基于深度学习的食品安全风险知识图谱构建方法
2023-11-01袁刚郭爽唐琦许入文王金国韩春晓温圣军张文通
袁刚 郭爽 唐琦 许入文 王金国 韩春晓* 温圣军* 张文通
(1.国家市场监督管理总局信息中心 北京 100820;2.北京理工大学计算机学院)
0 引言
食品安全风险管理是当前提升我国食品安全管理能力的重要内容,《食品安全法》在总则中确定了一个重要原则,就是食品安全工作实行以预防为主、风险管理、全程控制、社会共治,建立科学、严格的监管制度。 实际上就是强调对食品安全风险进行全面管理的重要性。 当前,风险管理主要来源于对数据的分析判断,但食品安全链条长、范围广、涉及的因素多,每天产生大量与食品安全相关的风险数据, 但对于庞大的数据体量和无规则的数据关系,利用技术进行分析挖掘不够,导致食品安全风险预警研判成为业界共同研究的课题。
知识图谱技术蕴含丰富的先验知识,具有重要的学术价值和广泛的应用前景。 知识图谱分析推理作为知识图谱领域的核心技术,能够极大地扩展现有知识的边界, 有力地辅助人类进行智能决策。 因此,利用知识图谱技术和食品安全监管的海量数据,构建食品安全风险知识图谱, 建立食品各维度数据之间的关联关系, 为食品安全风险分析和预测提供技术手段。当前,构建食品安全风险知识图谱需要面对一系列问题:(1) 信息数据量大, 难以人工处理;(2)信息来源多样,难以挖掘数据间关联;(3)信息维度多样,难以统筹整合。 针对以上3 个问题,本文使用BiLSTM-CRF 神经网络构建食品安全风险知识图谱。
知识图谱以“实体—关系—实体” 形式描述语义,进而使用包含语义的网络结构来组织知识,表示现实世界事物与事物之间各种各样的联系。 作为一种更适合于描述客观世界实体与关系的信息载体,知识图谱的研究掀起一股研究热潮[1]。
早期主要是基于对启发式规则的应用,通过人工定义构建模式,进行文本匹配,从而实现信息抽取知识图谱构建。1991 年,RAU[2]结合人工编写规则与启发性算法,首次实现从文本中提取公司实体的原型系统。这些基于规则的实体识别系统的优点在于可以在特定领域有良好的性能表现,但同时也有着巨大缺点,即需要花费大量人工成本设计信息抽取规则。 这些规则通常是依托于场景的,因此在复用性上表现也比较差。
为解决这一问题, 研究者将自动构建与统计机器学习方法相结合,分为几个子任务:实体抽取、关系抽取、属性抽取。将拆解出的子任务转化为机器学习领域研究的序列标注和分类问题, 进而使用学习模型来解决,比如CRF 模型[3]、HMM 模型[4]、MEMM模型[5]、SVM 模型[6]、LSTM 模型[7]等。 其中,生成式模型如HMM 对数据量的需求往往较大, 而判别式模型如MEMM、CRF 对数据量的要求就要少许多。 SUTTON 等[8]分析了CRF、HMM 与MEMM 之间异同,与HMM 和MEMM 相比,CRF 模型更复杂, 计算复杂度更高,但是其特征设计更灵活。 LIU 等[9]利用KNN算法和CRF 模型,实现了基于Twitter 文本数据的实体识别任务。 LIN 等[10]使用MaxEnt 模型,结合字典辅助,在GENIA 数据集上取得了精确率(precision)与召回率(recall)均超过70%的优秀结果。
随后, 具有极强的非线性拟合能力的深度学习出现了, 该技术也被应用于知识图谱抽取任务中。COLLOBERT 等较早地使用了结构形如NN/CNNCRF 的模型,来完成实体抽取图谱构建任务,并提出了基于窗口和基于句子的2 种模式。
而后学术界又提出一系列结构形如RNN-CRF框架, 其中这类模型中RNN 层主要代表LSTM 模型。 LAMPLE 等提出BiLSTM-CRF 框架,并分别在词和字的级别上给出应用。 REI 等基于RNN-CRF模型改进了词编码与字编码的拼接步骤, 并引入注意力机制, 实现了词编码和字编码中所包含信息的动态学习。 BHARADWAJ 等将字编码结果和音韵进行拼接处理,并在字编码上引入注意力机制。MA 等人提出了混合模型BiLSTM-CNNsCRF。 ZHANG 等提出Lattice LSTM 模型,引入字典机制,对输入的字符序列和所有与词典匹配的潜在词汇进行编码,实现了零分词错误。 AKBIK 等训练语言模型内部隐状态,产生一种新的编码模型。PETERS 等提出一种简单、通用的半监督方法TagLM。YANG 等提出一种基于RNN 的转移学习方法,并开发了用于3 种迁移学习架构:T-A,T-B,T-C。 3 个结构目前得到广泛应用,成为跨域、跨任务的一种baseline 模型。
1 BiLSTM-CRF 模型
在实体抽取的任务中, 某个词语是否能被识别为一个人名、组织或者其他实体信息,很大程度上取决于上下文信息。例如:“钟南山院士”、“本科毕业于北京协和医学院医疗系”等文本中,“院士”并不是命名实体,但是对于识别“钟南山”为人名实体有帮助;“本科毕业于”、“医疗系” 也不是需要识别的命名实体,但是有助于识别出机构名“北京协和医学院”。
1.1 BiLSTM 模型
深度学习中长短期记忆网络(LSTM)正是利用这一上下文信息,通过在模型中引入遗忘门机制,使得模型可以存储记忆序列化数据, 并将其量化表现为参数能力。 因此LSTM 非常适合处理依赖上下文信息的实体抽取任务。 LSTM 网络可以在一定程度上使用上下文之间的一些关联信息, 增强对字词的语义理解。 但是传统的单向LSTM 只能捕获序列的历史信息,没用充分利用上下文信息。
不充分考虑上下文信息, 可能在进行命名实体识别的任务中出现错误,例如“武汉市长江大桥位于中国湖北省武汉市”,如果不对下文信息“位于中国湖北省武汉市”加以利用,而只观察到“武汉市长江大桥”,则可能只看到“武汉市长”信息,并将“江大桥”标注为人名,这种情况是需要避免的。
BiLSTM,即双向长短期神经网络,通过特有门阀单元控制信息传递有选择地保留上下文信息,实现对上下文信息利用和对有效文本的记忆功能。
对于BiLSTM 网络,举例网络的输入若为“钟南山院士”,主要捕获反向信息,“院士”为职称,记忆单元因此可能学习到前面的词大概率为人名或姓氏,因此预测“钟南山”为人名。
BiLSTM 层在知识图谱构建模型框架中起着很重要作用, 由于具备能接受预训练得到的文本向量、可基于前后时序进行建模捕捉文本中上下文信息、同时捕获文本数据历史信息和反向信息这几个特点和优势,BiLSTM 模型具有优于其他模型的实体识别效果。
1.2 BiLSTM-CRF 模型
对于中文知识抽取任务, 经过BiLSTM 的输出,文本中历史信息和反向信息被捕捉和记忆,模型计算得到各个字的输出表示。 BiLSTM 输出的各个字之间没有互相影响, 这不利于得到一个完整的中文实体。这样的标注显然是不合理的,也无法获得任何有效信息,用以构建知识图谱。 其原因在于,BiLSTM 模型将会输出各个标签对应得分张量矩阵,随后会简单地选择每个字对应张量中得分最高标签类别, 作为当前字的标签预测结果, 而得分最高的标签相互组合并不一定构成完整实体,这种现象在中文数据中尤为明显。
而上述问题可通过引入CRF 层来解决。CRF 模型是一种用于解决序列标注问题的深度学习模型,该模型结合了HMM 模型与MaxEnt 模型优点,具有表达长距离依赖性和交叠性特征能力, 解决了最大熵马尔可夫模型存在的标记偏置问题, 通过将所有特征进行全局归一化,来求得全局最优解。
CRF 模型侧重考虑句子层面上,每个字标注的tag 之间互相影响。作为BiLSTM 模型和CRF 模型的结合体,BiLSTM-CRF 模型先通过BiLSTM 层获取历史信息和反向信息, 输出每个字对于各标签的权值矩阵, 再通过CRF 层学习标签间依赖性调整输出,最终得到预测结果。
经过CRF 层对最终输出的约束, 相较于BiLSTM 网络,BiLSTM-CRF 网络的预测结果不合理现象出现概率大大降低。
1.3 食品安全风险知识图谱构建
本文将以BiLSTM-CRF 神经网络训练模型,完成食品安全风险知识图谱的自动构建。 将从数据预处理、基于BiLSTM-CRF 的知识图谱构建、效果及分析三小节对构建过程进行介绍。
1.3.1 数据预处理
目前基于食品安全监管知识抽取数据集包括监督检查数据集、行政许可数据集、信用监管数据集、行政处罚数据集、抽检监测数据集、投诉举报数据集、登记注册数据集、违法失信数据集等,如表1 所示。

