基于计算机视觉的手语双向通信系统
2023-10-24千学明罗振刚赵培智杨子琪
王 鸽,千学明,罗振刚,赵培智,刘 涛,杨子琪
(西安工业大学 机电工程学院,陕西 西安 710021)
0 引 言
手语是听力语言障碍患者的主要沟通方式之一,与手势不同,它是一种通过面部表情和手部动作表达意思的特殊语言形式。对于听力和语言障碍人群来说,手语不仅便于其日常学习,而且可以为他们带来就业机会。基于计算机视觉的手语双向通信系统包括手语识别、翻译和手语动画生成等功能,不仅能够帮助无障碍人群理解手语,还可以将自然语言转化为手语动作并生成手语动画,便于听力和语言障碍人群理解。目前许多学者仅针对手语识别、翻译[1-2]方面进行了深入的研究,但是对于实现无障碍人群和听力语言障碍人群两者之间的双向通信研究少之又少。如吕蕾等人[3]利用数据手套收集用户手部动作变化数据,提取其动作特征并进行手势识别。贠卫国等人[4]融合纹理特征、几何特征和卷积神经网络等特征进行手势识别,从而提高手语的识别率。张鑫等人[5]提出了一种CGRU-ELMD 的混合深度模型来识别六种常见的人机交互手势,其平均准确度达到了93.4%。谷学静等人[6]利用卷积神经网络和长短时记忆网络相结合的方法识别动态手势序列,其平均识别率达到92.5%。Hurroo 等人[7]使用体积神经网络来训练和预测ASL 数据集,准确率为94.7%。栾迪等人[8]使用基于卷积神经网络的静态手势识别方法,经过图像采集、图像识别、数据处理、CNN 建模、参数训练等步骤,通过测试集验证该模型的准确率达到了92.19%。郭书杰[9]针对复杂背景会对手势识别产生一定程度的影响,提出一种基于AlexNet 优化模型的手势识别方案,该方案的识别准确率可达到93%。李晨等人[10]利用卷积神经网络提取手语的手型特征,利用轨迹归一化算法和长短时记忆网络识别连续的动态手语,该算法可以识别47 个常用手语词组成的语句。以上的研究内容仅关注手语的识别、翻译,而忽视了在实际双向交流过程中手语的生成,且在训练模型时关注静态手语较多,具有很大的局限性。
综合考虑手语的广义性、多样性、复杂性以及遮挡性问题,本文提出了一种基于计算机视觉的手语识别、翻译以及手语生成的一体化系统,实现手语交流双向通信。手语识别、翻译旨在将摄像头录入的手语视频转化为文本或语音,而手语生成是根据自然语言生成手语合成视频。本文采用AlexNet 神经网络模型、CNN-GUR 神经网络模型分别对静态手语和动态手语进行训练。手语的生成利用自然语言处理技术、状态机工作原理,将识别到的语音或文字信息自动匹配到手语数据库中,完成手语动画视频的生成,手语的识别、翻译和生成互为逆过程。
