融合简化句法信息的端到端方面级情感分析
2023-10-30张济群张名芳郭军军
张济群,张名芳,郭军军,相 艳
1.昆明理工大学 信息工程与自动化学院,昆明 650500
2.昆明理工大学 云南省人工智能重点实验室,昆明 650500
基于方面的情感分析(aspect-based sentiment analysis,ABSA)关键任务是检测出评论中提及的方面术语,即方面术语提取[1-4(]aspect term extraction,ATE),同时预测方面术语的情感极性,即方面术语情感分类[5-8](aspect-based sentiment classification,ASC)。例如在句子“The cheese pizza is delicious.”中,方面术语分别是“cheese pizza”,对应的情感极性为积极。最初的研究工作大多解决其中的某一个子任务,但需要事先给出评论中的方面术语,限制了其实际使用。因此,有研究者提出将两个子任务以联合标签的方式连接在一起[9-10],直接建模为序列标注问题[11-12],如表1所示,用{B-(POS,NEG,NEU),Ⅰ-(POS,NEG,NEU),E-(POS,NEG,NEU),S-(POS,NEG,NEU)}分别表示方面术语的开始,内部,结尾和单个方面词及其对应的情感极性,O表示非方面术语。这种标注方式也称为端到端方面级情感分析(E2E-ABSA)。

表1 E2E-ABSA联合标签方案说明Table 1 E2E-ABSA unified tagging scheme description
目前E2E-ABSA 的研究主要设计不同的特征编码器和解码器,将ABSA 形式化为一个统一的框架,提升性能。例如Schmitt 等人[13]提出使用卷积神经网络(convolutional neural network,CNN)作为特征提取器,CNN可以识别局部特征,且有很强的并行计算能力,一般来说,带有情感倾向的词会影响整体结果,所以CNN网络可以很好地应用到ABSA任务中。Li等人[6]设计了一个堆叠的循环神经网络(recurrent neural network,RNN)模型作为特征编码器,这种设计基于统一标记方案下,跨度信息与边界标记的信息完全相同,RNN网络可以缓解远距离依赖,下层RNN提供引导信息,执行目标边界预测,上层RNN生成最终预测结果。Li等人[7]使用拥有强大语言表征能力和特征提取能力的双向语言模型BERT 或其变体Deem BERT 作为特征提取器,并与下游神经模型耦合以完成任务。
