基于深度神经网络的多模态计算机图像识别
2023-11-02周晓成
越 缙,周晓成
(安徽文达信息工程学院 计算机工程学院,安徽 合肥 231201)
0 引言
数字图像处理的终极目的就是利用电脑来代替人进行图像的识别,并从中找出所需的对象,它是电脑模式识别的重要内容[1]。模式识别技术是以人类的听觉和视力为基础的利用电脑模拟人类不同的认知功能的图像识别技术。图像的模式识别就是机器对文字和图像的处理。图像识别分为3个部分:数据采集、数据处理和分类。图像识别主要有:统计模式识别、结构模式识别、模式识别等[2]。20世纪80年代兴起的 ANN是一种广泛的智能模式识别技术,它具有高的并行性、分布式记忆能力和良好的容错性;具有自适应联想记忆和高度非线性处理的特点。在模式识别方面,传统机器学习算法或计算机视觉技术过度依赖于手动选择,通过分类器进行图像识别,其对复杂场景下的计算机图像识别鲁棒性比较差。神经网络图像辨识技术是将现代电脑技术、影像处理与人工智能相结合的技术;作为一种新的图像识别技术,神经网络图像利用多模态识别技术可以进一步提高图像识别效率。该方法基于传统的图像识别技术,并将其与神经网络相结合[3]。
1 深度神经网络算法
1.1 径向基函数神经网络模式
RBF神经元的构造如图1所示。RBF的主要功能采用了辐射基元,一般是指由欧几里得距离从一个空间的任何一点到一个中心的单一函数。由图1中的 RBF神经元的构造可知,RBF神经元的启动功能是将输入矢量和加权矢量的间距dist作为自变量。其中RBF网络的启动功能的通用公式如下:
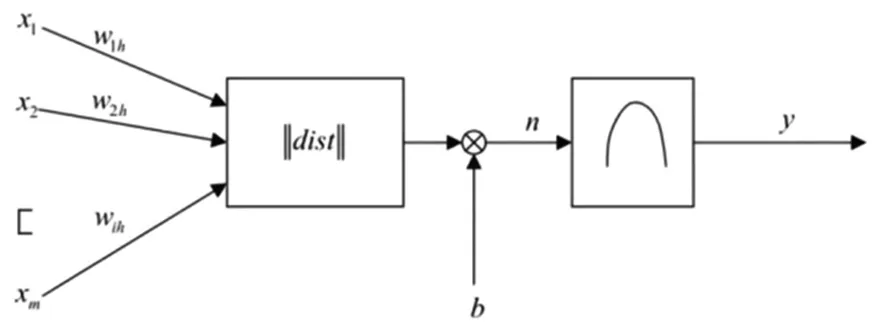
图1 RBF神经元模型
R(‖dist‖)=e-‖dist‖2
(1)
当权值与输入向量之间的距离减小时,网络的输出量就会增加[4]。在图1中,b是调整神经元敏感度的一个阈值。利用径向基神经元和线性神经元,可以建立一个适用于函数逼近的广义回归神经网络。该方法能构建出适合于解决问题的径向基和竞争性神经元的概率神经网络。
典型的RBF结构由输入层、隐含层、输出层构成,不妨设输入层节点数、隐含层节点数、输出层节点数分别为n、k、m。定义x=[x1,x2,…,xn]T为输入,隐含层输出为φ=[φ(x,c1),φ(x,c2),…,φ(x,ck)]。在隐含层输出矩阵中,ci对第i个隐含层节点有
Wkm=[W1,W2,…,Wk]T,i=1,2,…,k
式中:Wkm为网络输出权重矩阵,
Wi=[Wi1,Wi2,…,Wim]T
F(x)=[f1(x),f2(x),…,fm(x)]T
为RBF网络输出向量。
在RBF网络结构中(图2),只有在输入层才能传送数据信号。由于输入层与输出层2个层面的工作方式不同,因此其运算方式也不同。文章所提出的深度神经网络算法采用了最优化的线性权重,从而提高了系统的学习效率。隐含层则采用了一种基于非线性最优化的方法来调节激励功能的参数,从而提高图像识别效率。
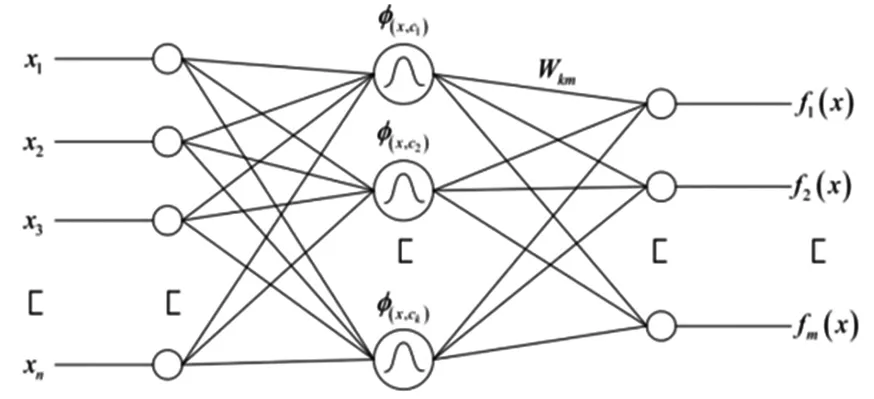
