次数。
在设定条件下,全部数据对象的邻域半径可以表示为公式(12)的形式:
其中,rxyz代表邻域半径;aver 代表邻域调节系数;met代表属性值在设定区域内出现的次数。
在希尔伯特空间内,从云平台异常传输数据的第一列属性开始,需要展开相似度计算,选取该属性作为第一个数据集。根据聚类算法的操作原则,将得到的新数据集划分为多个簇。
完成上述操作后,设定各个簇中全部数据对象的属性值采用相同的数字替换,但是同一列中不同簇需要采用不同的数字表示。同时将数字替换后的列存储到数据矩阵Data(i,j)中,对应的表达式为:
其中,i、j分别表示为属性类型。完成上述操作后,需要在希尔伯特空间内计算各个数据相似度[20-21]。在计算过程中,不仅涉及数据维数的重要程度,同时还显现了数据维数的重要性,根据维数的设定达到某些目的。假设赋予第i种属性的权值为σ(i),则第i种属性与第j种属性的相似性度量函数σ(i,j)如公式(14):
其中,θ(xi)代表时间复杂度。根据矩阵更新原则,引入最小值原理,计算对象合并处理之后和其他对象的相似度Similarity(i,j),选取两者中取值最小的相似度数值作为合并后的相似性数值[22-23],经过上述分析,根据全部数据对象的相似度计算结果,将相似度取值接近的数据划分到同一个数据集内,进而确定云平台异常传输数据,最终完成云平台异常传输数据聚类。
2 实验结果与分析
2.1 异常传输数据聚类结果对比