以上E2E-ABSA 模型主要考虑了如何设计编码器获得较好的方面特征,从而更好地预测联合标签。事实上,方面术语和观点术语通常是名词短语或形容词名词短语的组块形式;同时,方面术语和观点术语之间存在句法联系,观点术语的正确识别有利于方面术语的情感极性预测。上述的特性可以通过句法分析工具获取。但是,直接通过句法工具解析的依赖树通常有很多节点,这不利于对方面词和观点词的整体判断。因此,需要对句法标记节点信息进行简化,实现方面术语和观点术语的整体提取,构建方面术语和观点术语之间的联系。以图1 评论“It had the fully sized touch pad.”为例,在属于同一方面术语的“touch”和“pad”之间存在依赖关系“nn”。如果可以简化这种依赖关系,并将它们与父节点“had”直接连接,那么就会形成一个完整的方面术语“touch pad”。类似地,如果可以简化“fully”和“sized”之间的依赖关系“dep”,并将其与父节点“touch”直接连接,则将形成完整的观点术语“fully sized”,并连接到方面术语“touch pad”上。

图1 采用Biaffine句法解析的原始句法树结构Fig.1 Original syntax tree structure with Biaffine parsing
本文提出了一种融合简化句法标记信息的E2EABSA 模型,设计了一组剪枝规则来重塑原始的依赖树,以获取简洁的句法依赖标记,从而表示术语完整性及方面术语和观点术语之间的相关性;同时,利用自注意力网络,将句法依赖标记表征融入模型。在两个公共评论数据集上进行了实验,并与多个基线模型进行了比较,结果表明,本文所提模型具有更优的性能。
1 相关工作
以往的研究工作大多集中于ABSA的某个子任务,即ATE或ASC。ATE通常被视为序列标注问题[14],最近的研究尝试将ATE建模为序列到序列的学习,在预训练语言模型上获得了很好的效果[15-16]。对于ASC,之前有研究使用LSTM 网络提取方面词和上下文之间的联系[17];之后的研究提出,ASC 通过注意机制将方面词和上下文联系起来是有帮助的[18]。此外,还有模型使用了门控机制和存储机制,来解决ASC问题[19-21]。
由于两个子任务是高度关联的,将二者视为两个独立任务限制了它们的实际应用价值。因此,有研究者提出使用联合标注体系的方法同时解决这些问题。他们使用一组方面标签{B,Ⅰ,E,S,O}来表示方面术语的开始、内部、结束、单个单词和空值,同时使用另一组情感标签{POS,NEU,NEG}来表示方面术语的积极、中性和消极情绪。此标记方案通常用于两个子任务的联合训练。例如Ma 等人[22]提出多级的双层门控循环网络(gated recurrent unit,GRU),该模型考虑了单词和字符两个层面的嵌入特征,建模了字符级特征和高级语义特征之间的关系。更多的模型考虑了方面术语和情感极性的关系。Klinger 和Cimiano 等人[23]提出的联合模型可以从两个方向分析方面和主观短语之间的关系,并做出预测。在此基础上,Yang等人[24]使用CRF将观点持有者、方面和观点表达建模为一个序列标记,将方面和观点表达与句法关系相结合。Luo等人[25]提出了一种基于注意力机制的双循环神经网络交叉共享(dual cross-shared RNN)的框架,使用两个BiLSTM 分别提取方面词和情感极性的表征,同时使用一个交叉共享的单元来考虑它们之间的关系。
