三种机器学习方法在广东雷暴大风自动识别的应用效果评估
2023-10-27兰宇罗聪伍志方唐思瑜吴林程兴国陈蝶聪
兰宇,罗聪,伍志方,唐思瑜,吴林,程兴国,陈蝶聪
(1. 广东省气象台(南海海洋气象预报中心),广东 广州 510641;2. 中国气象局龙卷风重点开放实验室,广东 广州 510641;3. 华南理工大学,广东 广州 510641;4. 广东省生态气象中心,广东 广州 510641)
1 引言
雷暴大风是强烈的大气对流现象,常造成较大范围的严重影响[1]。广东一年四季都可发生雷暴大风。粤北、两广交界的山区及沿海一带均是雷暴大风多发区,尤其人口稠密的珠江三角洲地区是受影响极重的区域。雷暴大风具有生消快、移速快、易致灾等特点,对人类威胁极大。因此深入研究雷暴大风的识别预报和提升短临预警能力是十分紧要的。
新一代天气雷达观测是雷暴大风监测和临近预警的主要手段,对雷暴大风的临近预报预警主要基于雷达回波特征。俞小鼎等[2-3]指出低层大风区(≥13 m/s)、弓形回波、近地层辐散、中气旋对雷暴大风具有较好的指示作用。伍志方等[4]研究发现80%的雷暴大风包括下击暴流在多普勒速度图上表现为大风区型和近地层辐散型,还有较少比例的中气旋型大风。此外,雷暴大风在反射率因子强度及高度、回波移速、垂直累积液态水含量等特征与强降水的雷达特征差异明显[5-6]。
近年来,机器学习方法在分类识别、雷达回波外推等气象领域取得了很好的应用效果,其中传统机器学习方法在人工选取特征的基础上,能在数据量较小的场景下建立模型。早在2014 年,李国翠等[7]通过统计多个雷达特征指标,利用模糊逻辑算法建立了基于多因子的雷暴大风自动识别算法,周康辉等[8]在此基础上通过增加闪电、卫星资料来有效识别雷暴大风。此外,国内外学者也相继使用决策树、支持向量机等传统机器学习方法开展冰雹和雷暴大风的自动识别研究[9-11]。
随着观测资料不断丰富、计算机性能持续优化,以深度学习为代表的人工智能方法在气象上应用逐渐增多。深度学习省略了传统机器学习方法中人为选取特征的过程,基于海量数据基础上,通过多隐层的层次结构式神经网络进行训练,深度挖掘特征,从而构建出性能好的学习模型。香港科技大学的学者率先提出卷积长短期记忆单元网络算法(ConvLSTM)优于普通的光流法外推预报[12],Wang 等[13-15]先 后 提 出 PredRNN、PredRNN++、MIM 等算法用于临近预报均有较好效果。陈元昭等[16]研究发现基于生成对抗网络的临近预报方法对于中等强度回波预报效果较好,顾建峰等[17]运用Traj-GRU建立强对流雷达回波预报模型,并利用U-net建立了雷暴大风和冰雹的智能识别模型。由此看来,目前在气象领域中,深度学习方法多应用于短临外推预报,雷暴大风智能识别方面研究尚较少,华南地区相应研究有待进一步深入开展。
