面向朝鲜语命名实体识别的多粒度融合方法
2023-10-25黄政豪金光洙高君龙
黄政豪,金光洙,高君龙
(1. 延边大学 工学院,吉林 延吉 133002;2. 延边大学 朝汉文学院,吉林 延吉 133002)
0 引言
随着信息规模的不断扩大,从海量数据中提取高价值信息逐渐成为了研究热点,而命名实体识别(Named Entity Recognition, NER)是信息抽取常用技术之一,是自然语言处理中信息抽取过程不可或缺的基本任务。它的研究成果广泛应用于自然语言处理的各项子任务中,如文本理解、信息检索、自动摘要、自动问答、机器翻译等,对知识库建设有重要作用[1];这也是国内亟待发展的朝鲜语相关研究内容之一。
朝鲜语作为黏着语,不同语境下的命名实体和上下文之间的关系十分复杂。因为在朝鲜语中,具有实际意义的词干通常与具有语法意义的助词和词缀连接在一起,形成基本语义单位[2]。这些组合而成的语节再次通过空格(隔写)连接在一起,充当不同的句子成分来构建一个完整的句子[3]。因此,在进行命名实体识别任务时,无法直接将英语或汉语等语言所能够使用的方法迁移过来使用。其次,朝鲜语作为资源稀缺语言,能够用于研究的已标注语料库在规模上相较于英语和汉语等语言有明显的差异,这也是阻碍研究的重要原因之一[4]。
通常针对训练数据不足的问题,一般是持续通过人工标注的方式构建新的数据集来填补不足的部分。但这种方式对时间成本和人员专业程度要求过高,很难在短时间内从根本上解决问题。因此,目前更倾向于对已有的数据集进行增强的方式提高模型的性能。Lee等[5]在研究中发现不少研究者通过数据增强方式提高了英语命名实体识别任务的性能,在韩国的研究也是通过预先构建词典、词素和音节特征的融合等方法增强数据,从而提高模型性能。而目前大部分融合特征方法只是对特征向量进行拼接,缺点是容易丢失位置相关性和不同粒度之间的相关信息。
本文从朝鲜语语法和构成特点出发,研究在音素、音节和词素三种粒度下朝鲜语实体的有效表征,提出一种基于多粒度融合的朝鲜语命名实体识别方法。该方法并不是拼接特征向量,而是通过词素、音节和音素向量有效融合,确保以上三种粒度之间的位置关系和上下文关系保留下来,从而提高模型的性能。
1 相关工作
数据增强是一种通过人为操作对数据进行变换的过程。其目的是增加数据量,从而获得用于学习的新数据,特别是在研究所需的语料数量不足的情况下使用。在计算机视觉领域中,常用对原始数据进行裁剪、翻转、放大、旋转等变换的方法,以增加数据的多样性。通过这些过程,可以生成与原始数据相似甚至接近实际存在的新数据。利用这种增强技术生成的数据可以有效地提高模型的性能[6]。
然而,在自然语言处理领域中,即使是单词的微小变化,也有可能导致整个句子的含义产生明显差异,同时句子排列顺序的变换也可能导致语法错误。因此,选择数据增强的方法时必须非常谨慎,避免对模型训练造成负面影响。
朝鲜语中使用音节和组成音节的音素都包含不同的语法特征和上下文关系特征。同时,一个词汇被切分为音节或者音素都不会影响到原有语义,因此,常用于自然语言处理任务的数据增强过程中。Kim等[7]提出了使用音节分布模式作为深度学习输入的形态分析方法,所提出的音节分布模式包括音素嵌入向量和词素音节分布模式。Na等[8]针对韩语NER任务提出了一个基于字符表示的双向LSTM-CRF方法,其中使用了基于音节向量的LSTM-ConvNet混合表示方法。Oh等[9]提出基于音节特征的命名实体识别方法,用于宠物疾病问答系统。同时,为了增加数据规模,使用相似病例数据扩充了数据集以提高模型性能。
