基于EMD-RF算法的重介精煤灰分预测研究
2023-11-04孟巧荣王然风
李 哲,孟巧荣,王然风,付 翔,程 凯,王 珺
(太原理工大学 矿业工程学院,山西 太原 030024)
随着我国能源结构的进一步优化,洁净煤技术的发展成为提高煤质的重要举措[1,2]。国家最新战略规划要求各选煤厂在大方向上由信息化逐步向智能化过渡[3]。重介质分选是煤炭分选的主要工艺之一,其原理是通过离心力和重力双重作用实现煤矸分离[4]。重介质旋流器具有较高的分选精度,较强的适应能力,较宽的悬浮液密度可调节范围以及较大的工业处理量等特点[5]。
传统重介分选过程的灰分控制都属于未建模控制,而对于重介分选过程来说,建立数学模型在实验研究中进行仿真是有必要的。赵春祥根据重选控制流程中各工艺环节物理参数间的动态平衡关系,提出具有普遍意义的重介质选煤过程的数学模型,准确描述出控制系统中控制变量和被控制变量之间的函数关系[6]。邱佳楷为满足原煤煤质变化对重介质悬浮液密度大范围调节的需求,在重介质分选过程中采用反分流工艺,设计了密度宽域智能控制机理建模[7]。王光辉等结合机理研究、大数据分析以及人工智能算法,建立出一个由机理过程和数据综合驱动的重介质选煤过程数学模型[8]。这些研究都基于工艺流程对重介质分选做出了机理建模。但是前述文献的机理建模没有全面涵盖重介生产全部工艺环节,特别是对于重介精煤在带式输送机传输这一过程,不考虑这个环节就难以科学准确建模,也为后续基于灰分仪的闭环控制带来了挑战。同时,所需的工业参数单靠现场经验难以界定,且对于灰分测量时滞这一重点问题没有给出有效的解决办法。代伟与张凌智等人给出了一个由基于数据的虚拟未建立动态补偿器所构建的自适应运动反馈控制方式及其稳定性分析理论研究[9]。程凯根据重介精煤灰分数据噪声特性和灰分回控过程中控制对灰分预测精度、预测时间的需求,给出了基于EMD-LSTM的重介精煤灰分时间序列预测方案[10],通过基于控制过程的预测,得出利用EMD方法将灰分数据进行降噪处理后所得结果较好,但并没有建立关于重介分选系统的数学模型。