因此,本文分别选取传统机器学习方法(决策树)和深度学习方法(CNN 和YOLO)等3 种方法,利用广东省地面自动站所观测的雷暴大风记录及相对应的雷达拼图数据,分别建立3种雷暴大风自动识别模型,并针对3 种模型开展检验评估,以对比传统机器学习和深度学习方法在广东雷暴大风识别上的应用效果,确立最优识别模型并最终实现识别算法的业务化运行,为建设广东雷暴大风实时监测体系、提高预警预报的准确率、提升预警提前量提供技术和产品支撑。
2 数据与方法
2.1 数据资料
选取广东省2012—2020年全年雷暴大风天气过程中自动气象站5 min加密瞬时风观测数据,及对应的广东省反射率因子、组合反射率因子、回波顶高、垂直累积液态水含量等雷达拼图数据,拼图数据为广东省气象局业务化应用拼图,已经过杂波抑制、孤立噪声过滤、中值滤波和双线性插值填补等数据质量控制,数据来源于广东省11 部S 波段天气雷达数据。拼图数据空间分辨率为1 km×1 km,格点数为1 050×880,时间分辨率6 min,垂直方向共21层。
雷暴大风自动站观测实况的筛选条件为:自动站观测瞬时风速≥17.2 m/s(下文中大风均代表风力达到8 级以上),同时周围10 km 范围内存在雷电活动及反射率因子大于30 dBZ,并剔除了站点海拔高于200 m、海上浮标站及强冷空气过程、台风直接影响等引起的大风记录。由于相比一般性天气而言,雷暴大风观测记录较少,在广东全省范围内属小概率事件,雷暴大风正、负样本比例需适宜,以避免出现样本失衡和数据偏差,兼顾模型运行所耗计算资源、训练效率和识别效果,最终挑选了17 470个大风正样本和34 950个无大风负样本,正、负样本比例为1∶2。(注:一次雷暴大风观测记录(即符合雷暴大风判定条件的观测数据)记为一个正样本,反之则作为负样本。)
2.2 标签集制作
读取雷暴大风观测数据中的经纬度,将其转换成以拼图左上角为起始点,右下角为结束点的图像坐标系(图1)中的坐标,考虑到自动站观测范围代表性,制作标签时设定雷暴大风影响范围为16 km,在此条件下,获得如(Xt,Yt,16,16)的标签,其中(Xt,Yt)为该雷暴大风记录点在新坐标系中的横纵坐标,(16,16)为雷暴大风的矩形影响范围;将与出现雷暴大风对应时刻(或相邻最近时刻)的各类拼图数据转换为图像产品并标记为class,最终得到用于机器学习模型的标签集(class,Xt,Yt,16,16),按照一定比例随机选取将标签集分为训练集、验证集和测试集。

图1 用于机器学习的雷暴大风标签集制作
2.3 训练与检验
本文共采用2012—2019 年共52 420 个数据集,并按照7∶2∶1 比例划分为训练集、验证集和测试集用于算法建模,其中训练集用于训练模型,验证集用于模型参数调整和优化,测试集不参与特征选取、参数调整等训练,只用于测试模型对雷暴大风的识别能力。通过训练、验证和调参不断循环使识别模型达到最优识别效果后,模型参数方案即最终确立不再更改,后续的检验评估均沿用此方案。鉴于雷暴大风的小概率事件特性,而日常预报预警业务中针对其高致灾性常采用宁空勿漏的防御策略,因此在本文中训练和评价模型能力同时采用了命中率POD、虚警率FAR 以及临界成功指数CSI 作为训练和评价指标进行定量检验[18],旨在避免漏报的情形下尽量减少空报,提高命中。
