基于轻量化YOLOv5s 的交通标志检测研究
2023-10-29章羽罗素云
章羽,罗素云
(201620 上海市 上海工程技术大学 机械与汽车工程学院)
0 引言
交通标志规定了车辆在道路上的行驶规范,是必须要遵守的基本规则。智能驾驶汽车在公路运行的首要任务就是能准确识别交通标志,按照交通标志安全驾驶[1]。因此,交通标志的检测和识别对智能车辆安全行驶具有重大意义[2]。
近年来,深度学习在视觉领域表现优异,交通标志的检测也由原来的传统机器学习方法转为深度学习方法[3]。深度学习在目标检测领域主要有2 条技术路线:一是Anchor-based,例如Faster-RCNN[4]、SSD[5]算法等;二是Anchor-free,CornerNet[6]、FCOS[7]和FSAF[8]算法等。在Anchorbased 技术路线下,又分为单阶段目标检测算法和双阶段目标检测算法[9]。单阶段目标检测算法有YOLO 系列和Retina-Net[10]等,双阶段目标检测算法有RCNN[11],SPP-Net[12]和Fast R-CNN[13]等。单阶段算法速度快、消耗算力少,而双阶段算法检测精度高,但速度稍慢。李一鸣等[14]采用YOLOv5s对轧钢表面缺陷的检测,能有效检测6 种不同形态的表面缺陷,有助于生产人员准确把握轧钢情况;宋甜等[15]通过改进YOLOv5s 对车载红外图像目标进行了检测研究,通过嵌入注意力模块和替换CIoU 损失函数,成功将mAP@0.5 的值提升了3.4%,实现了对车载红外图像目标的高效检测。YOLOV5s 模型具有很强的泛化性能,可对交通标志实现准确检测。由于本研究所应用的Jetsonnano 开发板最大功率只有10 W,算力相对较小,同时还要满足交通标志检测的实时性要求,因此决定选用YOLOv5s 作为基础模型。
本研究通过注意力机制SENet[16]和CBAM 提升YOLOv5s 的目标检测精度,将YOLOv5s 模型的卷积核数量缩减至原来的一半,得到的轻量化模型既达到交通标志检测的精度要求,也满足了实时性的需要,有助于智能车辆在道路上实时安全行驶。
1 YOLOv5s 模型介绍
根据网络模型C3 个数和卷积核数量的不同,YOLOv5 分为YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x 等版本。其中YOLOv5s 模型最小,计算量最低,由于本研究是在嵌入式设备上进行部署,所以选用YOLOv5s 模型作为基础检测模型。YOLOv5s 网络模型结构如图1 所示。
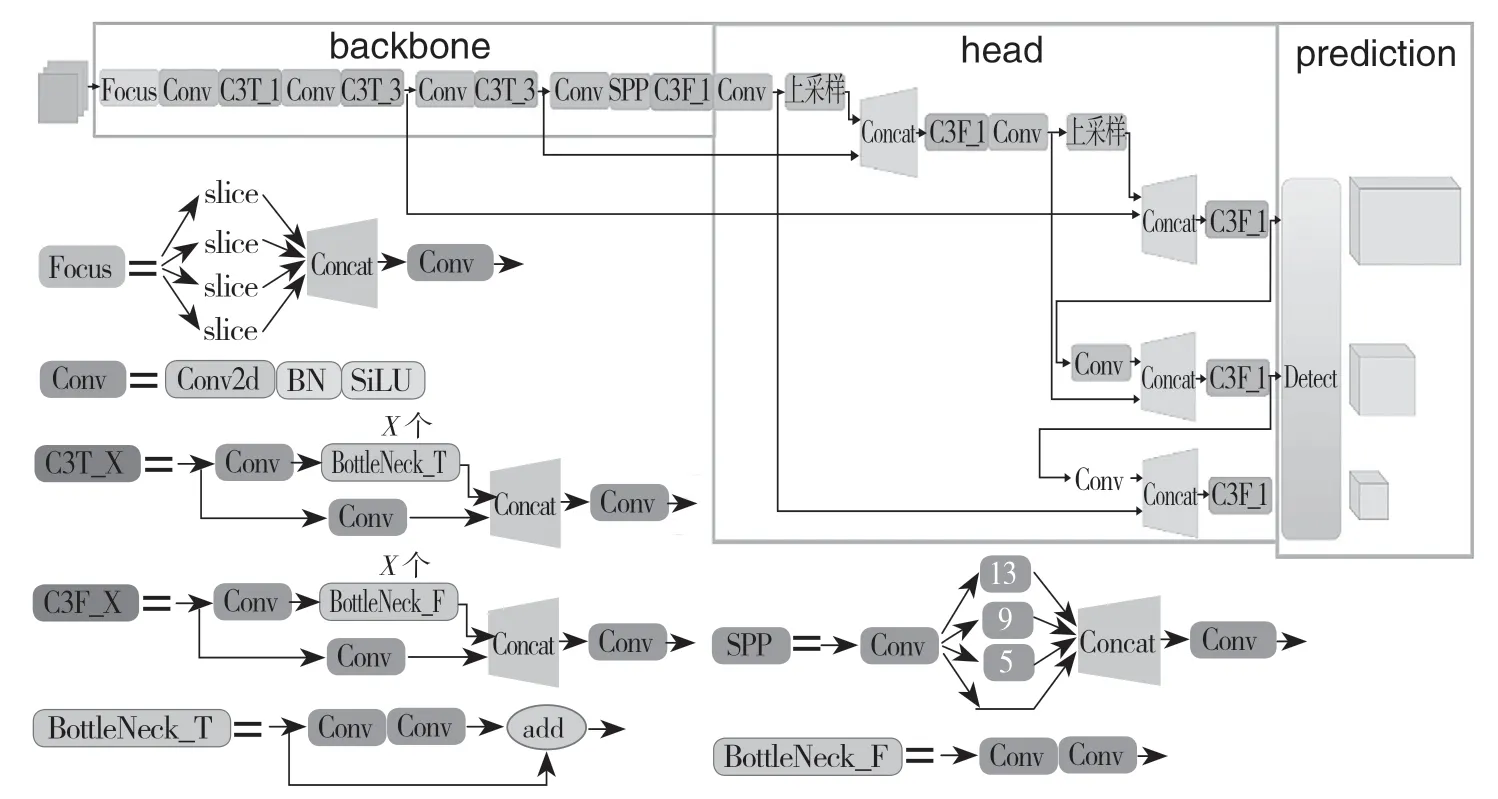
图1 YOLOv5s 结构图Fig.1 YOLOv5s structure diagram
2 改进网络结构
2.1 SENet 注意力模块
SE 模块全名为Squeeze-and-Excitation block,主要由4 部分组成:转换操作(Ftr)、挤压操作(Fsq)、激励操作(Fex)和比例操作(Fscale)。基于注意力机制的SE 模块原理图如图2 所示,SE 模块具体实现图如图3 所示。转换操作是一个常规卷积过程,经过转换操作后得到一个三维矩阵,对应图2 中的Ftr 操作。挤压操作对应图2 中的Fsq 操作,其使C 个特征图最后变成1×1×C 的实数数列,图3 中Global pooling 区域就是挤压操作。激励操作对应图3 中方框区域,用来全面捕获通道依赖性。比例操作对应图2 中的Fscale,相当于把输入特征图的每一通道中的每个值都乘以一个权重值,从而得到一个对于不同通道具有不同关注度的特征图。