图2 RBFNN的网络结构图
1.2 相似度计算规则
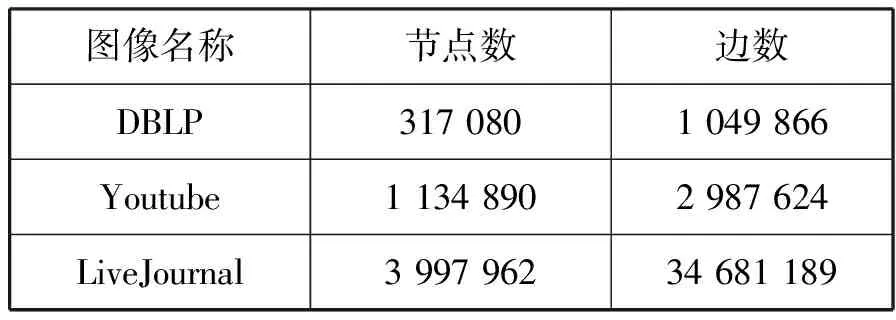
在已有的PSCAN方法中,对各边相关的各顶点进行了类似的运算[5]。在整个算法中,两个顶点之间的相似度的计算比较耗时。若能在图形中减小顶点,则可以通过计算类似程度来显著地改善运算速度。通过对2种不同的顶点之间的相似性进行分析,得出以下的简化准则。若或使2个顶点v与w为相同的相似性阈值ε(0<ε<1),如果|H[v] (2) 即δ(v,w)<ε所以两个顶点v和w不相似,同样绘制: |H[w] (3) 所以,如果|H[v] |H[v]∩H[w]|≥(v,w) (4) 因为 (5) 所以 (6) 当δ(v,w)≥ε当且仅当 由于H[v]∩H[w]是一个整数,所以 =min(v,w) 使用这个引理,公式3利用算法来确定2个顶点是否相似,假设2个顶点没有被精确计算。使用Sim算法,输入精确计算的v和w,以及顶点w的邻居Nv和Nw,具有Nv[i]的顶点的第i+1个邻居(其中Nv和Nw中的顶点按顶点标签的升序排列),以及相似度阈值ε(0<ε<1)输出结果如果顶点v和w相似,即输出真,否则假。在该算法中,首先找到使顶点v和w相似的最小结构化公共邻居的数量。然后定义一个变量counter,记录结构化公共邻居的数量,由于该方法输入了一个相邻的顶点v和w,因此仅计算了2个顶点的共同相邻数目,而不包含它们自身的值,而该方法则是计算相邻节点的共同数量,因此,将其初值设为2。 通过上述对深度神经网络算法建立的基础上,对基于深度神经网络的多模态计算机图像识别方法进行试验。采用了以下软件和硬件平台:机群包括5个采用Red Hat 64位系统、16核CPU、1.9 GHz、16 GRAM、2 T硬盘;2.6.0版本 Hadoop,1.6.0版本,Java1.8.0版本,Scala2.10.4版本。系统配置:Windows7 32位的旗舰版本,主频率3.10 GHz,4 G记忆体,500 G的硬盘;在 Java1.8.0版本和 Scala2.10.4版本中,IntelliJIDEA Community版本15.0.2。 系统的实验对象主要有DBLP,YouTube,LiveJournal 3个数据集。在这些协议中,YouTube是一种连接到使用者的网站;而LiveJournal是一个社会网站。利用以前的文件中的演算法产生人工数据集合。数据集统计见表1和表2。 表1 真实数据集 表2 合成数据集 文中给出了一种新的基于PSCAN的新方法,并与魏秀参等[8]人的PSCAN进行比较。PSCAN和神经网络在相同的组态下工作,试验中,PSCAN没有给出最小聚类量,因此在试验中将其聚类的最小值设定为2。对计算机图像识别运行时间进行了对比能评价神经网络算法性能,为此,设定神经网络算法和PSCAN算法分别在相似度阈值分别为0.6、0.7、0.8、0.9的条件下运行。