本文中,命中并非时间和空间严格点对点,而是根据自动站观测间隔,T时刻算法识别到大风落在[T-5 min,T+5 min]时间窗内、真实实况大风标签16 km×16 km 范围内即记为命中,算法识别到大风但未落在相应范围内或无大风实况则记为空报,存在大风实况而无识别结果相对应则记为大风漏报。命中率POD、虚警率FAR、临界成功指数CSI的计算公式如下:
说明:NA 为命中数,NB 为空报数,NC 为漏报数。
3 模型介绍
3.1 决策树模型
3.1.1 决策树模型结构
决策树(Decision Tree)是一种基本的分类与回归方法,决策树模型呈树形结构,在分类中表示基于特征对实例进行分类的过程[19]。其主要优点是:模型具有可读性,分类速度快。学习时利用训练数据,根据损失函数最小化原则建立决策树模型。决策树学习通常包括三个步骤:特征选择、决策树的生成、决策树的修剪(图2)。
图2 决策树模型结构示意图
决策树由结点和有向边组成,决策树模型构建过程:先构建根结点,将所有训练数据都放在根结点。选择一个最优特征,按照这一特征将训练数据集分割成子集,使得各个子集有一个在当前条件下最好的分类。如果这些子集已经能够被基本正确分类,那么构建叶结点,并将这些子集分配到对应的叶结点中去;如果还有子集不能够被基本正确分类,那么对这些子集选择最优特征,继续对其进行分割,构建相应的结点。如此递归下去,直至所有训练数据子集被基本正确分类或者没有合适的特征为止。最后每个子集都被分到叶结点上,即都有了明确的类,从而生成了一棵决策树。
3.1.2 特征因子选取
通过结合以往的雷暴大风特征研究以及预报员日常值班中经验总结,归纳总结了以下对雷暴大风识别预警具有指示意义的特征因子,用于建立决策树模型。
(1) 组合反射率因子强度。该因子是雷达一个体扫中不同高度反射率因子的最大值。有研究发现回波中心强度低于55 dBZ 时,出现大风的概率很小[20];周康辉等[8]通过统计也发现,雷暴大风的反射率因子强度主要分布均超过30 dBZ,峰值分布于53 dBZ。因此,反射率因子强度对于雷暴大风具有很高指示意义。
(2) 反射率因子强度梯度。通常雷暴大风出现在雷达回波强且伴有强梯度的区域,尤其当回波形态上具有典型带状、弓状或者钩状特征时,地面大风多出现在强度梯度大值区域[21-22]。
(3) 垂直累积液态水含量(后文统称VIL)。该因子表示的是将反射率因子数据转换成等价的液态水值,并且假定反射率因子是完全由液态水反射得到的。有研究对雷暴大风出现前的VIL 进行统计发现,VIL值达到30 kg/m2是地面灾害大风出现的阈值,VIL值达到或超过40 kg/m2可以作为地面灾害大风的一个预报指标;且VIL 值快速下降也常表征雷暴大风的出现[23]。
(4) 回波顶高。已有学者在多个雷暴大风个例的回波特征研究中发现雷暴大风通常与较高回波顶高相对应[24]。李国翠等[7]统计结果表明雷暴大风与回波顶高具有较好的正相关关系,可以用作雷暴大风识别的一个特征因子。