图2 SE 模块原理图Fig.2 Schematic diagram of SE module

图3 SE 模块具体实现图Fig.3 Concrete implementation of SE module
2.2 基于SENet 注意力模块的C3 模块改进
原C3 模块主要针对特征图进行卷积(Convolution)、堆叠(Concat)、相加(add)操作。卷积是对特征图空间维度的变换,堆叠是对特征图通道维度的增加,相加是特征图对应通道的像素值的相加,相加属于一种信息融合。这些操作都忽视了对特征图不同通道维度的关注,而SENet 注意力机制重点解决的就是对特征图不同通道的不同关注度,SENet 的应用增强了特征图有效通道的权重,减小了无效或效果差的特征图通道的权重,因而SEC3 具有更强的特征提取能力。
将SENet 添加到BottleNeck 中的2 个Conv 模块中间,就形成了SEBottleNeck,将SEBottleNeck放入原C3 中BottleNeck 的位置,就形成了SEC3 模块。用SEC3 模块代替YOLOv5s 中的backbone 部分的C3 模块,将得到的新网络命名为S-YOLOv5s,其结构简图如图4 所示。

图4 S-YOLOv5s 结构图Fig.4 S tructure diagram of S-YOLOv5s
2.3 卷积注意力模块
Convolutional Block Attention Module(CBAM)表示卷积模块的注意力机制模块,CBAM 由一个通道注意力模块和一个空间注意力模块组成,如图5 所示。

图5 CBAM 结构图Fig.5 CBAM structure diagram
先对输入特征分别进行一个空间维度的全局平均池化和最大池化,再将其分别送入一个2 层的神经网络中,此时得到的2个特征相加后,经过一个Sigmoid 函数,就得到了通道注意力权值。通道注意力模块(CAM)结构如图6 所示。

