海上布防任务中无人艇对可疑目标的驱逐方法研究
2023-11-01鲁宇琦魏长赟
鲁宇琦,魏长赟
(河海大学机电工程学院,常州 213022)
1 引 言
海上无人船(Unmanned Surface Vessel,USV)作为一种海洋无人智能运载平台,具有使用灵活、泛用性好、可执行危险任务等显著特点,其在各种海洋作业中的运用愈加广泛,比如特别依赖长期连续性数据的海洋环境监测,USV因其长期性和持久性在海洋环境监测方面发挥越来越重要的作用[1];再比如航母护航舰队,航母进行远洋作业时需要护航舰队执行任务,但远洋作业未知且危险,USV即可替代人类执行危险任务,在海上风电场巡逻、岛屿警戒、反雷反潜艇等军事领域也有USV的应用。因此对USV行动方法的研究受到国内外学者的广泛关注。对USV行动方式最基础的研究则是对其航行规划和导航的研究。全局路径规划能够解决路径到达和路径覆盖两个问题。传统的全局路径规划方法有A*算法、D*算法、遗传算法[2-3]、蚁群算法[4]、粒子群寻优算法[5]等。Chen等[6]提出了一种改进的蚁群优化算法,通过一种新的信息素更新规则,提高了传统蚁群算法的收敛性,减少局部最优的问题,并且与人工势场法相结合,使得USV能够在动态环境下获得最优的路径规划,但是该算法是基于网格图的设计,实用性较低。全局路径规划适用于静态环境的路径规划,其实用性较小,更有实用价值的是局部路径规划。局部路径规划方法有基于启发式算法的路径规划、人工势场法[7-8]、深度强化学习相关算法等。Shao等[9]提出了一种用于规划无人机编队的改进粒子群算法。通过引入一种基于混沌的映射方法来改善粒子群的初始分布,然后将速度和最大速度系数设计为自适应线性变系数,用以适应优化过程,提高了解的最优性,此外还加入了将不重要的粒子替换为重要的粒子的突变策略,加快了算法的收敛。学者们对路径规划进行了大量研究,但是在对抗性的驱逐方法方面研究较少[10]。无论是航母护航,还是反雷反潜艇等军事作业,需要驱逐的对象并不是静态和低智能的。Lee等[11]构建了一种多潜艇防御追击的目标分配和路径规划框架,提出使用PNG定律进行目标分配,利用Dubins路径处理防御追击时的避障问题,其防御追击的目标会主动入侵,但是该环境中入侵者的入侵路径是固定的,并不会对护卫潜艇的逼近作出反应。
因此构建一种动态强对抗的环境,其中的可疑目标移动速度快、转向灵敏、综合性能比USV更好,并且会主动、不间断地对布防目标进行进攻,同时会对USV的防御动作做出反馈;在这样的强对抗背景下对USV进行训练,并实现在动态环境中USV对可疑目标精准快速驱逐的算法,对于具体的海上布防任务来说具有重要意义。
对此本文提出一种基于深度强化学习(Deep Reinforcement Learning,DRL)的布防驱逐算法,并引入改进人工势场法智能化可疑目标的进攻路径,使其进攻性更强且更难以被驱逐,提高了算法的实用性。同时搭建了策略梯度算法学习模型,并在gym中构建仿真环境进行训练,成功验证了驱逐方法的可行性。
2 问题描述