E2E-ABSA 使用联合标签方案消除了ATE 和ASC两个子任务的边界。Schmitt等人[13]提出的模型将CNN和Bi-LSTM 作为特征提取器,并在最后使用softmax 分类来判断一个词是否是方面词。如果是,则模型输出情感极性。E2E-ABSA 需要考虑同一方面词的情感极性一致性。为此,Li等人[6]设计了一个包含两个堆叠RNN的新型统一框架。下层通过向上层RNN提供引导信息来执行目标边界的辅助预测,上层生成最终预测结果。该模型通过门控机制将当前单词与前一个单词进行集成,以保持同一方面术语中的情感一致性。在利用不同粒度信息方面,He等人[26]提出了交互式多任务学习网络(interactive multi-task learning network,IMN),它可以同时联合学习token 级和文档级的多个任务。此外,预训练模型和图模型为E2E-ABSA 提供了新的思路。例如,Li 等人[7]使用BERT 将上下文单词嵌入层与下游神经网络层耦合,以完成任务。Liu 等人[27]提出了一种新的动态异构图联合模型,该模型同时使用单词和情感标签作为节点,实现方面和情感之间的交互,进一步提高了ABSA的性能。
上述E2E-ABSA 方法仅侧重于将ABSA 形式化为一个统一的框架,而忽略了评论中不同单词的相关性对这项任务有很大作用。因此,本文重点对方面词和观点词之间的内部关系进行建模,以提高模型的性能。
2 本文模型
图2给出了本文模型的结构,主要由BERT表征层、句法简化层和特定任务层组成。BERT表征层获取评论的上下文表征;句法简化层根据一组规则对句法依赖树进行重塑,获得简化的句法表征;特定任务层采用单层注意力机制变体TFM[7(]self-attention network variant),以更好地融合上下文表征和句法表征,并使用softmax函数预测每个单词对应的标签。
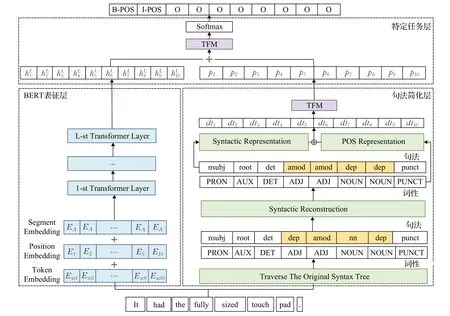
图2 本文模型总体框架Fig.2 Overall framework of model
2.1 BERT表征层
将输入的评论文本表示为W=(w1,w2,…,wn),其中n是句子的长度。通过BERT模型来计算W对应的上下文表征。输入特征表示为H0=(e1,e2,…,en),其中ei(i∈[1,n])是输入评论中的词wi对应的词嵌入(token embedding)、位置嵌入(position embedding)和段嵌入(segment embedding)的组合。然后引入L层transformer,逐层细化词级特征。具体而言,第l(l∈[1,L])层的特征表示HL计算如下:
2.2 句法简化层
2.2.1 句法剪枝规则
