基于sCARS-PSO-SVM的土壤硒含量高光谱定量反演
2023-11-03王正海曹海玲苏文林
谢 鹏, 王正海, 肖 蓓, 曹海玲, 黄 意, 苏文林
中山大学地球科学与工程学院, 广东 广州 510275
引 言
硒(Se)是与人体健康密切相关的微量生命元素之一[1-2], 例如, 食用过量硒会导致硒中毒[3], 缺乏硒会导致人体产生克山、 大骨节等疾病[4]。 人体补充硒最稳妥的方式是食用含硒农产品, 而农产品中硒的含量在很大程度上受限于土壤中硒元素的含量及分布。 因此, 确定土壤中硒的含量和分布情况, 对人的生命健康具有重要意义。 近年来, 关于土壤硒含量的监测和分析受到研究者的广泛关注。 到目前为止, 对土壤硒的调查研究大多基于地球化学手段, 需借助大量的样本进行化学实验分析, 如此一来所花费时间过长、 投入资金偏高, 以及估测范围极其有限, 难以满足土壤微量元素的快速、 大面积测定。 而高光谱技术凭借高效率、 便捷、 高环保、 不损害土壤等优势, 在土壤微量元素预测研究中得到了广泛应用[5]。
微量元素含量不同的土壤具有不同的光谱特征, 这为土壤微量元素含量的快速测定开辟了新的途径。 近年来, 众多研究人员利用高光谱手段对土壤元素含量的预测进行了大量的研究。 目前常见的土壤元素含量预测模型有多元逐步回归、 偏最小乘回归等线性模型, 以及随机森林、 支持向量机等非线性模型。 在土壤元素含量光谱特征波段筛选上, 较常见的特征提取算法有迭代保留信息变量(IRIV)和连续投影(SPA)以及竞争性自适应重加权(CARS)等。 在土壤硒含量高光谱反演方面, 许多学者也进行了相关反演研究: 赵宁博等通过随机森林模型, 结合相关分析选择特征波段进行土壤硒含量预测, 得到了较好的结果[6]; 李巨宝等利用偏最小二乘法建立土壤硒含量与土壤光谱反射率的关系模型, 认为土壤硒元素含量在一定条件下可以借助土壤光谱参数进行反演[7]。 尽管国内外关于土壤硒含量的讨论大幅增加, 但部分难点依然存在。 例如, 在利用高光谱参数进行建模分析时, 波段信息冗余的影响难以消除, 此外, 多数研究仅通过皮尔逊相关性分析(PCC)选择相关性较大的波段作为特征波段, 许多带有化学信息的波段被剔除。 在具体研究中, 由于土壤硒含量的光谱特征敏感性较低, 常见的SPA、 CARS等特征提取算法无法保证变量的稳定性, 因此, 在建立回归模型反演硒含量时, 有必要对特征提取方法的稳定性做出相关改进。 另外, 众多研究结果表明, 土壤微量元素含量与光谱反射率受多方面的影响, 关系极其复杂, 用偏最小二乘等线性模型难以给出合理解释, 但支持向量等非线性模型参数的设置也对模型的性能有很大影响, 因此, 构建稳定的特征筛选算法以及精度较高的预测模型, 对土壤硒含量的光谱反演来说, 显得尤为重要。
以连州地区土壤硒含量为研究对象, 通过对原始反射光谱进行相关性增强处理, 利用基于变量稳定性的竞争自适应加权抽样法(sCARS), 结合皮尔逊相关性分析(PCC)来降低模型复杂度, 提升模型效率, 并尽可能保证变量的稳定性。 将光谱参数作为自变量, 把土壤硒含量作为因变量, 分别建立PLSR、 SVM和PSO-SVM土壤硒含量高光谱反演模型, 通过对比不同特征提取下的3类预测模型的反演精度, 分析基于变量稳定性的特征筛选方法与线性模型以及参数优化后的非线性模型的预测效果, 进而寻找最优的土壤硒含量高光谱反演模型。
1 实验部分
1.1 数据获取
研究区位于广东省清远市西北部的连州地区, 经纬度范围为东经112°07′—112°47′, 北纬24°37′—25°12′, 属亚热带季风气候区, 常年受季风影响。 区内土壤硒元素分布广泛。 采样点(如图1所示)分布于连州市范围内。 共采集0~20 cm表层土壤样品50份。 采集土壤样品时按照五点采样法, 对采集的土壤样品进行密封、 标记等处理后, 将土壤样品自然风干, 研磨并剔除土壤中杂质, 为减少因土壤颗粒差异以及水分差异带来的影响, 所有样品过60目筛, 将过筛后的样品放入烘箱, 在60 ℃下放置24 h。 将每份样品均分为两份, 分别用于土壤Se含量测定(检测结果如表1所示)和室内光谱数据获取: 使用PSR+3500便携式地物光谱仪(波长范围: 350~2 500 nm), 在暗室进行土壤样品的光谱数据获取(图2为部分土壤样本的原始光谱曲线)。