本研究在前人研究基础上尝试建立具有灰分预测效果的模型:即利用随机森林建模的方式[11,12],跳过包含人工操作、煤质波动、工况变化在内的所有影响因素直接构建关于输入与输出的数学模型,并在训练模型的过程中将t+T时刻的精煤灰分值前置一段时间T再去对应t时刻输入数据,以此消除灰分测量时滞给控制系统带来的不稳定性。
1 基于EMD-RF的精煤灰分闭环控制流程
传统重介质选煤过程中利用灰分仪测出灰分再对控制系统做出反馈,而灰分检测仪在工业中一般有十几分钟的系统延迟,要使工业现场高效稳定运行就需要控制系统能够提前感知到灰分的变化,而本文提出的通过随机森林建模[13-17]跳过控制流程,利用系统的输入输出值来建立数学模型,从而改善工业现场由于灰分测量的延迟时间而造成的控制系统难以稳定运行的现状。控制流程如图1所示,通过密度计、磁性物含量仪、灰分仪分别测得的数据m、n、h作为随机森林模型训练集,在煤质信息改变、工况变化或有其他原因造成模型误差过大时闭合开关A进行模型更新。
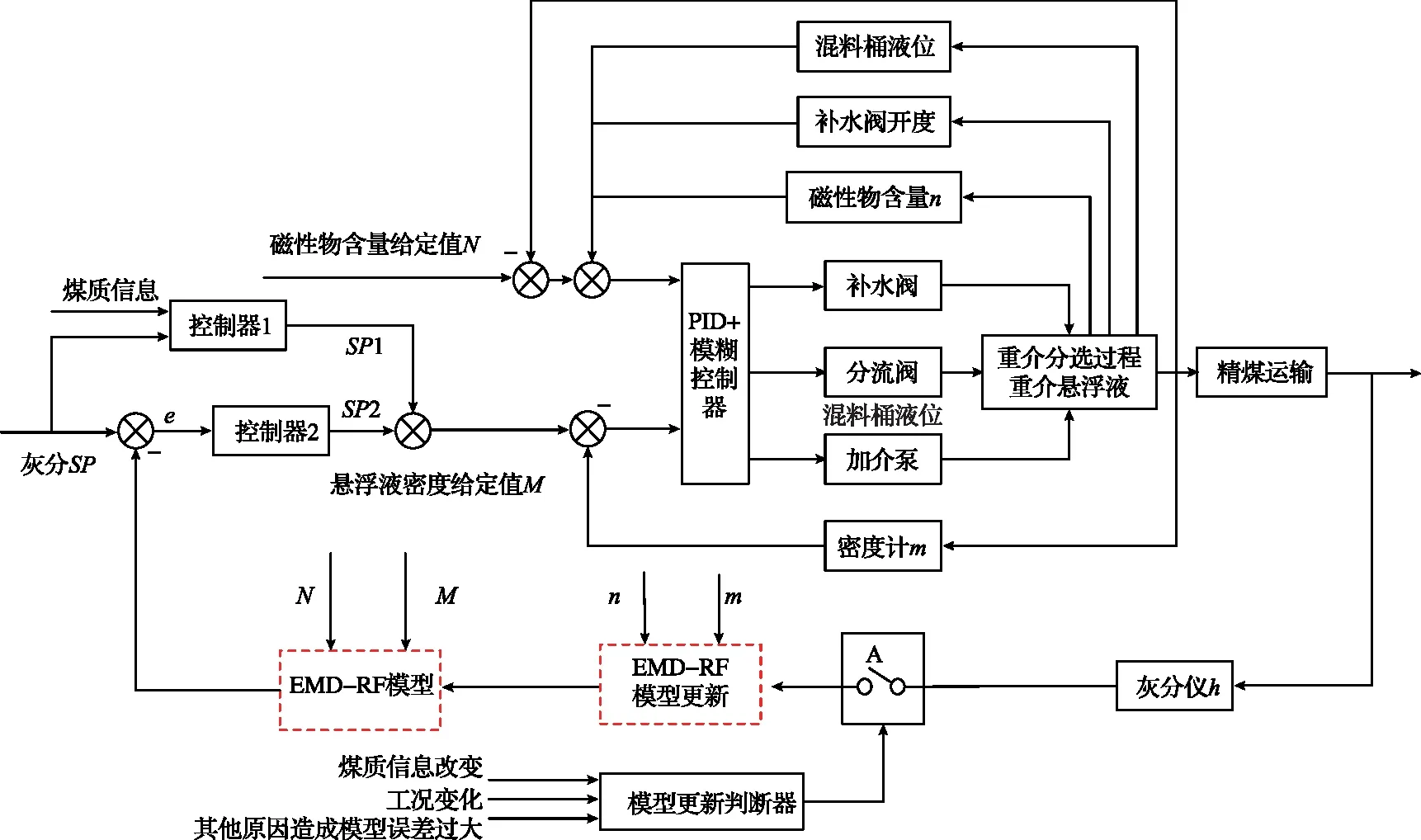
图1 重介分选控制流程
2 基于EMD-RF算法的灰分控制建模
建立经验模态分解-随机森林模型主要有四个阶段,分别是:对现场数据进行灰分前置对应(即上文提到的用t时刻的输入m、n对应t+T时刻的输出h)、进行有效特征提取得到高相关度数据集作为模型训练集、训练随机森林模型和测试随机森林模型。
2.1 数据采集及预处理
本研究选取中兴选煤厂某天连续5 h自动控制生产下的重介分选流程数据,其样分布如图2所示,数据均位于合理区间,符合正态分布规律。