为了验证本文基于希尔伯特相似度的云平台异常传输数据聚类方法的有效性,实验在Matlab平台展开。实验数据来自Wine数据集和Iris数据集。测试环境基于公司私有云,表1为系统测试环境硬件配置,集群使用了2 台服务器,服务器的硬件配置为每台8 核CPU、12 GB 内存、25 GB固态硬盘。测试环境中一共部署10 个Redis 集群,采用Docker 方式部署在Kubernetes集群中,宿主机总内存为250 GB。每个Redis集群由4个分片组成,总内存为40 GB,每个分片内包含1个主节点,1个从节点,每个节点内存都是10 GB。
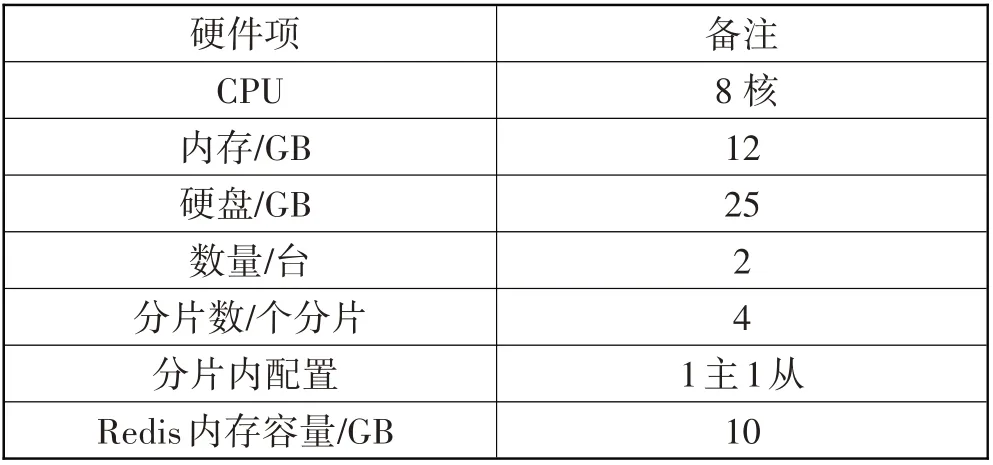
表1 硬件和环境配置
选取多个数据样本作为测试对象,对各个方法的性能展开聚类分析,详细的实验测试结果如图2所示。
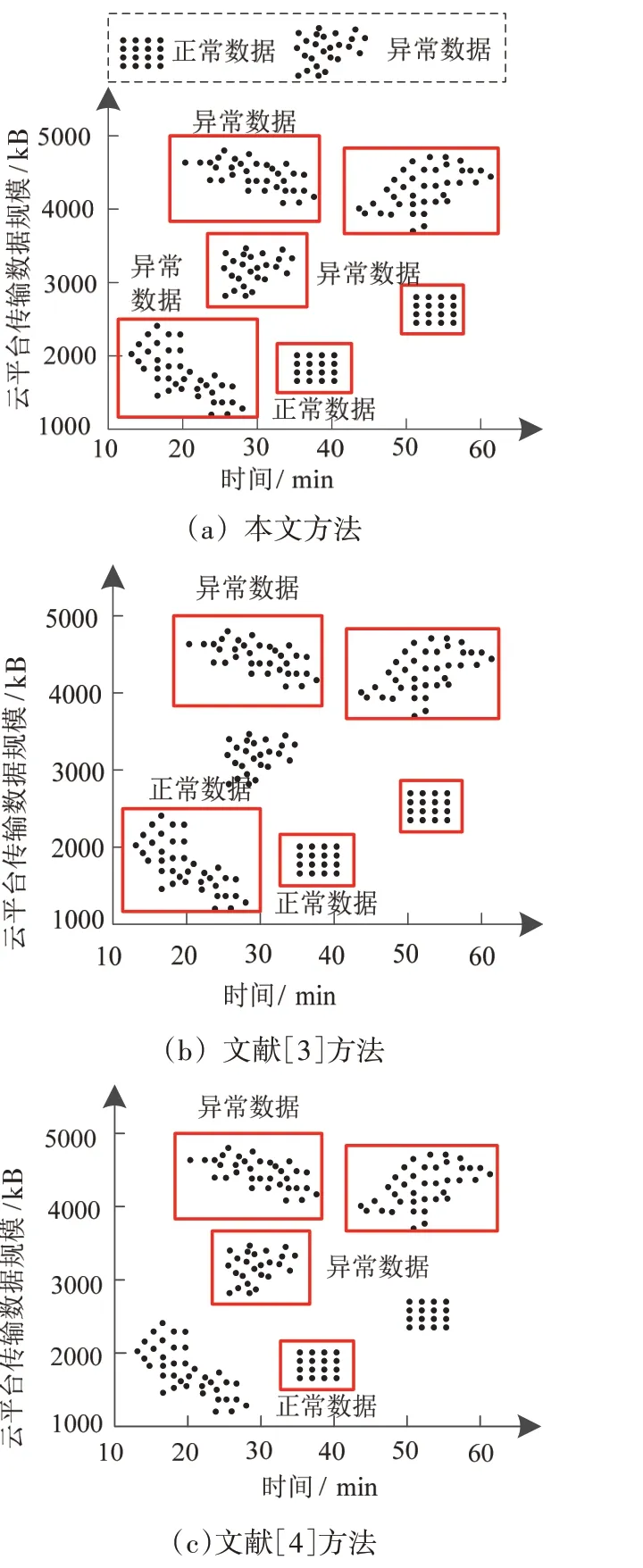
图2 云平台异常传输数据聚类结果
分析图2 中的实验数据可知,采用本文方法可以对全部数据样本进行聚类处理,同时可以获取比较好的聚类结果,准确区分云平台传输数据中的异常部分。而采用文献[3]方法和文献[4]方法聚类过程中,会存在聚类错误或者无法聚类的效果。经过对比可知,本文方法可以更好地完成云平台异常传输数据聚类。这是因为本文方法通过计算希尔伯特空间内的相似度取值,划分到同一个数据集内,可准确划分云平台异常传输数据,提升了数据聚类效果。
2.2 正确聚类数据数量对比
本文选取多个数据样本作为测试对象,对各个方法的性能展开聚类分析,详细的正确聚类数据数量如表2所示。
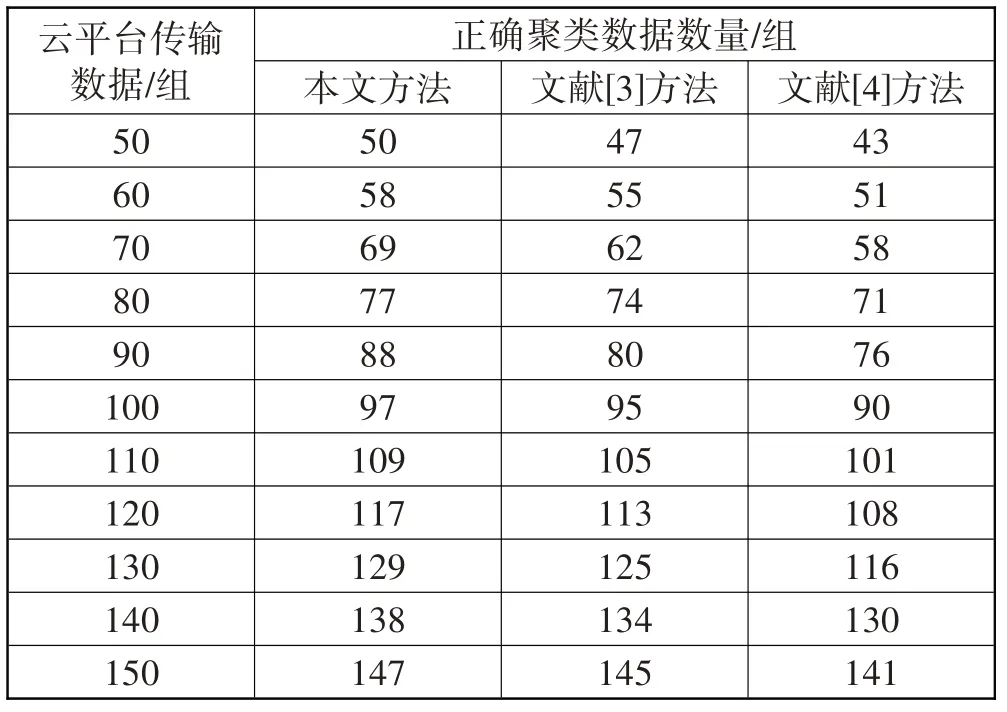