海上布防任务,是指利用海上军事力量,对某个有价值的目标比如航母、岛屿等进行分布防御,封锁控制。在确定布防目标后,对封锁范围内的任何可疑目标进行驱逐是布防任务非常重要的一环。虽然USV集群协作可以更有效地执行任务[12],但是USV海上集群决策是极其具有挑战性的[13]。原因有以下几点:一是因为集中式决策需要一个汇总信息的中央处理器,同时与每个USV进行信息交互,而海上通信极易受到环境干扰,存在较高延迟,信息滞后效应会极大影响决策;二是因为集群决策寻找全局最优解,但是联合行动时状态空间及动作空间成指数增长,难以找到最优解,且该解扩展性差无法转移至其他类似环境。
因此本文以深度强化学习模型为基础,提出了USV集群驱逐任务模型,USV配有雷达,能够以自身为中心探测可疑目标位置,并将其坐标进行转化处理,通过策略学习实现对可疑目标的驱逐作业。具体模型如图1所示。
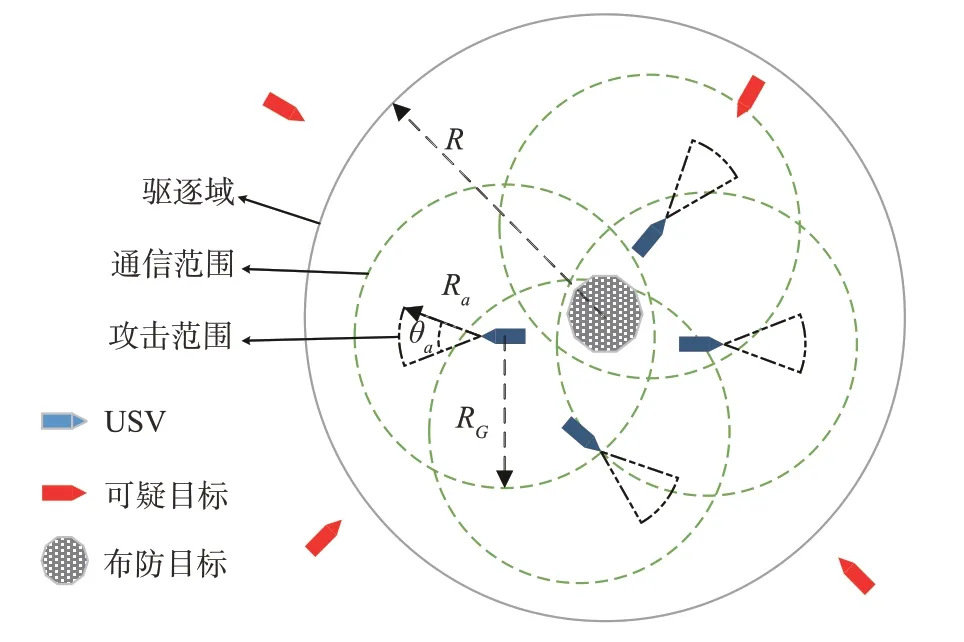
图1 USV集群驱逐任务模型Fig.1 Expulsion model of Swarm USV
图中中心点为布防目标,以布防目标为中心,半径为R的圆形区域为驱逐域,m个可疑目标(红色锥形目标)随机在驱逐域外一点生成并进行进攻,分别记为(T1,T2,…,Tm),相对应有m个USV(蓝色船),对应记为(G1,G2,…,Gm)从布防目标点出发进行驱逐作业。USV的通信范围用半径为RG的绿色圆圈表示,由于海上通信条件受限,USV无法与范围之外的友军进行信息交互,同时USV可以对正前半径为Ra、角度为θa的扇形区域攻击,其攻击范围的大小决定了USV接近可疑目标时,可疑目标的逃逸距离dflee。防守船的最终目标为将可疑目标成功驱逐出驱逐域。将每个可疑目标与布防目标之间的距离定义为(D1,D2,…,Dm),则该模型任务目标可以定义为
可疑目标遵循人工势场法快速逼近布防目标,其中布防目标对其有引力生成引力场,USV对其有斥力生成斥力场,综合势力场得到梯度下降最快的方向,这使得可疑目标每时每刻都能以最快的方向逼近布防目标,同时保证了可疑目标不会被USV贴近。此外,USV对其产生的斥力也是USV能够将可疑目标驱逐出驱逐域的原动力。但是在此设置下,若存在多个USV,每个USV都会对可疑目标产生斥力,将会极大影响可疑目标对布防目标的进攻,同时对USV的学习产生严重干扰,这将导致USV无法学习到好的驱逐策略,因此本文主要研究单个可疑目标及与其对应USV的驱逐任务,而USV之间的通信则在本文中不过多考虑。
对于每个可疑目标Ti及其对应的USVGi,其驱逐模型如图2所示。
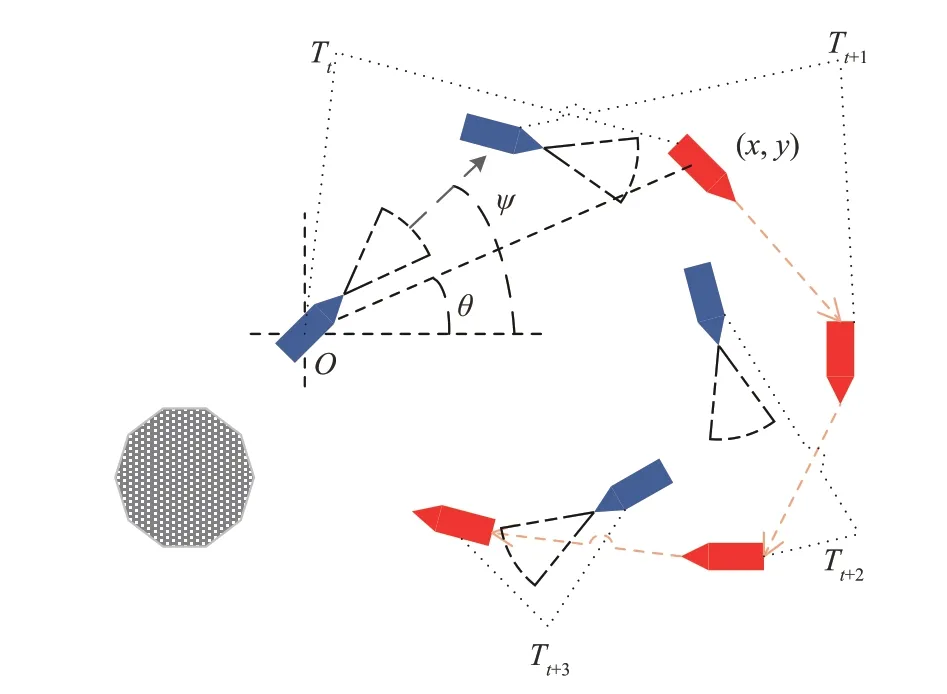
图2 单个可疑目标及与其对应USV的驱逐任务模型Fig.2 Expulsion model of UAV for a single suspicious target
图中ψ为USVGi的艏向角,USV在水面运动速度不可突变,因此USV运动过程是艏向角ψ连续变化的过程,需要尽快指向可疑目标以快速逼近驱逐目标。θ为可疑目标相对USV的方位角,与相对USV的距离ρ共同构成可疑目标的极坐标位置信息,其计算公式为
式中,(x,y)为可疑目标在USV以自身为原点的笛卡尔坐标系中的二维坐标值。三者共同构成了驱逐任务模型的状态信息St(ρ,θ,ψ)。