(5) 50 dBZ 高度。华南短时强降水多暖云降水,其回波中心高度常常位于0 ℃层高度附近或以下,而产生雷暴大风的雷暴体对流往往发展更为旺盛,强回波垂直伸展高度可达-20 ℃层以上,在华南地区-20 ℃层常高于7 km[25]。与此同时,当反射率因子强度低于50 dBZ 时雷暴大风出现概率较低,因此,可选取50 dBZ 回波出现的高度作为雷暴大风的特征因子用于识别[26]。
考虑到雷达特征因子与地面雷暴大风的出现时刻并非完全严格对应,且部分雷达特征随时间推移的强度、位置变化更能表征雷暴大风,因此除提取上述因子T时刻特征值外,还提取了ΔT(T-6 min,T+6 min)在12 min 内的变化值共10 个因子用于模型建立。
3.2 CNN模型
卷积神经网络(CNN),是一种包含卷积计算且具有深度结构的神经网络,是深度学习的代表算法之一,可以进行监督学习和非监督学习,是分类识别主流模型之一[27],在本文中应用此模型进行监督学习。CNN的原理为通过一个特定的滤波器,不断与图片做卷积来提取特征,从局部特征到总体特征,从而实现图像识别的功能。其整体结构包含3 种层(layer)。第一层为卷积层(CONV),由滤波器和激活函数构成,涉及到滤波器数量、大小、补偿等超参数。第二层为池化层(POOL),亦称下采样或欠采样,其功能为特征降维,压缩数据和参数数量,减少过拟合同时提高模型的容错率。第三层为全连接层(FC),亦称输出层,全连接层为多个神经元单元排列连接组成,其功能为观察上一层的输出并确定所提取的特征与目标分类的吻合度,并得到模型识别输出[28],模型结构如图3所示。

图3 CNN卷积神经网络层级结构示意图
3.3 YOLO模型
YOLO(You only look once)是一种目标检测模型,用来在一张图片中寻找某些特定目标物体,不需要预先提取候选区域,通过一个网络就可以输出目标类别、置信度和坐标位置[29]。YOLOv3是YOLO 算法中的第三版,相比于之前的算法,识别精度有所提升[30]。YOLOv3 是一个庞大且丰富的深度卷积神经网络模型,一共有53 个全连接卷积层,因此又称为Darknet-53[31](图4)。
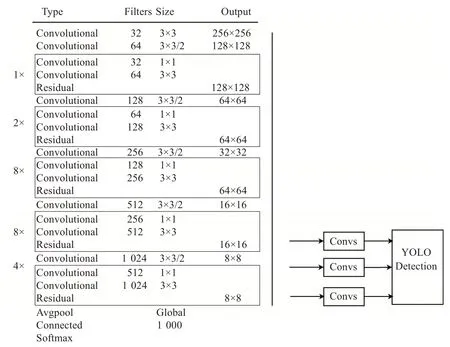
图4 YOLOv3网络结构图
模型首先将输入图片统一缩放至416×416 像素,将照片分割为N个大小相等的网格,并对每个网格中的物体进行识别。包括识别物的中心位置(x,y)、识别的置信度及识别物的类别。置信度即为模型识别物体为目标物的自信程度,置信度越高,意味着模型检测越严格,对于识别结果也越自信。YOLO 模型可以输出不同置信度下目标识别结果,本文中所有YOLO 模型的输出结果均是置信度为0.7时的识别结果。