评论中的显式方面词基本上是多个名词的组合、形容词和名词的组合以及副词和名词的组合。也就是说,方面词与句法和词性密切相关。本文总结了如表2 所示的规则。如果两个单词满足表2 中的词性关系和句法依赖关系,就将尾节点(句法关系指向的节点)的初始依赖标记更改为与头节点(句法关系出发的节点)一致。

表2 句法规则设置Table 2 Syntax rule setting
2.2.2 句法标记获取过程
首先,遍历每个句子的原始句法树,获得可能的句法序列。以句子“It had the fully sized touch pad”为例,以“had”作为根节点遍历其原始语法树,并获得三个序列,如表3所示。

表3 通过遍历原始语法树获得句法序列举例Table 3 Examples of syntactic sequences obtained by traversing original syntax tree
接下来,设置一个宽度为2 的窗口,并将窗口在句法序列上从开始到结束以步长为1进行滑动,处理窗口中的单词。如果窗口中的两个单词符合表2 中的规则之一,将更改这两个单词的依赖关系,使其与头节点相同。
例如,对于滑动窗口中的两个单词“fully”和“sized”,对应的词性分别为“ADV”和“ADJ”,两词之间的依赖关系是“dep”,对应表2 中的第五行。头节点是“size”,尾节点是“fully”。由于“size”的父节点是“touch”,对应依赖关系是“amod”,将“fully”和“touch”之间的依赖关系更改为“amod”,并删除“fully”和“sized”之间的依赖关系“dep”。其余单词的句法标记也如此更新,如图3所示。经过句法简化,同一方面术语的“touch”和“pad”用相同的句法标记直接连接,而同一观点术语中的“fully”和“sized”通过依赖关系“amod”与方面术语“touchpad”直接连接。

图3 句法树结构Fig.3 Syntax tree structure
2.2.3 句法标记的表征
在简化句法标记之后,将句子中每个词的句法标记和词性标记按顺序排列。在上面的示例中,原句法标记为nsubj、root、det、dep、amod、nn、dep。经处理后,句法标记为nsubj、root、det、amod、amod、dep、dep;相应的词性标记为PRON、AUX、DET、ADV、ADJ、NOUN、NOUN、PUNCT。
为句法标记和词性标记生成句法表征HD=(d1,d2,…,dn)和词性表征HT=(t1,t2,…,tn)。不同的标记di和ti用一定维度的随机生成的向量来表示。对两种表征进行拼接操作,获得句法标记的整体表征HDT=(dt1,dt2,…,dtn)。
使用自注意力网络的变体(self-attention network variant,TFM)[7]进一步学习句法增强表征HP=(p1,p2,…,pn)。TFM结构如图4所示,具体的计算过程如下:
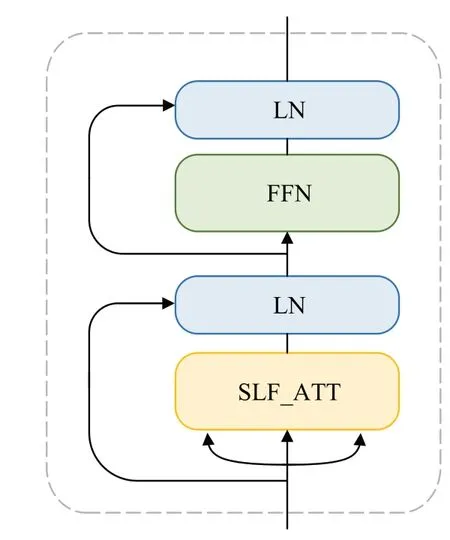
图4 TFM的结构Fig.4 Structure of TFM
将句法标记的整体表征HDT作为TFM的输入,经过点乘注意力机制[28(]self-attentive scaled dot-product attention,SLF_ATT)生成包含更多信息的表征。
其中,LN为层标准化(layer normalization)。
2.3 特定任务层
在获得上下文表征HL和句法增强表征HP后,将二者相加,获得维度为dimh的表征HF:
然后将HF送入TFM,获取最终表征,TFM的计算过程按照上述公式(2)~(4)进行。
最后,使用线性变换和softmax以输出每个词wt的预测结果yt。
其中,Wo和bo表示线性层可学习的参数。
通过在所有数据上最小化目标y和预测之间的交叉熵损失来训练本文所提模型。
其中,i是数据的索引,j是情感类别索引。
3 实验与分析
3.1 数据集
使用来自SemEval 的两个产品评论数据集[29-31]进行模型评估,表4 给出数据集的统计信息。Laptop 是SemEval 2014笔记本电脑领域的评论,Rest是SemEval 2014、2015和2016餐厅数据集的合集。
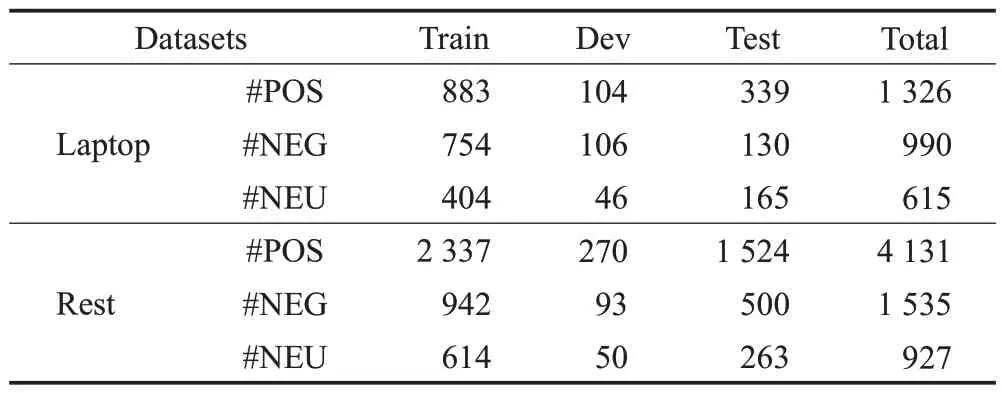
表4 数据集描述Table 4 Dataset description
3.2 评价指标
本文所采用的评价指标是方面术语作为一个整体的准确率(P)、召回率(R)和F1-score(F1)。其中对应的公式如下所示:
其中,TP对应真阳的数目,FP对应假阳的数目,FN对应假阴的数目。
3.3 实验参数设置
在句法标记的表征中,句法表征HD和词性表征HT的维度均为384,拼接得到的整体表征的维度为768;文本表征使用“BERT-base-uncased”[32]模型,其中transformer 的层数L数量为12,隐藏层的维度为768。对于Laptop 数据集,batch size 设置为32,对于REST 数据集,batch size 设置为16,使用Adam 进行参数优化,学习率为2E-5。将模型训练到1 500 步。在训练1 000个步骤后,以100步为一个周期计算模型在验证集上的误差。用不同的随机种子训练了五个模型,并报告了平均结果。
3.4 对比模型
NN-CRF[33]:这是一个使用单词嵌入和神经网络的增强型CRF模型,也采用联合标签方案。神经网络的隐层维数为200,AdaGrad 的初始学习率为0.001,正则化参数为10-8。
LSTM:这是一种使用标准LSTM 网络作为特征提取器,并采用联合标签方案的序列标记模型。
LSTM-CNN-CRF[34]:这是一种增强的CRF模型,使用LSTM 和CNN 网络的单词嵌入和特征提取器,并采用联合标签方案。