从图3的实验结果可以看出,2种算法的运行时间都随着相似度阈值的增加而逐渐减小,并且神经网络算法在4个数据集上运行速度比PSCAN算法快了30倍以上,表明该算法与PSCAN算法相比更有效,可有效提升图像识别效率。 图3 Youtube数据集 神经网络算法识别图像较快有2个原因。一是得益于以 GraphX为基础的神经网络演算法,如集中式记忆体的容量大[9],可在记忆体里进行全资料的运算,并将中间的运算结果储存在记忆体里,从而减少了许多硬盘 I/O,节约了许多的运算空间。而PSCAN则要求在Hadoop集群中执行多个映射和 Reducer,且在各个级别,即便有大量的内存,也会将其储存到硬盘上;下一步会从硬盘上读出中间的数据,这会提高硬盘 I/O的消耗,提高软件的运行速度。二是在计算相邻顶点的相似度时,神经网络算法通过2种归约策略计算顶点之间的相似度。当顶点之间的相似度没有精确计算时,判定2个顶点之间的相似性,从而进一步缩短了程序的执行周期。 为深入研究算法性能,将算法中2种简化规则进行试验对比,了解不同缩减战略性能。对各数据集合进行5次运算,时间进行均值处理,同时试验过程仅统计各节点相似性,对比结果如图4所示。 由图4可知,采用切割法计算各数据组相似性,所消耗的时间明显缩短,计算量显著降低。同时,随着相似度阈值的增加,每一组算法运行时间在减少。按照约简规则计算,相似度阈值越大,其有效规则越少[10]。 由图4(a)可知,在图形中保留边数并更改顶点数目能够有效缩短裁剪的时间。如果要保证图形中的顶点数目不变,就必须更改图像边框数目,并且缩短计算的次数,如图4(b)所示。无论是改变顶点数目还是改变图像边数目,使用归约策略均可以显著减少相似度计算所花费的时间。同时,随着顶点数量的增加,2种算法都会消耗更多的时间。保持图中顶点数量不变,在不采用简化算法的情况下,随着边数的增大,相似性计算所消耗的时间也会增大。一张图越密集,其邻接的顶点也就越多,采用规约策略可以判断的邻接顶点也越多,规约策略越有效。即该方法能够显著缩短计算过程中相似性计算所消耗的时间,大大提高运算的效率。 算法扩展性反映当所处理的图像数据量增多时,算法处理效率受影响的程度,受影响程度低表示算法可扩展性强。为分析神经网络算法的可扩展性,将神经网络算法的相似度阈值设置为0.6,将3个真实数据集的最小聚类值设置为2进行试验。结果表明在不同机群数条件下,神经网络算法对各图像数据集的性能进行了优化,提升了神经网络算法在每个图像数据集上的运行效率。在一定范围内,该算法能够提升运算速度。同时,伴随着数据集的增加,图像识别的效率增加,如图5所示。 图5 合成数据集pruning策略 针对以Hadoop MapReduce为基础的多模态计算机图像识别存在的占用硬盘资源多、运行效率低的问题,对PSCAN进行改进,并对2种简化规则进行试验对比。结果表明,该方法能够有效降低系统的I/O消耗,提升算法运行的效率,这对大数据分析中计算机图像识别具有一定的参考价值。
1.3 时间缩减规则

2 仿真实验与分析
2.1 仿真实验参数设定

2.2 算法运行时间分析

2.3 算法缩减战略
2.4 算法可扩展性分析

3 结论