相较于YOLO的v1、v2版本,YOLOv3版拥有3 个特征尺度,即可以同时使用3 个特征层分别进行卷积和预测识别,这意味着模型可以允许同时输入3 张不同高度的雷达回波进行识别。为了使YOLOv3 更好描述雷暴大风的空间结构特征,本文在实际模型训练时,对原版YOLOv3(后文统一简称YOLO)的网络进行改进,将其特征尺度层扩展到11 层,即允许同时将11 层不同高度的雷达拼图作为输入层,从而可以更详细地反演雷暴大风的空间结构特征供模型提取和学习。本文即将1~9 km 高度(高度分别分为1、2、3、4、5、6、7、7.5、8、8.5、9 km)共11 层的雷达拼图作为输入层,用于模型检测识别对YOLOv3 进行训练优化,形成YOLOv3版雷暴大风识别模型。
4 模型算法检验分析
4.1 三种模型算法的检验对比分析
4.1.1 批量检验分析
为验证三种模型算法的识别效果,利用测试集(共5 242 个样本)分别对3 个模型进行批量识别测试,测试结果如表1 所示。结果表明:决策树模型的命中率高于CNN,略低于YOLO,但虚警率偏高,为3个模型中最高达到0.57,即空报偏多,导致CSI低于CNN 和YOLO;3 个模型中YOLO 的表现最为优异,POD 和CSI分别为0.994、0.685,均为最高,且CSI 明显高于其他两个模型,表明YOLO 模型相较于另外两种模型有更好的识别能力。

表1 三种模型识别效果批量测试对比
4.1.2 飑线个例检验分析
2016年4月12日夜间受高空槽配合低涡切变线、低空西南急流影响,华南地区出现了一次大范围飑线过程,伴随着雷暴大风、短时强降水等强对流天气,对流回波于12日20时(北京时间,下同)开始自广西境内逐渐东移南压,东移过程中回波逐渐高度组织化,13 日03 时左右东移至两广交界时发展为东北西南走向的飑线,进入广东境内后回波发展旺盛,移速加快达到100 km/h以上,并逐渐形成弓状,弓形回波主要影响肇庆、佛山、广州、东莞一带,造成上述地区10级以上雷暴大风天气,大风主要出现在弓形回波附近,弓状回波凸起经过的区域多个站次监测到12 级以上大风,经筛选4月13 日04—06 时共取得符合标准的大风观测记录214个。
将4月13日04—06时相应的雷达回波作为输入层同时运行3个模型进行识别,并对识别结果进行检验评估(表2)。整体来看个例检验结果与批量测试结果类似,3个模型中YOLO对于此次飑线过程大风的识别效果最好,POD 和CSI 均最高,FAR 最低,分别为0.981、0.667 和0.325,且YOLO模型的CSI 较其他两个模型提升较明显;决策树的POD 略高于CNN,但CSI 更低,这主要因为决策树模型的识别偏差来源于更多的空报。

表2 2016年4月13日飑线型雷暴大风天气过程识别评估结果
4.1.3 混合对流个例检验分析
2019年3月2—3日,华南地区有高空槽过境,配合低层850 hPa的切变线和西南急流,广东自北向南自西向东出现了一次雷暴大风、伴随着短时强降水等强对流的天气过程。2 日夜间(2 日23 时—3 日02 时)系统主要影响广东北部的韶关、清远等地区,对流回波在移动过程逐渐密实呈现块状,反射率因子最强达60 dBZ,移入韶关中部后组织为线状对流并呈弓形,移速加快,引起韶关地区降水有所减弱但雷暴大风明显增强,整个过程中韶关、清远出现了8~9级雷暴大风,其中韶关乳源国家气象站观测到27.2 m/s(10 级)的大风,经筛选3月2 日23 时—3 日02 时共取得大风观测记录28个。