在命名实体抽取建模方法上,早期在深度学习普及之前,大多数命名实体识别任务主要围绕传统机器学习方法展开,主要包含基于隐马尔科夫模型(Hidden Markov Model,HMM)的命名实体识别方法[10],基于支持向量机(Support Vector Machine,SVM)的方法[11],最大熵模型(Maximum Entropy Model,MaxEnt)与词典匹配和规则相结合的方法[12]。传统机器学习方法对词典和语料库特征标注要求很高,利用这些规则集可以更高效地匹配相似领域语料中的命名实体,但构建规则集本身需要的人工和时间成本较高,同时跨领域可移植性较差。
随着近几年深度学习的发展,最早由Huang等人[13]提出Bi-LSTM-CRF模型,提升了命名实体识别精度,在CONLL2000和CONLL2003语料集上F1值达到了94.46%和88.83%。Yao等[14]提出一种基于CNN的生物医学命名实体识别模型,使用skip-gram神经网络结构实现医学文献中稀有实体的识别训练。Chiu等[15]使用LSTM和CNN架构自动检测字和字符级特征,该模型在CONLL2003数据集上获得了91.62%的F1值。Kwon等[16]使用音节级别的Bi-LSTM进行编码,再通过将双字音节作为额外编码,最后通过Bi-LSTM-CRF模型完成NER标记。
2017年,Transformer 模型由 Vaswani 等[17]提出,强大的注意力机制可以捕捉到长距离的依赖关系,并且能够进行并行运算,明显优于基于CNN和RNN的结构。为解决Transformer中无法捕捉方向信息和相对位置的问题,Yan等[18]提出了TENER模型,该模型在MSRA中文语料中的F1值达到92.74%,在OntoNotes5.0数据集上F1值达到88.43%。随着Google提出基于双向Transformer网络结构构建的预训练语言模型Bert[19],成功在11项NLP任务中获得非常好的成绩。越来越多的人将Bert引入到命名实体识别任务。杨飘等[20]在中文命名实体识别任务中引入Bert预训练模型,提出了Bert-BiGRU-CRF网络结构,该模型在MSRA中文语料中F1值达到95.43%。2021年Park等[21]提出KLUE-BERT预训练模型,包括8个自然语言处理任务的数据集,其中使用KLUE-BERT-BASE和KLUE-RoBERTa-BASE预训练模型的方法在KLUE-NER数据集上的F1值分别获得83.97%和84.6%。
2 研究方法
2.1 朝鲜语语法特征
朝鲜语语法中把名词、数词、代词统称为体词[22],那么命名实体属于朝鲜语语法中的体词范畴。而朝鲜语中用于修饰体词的助词也是相对固定的,因此词素粒度有助于计算机更明确地描述命名实体与上下文之间的关系。
朝鲜语具有大部分语言的普遍特征,同时也具有自身独特的语言特点。它具有与英语类似的分写结构,在研究过程中便于切分为语节单位。但朝鲜语的词根与助词等语义相关粒度单位是连写的,因此在进一步细化粒度时需要经过类似于汉语的分词过程完成词素级别的切分操作。这些特性也导致了朝鲜语命名实体与其他词缀之间边界不明确的问题。
本文从朝鲜语语法角度进一步细化语料粒度融合来优化所提取的特征。如表1所示,中国朝鲜语规范中规定的音素包含19个辅音、21个元音和27个韵尾,通过这三种音素组合形成一个音节[23]。