表1 知识抽取数据集Table 1 Dataset for knowledge extraction
因此,经过分析权衡,本文选取以上数据集作为训练数据。 提取2023 年1—5 月数据,形成训练集,2023 年6 月份数据作为测试集。 训练集与测试集数据量大致是5∶1,以此构建模型训练使用的数据集。
1.3.2 基于BiLSTM-CRF 的知识抽取
深度学习中长短期记忆网络(LSTM)利用上下文信息,通过在模型中引入遗忘门机制,使得模型可以存储记忆序列化数据, 并将其量化表现为参数能力。 LSTM 记忆单元结构如图1 所示[32]。
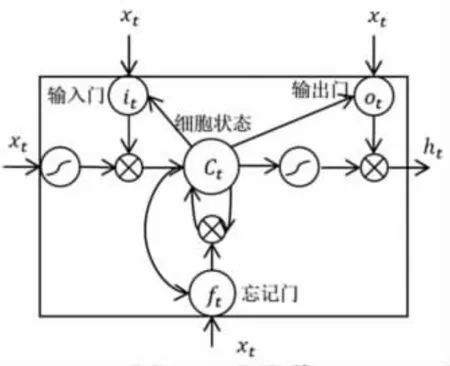
图1 LSTM 记忆单元Fig.1 A LSTM memory cell
LSTM 记忆单元中细胞状态的保存和更新由输入门、遗忘门、输出门决定。 输入门将新信息保存到记忆单元,遗忘门控制历史记忆信息保留哪些,输出门控制更新后的细胞状态输出哪些。 记忆单元依照下面一组公式执行:
其中σ 是sigmoid 函数,i 是输入门,f 是遗忘门,c 是记忆单元,o 是输出门,h 是隐藏向量,Wxo代表输入门(x)到输出门(o)的权重矩阵,其他权重矩阵表示同理。
LSTM 网络如图2 所示, 其中浅蓝色部分表示一个上述LSTM 记忆单元。