将3 个模型对此次过程的识别结果进行检验评估(表3)。对比来看,3 个模型在本次过程中的表现与4.1.2 节的个例(简称个例一)类似,YOLO模型识别效果最好,POD 和CSI 均最高,且其漏报数为0;决策树同样表现出比CNN 模型更高的POD 和更低的CSI。值得注意的是,相较于个例一的飑线过程,此次过程中3个模型均表现出更高的空报,造成空报增加的原因主要有两个:一方面相比于本次由多单体风暴引起的大风和强降水混合过程,个例一为典型弓形飑线过程,具有更鲜明的雷暴大风特征,更易于捕捉识别;另一方面,个例一发生在全广东气象自动站分布最密集的珠三角,而本次过程发生在北部高海拔山区,气象自动站分布相对稀疏,且部分气象站观测记录因海拔高达300~400 m 以上而被剔除,使得实际出现了大风但未被观测到或因海拔太高不符合标准被剔除的情况出现。

表3 2019年3月2日雷暴大风、强降水混合天气过程识别评估结果
4.2 YOLO模型算法检验分析
通过对3 个模型识别能力测试对比发现,YOLO 模型识别能力最好,确立为最优模型。进而选取广东省2020 年3—8 月的雷暴大风过程,依据天气形势划分为局地性雷暴大风过程、系统性雷暴大风过程两类分别对该最优模型进行检验评估,本文定义局地性雷暴大风为无明显天气系统存在的弱天气尺度强迫条件下产生的天气过程,如副高边缘不稳定区、夏季午后中尺度辐合线触发热对流等。系统性过程则为高低空有天气系统配合、存在较强天气尺度强迫的强垂直不稳定条件下产生的天气过程,如高空槽、切变线过境影响等。
检验同样采用POD、FAR和CSI等3个指标进行评估,其中用于检验的自动站实况观测记录采用前文2.1 节所述的筛选条件得到。基于后续将算法投入业务化使用的需求,本文增加了最长达30 天连续时间段内任意天气的识别检验,以测试该模型算法业务化识别能力。
4.2.1 分类个例分析
4.2.1.1 局地性雷暴大风过程识别分析
2020年7月14日菲律宾以东洋面有热带扰动发展并西移进入南海,此时500 hPa副热带高压偏强偏北,广东东部位于副热带高压南部边缘不稳定区内,午后热力作用和地面辐合线触发引起了局地强雷暴发展,多个雷暴单体于福建南部生成并逐渐向西南移动,初始回波较松散,移动过程中逐渐加强合并为多单体风暴,回波渐呈现为密实块状,反射率因子最强达60 dBZ。受此影响,粤东地区夜间20—21 时出现了8~9 级雷暴大风,最大达10 级(26.7 m/s),此次过程自动站共录得大风20站次。
对于此次局地性过程YOLO 算法识别效果较好(图5),过程出现的所有8级以上大风均能识别,无一漏报;但同时存在2 站次空报,其中有一个站次识别结果对应了瞬时风6 级风实况,其POD、FAR和CSI分别为1.000、0.091和0.909。
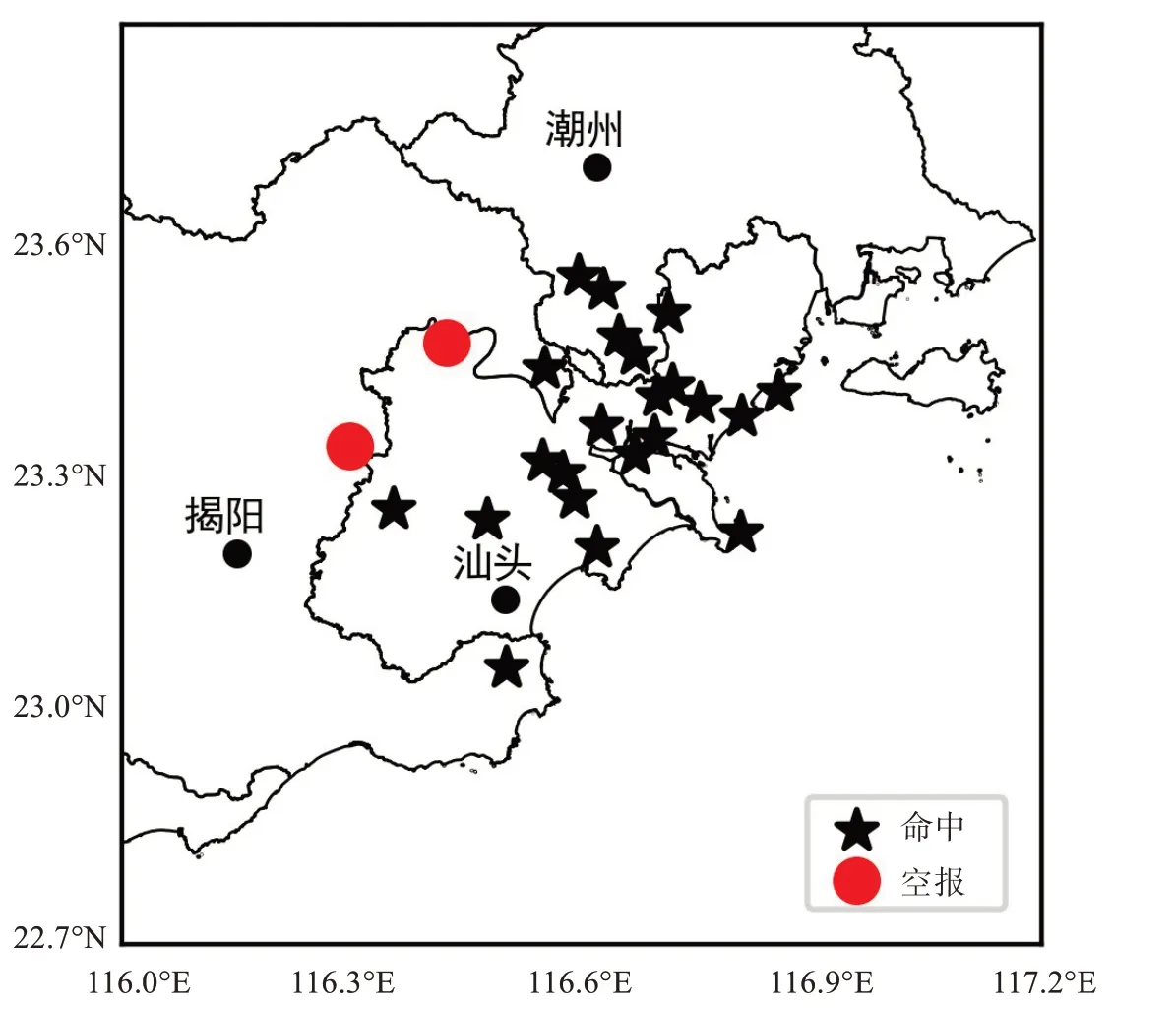
图5 2020年7月14日20—21时实况大风与算法识别结果分布情况
4.2.1.2 系统性雷暴大风过程识别分析