USV的动作则由布防驱逐算法根据状态信息训练得出,以保证能够以最优的策略实现驱逐,具体算法模型将在后续进一步介绍。
3 可疑目标驱逐方法
传统的驱逐对抗设计中只考虑了如何让USV学会逼近可疑目标,将接触或是接近到一定距离设置为成功条件,同时对于可疑目标的运动设置是极其简单的。但对实际的布防任务而言,可疑目标是迅速并且智能的,如图2所示,如果USV只是不断逼近可疑目标,可疑目标会在USV接近时主动进行回避,尤其是当可疑目标移动更快时,更易绕开USV的拦截与驱逐。因此需要对传统的跟踪追逐算法进行改进以实现对可疑目标的驱逐。
3.1 基于DRL的驱逐方法框架
DRL是一种将深度学习(Deep Learning,DL)整合信息的能力和强化学习(Reinforcement Learning,RL)决策能力相结合的方法。随着深度强化学习在围棋中的突破,证明了深度强化学习能够解决现实问题,使其在更多无人智能领域获得关注。
马尔科夫决策过程(Markov Decision Process,MDP)是强化学习的理论基础。智能体获得当前环境的状态值st,然后选择一个动作值at,环境状态转移至下一状态st+1,同时环境会给出一个收益rt+1。此后不断重复上述过程直到终局状态。
DRL的算法已经提出了很多种,深度Q学习网络(Deep Q-learning Net,DQN)[14]解决了当状态空间过于复杂和高维时穷举不可实现的问题,并在Atari2600游戏中有着不俗的成绩;随后针对DQN只能在离散空间中使用的缺陷,提出的深度确定性策略梯度算法(Deep Deterministic Policy Gradient,DDPG)[15]使DRL成功在连续环境中得到应用,并在Atari2600游戏中完胜DQN;还有诸如异步优势演员评论家网络(Asynchronous Advantage Actor-Critic,A3C)[16-17]、近似策略梯度优化(Proximal Policy Optimization,PPO)[18]等算法均在不同方面进行了优化,也取得了较好的成果。鉴于本文难题的特点,选择将能够解决连续控制性问题的DDPG算法作为基础算法;针对本文对抗性环境中的奖励稀疏(Sparse Reward,SR)[19]问题设计了其奖励函数;针对跟踪追逐算法将可疑目标当前位置作为目标点导致USV容易被绕开的问题,提出了一种意图预测及封堵策略;针对DDPG在训练开始时需要大量试错迭代学习的冷启动(Cold Start,CS)问题,设计了一种专家经验矫正纠偏策略对模型进行预训练,加快训练速度。整体算法框架如图3所示。
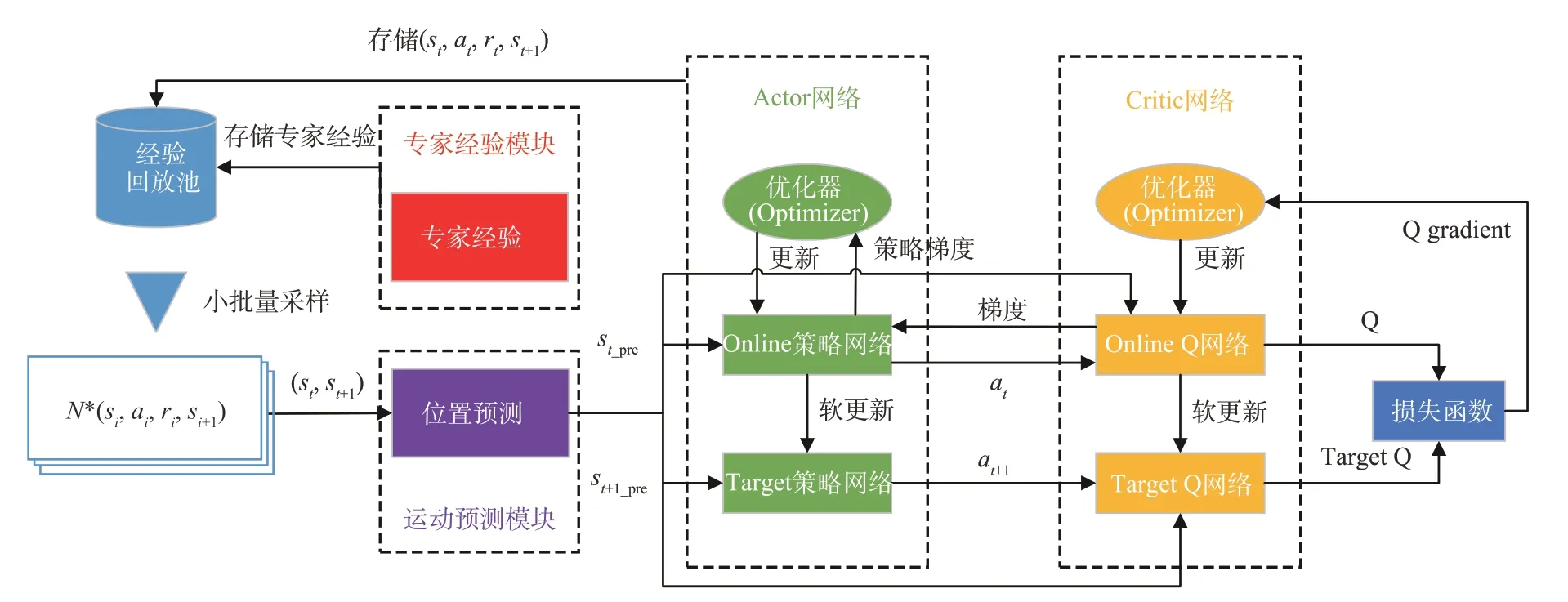
图3 基于DDPG的对抗驱逐算法框架Fig.3 Adversarial expulsion framework based on the DDPG algorithm
3.2 驱逐任务的奖励函数
传统跟踪追逐任务的奖励函数设计多为步进惩罚加上成功的奖励值,步进惩罚用于督促智能体选取更快的路径、更少的步数完成任务,成功的奖励值则用于智能体不断更新学习。