HAST-TNet:HAST[3]和TNet[5]分别是ATE和ASC的经典模型。HAST使用历史信息预测当前单词,TNet有三层,底层为Bi-LSTM,上层为CNN。HAST-TNet是使用这两种模型的管道方法。
DOER[25]:这是一个双重交叉共享的RNN 框架,利用ATE 和ASC 的交互作用,输出所有的方面词和其对应的情感极性。使用Adam作为优化器,学习率为0.001,dropout率为0.5,最大迭代次数设置为50。
BG-CS-OE[6]:使用两个叠加递归神经网络,其中下层神经网络用于辅助方面术语的边界识别,上层神经网络用于联合标签预测。该模型使用Adam 进行参数优化,初始学习率为10-3,迭代次数设置为50,dropout率设置为0.5。
IMN[27]:一个交互式多任务学习网络,可以同时学习单词级和文档级的多个相关任务。该模型使用Adam进行参数优化,学习率为10-4。
DHG[28]:以单词和情感标签为节点,构造一个动态异构图,并通过迭代不断修剪该图。该模型使用Adam进行参数优化,学习率为10-4,迭代次数为3,阈值设置为0.75。
MTMVN[35]:多任务多视图网络架构,统一的端到端ABSA任务作为主任务,ASC与ATE作为辅助任务别构建视图,通过在多视图学习的思想下增强视图之间的相关性,通过优化全局视图表示提高模型整体性能。
C-ATT[36]:使用相邻注意力机制和等级限制,从而归纳句中的不同成分。加入成分感知系数,使方面术语更加关注对应的观点术语。该模型使用Adam 进行参数优化,学习率为5E-5。
对比表5 中的F1 值,有以下分析:(1)在所有使用Word2vec 作为词嵌入表征的模型中,LSTM-CNN-CRF性能相对较高。该模型在LSTM 的基础上,利用CNN进一步学习字符级特征,并以CRF 为解码层,从而获得全局最优的标签序列。相比于最强基线LSTM-CNNCRF,Our model-Word2vec在数据集Laptop和Rest上分别获得了2.92 和8.77 个百分点的提升。这证明加入了简化句法的模型可以更好地学习序列特征,从而提高ABSA 的性能。(2)在基于Glove 的模型中,HAST-TNet模型集成了HAST 和TNet,与LSTM-CNN-CRF 相比有所改进。然而,管道形式会造成不可避免的误差累积,因此改进是有限的。DOER 使用两个网络来生成方面术语和情感极性的不同表示,并使用交叉共享单元来学习ATE 和ASC 任务之间的关系,在两个数据集上的F1值都显著高于HAST-TNet;同样的,联合模型IMN通过一个交互式多任务学习网络,执行方面术语和观点术语的联合提取、方面级情感分类、文档级情感分类和文档级领域分类四个任务。通过四个任务的信息交互,该模型在Laptop 数据集上具有较好的性能。