受高空槽、低空切变线和低空急流共同影响,2020年6月5—9日华南地区出现了一次“龙舟水”过程,雨势强烈并伴随8~9 级雷暴大风。9 日13时前后强对流回波主体位于广东西北部一带,南部有零散对流单体发展,反射率因子强度40~50 dBZ,随着东北移,其南部回波明显加强并逐渐组织为短弓形线状强回波,反射率因子最强达60 dBZ,弓形回波主要影响珠三角的西部和北部。受此影响,15—17 时珠三角多个市县录得8~9 级瞬时大风,此次过程经筛选共取得大风17 站次。YOLO 模型算法对于此次过程出现的所有大风均成功识别,无漏报情况(图6),但相比于7 月14 日过程的识别结果,本次过程的虚警站次有所增加,共有7 站次的虚警,究其原因主要为两方面:一方面本过程发生在华南“龙舟水”期间,伴随着局地小时雨量50~60 mm 的短时强降水,雷达特征更加复杂,识别难度相对更高;另一方面,虚警识别主要出现在清远和广州交界的山区,自动站分布相对稀疏,海拔也较高,部分观测站点海拔达800 m以上。

图6 2020年6月9日15—17时实况大风与算法识别结果分布情况
4.2.2 分类批量检验
4.2.2.1 局地性过程批量检验
选取广东省2020 年7 月5 次局地性雷暴大风过程共71 个大风样本进行识别检验,5 次天气过程均由于处在副热带高压边缘不稳定区,配合低层南风和充足的不稳定能量而引起。将上述过程相应高度的雷达回波拼图输入识别模型,得到相应的识别结果并对其进行检验评估,结果表明:YOLO 算法对于局地性雷暴大风过程的大风识别命中率为0.958,相较于测试集结果略有下降(表4)。

表4 基于YOLO的识别模型对于局地性天气过程识别能力的评估
4.2.2.2 系统性过程批量检验
选取广东省2020 年3 月和6 月共5 次系统性天气过程,其中包含2 次飑线过程,共148 个大风样本进行识别检验。5 次天气过程主要由高空槽过境配合低层切变线影响广东地区而出现了雷暴大风天气。检验评估表明:相比局地性过程,识别算法对于系统性雷暴大风过程的识别效果略有提升,命中率达0.986,虚警率亦有下降,CSI 较局地性过程提高了0.06(表4);对比测试集的检验结果,该模型算法的识别能力略有下降,说明本算法模型仍存在一定过拟合现象。
4.2.3 YOLO模型算法的业务应用评估
基于识别算法业务化的需要,选取2020 年5月全月(广东前汛期)和8月全月(广东后汛期)两个长连续时间段进行自动识别检验,两个时间段涵盖了前汛期和后汛期两类环流形势下、不同环境条件引起的弱降水过程、强降水、雷暴大风和冰雹等强对流天气过程,共1 520个大风样本。
检验结果表明:基于YOLO 模型的识别算法在长达30天连续时段内任意天气条件下的雷暴大风识别能力仍较高,其POD 和CSI分别为0.939 和0.601,尤其漏报比率低,具备投入业务化使用的条件(表5)。

表5 基于YOLO的识别模型在连续时段内识别能力的评估
4.3 识别算法实时运行效果评估