表1 土壤硒含量统计表
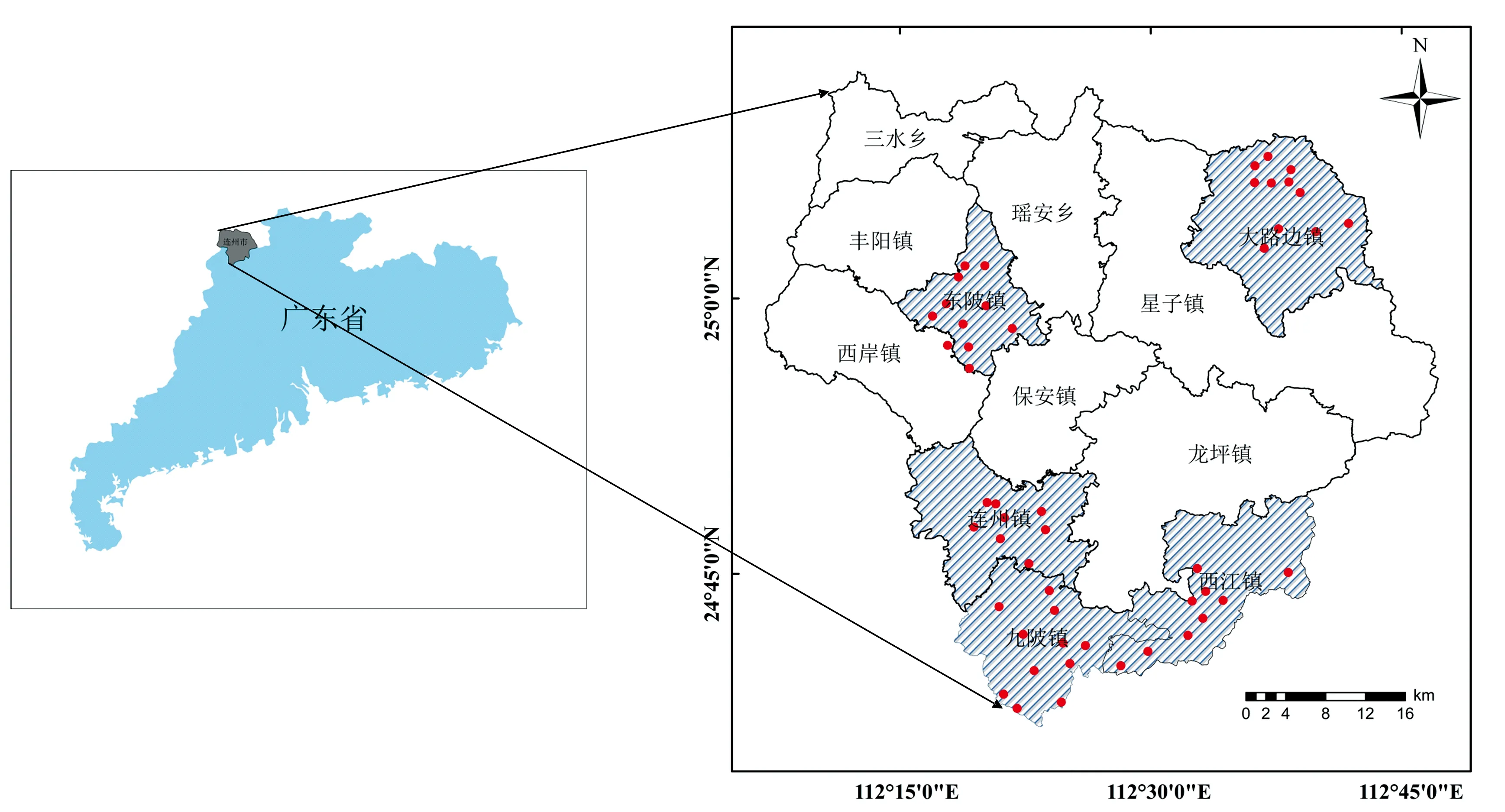
图1 研究区位置及采样点分布图
图2 土壤样品原始光谱曲线
1.2 光谱预处理与相关分析
因为土壤样品获取过程中, 会受到含水量、 土壤颗粒大小、 以及人为操作等因素的影响, 导致所采集的光谱信息含有较多的噪声, 不仅影响微量元素与光谱反射率的相关性, 还会降低预测模型的精度和稳定性, 所以通过光谱数据处理, 减少噪声, 增强光谱敏感性, 对土壤硒含量预测模型的构建极其重要。 采用多元散射校正[MSC, 图3(a)]、 标准正态变量校正[SNV, 图3(b)]、 对数一阶微分[lg(R)-FD, 图3(c)]和多元散射校正一阶微分[MSC-FD, 图3(d)]等数学变换处理光谱数据, 以此增强光谱反射率与土壤硒含量的特征关系。