图2 样本分布情况
将取得的数据设置为三个不同样本容量的对照组,分别为:0~100 min,0~200 min,0~300 min。通过在中兴选煤厂的现场测量,已知该工业现场磁性物含量、密度、灰分数据以及灰分回控的13 min延迟时间。为了消除模型中的延迟环节,首先将灰分数据前置13 min与输入(密度数据、磁性物含量数据)部分相对应。由于现场采回的煤质信号含有过多的高频细节信息,且有一些因为工艺或设备故障等问题或造成的突变及扰动,而在基于RF算法进行系统建模时,如果用于训练模型的数据变化过于突然,会导致训练效果较差。所以需要先将从工业现场采回的样本做EMD[18-22]信号分解进行数据降噪预处理。
2.2 EMD算法及流程
EMD依靠精煤数据本身的时间尺度特性进行,基函数无需提前设定。这一特点与傅里叶分解、小波分解有着本质性的差别。也正因为它的这种特点,使得EMD在理论上可以被用来处理任何类型的信号,包括在处理分析极不平稳的非线性信号时,EMD也能保证具有较高的分解精度,即信噪比。以精煤灰分信号为例,通过EMD分解得到一些精煤煤质信号的分量信息。数据处理流程如图3所示。

图3 EMD处理流程
其中分解步骤如下:
1)原始灰分信号h(t)的极大值和极小值点,并对这一系列极值点进行拟合,得到灰分信号的上下包络线hmin(t)和hmax(t)。
2)求上下包络线的均值:
3)对于非平稳信号,信号不是在某一个区域内单调递增的,会出现拐点。这些能反映原始信号h(t)的具体特征的拐点若未被选中,则得到的第一阶模态函数并不准确,也就是通常得到的d1(t)不满足IMF的两个条件,需要继续进行筛选。
4)对所剩信号d1(t)进行步骤1)—3)的处理,当SD小于门限值(一般为0.2~0.3)时停止,这样取到最合适的第一阶模态分量,IMF1。筛分门限值SD求法如下:
5)对灰分信号h(t)与IMF1作差得到r1(t),并将这一残差量代替原始灰分信号h(t)重复步骤1)—5),重复n次后即可得到符合要求的残差值rn(t)。此时得到原始灰分信号经过EMD分解后可表示为:
将灰分数据进行EMD分解后所得分量如图4所示。

图4 灰分数据EMD分量
计算灰分分量特征的Pearson相关系数,并根据相关系数的大小进行排列,见表1。相关系数在这里用来描述IMF分量与原始数据的相关程度,相关系数的绝对值越大,相关性越强:相关系数越接近于1或-1,相关度越强,相关系数越接近于0,相关度越弱。灰分分量特征中IMF1的Pearson相关系数0.693明显低于其余分量,其余四维特征的相关系数都在0.8以上,与原始数据有极强相关性。所以将这四维分量值作为进行重构得到模型训练集。即将精煤灰分信号中所含的高频噪声信号IMF1去除,保留频率较低的近似趋势曲线IMF2—IMF4。将煤质信号分解后的分量按此原则有选择地进行重构,重构后的灰分图像与原始灰分数据对比如图5所示。