图1 音节与音素关系图

表 1 朝鲜语音素表(中国)

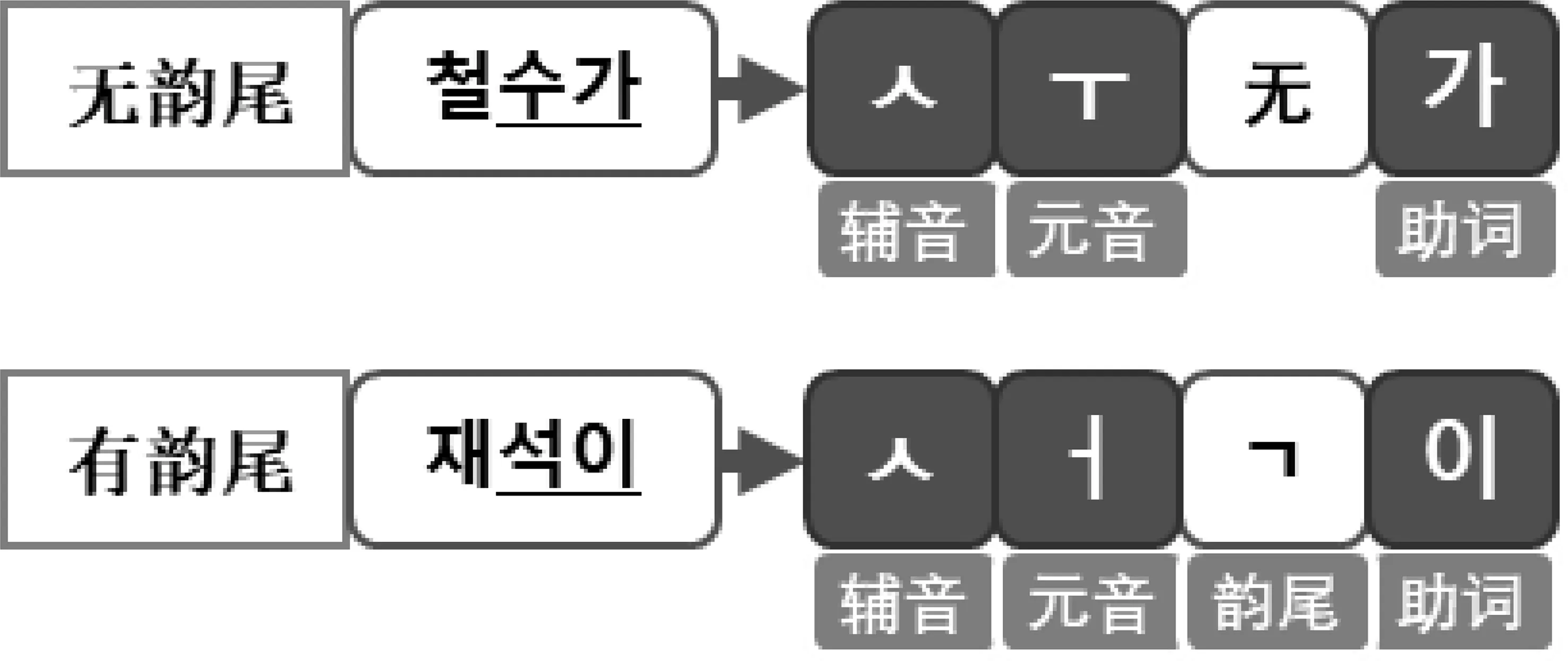
图2 韵尾与助词使用关系图
结合这一特征,本文采用词素、音节和音素三个粒度做多粒度融合的朝鲜语命名实体识别任务。如图3所示,第一列是根据朝鲜语隔写法分割的语节,将每个语节通过词素分析获得词素粒度,其中每个词素都对应一个命名实体标签。最后,通过音素切分获得每个音节的音素字母作为音素粒度。本文提出的这一融合方法,提高了描绘朝鲜语命名实体边界的能力,进一步提高了命名实体识别效果。