但是对于本文的对抗性驱逐环境,可疑目标的运动规则是固定的人工势场法,它会遵循势场梯度以最快的路径逼近布防目标,当USV靠近时会根据势场变化迅速远离USV。并且在环境设计中可疑目标是灵活的(速度、方向可以突变),这保证了它永远不会被USV追上。而USV在学习过程中完全随机探索,其能成功将可疑目标驱逐出驱逐域的概率是极低的。这将直接导致SR问题,USV将学习缓慢甚至无法学习。
因此为了加快智能体的训练,设计奖励函数,并稠化奖励值,在训练过程中给予USV更多的奖励,利于其学习,为此,将奖励函数定义为
式中,r为总奖励,rΔθ为夹角奖励,rT为可疑目标位置奖励,rGT为驱逐距离奖励。a,b,c为每个奖励的权重,符合a+b+c=1。
夹角奖励rΔθ与Δθ有关,Δθ定义为USV艏向角ψ与可疑目标相对USV方位角θ差值的绝对值。在USV运动过程中,希望Δθ尽量小,这意味着USV运动的方向是指向可疑目标,会不断逼近可疑目标的位置,便于驱逐任务的执行。因此,Δθ越小则rΔθ越大。
可疑目标位置奖励rT与可疑目标相对布防目标距离dT的变化有关。在USV运动过程中,希望dT越来越大,这意味着可疑目标在远离布防目标,当dT>R时则驱逐成功,因此dT增大则rT为正,dT减小则rT为负。但是考虑到在环境运行初期,USV还未接近可疑目标,此时可疑目标并不会因USV的接近而进行避让,因此dT在此时是单调减小的,这将导致在初期的位置奖励rT是不合理的,并不能有效反映USV此刻动作的好坏。因此对rT加入一个约束,当dGT>dflee时,b≡0,其中dGT为USV相对可疑目标的距离。
驱逐距离奖励rGT与USV相对可疑目标的距离的变化有关。在USV运动过程中,希望尽快接近可疑目标,因此dGT减小则rGT为正,dGT增大则rGT为负。与rT相反,在环境运行中后期,由于USV与可疑目标会在dGT=dflee附近时刻进行动态博弈,此时的rGT是不合理的。因此也对rGT添加一个约束,当dGT<1.1⋅dflee时,c≡0。
3.3 意图预测方法及封堵策略
对于驱逐任务来说,提出一个假设:可疑目标不能直接越过USV进攻布防目标,当USV接近可疑目标时,可疑目标需采取避让动作远离USV,也意味着远离布防目标,如图4所示。

图4 意图预测模型图Fig.4 Intention prediction model
式中,φ为USV和可疑目标与布防目标连线的夹角,其取值范围为(-180°,180°],dGO,dTO分别是USV和可疑目标相对布防目标的距离。
根据假设,提出一个引理:
如果能保证USV永远保持在布防目标和可疑目标中间,那么可疑目标将在任何时刻都无法接近布防目标,即
但是,传统的算法设计一般是向可疑目标的当前位置接近,这将导致可疑目标有机会绕开USV,如图2所示。
为防止可疑目标绕开USV导致无法驱逐,引入一种意图预测方法和封堵策略(Intention Predict and Blocking Policy,IPBP),通过不断改变USV的目标点防止在驱逐过程中USV被可疑目标绕开导致驱逐失败。在USV接近可疑目标前使用意图预测方法,在USV接近可疑目标后使用封堵策略。分两种情况进行不同设计,将可疑目标的逃逸距离记为dflee。