图3 变换后的光谱
为改善高光谱数据因其所含有的信息波段多, 数据冗余而导致土壤元素含量反演模型的不稳定, 以及减少由于直接通过PCC方法选择特征波段所造成的有用信息的损失, 使用sCARS算法对几种光谱数据先进行初步特征波段的提取, 再利用PCC选择出相关系数绝对值大于0.5的波段作为特征参数。
sCARS是一种以变量的稳定性为变量重要性指标的特征波段选择方法[1]。 sCARS可以借助极少量的自变量得到满足条件的最佳均方根误差(RMSEP)和交互验证均方根误差(RMSECV)值。 相较于皮尔逊相关性分析(PCC)等常用的敏感波段提取手段, sCARS算法能够最大程度的凸显所选取特征波段的重要性, 降低了变量无用性的影响, 进而能够提取含有硒含量信息的敏感波段, 较少数据冗余, 降低模型复杂度, 提高预测模型反演精度和稳定性。
sCARS算法首先计算各波长变量的稳定性, 然后利用自适应重加权采样技术ARS和指数衰减函数EDF, 筛选出回归系数绝对值大且稳定性高的变量, 经过多次循环迭代, 最终以十折交互检验对每次循环后所得的变量子集进行检验, 选出交互验证均方根误差(RMSECV)最小的变量子集。
1.3 样本划分与模型构建
1.3.1 模型样本集划分
考虑到异常样本对回归预测模型精度的影响, 在划分训练集和预测集数据之前, 应最先剔除异常样本; 采用Origin2022软件作箱型图, 剔除掉异常值, 最终将剩余的49个土壤样本按照硒含量的高低进行排序, 划分出训练集与预测集样本比例为2∶1, 划分结果如表2所示。 训练样本的土壤硒含量最小值为0.20 μg·g-1, 最大值为1.15 μg·g-1, 平均值为0.67 μg·g-1; 预测样本的土壤硒含量最小值为0.35 μg·g-1, 最大值为1.14 μg·g-1, 平均值为0.72 μg·g-1, 所划分出的训练样本数据包含了预测样本硒含量范围, 可以消除样本集中特殊数据对建模精度带来的部分影响, 有助于提高回归预测的准确性。

表2 训练集和预测集土壤硒含量描述性统计表
1.3.2 预测模型构建
PLSR模型: 偏最小二乘回归模型, 是集多元线性回归(MLR)、 典型相关分析(PCC)和主成份(PCA)分析于一体的线性模型[8]。 利用PLSR模型预测土壤硒含量, 可以很好地处理大量光谱数据的多重共线性问题, 也可以有效避免回归预测模型在反演过程中产生的过拟合现象[9-10]。
SVM模型: 支持向量机(support vector machines)是Vapnik在1995年提出的一种基于统计学理论的新型机器学习方法。 SVM模型在解决小样本、 非线性和高维度模式识别中拥有较大优势[11-12]。
PSO-SVM模型: 由于核函数和正则化参数是SVM回归模型的重要参数, 对该模型的预测精度有很大影响。 因此, 优化两个重要参数, 对提高预测模型的整体精度至关重要。 粒子群优化(PSO)算法是一种基于迭代寻优的群计算技术。 该算法首先定义具有一定数量的粒子, 再经过迭代过程寻找目标函数的最优解。 以下是PSO-SVM的实现过程(如图4所示)。