然而DOER 和IMN没有限制方面术语的界限,会导致同一方面术语内出现不同的情感极性,Our model-Glove 通过句法简化的方法,将属于同一方面术语的单词赋予相同的句法标记,在一定程度上辅助了方面术语的边界的判断,相比于最强基线DOER,在Rest数据集上提升了1.08个百分点。(3)在基于BERT的模型中,C-ATT使用相邻注意力机制和等级限制,一定程度上限制了方面术语的边界,同时加入成分感知系数,使方面术语更加关注对应的观点术语。Our model-BERT与之相比在数据集Laptop上的F1 值提升了0.95 个百分点,这证明本文所提模型采用的简化句法在保证方面术语完整性的同时考虑到了方面术语与观点之间的联系,将简化的句法信息和上下文信息的结合可以提高ABSA的整体性能。
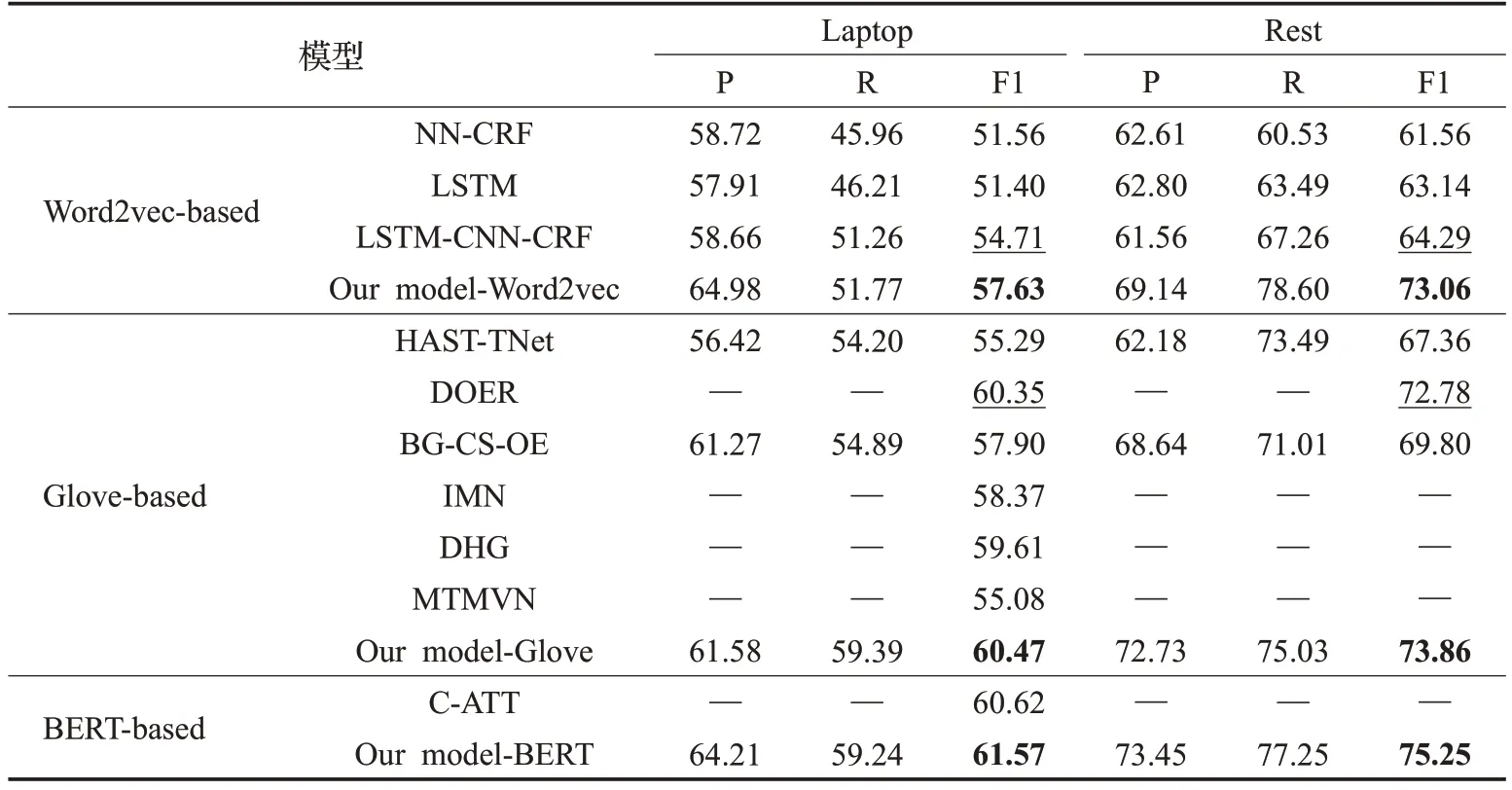
表5 不同模型的实验结果Table 5 Experimental results of different models 单位:%
3.5 消融分析
为了验证本文提出的融合简化句法信息的有效性,本文设计了消融模型并在Rest数据集上进行了实验。
(1)Bert-TFM:使用BERT层来获得上下文表示,并使用单层TFM 来微调模型,而不融合任何句法信息或词性信息。
(2)Bert-TFM+dep_tree:将未经简化的初始句法依赖标记表示为随机向量,添加到从BERT层获得的上下文表示中,并在上层使用TFM。
(3)Bert-TFM+pos:将词性表征添加到从BERT 层获得的上下文表征中,并在上层使用TFM。
(4)Bert-TFM+new_dep_tree:将简化的句法表征添加到从BERT 层获得的上下文表征中,并在上层使用TFM。
(5)Bert-TFM+dep_tree+pos:将未经简化的初始句法依赖标记信息表示为随机向量,与句法表征拼接在一起,然后将拼接表征添加到从Bert层获得的上下文表征中,并在上层使用TFM。
实验结果如表6所示。与Bert-TFM相比,Bert-TFM+dep_tree 的P 值有所提高,而R 值降低了0.62 个百分点。说明句法信息有助于方面词和情感极性的准确识别,从而提高精度。但另一方面,解析工具获得的句法树包含过多的子节点,影响了方面词的整体判断,某些方面词可能会遗漏,导致R值下降。与Bert-TFM+dep_tree相比,Bert-TFM+new_dep_tree的P值和R值分别增加了0.27和0.61个百分点,这说明简化句法信息由于减少了冗余节点,形成方面术语在一定程度上有助于模型确定方面术语的边界。
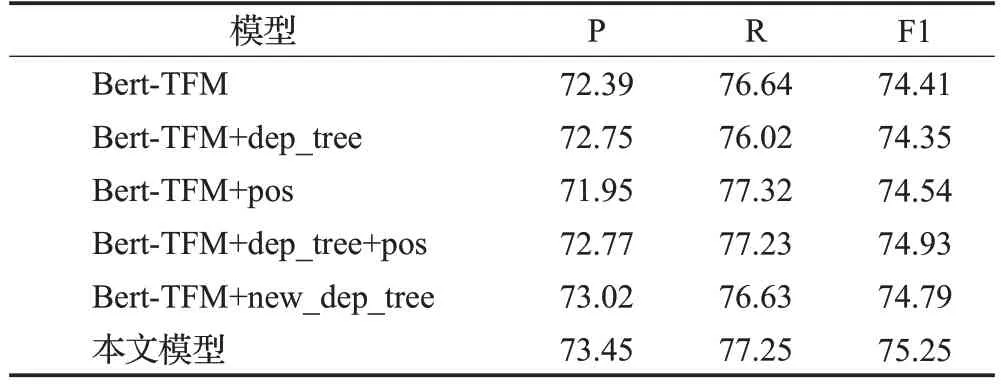
表6 消融分析的实验结果Table 6 Experimental results of ablation analysis单位:%