USV接近可疑目标前(dGT>dflee):对于可疑目标而言,USV还未接近时,USV对其并无威胁,因此可疑目标不会发生避让动作,其动作单调向布防目标接近。因此对于t时刻的可疑目标而言,通过记录其前几个时刻的位置序列即(ρt-m…ρt-2,ρt-1,ρt)和(θt-m…θt-2,θt-1,θt),其中ρ,θ为可疑目标相对USV的位置信息,表征序列长度。然后对得到的序列进行线性回归计算,即可对可疑目标进行意图预测,得到t+1,t+2…时刻可疑目标的位置信息,将预测出的位置信息作为USV的目标点。
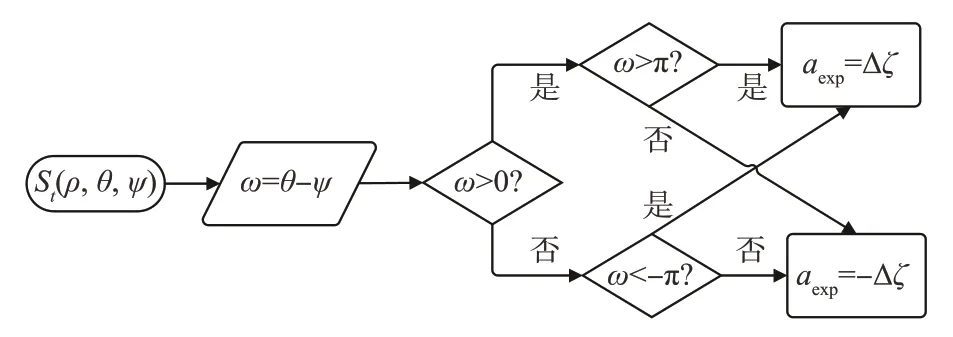
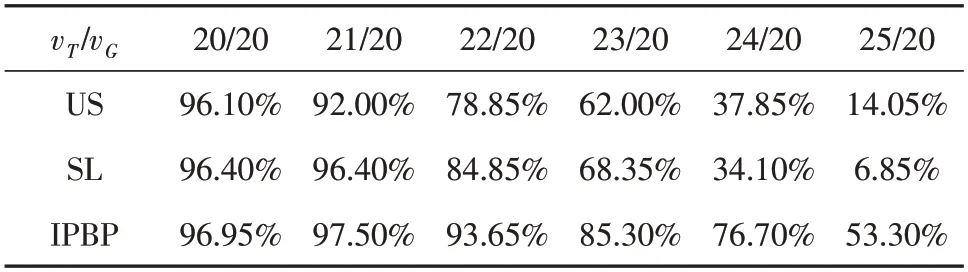
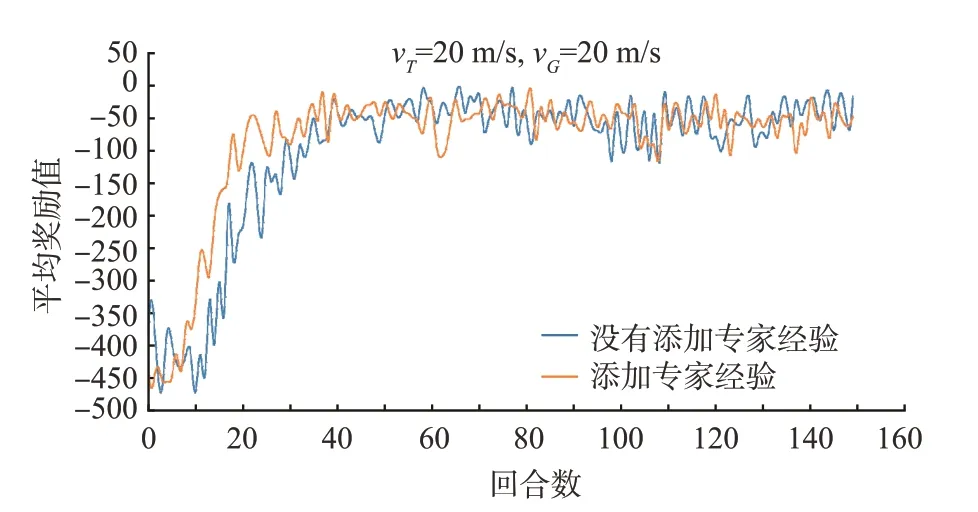
USV接近可疑目标后(dGT 图5 中间点封堵策略示意图Fig.5 Intermediate location for blocking policy 根据引理可知保证可疑目标无法成功接近布防目标的关键在于尽快使USV处于可疑目标与布防目标连线的中间,同时为了更快完成驱逐任务,需要USV靠近连线的同时尽快逼近可疑目标,因此提出一个点P,称为极限封堵点,该点为保证USV不断逼近可疑目标的同时一定不会被可疑目标绕开的最佳点。 如图5所示,P1点为T1O连线上一点,P1点位置满足P1T1/P1G1=vT/vG,式中vT,vG为可疑目标T和USVG的速度。 攻防开始时可疑目标T位于T1点,USVG位于G1点,dT1O>dG1O。显然可疑目标T进攻O的最快路径为T1O连线。假设经过时间t,USVG到达P1点,此时若T选择T1O路线,那么T同时到达P1点,此时满足dTtO=dGtO,T没有越过G,USV封堵成功。如果T选择其他路线,那么t时刻T的可能位置为以T1为圆心,P1T1为半径的圆内任意一点,此时一定仍然满足dTtO>dGtO,USV封堵成功。 因此只要保证USV每一步都前往当前时刻的极限封堵点,就能确保可疑目标无法越过USV,从而实现不断逼近可疑目标将其驱逐的目的。 由于本文环境中可疑目标会主动逼近布防目标,并在接近到危险距离时会判定失败重置环境,而在纯随机探索的情况下,这将导致在DDPG训练初期极易失败,需要对环境进行大量的探索;同时为了能够更好地探索最优策略,在训练过程中需要添加噪声以获得更多变复杂的动作用于学习。以上都导致想要学习到好的策略需要大量的时间。对于常规的应用DDPG的任务环境而言,其动作的好坏难以量化表达,因此需要长时间的迭代学习。 但是对于本文布防封控中具体的驱逐任务而言,USV的初始行为是可以预料并且量化的,即在驱逐任务开始时USV需要尽快瞄准可疑目标并向可疑目标附近前进。因此提出一个专家经验矫正纠偏策略,其目的为在训练初期对USV对动作的探索进行矫正与纠偏,减少USV动作的无用探索,使其尽快瞄准可疑目标,加快后续的训练。 因此需要得到一个专家动作序列(aexp1,aexp2…aexpT)使USV尽快瞄准,如图6所示。 