表2 不同方法的聚类结果对比
由表2 可知,当云平台传输总数据为50 组时,本文方法的正确聚类数据数量为50 组,文献[3]方法的正确聚类数据数量为47 组,文献[4]方法的正确聚类数据数量为43 组;当云平台传输总数据为100 组时,本文方法的正确聚类数据数量为97 组,文献[3]方法的正确聚类数据数量为95 组,文献[4]方法的正确聚类数据数量为90 组;在数据不断增加的状态下,各个方法的云平台异常传输数据聚类精度会受到不同程度的影响。但是,本文方法可以以较高的精度完成云平台异常传输数据聚类,本文方法将采集到的数据映射到希尔伯特空间内,通过构建希尔伯特指数,获取指数的离散概率分布,进一步提升了本文方法的聚类精度。
2.3 异常传输数据聚类速度对比
在本文实验过程中,选择2 个不同的数据集展开测试,选取运行时间作为测试指标,运行时间越短,则说明云平台异常传输数据聚类速度就越快。
1)Wine数据集。
在Wine数据集中,异常传输数据聚类耗时见图3。

图3 Wine数据集中异常传输数据聚类耗时
分析图3中的实验数据可知,当运行次数为10次时,文献[3]方法的异常传输数据聚类耗时为192 s,文献[4]方法的异常传输数据聚类耗时为213 s,本文方法的异常传输数据聚类耗时仅为175 s;当运行次数为30 次时,文献[3]方法的异常传输数据聚类耗时为198 s,文献[4]方法的异常传输数据聚类耗时为200 s,本文方法的异常传输数据聚类耗时仅为146 s;本文方法在Wine 数据集下始终具有更低的聚类耗时,这是因为本文利用小波基分析云平台异常传输数据的敏感性,对异常传输数据小波分解处理,计算了希尔伯特空间内的相似度取值,准确划分了云平台异常传输数据,提升了异常传输数据聚类速度。
