对比式自监督视觉表征学习研究综述
2023-11-04刘相均
刘相均
(广东技术师范大学,广东 广州 510665)
近些年,自监督学习(Self-supervised Learning,SSL)在图像分类、图像分割、目标检测等计算机视觉任务中表现出了优异的表征学习能力,广受研究者们的关注。而对比学习(Contrastive Learning,CL)作为一种极具代表性的SSL 方法,在自然图像领域取得了进一步成功。与全监督学习不同,CL 方法不需要标注数据,其本身可以利用大量的无标注数据来学习图像的特征表示。CL 的核心思想是通过数据增强构造样本的多样性,利用损失函数在投影的嵌入空间中构造距离近的相似(正)样本对,同时构建距离相对远的不同(负)样本对,从而学习到不同数据样本之间的相对关系表达。本文将从CL 的发展历程,CL 的基本原理以及不同CL 算法的比较三个方面进行阐述,然后进行总结,旨在帮助后续的研究者们能够快速地对CL算法有一个大致了解。
1 对比学习的发展历程
最早的CL 方法可以追溯到基于Siamese 网络和三元组网络的方法,这些方法主要应用于验证和检索任务。而随着深度学习的发展,特别是基于深度神经网络的无监督预训练方法的兴起,在计算机视觉领域中,对比学习逐渐受到广泛关注,在2018 年Wu 等人[1]提出了InstDisc(Instance Discrimination)模型,采用了Memory bank 来存储编码器计算得到的表征向量,由此开启了基于正负样本对的对比学习研究思路。随后,一系列基于对比学习的预训练方法相继提出,如MoCo[2]、SimCLR[3]、SwAV[4]等。这些方法都通过对数据样本之间的关系进行建模来实现特征学习,并在多个视觉任务上取得了优异的效果。随着Transformer 在视觉领域的热门,研究者尝试利用Transformer 的自注意力提取方式进行对比学习的研究,在2021 年SwAV的作者提出了DINO[5]模型。随后在2022 年Peng 等人[6]考虑了随机采样这一增强操作对于视图质量的影响,提出了训练预热Grad-CAM 定位ROI 区域,然后在定位区域内进行中心压制采样的方法,该方法为CL 算法的增强视图提供了更加丰富的图像对比信息,使得CL 算法更具鲁棒性。
2 对比学习原理
对比学习的学习模式可以抽象为通过编码器-解码器的架构将图像Embedding 排列到嵌入空间中,通过在嵌入空间中的关系来判断图像间的相似性。其中最优特征嵌入是通过实例级判别来学习的,如图1所示,该判别试图最大限度地将训练样本的特征分散在单位球面上。假设输入一个批次的图像,首先使用数据增强策略得到同批次大小的增强视图队列,使用主干CNN网络将两部分批次图像编码为特征向量,然后通过投影层计算使得向量均匀分布,最后将其投影到高维空间并通过相似度损失函数进行归一化聚集。图1 中示例的三组向量表示组内近似,而三组向量相互之间是非近似状态。
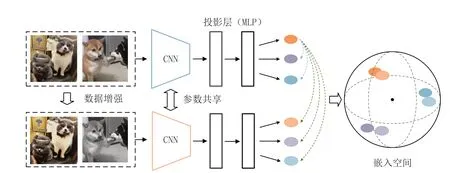
图1 CL 算法示意图
从得到的嵌入表征向量损失计算观察,对比学习旨在通过噪声对比估计(Noise Contrastive Estimation,NCE)进行学习比较,其中x、x+以及x-表示输入,x+与x为正样本对,x-与x为负样本对,f表示编码器。由于在实际训练过程中可能涉及很多不相似对,而衍生出了InfoNCE 损失函数,其具体公式的表达形式为:
通过以上的损失函数,CL 模型不断地将编码器参数更新,使得CL 算法所构建的相似正样本对更加接近,而不同的负样本对更加远离,从而实现无监督条件下对图像的表征学习。
3 不同对比学习算法的分析
目前已经发展出了不少对比学习算法,不同对比学习算法各有优劣,在具体使用时需要根据任务和数据集的特点进行选择和调整。在这我们分析极具代表性的三种暹罗网络结构的模型MoCo、SimCLR 和BYOL[7](如图2)。MoCo 提出了使用基于动量对比的表征一致性来实现实例区分,利用记忆体(memory bank)形式来进行编码存储。尽管MoCo 取得了很好的效果,但是其采样方式使得区分正样本对过于简单,需要进一步探索更高效的正样本对采样策略来提升模型的性能。SimCLR 提出使用多种数据增强方法增加输入图像的多样复杂性,不同于MoCo 模型,SimCLR 直接使用当前批次的记忆体内负样本,但这导致了训练需要使用较大批次的样本容量。此外,SimCLR 还提供了一些技术思路,包括在编码器中添加非线性映射、使用更深的backbone 网络等。

图2 暹罗网络体系对比算法结构演化
BYOL 吸收了MoCo 和SimCLR 的特点并改进,取得了比二者更好的性能。BYOL 只采用了正样本对,使用随机初始化的网络作为目标编码器,然后将其逐渐替换为经过训练的查询编码器来迭代训练。BYOL 还采用了回归范式的损失计算,使用均方差来度量预测值和目标值之间的差异。通过这些改进,BYOL 取得了很好的表现。BYOL 的设计清晰简洁、方法独特,为对比学习领域的研究提供了一种有效的方法。
一般来说,暹罗结构形式的CL 网络适用于小规模数据集和特定领域,而BYOL 和DINO 等方法则更适合大规模无监督学习和跨领域表示学习。我们在以下列举了一些CL 算法,见表1。其中主要比较了不同的CL算法的核心思想的转变和随着新技术的改进。
4 总结
本文对目前对比学习的发展、原理以及一些CL 算法的设计创新做出了简要概括,尽管由于不同的体系结构和实现,我们很难详细比较这些方法的性能,但根据这些CL 算法的设计思路可以总结出对比学习的主要发展的趋势。当前对比学习面临的挑战如下:
1.数据噪声:CL 方法都要求使用大量的训练数据,但这些数据往往会存在一定的噪声和错误,这会使模型在学习和推断时产生不良影响。如何消除数据噪声和错误,提高数据的质量和可靠性,是对比学习领域需要解决的问题。
2.训练效率:对比学习方法往往需要进行大量的重复计算和参数更新,对计算资源和存储能力要求很高,这会导致训练和资源成本的增加。如何提高对比学习的训练效率,是未来需要面对的挑战。
3.多模态学习:大多数对比学习方法只是在单个模态上进行学习,如图像或文本等。但在实际应用中,我们需要对不同模态的数据进行分析。如何将对比学习扩展到不同模态数据之间进行学习,也是未来的一个重要方向。
4.泛化性能:对比学习方法往往是在特定数据集和任务上进行训练和评估的,但这些方法是否具有比较好的泛化性能,即是否可以在不同数据集和任务上进行推广,仍然需要进一步的探索。
总的来说,对比学习需要解决的挑战包括数据噪声、训练效率、多模态学习和泛化性能等,在未来通过开展更多的研究和实践,对比学习有望在更广泛的场景中发挥重要的作用。