图6 专家经验矫正纠偏策略模型图Fig.6 Expert experience’s correction strategy model 图示为t时刻,状态用St(ρ,θ,ψ)表示,其中ρ为可疑目标T与USVG的距离,θ为可疑目标T与USVG连线相对正东方向的偏转角,ψ为USVG的艏向角,θ和ψ的取值范围均为[0,2π)。同时考虑到USV在水面的运动特性,其每一步能够旋转的角度是有限的,将其每一步的动作a选取范围设置为[-Δς,Δς],Δς为其每一步能够旋转角度的最大值,a为正时USV逆时针旋转,为负时顺时针旋转。 训练初期需尽快瞄准可疑目标,可描述为 又因为a∈[-Δς,Δς],所以为了使T最小,aexp=±Δς,当aexp=Δς时,说明USV需逆时针旋转以瞄准可疑目标,当aexp=-Δς时,说明USV需顺时针旋转。并且对于一个确定的St(ρ,θ,ψ),其aexp具有单值性,即后续所有aexp均为Δς或-Δς。现证明其单值性。 假设对于某个确定的St(ρ,θ,ψ),其后有两个专家动作序列 式中,T1序列为单值序列,不妨令aexp≡Δς,则Δς·T1=θ-ψ,T2序列为非单值序列,假定有n个aexp=-Δς,则Δς·(T2-n)+(-Δς·n)=θ-ψ,联立可得T1=T2-2n,n∈N,因此T1为最小的动作序列,其为单值序列。因此只需根据St(ρ,θ,ψ)判断出训练初期时的专家动作aexp即可得到专家动作序列。 因此提出一种以当前状态值St(ρ,θ,ψ)为自变量的判断函数f(St),用于输出专家动作aexp。 其中条件判断函数f(St)设计如下: 记ω=θ-ψ,可得ω的取值范围为(-2π,2π)。当ω取(-2π,0)时,分两种情况:若ω∈(-2π,-π),则aexp=Δς,若ω∈(-π,0),则aexp=-Δς;当ω取(0,2π)时,同样分两种情况:若ω∈(0,π),则aexp=-Δς,若ω∈(π,2π),则aexp=Δς。逻辑图如图7 所示。 图7 条件判断函数模型图Fig.7 Conditional judgment function model 本节将详细介绍基于gym搭建的环境具体参数设置以及实验方案设置。gym是由openai开发的一款专门应用于开发和比较强化学习算法的工具包,它对智能体的结构不会进行任何假设,并且与任何数值计算库如Tensorflow等兼容,支持python语言对其进行编写,目前绝大多数研究强化学习算法的学者都会基于gym进行环境的搭建,这会为后面使用强化学习算法训练智能体提供便利。 整体环境大小为240 m×240 m,防守目标位于正中间,以防守目标为中心,半径20 m的圆形区域为安全区域,半径80 m的区域为驱逐域;护卫船将从防守目标处出发,速度vG为一定值,其艏向角ψ不可突变;可疑目标将在距离防守目标60 m之外的区域随机生成,速度vT为一恒定值,其运动规则服从人工势场法,其艏向角可以根据势场的变化立刻改变以满足人工势场法。环境的渲染设置为1秒60帧,这也意味着USV用强化学习1秒进行60次迭代学习,而本环境设置每一回合最多训练次数为1000次,这些限制条件影响了vG和vT的设置。