图2 LSTM 网络Fig.2 A LSTM network
BiLSTM,即双向长短期神经网络,通过LSTM 特有的记忆单元控制信息传递, 有选择地保留来自前向和反向上下文信息, 进而实现对上下文信息利用和对有效文本记忆功能。 BiLSTM 网络如图3 所示。

图3 BiLSTM 网络Fig.3 A BiLSTM network
CRF 模型具有表达长距离依赖性和交叠性特征的能力,通过将输入的所有特征进行全局归一化,进而求得全局最优解。
作为BiLSTM 模型和CRF 模型的结合体,BiLSTM-CRF 模型先通过BiLSTM 层获取历史信息和反向信息,输出每个字对于各标签权值矩阵,再通过CRF 层学习标签间依赖性调整输出,最终得到预测结果。 图4 以“生产环境卫生不合格导致食品安全风险”为例,展示了BiLSTM-CRF 网络结构及运行结果。

图4 BiLSTM-CRF 网络结构及实例Fig.4 A BiLSTM-CRF network and instance
在对BiLSTM-CRF 神经网络训练中,本文采用当前适用性最强,性能最优的自适应矩估计(Adam)优化器;loss 函数使用最小负对数似然(NLL)。
本实验使用精确率 (Precision)、 召回率(Recall)、准确率(Accuracy)、F1 值(F1-score)4 项作为评估指标。 Precision 衡量模型仅返回所有检索到的实例中相关实例的能力。 Recall 衡量模型检索所有相关实例的能力。 Accuracy 评估模型在整个数据集中做出正确预测的百分比。 F1-score 是Precision 和Recall 的调和平均值, 它同时考虑了测试精度和召回率。 这4 个指标一起可以对食品安全风险知识图谱构建模型进行综合评价。 公式如下所示。
模型训练主程序核心代码如图5 中伪代码所示。

图5 模型训练主程序核心伪代码Fig.5 Pseudocode of model training program
深度学习模型BiLSTM-CRF 构造函数的核心代码如图6 代码块所示。

图6 BiLSTM-CRF 模型构造函数伪代码Fig.6 Pseudocode of BiLSTM-CRF model constructor
1.3.3 食品安全风险知识图谱构建效果
最初训练的版本模型效果欠佳,F1-score 并不理想,经分析本文认为可能来源于参数选择不合理,本文采用预训练-微调方式和手工标注部分平台数据,使模型学到一些针对食品安全风险数据的特点,模型效果更适合食品安全风险结果。 后续实验尝试了多组参数进行对比分析,最终F1-score 可以达到较高水平。
本文在不同类型数据中, 随机抽取一定数量数据项,人工判断精确率、召回率、F1-score 的性能指标,用以测试不同模型在数据中的表现,知识抽取性能如表2 所示。