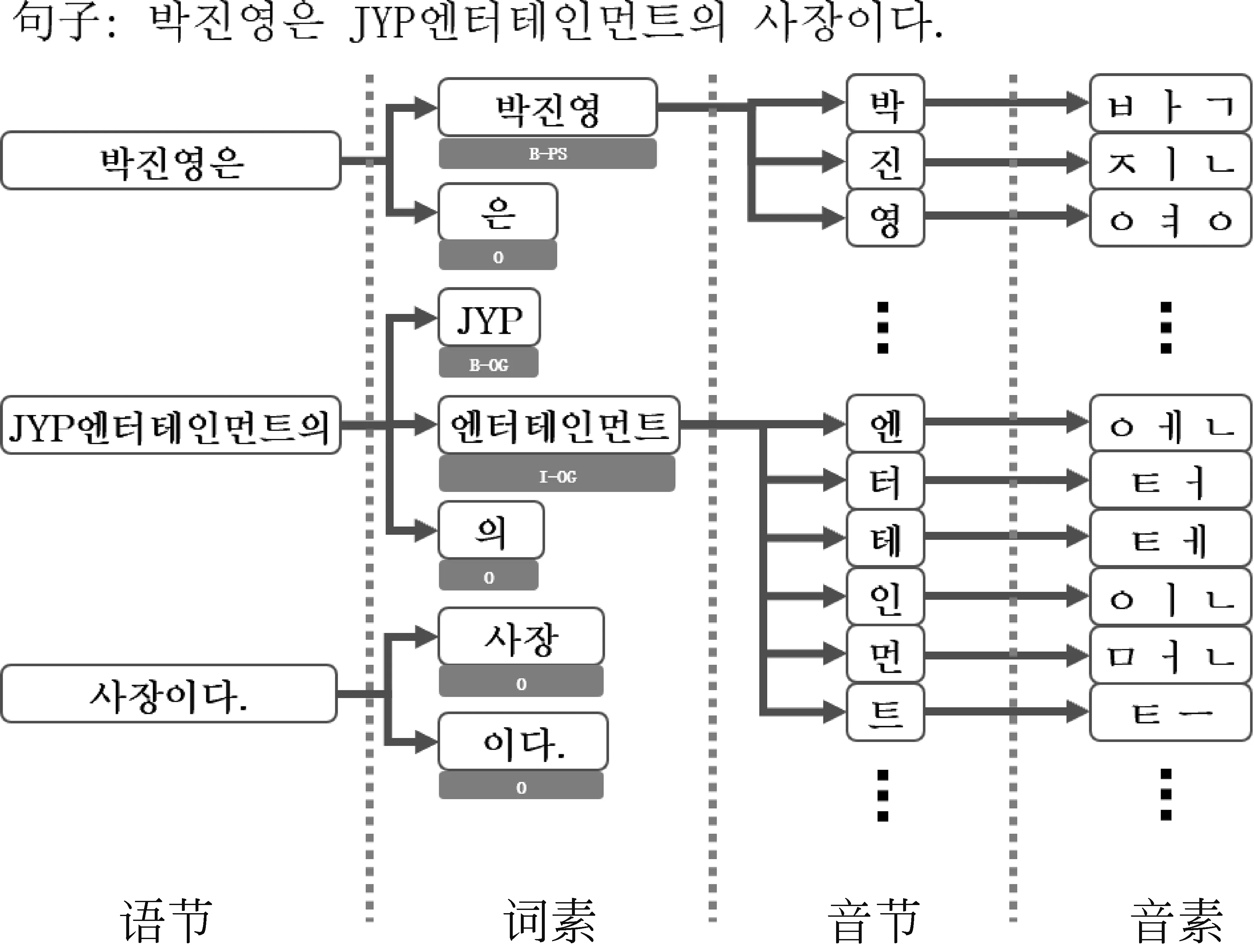
图3 朝鲜语多粒度切分图
有效地提取和融合朝鲜语多种粒度的不同信息,进一步提高朝鲜语命名实体识别模型的性能是本文研究的重点。本文利用CNN和Bi-LSTM来提取朝鲜语的音素粒度和音节粒度的特征,使用特征融合获得增强后的音节粒度向量,将其融入词素粒度向量中来提高基于词素粒度的朝鲜语命名实体识别的性能。其次,为提高模型对命名实体与助词边界的划定能力,使用TENER模型作为命名实体特征提取模型。在词素嵌入部分使用KLUE组织提供的KLUE-BERT-BASE预训练模型。
2.2 多粒度融合的命名实体识别方法