速度值不能设置过于小,这将导致学习初期USV与可疑目标无法快速接近,学习效率较低,并且在有限的回合步数中难以成功将可疑目标驱逐,这会大大影响USV学习的效率;同时速度不能设置过于大,这将导致USV与可疑目标的步长过大,训练效果会变差。因此综合考虑,将vG设置为20 m/s,vT设置为20 ~25 m/s较为合适。 为了测试意图预测及封堵策略的有效性,设置了三个对照组进行了实验。三个对照组分别为: 1.空白组(Untreated State,US):将状态信息St(ρ,θ,ψ)作为DRL算法的输入进行训练; 2.自学习组(Self-Learning,SL):通过将连续三个时间的状态信息(ρt-2,θt-2,ψt-2,ρt-1,θt-1,ψt-1,ρt,θt,ψt)作为算法输入,希冀DRL能够自主通过连续的状态信息预测其意图; 3.策略组(IPBP):添加意图预测及封堵策略的对照组,将Spredict(ρpredict,θpredict,ψpredict)作为算法输入进行训练。 每个对照组进行了20次实验并取平均值作为结果进行对比,每一次实验训练了150个回合,每回合最大训练步数为1000步。 如图8所示,可以发现在vT较小时,三种方法均能收敛并且学习效果相差不大,甚至US和SL组的奖励值更高,这是因为在可疑目标低速进攻的情况下,通过设计的奖励函数就已经足以让USV学习到足够好的驱逐策略。但是当vT不断增大时,US和SL组的回合平均奖励值下降非常快,这是因为当vT不断增大时,US和SL组中的USV难以跟上可疑目标的位置变化,难以将可疑目标驱逐,随着速度增大,USV越来越难获得正向奖励值,因为可疑目标越来越容易逼近布防目标,因此在图8中可以看到,随着速度增大,回合平均奖励值不断降低。直到vT=25 m/s时,US和SL组奖励值基本没有增长,这意味着没有任何学习效果,也意味着对于US和SL组已经达到了它们的极限,在这个速度下,US和SL组很难获得正向奖励了,USV只要离开布防目标稍远一点,可疑目标就会迅速找到一条进攻路径成功攻击到布防目标,而IPBP组在vT=25 m/s时仍然还有较好的表现,这说明IPBP组USV能够在一定范围内驱逐性能比自己更好的目标。 图8 可疑目标不同速度下训练实验结果Fig.8 Experimental results of training suspicious target at different speeds 而在驱逐的成功率和性能的稳定性方面,在20次实验结束后,对每一次训练得到的模型进行100次测试并记录其成功次数。最后汇总20个模型的测试结果并取均值进行对比。如图9、表1所示。 表1 可疑目标不同速度下驱逐成功率Table 1 The success rate of expelling suspected targets at different speeds 图9 可疑目标不同速度下驱逐成功率Fig.9 The success rate of expelling suspected targets at different speeds 可以发现在vT=20 m/s时,US和SL组也能有较好的成功率,与IPBP组差别并不大,这也说明了在可疑目标性能不强时,常规的一些强化学习算法即可完成对USV的训练,甚至有不错的效果;但是随着vT的增大,US和SL组的成功率下降非常快,在vT=25 m/s时基本无法完成驱逐任务。