表1 精煤灰分值相关系数对比
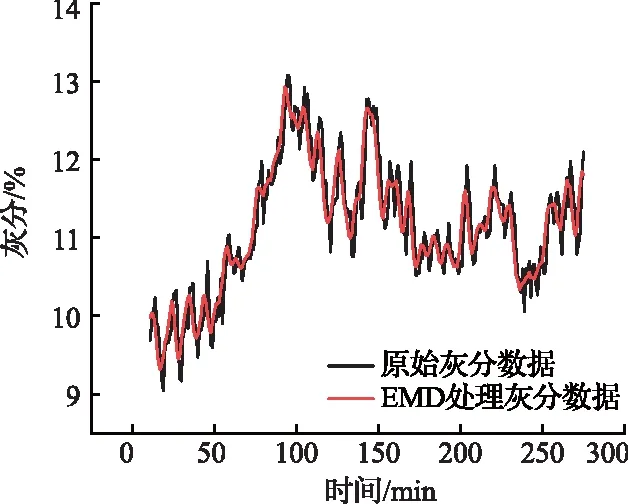
图5 原始灰分与EMD处理灰分对比
按上述方法分别将磁性物含量数据与密度数据进行EMD分解,并根据分量的相关性强弱进行选择,最后将相关性较高的分量进行重构得到处理后的数据,配合灰分值数据作为模型训练集。处理后的数据与原始数据对比如图6、图7所示。
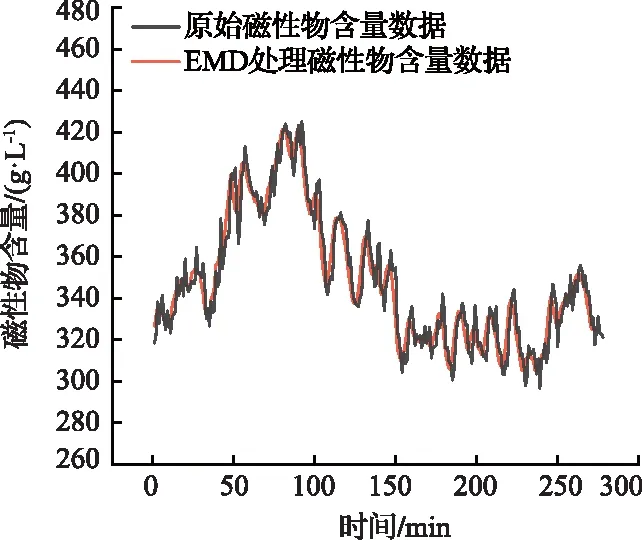
图6 原始磁性物含量与EMD处理后对比
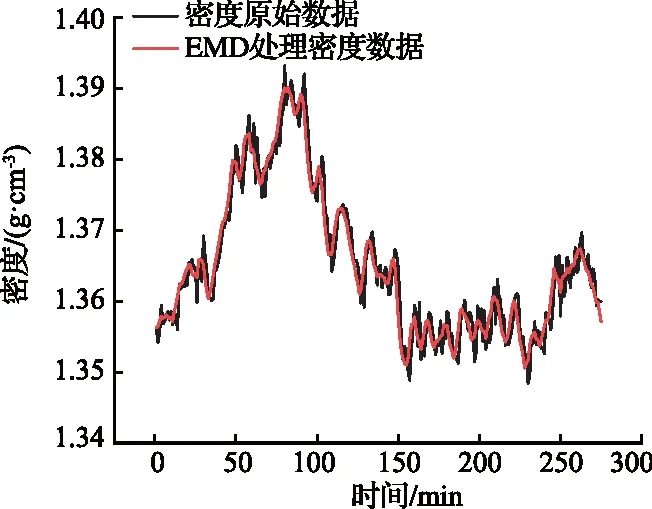
图7 原始密度与EMD处理密度对比
2.3 EMD-RF建模流程
随机森林算法(RF)是由多个决策树组成的一种智能集成学习算法。决策树(Classification and Regression Trees,CART)是一种统计模型,此类模型在输入特征后可得到不同类或值。决策树结构如同一棵树,包含内部节点、分支和叶节点。内部节点表示属性,分支表示属性测试,叶节点表示沿某一条路径的属性测试值。
Gn={(X1,Y1),(X2,Y2),…(Xn,Yn)}
(4)
式中,X为包含m个特征的输入向量;Y为输出值;Gn为由n个观测值组成的训练集。训练过程中首先将X划分为两簇分支,为趋于最优化划分,采用叶节点方差确定划分点k和阈值D,叶节点p的方差定义为:
式中,YP为叶节点p截止到Yi的平均值。然后,继续以相同的方式划分下一级叶节点,直至预设的节点阈值,训练停止。训练结束后建立估计函数S,新的X可以通过S得到估计值Y。
随机森林算法将多个决策树组合在一起,实现数据分类或回归,其调节参数少、训练速度快、估计精度高、泛化能力强。该算法通过Bootstrap抽样法从原始数据中抽取多个样本数据,构造新的训练样本集合。基于CART思想对每个训练集建立决策树。最终,根据q棵决策树的结果求平均,得出最终估计值Y为:
RF算法原理如下:①基于Bootstrap抽样法在原始数据Gn中提取q个训练样本集,即构建q棵决策树;②每棵树有m个特征变量,在每个节点处随机选取r个特征变量,继而选择最佳分割点;③决策树分裂达到预定的节点阈值后停止生长;④每棵树的估计值求平均得出最终估计值。建模流程如图8所示。
3 模型评价指标对比
利用方均根误差(RMSE)、平均绝对误差(MAE)和计算时间作为模型评价的指标。其中:

3.1 不同数据量下的 EMD-RF模型精度对比
用前文设置的三个不同样本容量的训练集进行相同的EMD-RF模型训练流程,并将三个模型分别命名为:RF1,RF2,RF3。分别计算三个模型的评价指标数据,见表2。
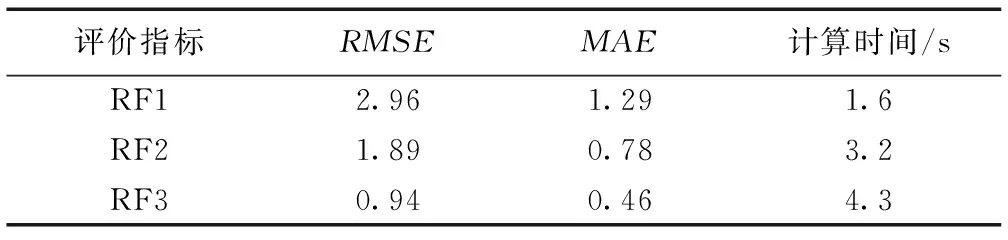
表2 三种模型的估计误差与计算时间对比
从表2可以得出,随着样本容量的增大,随机森林模型的RMSE、MAE数值逐渐减小,并在三百组样本时取到最佳的评价数据,计算时间也较为合理,所以取该样本容量所建模型与其余机器学习算法进行对比。
3.2 不同机器学习回归算法的对比
将几种较为常见的机器学习回归算法进行了拟合度对比,包括BP神经网络、基于最小二乘法的有源自回归模型(ARX)、传递函数模型(TF)及随机森林(RF)算法建模。
将同样基于最小二乘法原理训练所得模型(ARX,TF)代入测试集进行测试,如图9所示,由曲线可以直观看出这两种模型对测试集灰分的估计有较为严重的失真,分别将BP神经网络和随机森林算法也用同样一组数据进行测试,如图10所示。并分别计算出四种机器学习的评价指标数据,见表3。对比图9、图10可以明显看出后两种机器学习算法要优于前两种。

表3 几种模型的估计误差与计算时间对比

图9 ARX和TF模型估计值测试结果

图10 BP和RF模型估计值测试结果
经过对比可知,随机森林模型的RMSE和MAE数值分别为0.94和0.46,均为几种模型中的最低值,基于最小二乘的两种模型的计算时间最短,但由于模型较为简单,导致估算的误差较大。尽管RF3模型计算时间较长,但也处于能够接受的范围。由于未采样部分数据能保证模型的泛化能力,所以随机森林对精煤灰分值的估计相较于其他回归算法的精度更高。
4 工业现场应用
取2021年山西焦煤集团中兴选煤厂两段相似工况进行对比,已知现场精煤产品灰分目标均值为11%,合格区间为10.5%~11.5%。当现场目标灰分值发生调整时,采用基于EMD-RF算法的建模能够有效降低控制系统响应时间,保持灰分响应曲线平稳变化,且总体收敛度维持于合格区间内,将精煤灰分值基本控制在10.6%~11.4%区间内。而没有采用模型的系统在相似工况下,灰分值调整较慢,且收敛程度明显较弱。对比如图11所示。加入RF模型相较于无模型指导下的生产效果有明显改善。

图11 加入指导模型前后工业运行对比
5 结 论
1)训练集数据将灰分数据做了前置对应,可以在一定程度上消除灰分测量时滞过大造成的控制系统误差。
2)利用基于EMD-RF算法的模型训练方法得到的灰分估计模型,RMSE和MAE数值分别为0.94和0.46,这两项指标评价相较于其他机器学习算法能达到较高水平,且计算时间维持在合理范围内。
3)利用EMD-RF算法建立的模型应用于指导工业生产时,能较好地将精煤灰分值控制在合理区间内。相较于无模型指导下的生产效果有明显提升。