图4 PSO优化SVM参数流程图
步骤1: 将训练集数据和预测集数据导入模型中;
步骤2: 进行参数设置: 群体规模n=50、 最大迭代次数N=200、 学习因子C1=1.5和C2=1.7, 核函数设定为0.1~1 000、 正则化参数设定为0.01~100, 另外再设置粒子其他初始参数;
步骤3: 将光谱数据和土壤硒含量输入模型, 得到更新后的RMSE。 通过对比目前最优适应度与粒子本身最优适应度, 当目前最优适应度优于粒子本身最优适应度时, 更新个体极值(pBest)和全局极值(gBest), 进而更新粒子速度和位置。
步骤4: 检验最大运行次数和参数优值, 当符合时, 则将σ和γ代入SVM进行不同光谱处理下的土壤硒含量预测, 否则执行步骤3, 继续寻找参数最优值。
2 结果与讨论
2.1 光谱变换与相关分析
通过SPSS 26软件对光谱数据与土壤硒含量做相关性分析, 结果如图5所示。 从图5左图可以看出原始光谱与Se的相关性变化趋势整体上与MSC和SNV的一致, 均有较好的相关性, MSC和SNV与硒含量的相关性在1 250~1 800 nm波段明显优于原始光谱, 在1 800 nm以后原始光谱与硒含量的相关性有所提高, 在图5的右图中, 两种光谱变换数据与硒含量的相关性变化趋势基本一致。 考虑到几种光谱数据与硒含量的相关性都有较为明显的波段, 因此将以上光谱数据全部作为后续特征波段提取研究。
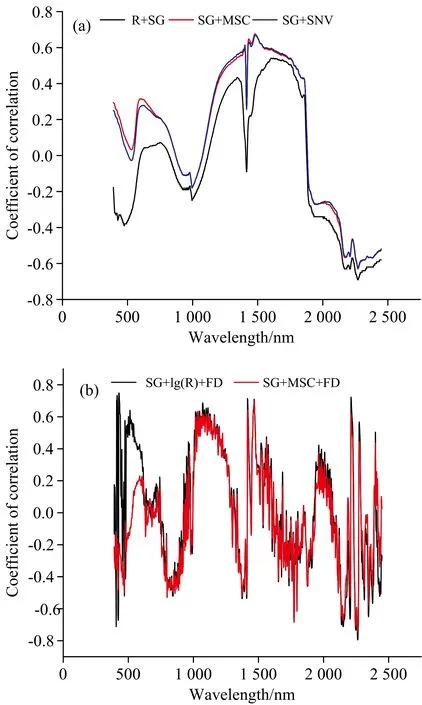
图5 光谱数据与Se元素相关性分析
2.2 sCARS算法筛选结果
由于篇幅有限, 仅以原始光谱特征波段选择为例进行说明(如图6所示), 从图6(a)中可以看出, sCARS算法在迭代过程中, 能够被提取的波段数据逐渐减少, 开始波段数量减少较快, 随后逐渐缓慢, 这是因为sCARS算法在提取敏感波段的过程中, 由“粗”到“细”分别剔除。 图6(b)为十折交互验证RMSECV值变化图, 从图中, 能够发现: RMSECV的随着迭代次数的增加, 先由大到小, 再由小到大。 RMSECV的值是在第27次运行后呈现最小值, 说明到达转折点, 在该点之前剔除掉了与土壤硒含量相关性较低的波段, 保留了反应土壤硒含量有用信息的重要波段, 属于有效剔除; 而过了该点, RMSECV值又逐渐增大, 很可能是进行了无效剔除, 损失掉了对土壤硒含量敏感性较强的重要信息。 结合图6的三个变化规律, 可以确定, 在RMSECV值最小时, 所选择的特征波长子集最佳, 特征波段的数量为27, 特征波段数量仅占总波段数量的1.31%。

图6 sCARS特征波段筛选过程
通过sCARS算法完成特征波段的初步筛选后, 利用PCC再次筛选出相关系数绝对值大于0.5的波段作为特征波段参与建模, 表3为经sCARS-PCC筛选的特征波段统计。 从表中可以发现, 只有经lg(R)-FD变换后, 在可见光和近红外波段存在特征点, 而其他几种变换下的光谱特征值都仅仅出现在短波红外, 且其最大相关系数波段极为接近。 从获取的特征波段数目来看, SNV拥有最少的特征波段, 波段数目为4, lg(R)-FD拥有的波段数目最大, 为84个。

表3 土壤硒含量光谱特征波段
2.3 预测模型预测结果
将表3中特征波段和全波段作为预测模型的自变量, 以土壤Se含量为因变量, 分别建立PLSR及SVM、 PSO-SVM回归模型, 采用决定系数(R2)和均方根误差(RMSE)对预测模型进行精度评估。 预测结果如下:
2.3.1 PLSR模型
表4为各光谱变换数据PLSR模型建模结果, 通过比较训练集和预测集的决定系数R2和均方根误差RMSE, 可以发现, 原始光谱和经对数一阶微分变化的光谱, 在采用特征波段建立PLSR回归模型时预测效果明显优于全波段参与建模的效果, MSC-FD和SNV特征波段的PLSR模型, 在精度上整体优于全波段模型。