而IPBP组虽然成功率也在下降,但是在vT=25 m/s的情况下仍然还能有53.3%的成功率。说明添加意图预测和封堵策略有助于USV学到更好的驱逐方法,完成对可疑目标的驱逐任务。 为了测试专家经验矫正纠偏策略对USV学习策略的加速效果,同样设置对照组进行实验对比,结果如图10所示。 图10 专家经验实验结果Fig.10 Experimental results about the expert experience 图10为在vT=20 m/s的情况下添加专家经验与否的实验结果,可以看出没有添加专家经验的实验组算法大概在40回合收敛,而添加了专家经验的实验组算法在25回合左右就能收敛。vT取不同的值也有相似的结果。添加专家经验相比没有添加提前了大概15个回合就能使算法训练达到收敛。 当然,由于每个回合的步数不同,并不是每个回合都运行了1000步后才进入下一回合,因此仅仅用收敛所需的回合数来判断专家经验的加速效果是不准确的。为了正确地反映专家经验是否有加速收敛的效果以及量化反映加速的效果是好还是差,将vT取不同的值进行了实验,并重复进行了20次,然后对每次实验训练达到收敛的时间进行了记录并取其均值,最终结果如表2所示。 表2 收敛时间实验结果Table 2 Experimental results of convergence time 从表2中可以看出,当vT增大时,没有专家经验训练收敛所需的时间越来越大,而有专家经验则相对稳定,并且有专家经验所需的时间远小于无专家经验所需时间,这说明专家经验矫正纠偏策略能够实现算法的加速训练,并且对算法的稳定也有一定效果。 本文针对具体的USV海上布防任务问题,以其中的驱逐任务为背景搭建了一个基于gym的强对抗环境,并提出了基于深度强化学习的可疑目标驱逐方法框架,然后在可疑目标不同速度值下对USV进行训练。实验结果表明,本文提出的方法框架能够提升USV的训练速度,速度提升率最高可达82.90%。在不同速度下该方法框架训练所得的驱逐成功率均为最佳,并且在速度差较大的情况下仍然能有53.30%的成功率。综上所述,本文所提出的驱逐方法框架能够解决驱逐任务问题。但是本文仅在二维环境中进行了建模,未来还需在三维环境中进行实验测试,以验证其实用性。 USV海上布防任务是一个综合研究课题,驱逐任务只是其中的一个难题,针对的是对于布防目标一定范围内,侦察到的低威胁目标。对低威胁目标而言,我们无需对其进行火力歼灭,而是需要将其驱逐出一定范围即可。本文则是研究了布防任务中驱逐任务的解决方法,后续可进一步研究如何实现控制、歼灭、侦察等其他任务。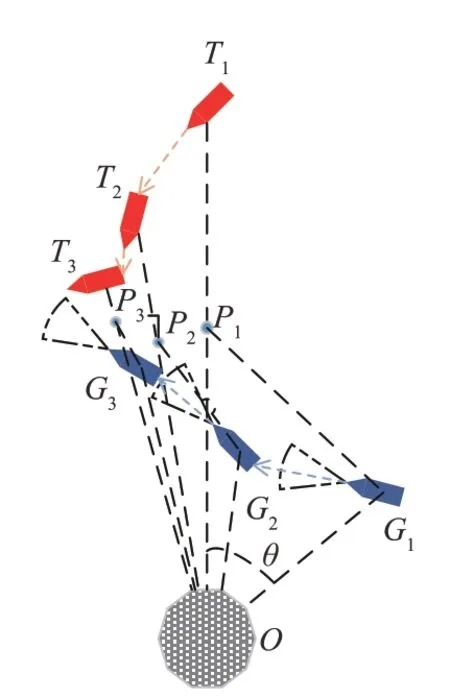
3.4 专家经验矫正纠偏策略

4 仿真实验结果及分析
4.1 测试意图预测及封堵策略实验

4.2 驱逐成功率实验

4.3 测试专家经验矫正纠偏策略实验

5 结 论