图6 CAM 结构图Fig.6 CAM structure diagram
从通道注意力模块来的特征图,先分别进行一个通道维度的平均池化和最大池化,并将所得的2 层在通道维度上拼接,送入一个7×7 的卷积层,经Sigmoid 函数处理后,就得到了空间注意力权值。空间注意力模块(SAM)结构如图7 所示。

图7 SAM 结构图Fig.7 SAM structure diagram
将S-YOLOv5s 模型删减一半卷积核后,模型的精度虽降到了92.0%,但模型的大小降到了3.98 M,只有原来的28.03%,相较于模型体积的大幅下降,模型精度的下降是可以接受的。为补偿模型精度下降,选择将CBAM 模块融合进S-YOLOv5s 以提升精度。CBAM 注意力模块具有关注特征图空间维度的特性,而模型head 部分中的后3 个C3 模块负责预测不同维度特征图中物体的具体位置,位置本身是一种空间信息,因此,本研究将CBAM 融合进head 的后3 个C3 模块中,形成C3CBAM模块。融合了CBAM模块后,将模型命名为SC-YOLOv5s。SC-YOLOv5s 模型结构如图8 所示。

图8 SC-YOLOv5s 结构Fig.8 SC-YOLOv5s structure
3 模型轻量化和加速推理过程
3.1 模型轻量化及效果分析
YOLOv5s 模型训练结果如图9 所示,在没有添加任何模块和优化的前提下,YOLOv5s 的精度达到了93.6%,说明YOLOv5s 模型本身的特征提取能力非常强。在仅训练50 个epoch 时,就达到了90%的精度,说明该模型对交通标志检测任务有很高的适用性。因此,本研究在保持S-YOLOv5s中各小模块各自结构和功能完整的前提下,削减各模块中卷积核的个数至原来的一半,大幅削减模型的参数量,以达到模型轻量化的目的。采用这一策略后的实验结果证明其可行,轻量化后的模型训练结果如图10 所示。在100 个epoch 时,mAP 就达到了90%的精度,说明该轻量化模型的收敛速度还是非常快的;训练结束时,该模型精度达到了92.0%,相较于原始精度94.6%,只有略微下降,但模型大小却从14.2 M 降低到了3.98 M,说明这次轻量化是非常有效的。

图9 YOLOV5s 训练图Fig.9 YOLOv5s training chart

图10 轻量化模型训Fig.10 Lightweight model training
从图9 和图10 的对比可以看出,轻量化模型相较于原模型的一个较大不足是,达到最高精度所需要的训练次数明显上升。原模型训练到120 个epoch 时,基本就能达到最高精度,后续训练精度不再上升,且会有微小的下降。
而轻量化模型在达到90%训练精度以前所需epoch 数是原模型的2 倍,且90%精度以后的训练提升极其缓慢,由图10 可见,曲线一直有一种微微向上的趋势,但增长极慢。训练到260个epoch时,基本达到其最高精度,即使后续接着训练,精度也不再提升。
3.2 基于TensorRT 加速模型推理过程
TensorRT 是英伟达官方推出的一个高性能深度学习推理优化器,能够为深度学习模型提供低延迟、高吞吐率的部署推理。Jetson nano B01 是英伟达官方推出的嵌入式开发板,深度学习模型运用TensorRT 技术部署在该开发板上,可以使得深度学习模型的推理速度明显加快。
先将SC-YOLOv5s 模型训练后所得到的.pt 文件转化为.wts文件,然后在Jetson nano上执行编译操作,此时会生成一个YOLOv5 文件,再利用YOLOv5 文件将.wts 文件转化为.engine 文件,利用这个.engine文件,执行反序列化操作就可以将模型运行起来。至此,模型就成功部署在Jetson nano B01 上了。
4 实验结果及分析
4.1 实验数据集
本次研究使用的是腾讯公司和清华大学合作制作的交通标志数据集TT100K,该数据集中含有训练图片6 105 张,测试图片3 071 张,交通标志种类45 个。由于训练图片偏少,本实验先将训练图片和测试图片混合成一个数据集,再将其打乱分割。在混合中发现训练集和测试集有6 张图片重复,将其去除,得到9 170 张图片;再将其分割,得到训练图片7 256 张,验证图片957 张,测试图片957 张。
4.2 实验环境及评价指标
本研究训练过程是在Ubuntu18.04 操作系统下完成的,GPU 为A4000 显卡,CUDA 版本为11.1,Pytorch 版本为1.8.1,python 版本为3.8。本研究设置的初始学习率为0.01,优化器为SGD,学习率采用余弦退火函数,在训练的初始阶段采用训练预热方式,减少震荡,使模型收敛速度更快。
本次研究采用mAP评估模型的准确率,采用FPS评估模型的识别速度。mAP为各类别AP的平均值,一般以P-R曲线所围成的面积的平均值计算,mAP越大说明网络识别物体的准确度越高。FPS为每秒识别的图片数,FPS值越大说明网络处理图片的速度越快。计算公式分别为
式中:R(Recall)——召回率;P(Precision)——准确率;AP——单个类别的PR曲线的面积;c——类别个数;TP——正类数预测为正类数的个数;FP——负类数预测为正类数的个数;FN——正类数预测为负类数的个数;TN——负类数预测为负类数的个数。
4.3 实验结果分析
在模型轻量化之前,改进S-YOLOv5s 算法的mAP达到94.6%,与原YOLOv5s 算法相比提升了1%,说明改进的SEC3 模块相较原始C3 模块具有更强的特征提取能力。从图11 可以看出,在整个训练过程中,改进的S-YOLOv5s 模型的曲线都是在原模型之上的,说明S-YOLOv5s 模型相较原YOLOv5s 模型有一定的优越性。