本文所设计的模型结构如图4所示,首先利用Jamo-CNN[24]来提取朝鲜语音素特征。其次,将音节向量和上一步提取到的音素向量融合成增强的音节向量。将得到的音节向量输入至Bi-LSTM层进行编码获得最终音节特征。这些音节特征与使用KLUE-BERT预训练模型得到的词素向量进行拼接。最后,输入至TENER模型,输出命名实体标签。

图4 本文方法的模型结构图
下面重点介绍CNN和Bi-LSTM对音节和音素向量的编码过程。
(1) 基于Jamo-CNN的音素特征提取
朝鲜语的音素包含19个辅音、21个元音和27个韵尾,去除辅音和韵尾中出现的重复字母,共计51个音素字母。通过卷积操作获取不同音素组合的特征信息,并与音节向量进行融合,增强音节向量的特征表示,其结构为图4中的Jamo-CNN部分。设经过卷积运算产生一个新的特征μi,公式如下:
式(1)中fcnn是一个非线性函数,卷积核为w∈Rh×2d,其中h为滑动窗口大小,d是音素向量的维度。Z为第i步卷积操作的矩阵区域,b是偏置项。通过卷积操作后得到了特征图μ=[μ1,μ2,…,μn-h+1],最后对特征图进行最大池化操作得到e=max{μ}。
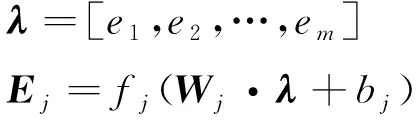
(2)
如式(2)所示,假设有m个卷积核,可以得到最终的特征λ。最后通过前馈神经网络得到音素对应的特征向量Ej,其中Wj是可训练的权重矩阵。
(2) 音节和音素特征融合方法
式(2)中的Ej是通过Jamo-CNN学习得到的音素特征。为了能够将此音素特征深度融合到音节向量中,我们提出了结合两种粒度的联系和差异的特征融合方法。如图4中Fusion Layer所示,使用预训练模型fastText[25]得到音节向量ES,然后使用特征融合方法得到增强的音节向量EIS。
(3)
其中,W1和W2是可训练的权重矩阵,g是一个门控机制,用于控制中间向量和输出向量的权重。通过预训练模型获得音节向量ES,与组成音节的音素特征向量Ej进行融合,得到每个音节的增强后的向量EIS。
(3) 基于Bi-LSTM的音节特征提取
朝鲜语的多数词素由两个或两个以上音节组成,形成一种相互关联的序列。因此,对音节向量EIS使用Bi-LSTM模型学习前后音节间的依赖关系,获得增强的音节特征,如式(4)所示。
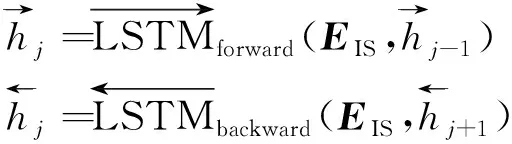
(4)

(5)
其中,⊕是向量连接操作,ri是句子中的第i个词素。WISF是权重矩阵,bISF是偏置项。最后将新的向量通过前馈神经网络进行降维,获得词素对应的特征向量EISF。
我们需要一个准确的词素粒度特征来结合上述方法所获得的音节和音素特征。因此,这里我们选择使用KLUE-BERT预训练模型作为朝鲜语词素嵌入方法。如式(6)所示。
将KLUE-BERT Embedding和词素的增强音节特征融合起来输入到最终的TENER层。
(4) TENER层

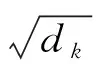
3 实验结果及分析
3.1 实验设置
本文使用KLUE-NER和KlpexpoNER(2016)两个不同的语料库进行了实验。KLUE-NER语料库是由KLUE组织发布的,其中包含多个不同领域的文本数据。该语料库的训练集包含21 008个句子,验证集和测试集分别为5 000个句子。KLUE-NER语料库公布于2021年,其中包含6种实体类型。Klpexpo NER(2016)是为2016年韩国语信息处理大赛而公布的,其中包含3 555个训练集句子,500个验证集句子,1 000个测试集句子。
我们使用F1值作为实验的评价指标,其中KLUE-NER[21]所提供的基线数据包括entityF1和charF1两种。entityF1是命名实体完整匹配结果,而charF1是将实体切分为音节单位后进行匹配的结果,即仅有部分音节识别的结果也计入统计结果中。本文采用命名实体完整匹配方法,因此统一使用entityF1作为评价指标,下文中简称为F1值,计算方法如式(11)所示。
如表2所示,针对不同语料库使用了不同的参数设置。其中Head分别设置为6和8,维度设置为128和96,学习率为0.000 3和0.000 4,Batch size为16和8,而优化器和Dropout统一使用SGD和0.15。实验使用了一块RTX5000显卡,除去数据预处理时间,每次迭代需要4min左右,每轮实验进行100次迭代。

表2 参数设置
3.2 实验结果及分析
有许多研究者在KlpexpoNER(2016)做过测试。选择其中5个最具有代表性的研究结果与本文的方法作了对比。Choi等[26]使用DBSCAN算法词性聚类,并与Word2Vec一起输入至CRF层完成韩语命名实体识别任务。其他的方法都是采用Bi-LSTM-CRF为基础模型完成的。其中Nam等[27]将词性特征融入到词素向量中实现命名实体识别问题。Yu等[28]结合了音素向量和外部的命名实体信息。Kwon等[16]利用LSTM学习音素特征,提高词素的特征表示。Jin等[29]添加Masked self-attention来提高上下文对实体的关注度,在词嵌入部分不仅通过Bi-LSTM学习音素特征,并且融入了自构建的命名实体外部信息特征和绝对位置编码。对比实验结果如表3所示。