2)Iris数据集。
在Iris数据集中,异常传输数据聚类耗时见图4。
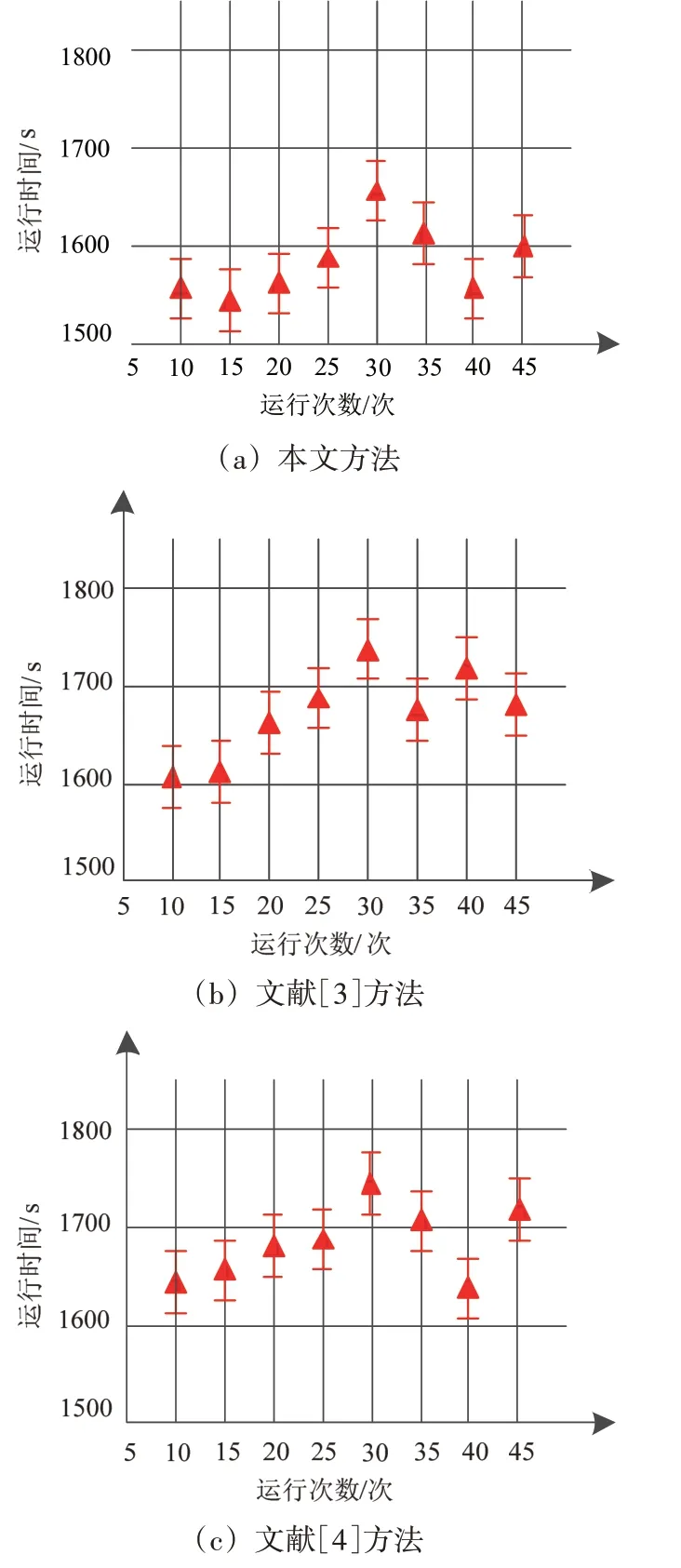
图4 Iris数据集中异常传输数据聚类耗时
分析图4 中的实验数据可知,由于测试的数据集不同,进而获取的执行时间结果也不同。由于Wine 数据集的规模比较小,得到的云平台异常传输数据聚类运行时间相对偏低一些;而Iris 数据集的规模比较大,进而执行时间相对偏高。对比3 种不同方法可知,本文方法在各个数据集上的云平台异常传输数据聚类运行时间均低于另外2 种方法。由此可见,本文方法可以有效提升云平台异常传输数据聚类运行效率,全面验证了本文方法的优越性。
3 结束语
本文提出了一种基于希尔伯特相似度的云平台异常传输数据聚类方法,并采集云平台异常传输数据,将采集到的数据映射到希尔伯特空间内,同时构建希尔伯特指数,利用小波基分析云平台异常传输数据的敏感性,选取敏感度比较低的小波基对异常传输数据小波分解处理,计算全部数据在希尔伯特空间内的相似度取值,将相似度取值接近的数据划分到同一个数据集内,准确划分云平台异常传输数据,进而达到云平台异常传输数据聚类的目的。
由于数据爆炸式增加,虽然本文方法取得了比较满意的研究成果,但是仍然存在不足,后续将引入各种优化算法,对其展开深入优化,使其综合性能得到有效提升[24-27]。