表2 随机抽取数据测试模型的性能Table 2 Performance for randomly extracted data
在不同分类(如:监督检查、信用监管、投诉举报等分类)下,系统对人才数据进行知识抽取时表现出的效果也不尽相同。 教育经历分类下知识抽取性能如表3 所示;工作经历分类下知识抽取性能如表4 所示;社会网络分类下知识抽取性能如表5 所示。
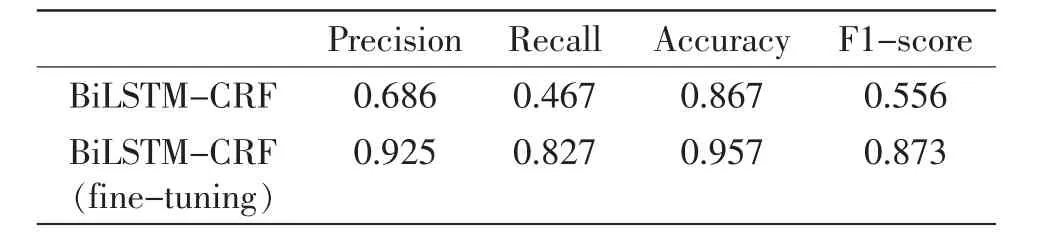
表3 监督检查方面的性能Table 3 Performance for supervision and inspection data
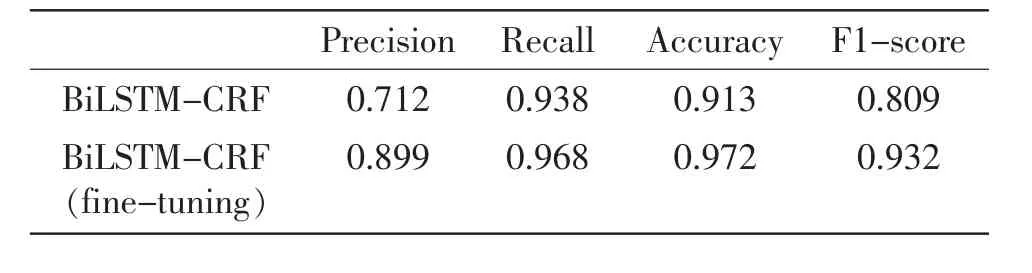
表4 信用监管方面的性能Table 4 Performance for credit supervision data

表5 投诉举报方面的性能Table 5 Performance for complaints and reports data
根据表3~5 分析可得,在不同的数据信息分类下,知识抽取算法表现差异较大,该结果需要根据数据特点进行分析是否合理。
监督检查分类下数据信息, 一方面存在很多生僻和不规范数据,另一方面,通常这类数据不以完成的一句话录入,模型无法利用到上下文信息,因此在此项中表现较差。
与之相反的投诉举报分类下信息, 通常有较完整的上下文信息如“XX 人于XX 时间食用了XX 食品,感觉恶心,出现呕吐”,本文训练出的模型对这类数据分类下信息的知识抽取效果很好。
基于所抽取原始数据的组织结构, 本文将食品安全风险设置为知识图谱的节点, 以因素间关联关系作为知识图谱的边。 通过食品安全风险信息中抽取出实体,对各因素进行关联,再通过信息所在信息项判断关联关系。 因素A 在食源性风险信息中出现因素X,因素B 在舆情信息中出现因素X,则因素A与因素B 之间建立关联关系。 如图7 所示。
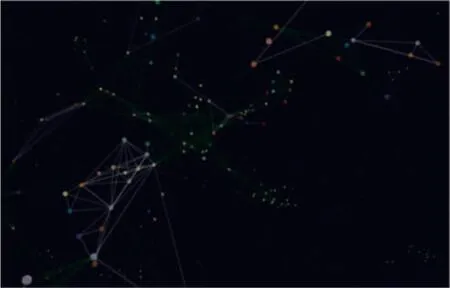
图7 食品安全风险图谱构建效果展示Fig.7 Demonstration for constructing a food safety risk knowledge graph
为更始图结构清晰, 限制所展示节点和边的总量,不同颜色节点代表食品安全风险因素,不同颜色的边代表不同关联关系。
2 结论
本文提出一种基于深度学习的知识抽取算法,自动构建食品安全风险知识图谱。 在大数据时代提供了食品安全风险知识图谱自动抽取方案, 对于海量食品安全相关信息, 建立食品安全风险因素之间关联关系, 为食品安全风险监测预警提供了一种有效的技术方法。