表3 五组实验和本文模型在KlpexpoNER(2016)数据集中的表现 (单位: %)
从表3的结果中可以看出,目前比较常用的模型是Bi-LSTM-CRF。使用Bi-LSTM-CRF方法都要比文献[26]的效果要好。而文献[16, 27-29]都是在Word Embedding的基础上,再分别叠加了词素、音节、位置等特征得到了更好的效果。其中文献[29]添加了masked self-attention,在对比文献中的效果最好。但是相对本文使用基于Transformer的模型,其强大的注意力机制可以获得更多更准确的实体特征,同时结合词素、音节、音素多粒度融合方式,比文献[29]高出了3.18%。
KLUE-NER语料库发布于2021年,因此目前只有KLUE组织做出的效果可作为对比。本文使用HMM、CRF和Bi-LSTM模型在KLUE-NER语料库上进行实验,并与本文方法进行对比。实验结果如表4所示。

表4 在KLUE-NER 数据集中的表现 (单位: %)
如表4所示,本实验提出的模型在KLUE-NER语料库中取得了最好的效果。传统的CRF和HMM在单独使用时只能得到74.36%和75.55%的成绩。而Bi-LSTM由于能对上下文特征更有效,因此比前两种方法效果要好。使用基于BERT模型的KLUE-BERT时,充分体现出注意力机制的优越性,效果有了大幅提升。本文的模型是在KLUE-BERT基础上结合了多粒度特征融合方法,相比KLUE-RoBERTa-BASE模型F1值提高了4.42%。实验结果表明本文提出的方法优于其他方法。
3.3 不同命名实体识别结果及分析
为了更清楚地了解本文的模型对不同实体的有效性,进行了针对Klpexpo 2016和KLUE-NER两种数据集的不同命名实体抽取效果实验。这里选择了命名实体分布最广泛的人名(PS)、地名(LC)、机构名(OG)、日期(DT)、数字(QT)、时间(TI)这六种实体类别的数据进行分析,如表5所示。

表5 不同实体类别实验结果 (单位: %)
从表5的结果可以看出,六种不同的实体识别率在相似的水平上,并没有出现太大的差异。其中人名、日期、时间和数字识别率是最高的,说明该模型对这类数据的敏感性最好。其主要原因是在语料库中人名、日期、时间和数字的长度较短,更容易捕捉其特征。而像地名和机构名这类数据,长度变化范围更广,因此模型的识别能力相对较弱。


表 6 测试实例(画方框的区域为语料库中正确的实体)
3.4 消融实验
为验证实验中使用的粒度融合方法、Jamo-CNN模块和Syllable-BiLSTM模块的有效性,设置了消融实验作为比较。如表7所示,第二项表示将音节与音素向量的融合方法改为普通的向量拼接;第三项代表去除将Jamo-CNN提取音素特征的模块,只用FastText静态词向量表示音节特征;第四项代表只通过KLUE-BERT预训练模型代表形态素向量,去除了增强的音节特征。

表 7 消融实验结果 (单位: %)
从表7的结果看出,去除本文提出的多粒度融合方法,单独使用KLUE-BERT预训练模型时,模型性能下降最为明显。而把特征融合改为特征拼接,去除Jamo-CNN音素特征和FastText音节特征时性能都有所下降,因此说明本文所使用的方法均对命名实体识别任务有提高效果。
4 结论
本文针对朝鲜语命名实体语料不足的问题提出了朝鲜语多粒度特征的融合方法,增强了命名实体特征表示。该模型采用基于CNN将音节粒度与音素粒度进行融合形成增强后的音节向量。其次,使用FastText预训练模型对增强的音节向量进行编码,获取其顺序特征。最后,为了提高词素粒度特征,使用KLUE-BERT预训练模型生成增强的词素向量,并与音节向量连接起来,最终输入TENER(基于Transformer的NER模型)模型完成命名实体识别。实验结果表明,本文提出的多粒度融合方法相较于词素和音节特征结合BiLSTM-CRF的方法F1值高出3.18%,相比单独使用KLUE-RoBERTa预训练模型的方法F1值高出4.42%。在未来的工作中,可将本文提出的方法扩展到朝鲜语的多个研究领域来扩大语料规模。