与Bert-TFM 相 比,Bert-TFM+pos 的P 值降低了0.44个百分点,R值增加了0.68个百分点。方面词通常是形容词短语和名词短语,词性信息可以引导模型更加关注这些词,从而提高召回率。另一方面,如果模型过度依赖词性,则会影响其判断,降低其精确率。
Bert-TFM+dep_tree+pos在Bert-TFM的基础上增加了句法依赖信息和词性信息,提高了性能。本文模型将简化的句法信息和词性信息结合起来,更准确地判断方面术语的边界,同时利用注意机制在一定程度上获得方面词和观点词之间的联系。因此,本文模型获得了最好的性能。
3.6 案例分析
使用IMN、Bert-TFM+dep_tree+pos 和本文模型给出了两个实例及预测结果,并显示了三个模型识别出的观点词,如表7 所示。在实例1“Ican say that Iam fully satisfied with the performance that the computer has supplied.”中,IMN 和Bert-TFM+dep_tree+pos 能够正确识别方面词“performance”,但相应的情感极性预测是错误的,而本文模型预测结果则完全正确。这是因为与方面词对应的观点词“fully satisfied”是一个词组,IMN 和Bert-TFM+dep_tree+pos 识别出的观点词“full”不完整,导致对情感极性的错误预测。本文方法对于该示例的句法简化过程如表8 所示。在原句法结构中,“fully”和“satisfied”的依赖关系标签分别为“dep”和“comp”。同一观点词的依赖关系标签不一致,会干扰观点词的识别,导致情感极性判断不准确。经过句法重构,“satisfied”和“fully”被标记为同一标签“ccomp”。这样,就保证了“fully satisfied”作为观点表达的完整性,从而获得正确的预测。
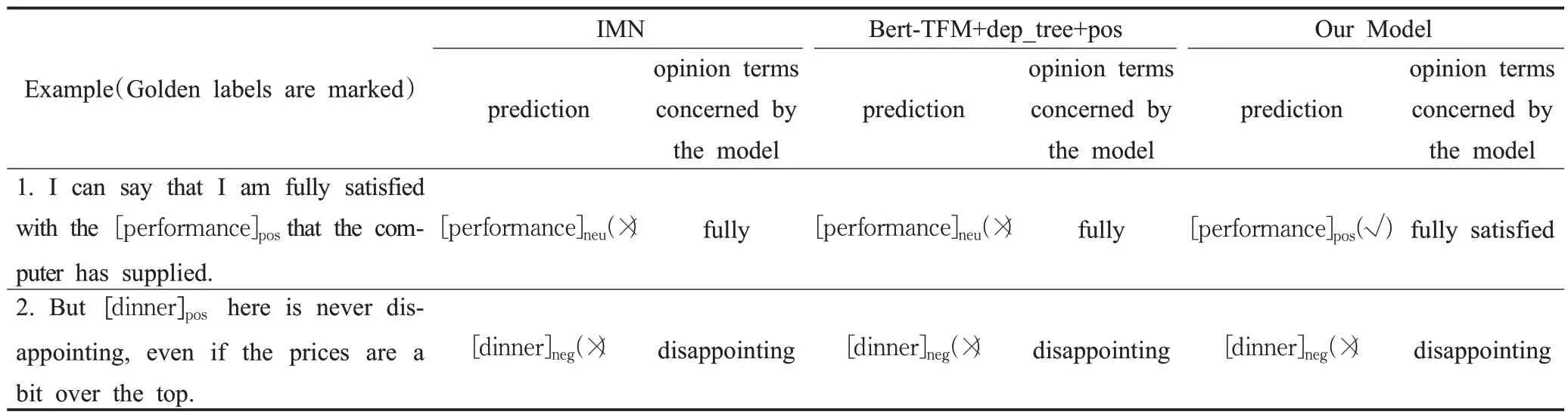
表7 案例分析Table 7 Case analysis

表8 实例1的句法解析Table 8 Syntax analysis of example 1
在实例2“But dinner here is never disappointing,even if the prices are a bit over the top.”中,方面术语为“dinner”,对应的情感极性为正向。这三个模型都能正确地检测到方面术语“dinner”,但都不能正确预测情感极性。这是由于实例2为双重否定,模型很难预测这类句子的情感极性。结果表明,一些复杂的语言表达可能会超出本文模型对情感极性的预测能力。
4 结论
本文提出了一个E2E-ABSA模型,考虑了方面术语和观点术语之间的句法关系,对句法标记进行了重塑;同时,利用注意机制实现了简化句法信息和上下文信息的融合,从而增强了模型的预测能力。在SemEval数据集上的大量实验表明,重构的句法表征有助于方面术语的识别和对应的情感极性检测,所提句法标记重构规则是合理的。