表4 PLSR回归模型精度评价
2.3.2 SVM模型
表5为土壤硒含量与全波段和特征波段的SVM模型预测结果。 经过对比全波段和特征波段模型训练集和验证集的R2和RMSE可知, 特征波段SNV-SVM、 MSC-FD-SVM、 lg(R)-FD-SVM模型的精度较之全波段的精度有明显提升, R-SG-SVM特征波段模型虽然精度没有提升, 但模型的稳定性有很大改善。 使用对数一阶微分变化后的特征波段建立的SVM模型效果较差, 但整体上各光谱变换后利用特征波段建立的模型稳定性明显高于全波段建模的稳定性。

表5 SVM回归模型精度评价
2.3.3 PSO-SVM模型
表6为基于sCARS-PSO-SVM模型的预测结果, 对比训练集和预测集的均方根误差和决定系数可知, 该模型的稳定性非常好, 模型精度较之未优化的SVM模型有明显提升, 其中MSC-PSO-SVM、 MSC-FD-PSO-SVM模型的决定系数R2超过了0.5, SNV-PSO-SVM、 lg(R)-FD-PSO-SVM模型的决定系数R2接近0.5。 从RMSE越小,R2越大, 则预测精度越好的判断标准考虑, MSC-FD-PSO-SVM模型精度最高。 整体上来看粒子群优化算法在一定程度实现了对支持向量机预测土壤硒含量的模型精度的提高。 由于篇幅有限, 仅以MSC变换后的PSO-SVM模型实测值与预测值散点图为例(如图7所示)。 可以看到预测值和实测值在y=x线两侧均匀分布, 预测结果较为理想。

表6 PSO-SVM回归模型精度评价

图7 实测值与预测值关系
采用sCARS算法挑选特征波段, 改善了高光谱数据冗余问题。 在寻找硒的敏感波段时, 不但选取波段数目少, 降低了模型复杂度, 而且也避免了单独利用PCC选择特征波段所造成的有用信息的损失, 极大的提高了硒含量回归模型的效率。 原始光谱经MSC、 SNV、 lg(R)-FD、 MSC-FD变换, 不同程度提高了光谱数据与土壤硒含量的相关性, 有更加明显的建模优势: 经几种光谱变换后的特征参数建立的SVM模型, 其模型精度高于PLSR模型, 这种优势在粒子群优化支持向量机参数的SVM模型中更加明显。 对比SVM和PLSR模型, 通过PSO优化SVM的核函数和正则化参数, 以迭代方式不断更新pBest和gBest, 获取参数最优解, 有效提升了土壤硒含量的预测精度。 其中MSC模型决定系数最高, 为0.53, MSC-FD的RMSE最小, 为0.04, 整体上几种光谱变换的PSO-SVM模型均具有较好的稳定性和精度, 可以满足对土壤硒含量的大面积、 高效预测。 另外, 选择的特征波段在可见光与近红外波段均有涉及, 与前人分析的土壤硒含量的特征波段相似之处有: 赵宁博[6]等分析出514~1 300 nm范围相关程度较高, 而在本次研究中, 经lg(R)-FD光谱变换的特征波段511~514、 521~523 nm符合这一特征; 张东辉[13]等在土壤硒间接反演时, 提出硒的敏感波段在437、 466和475 nm处, 而经lg(R)-FD光谱变换的特征波段436、 469~470 nm极为接近。 与此前研究不同的是, 本研究所选择的特征波段, 在2 000 nm之后较高频率出现, 尤其是2 262~2 270 nm这一范围。 在接下来的研究中, 应分段研究2 000 nm前后的波段, 以寻找更适合反演土壤硒含量的波段。
3 结 论
(1)通过光谱增强与特征波段筛选处理数据, 能够降低高光谱预测模型的复杂度, 能够明显提高模型的反演精度, sCARS算法能够很好地结合光谱预测模型实现土壤硒含量的高效反演。
(2)SVM模型相对于PLSR模型能够更好地反演土壤硒含量, 说明土壤硒含量与高光谱之间非线性关系更加突出。
(3)粒子群(PSO)算法优化SVM的核函数和正则化参数, 使得几种光谱变换的PSO-SVM模型预测精度都明显提高(MSC-PSO-SVM模型的决定系数最大, 为0.53, MSC-FD-PSO-SVM模型的均方根误差最小, 为0.04), 两模型的稳定性和预测效果好, 可以快速、 准确、 大面积反演土壤硒含量。