图11 4 模型训练结果对比图Fig.11 Comparison of training results of four models
在模型轻量化之后,由图11 可知,轻量S-YOLOv5s 模型的mAP为92.0%,融合了CBAM而形成的SC-YOLOv5s 模型的mAP为92.9%,模型有0.9%的精度提升;在100 个epoch 以前,轻量S-YOLOv5s 模型的训练精度略高于SC-YOLOv5s,但100 个epoch 以后,SC-YOLOv5s 模型的精度就超过了S-YOLOv5s。
在YOLOv5s 模型逐渐改进过程中,共产生4个模型,按改进顺序排序:YOLOv5s →S-YOLOv5s→轻量S-YOLOv5s → SC-YOLOv5s。
从表1 可知,在经过一系列改进和优化后,相较于YOLOv5s 模型,SC-YOLOv5s 模型的体积减小了71.7%,但mAP@0.5 仅仅下降了0.7%,说明本次研究对YOLOv5s 模型的改进和优化是成功的。

表1 4 模型对比Tab.1 Comparison of four models
与其他算法的对比结果如表2 所示,在公开数据集TT100K 上,本文改进算法的体积、平均精度和检测速度全部优于YOLOv3 和YOLOv4-Tiny,只有平均精度比YOLOv4 低1.2%,但体积和检测速度方面本文改进算法远远优于YOLOv4,体积只有YOLOv4 的1.6%,检测速度则是YOLOv4 的26.8 倍。综合各项指标,本文算法远优于其他算法。

表2 与其他算法对比Tab.2 Comparison with other algorithms
4.4 识别结果
从图12 和图13 可看出,YOLOv5s 和SCYOLOv5s 都能以很高精度正确检测出交通标志。原YOLOv5s 模型部署到Jetson nano 上,同样采用TensorRT 技术加速推理,得到的结果是平均每张图片的推理速度为75.76 ms,也就是FPS=13.2;而改进的YOLOv5s 模型运用TensorRT 技术部署到Jetson nano上,平均每张图片的推理速度为41.49 ms,即FPS=24.1。改进模型的速度是原模型的1.83 倍,而mAP仅仅下降了0.7%,且FPS达到了24.1,完全满足了交通标志实时检测的需要。

图12 YOLOv5s 检测效果图Fig.12 YOLOv5s detection rendering

图13 SC-YOLOv5s 检测效果图Fig.13 SC-YOLOv5s detection rendering
5 结论
快速检测交通标志和嵌入式部署是实现智能驾驶的基础条件。本研究在YOLOv5s 模型的基础上提出了一种交通标志检测的轻量算法,该算法有助于对交通标志的更高精度、更快速度的检测。
(1)首先,对YOLOv5 模型进行了分析,选择YOLOv5s 模型作为基础模型;然后通过注意力机制SENet 对YOLOV5s 的backbone 部分的C3 模块进行改进,提升整个backbone 的特征提取能力;接着删减一半的卷积核,使模型轻量化;再将CBAM模块融合进模型head 部分的C3 模块,以弥补轻量化导致的精度降低;最后,运用TensorRT 技术将模型部署在Jetson nano 开发板,实现模型的真正应用。逐次改进过程中模型mAP@0.5 和体积变化:YOLOv5s(93.6%,14.12 MB)→S-YOLOv5s(94.6%,14.23 MB)→轻量S-YOLOv5s(92.0%,3.98 MB)→SC-YOLOv5s(92.9%,3.99 MB)。
(2)在TT100K 数据集上的实验结果表明,本文的轻量化交通标志检测模型体积小,精度达到了92.9%,FPS达到了24.1,能满足实时交通标志检测的要求。还可以应用更好的池化方法提高精度,通过量化使模型速度得到进一步提高,更好地实现实时交通标志检测。