基于YOLO 模型的识别算法已于2021 年1 月接入实时雷达数据,并投入业务化试运行,可根据实时拼图每6 min 稳定更新识别结果。经收集筛选2021年全年符合条件的雷暴大风观测记录共有1 603 个,其中8~9 级有1 558 个,10 级及以上有45个。结合算法运行全年的识别结果进行评估分析(表6),在全年实时运行条件下,识别算法对于任意天气形势下产生的雷暴大风识别命中率仍超过90%,CSI 为0.629,与2020 年5 月和8 月全月运行的结果相比,识别效果略有波动,但波动较小,其中命中率略有下降,同时虚警率也下降,而CSI有所提升。

表6 2021年全年雷暴大风过程识别效果评估结果
5 结论与讨论
本文基于2012—2019年广东省的雷达拼图和加密自动气象站极大风观测数据,分别利用决策树、CNN 和YOLO 三种模型建立了雷暴大风自动识别算法,并利用相应测试集对三者的识别能力进行测试对比。测试结果表明:深度学习方法CNN 和YOLO 的POD、CSI 等指标均高于传统机器学习方法决策树模型,决策树模型存在空报较多情况。其中YOLO 识别能力最佳,其POD、FAR和CSI分别为0.994、0.308和0.685,为最优模型。
同时,针对YOLO 对不同天气类型下的雷暴大风识别能力测试及业务化的需求,分别选取了2020 年3—8 月不同类型天气过程以及连续时段任意天气进行识别检验分析,得到以下结论。
(1) 基于YOLO 模型的识别算法无论对局地性还是系统性雷暴大风过程的POD 均高于0.95,CSI 达到0.6 以上,FAR 低于0.4,表明该识别算法对于不同类型的雷暴大风均有较高的捕捉识别能力,且对于系统性雷暴大风的识别效果略优于局地性过程的。
(2) 基于YOLO 模型的识别算法在广东前汛期、后汛期形势连续30 天时间段内任意天气条件下,对雷暴大风的识别POD、FAR 和CSI 分别为0.939、0.374、0.601,表明该识别算法具备业务化条件。广东省气象台于2021 年1 月部署将该识别算法接入实时雷达数据,每6 min稳定生成广东省全省范围、1 km×1 km分辨率的识别产品。
(3) 需要注意的是,该算法虽命中率高,但仍存在一定的空报。这与广东省自动站分布不均匀有一定关系,粤北和粤西的山区自动站分布相对稀疏,却是雷暴大风的频发区,存在由于雷暴单体尺度小处于观测空白区而未被监测到的情况;同时检验中发现部分空报与6 级、7 级风观测实况对应,回看实况回波亦可见强反射率因子、强回波伸展高、高VIL等雷暴大风指示性特征。
(4) 相较于深度学习模型方法,本文中基于人为选取雷达特征的传统机器学习方法-决策树模型的识别算法表现出更多的漏报和明显的空报。这是因为传统机器学习方法非常依赖于人为选取的特征因子,需要通过更深入研究获取到更全面的雷暴大风雷达特征,从而对算法进行补漏消空。
此外,近地层辐散、大风速核、中层径向辐合等径向速度特征与雷暴大风密切相关,对于雷暴大风的监测识别具有明显优势,但利用单站雷达的径向速度产品来实现广东全省范围内上述速度特征的自动识别难度较大,有待于在后续的工作中进一步深入研究。