1 手语双向系统
如图1 所示,基于计算机视觉的手语识别系统设计具有以下3 个主要功能:验证用户身份、手语识别和翻译功能、手语生成功能。用户通过输入账号和密码登录主系统页面后,选择手语识别功能,系统将会打开摄像头捕捉用户的手部动作,本文采用中国手语和阿拉伯数字手势进行模型训练,输出结果为中国汉字或中国汉语;用户还可以选择手语生成,通过识别将用户的语音转换为相应的中文,然后将识别出的手语图片转化为视频显示给用户。
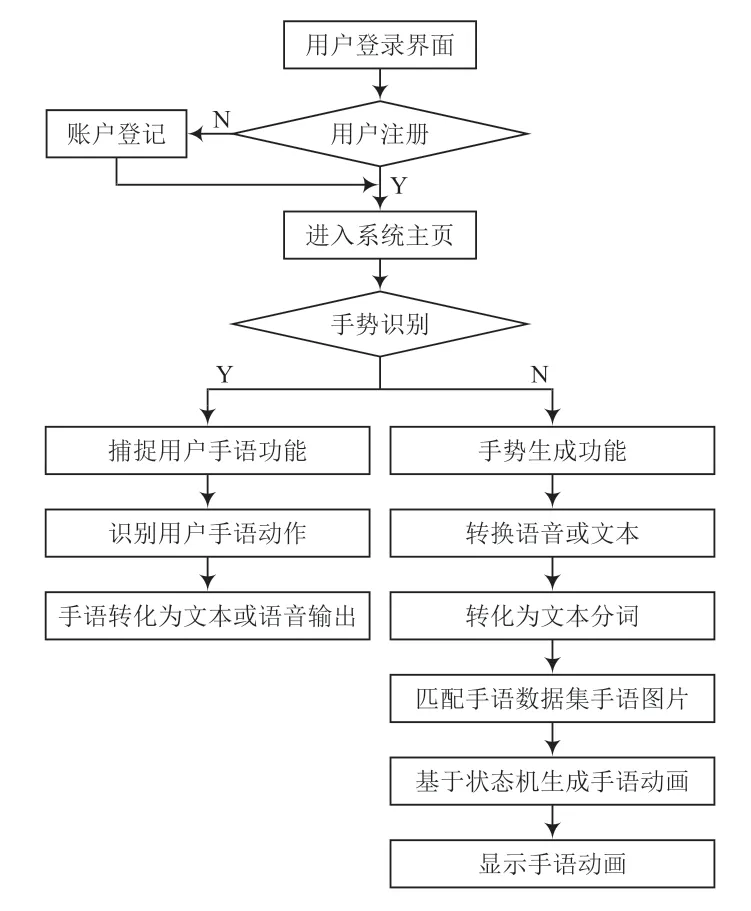
图1 手语识别系统流程
2 手语识别、翻译
目前,手语识别的方法有很多[11-13],主要有3 类:基于传统的模型方法、基于模型的优化方法、基于神经网络算法。基于计算机深度学习特征具有良好的空间时序表达性能,神经网络模型在手语研究中得到了广泛的应用。如图2 所示,手语由静态手语和动态手语两类组成[14]。本文针对静态手语设计一种AlexNet 的网络模型,针对动态手语设计了一种基于改进的CNN-GRU 混合模型。
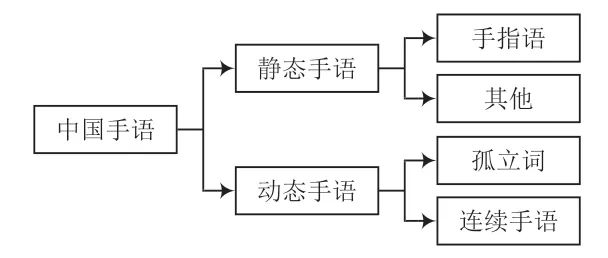
图2 手语分类框架
2.1 数据预处理
从Kaggle 下载DEVISIGN 手语数据集,该数据集包含4 414 个中国手语词汇、331 050 个RGB-D 中国手语视频动画及其对应的骨骼信息。下载后,分析图像目录中的子文件夹,修剪数据集,提取手部区域的图像,将其分为7 ∶2 ∶1比例的训练集、测试集和验证集,将每张图片处理为227×227 大小,并提取其“瓶颈”摘要层,检索或计算图像的“瓶颈”值,将未记录的瓶颈值写入文件。
由于手势识别的重点是手部轮廓和骨骼节点信息,所以使用OpenCV 处理过的灰度图像即可。
2.2 静态手语识别
静态手语包括字母手指语、数字手指语,此外还包括了一些不需要肘关节参与运动的手势。
2012 年Alex 等人凭借其设计的深度卷积神经网络AlexNet 模型在Image Net 大赛中夺冠,引起了人们对于深度学习研究领域的广泛关注,极大地促进了计算机视觉领域的快速发展[7]。基于OpenCV的图像采集处理,输入单通道图像,优化AlexNet 模型用于静态手语的识别。AlexNet 的优化模型如图3 所示,静态手语的识别流程如图4 所示。

图3 AlexNet 优化模型
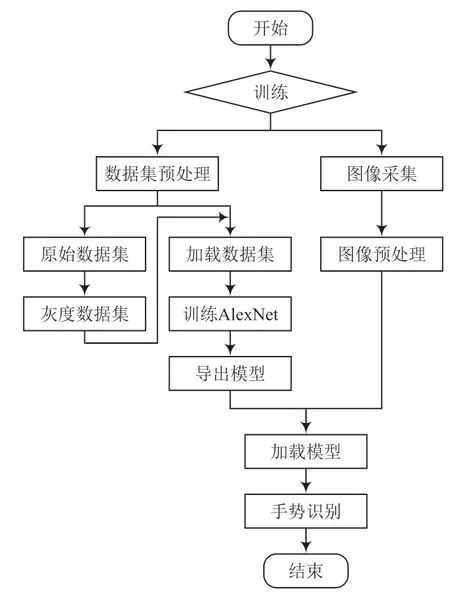
图4 静态手语识别方案流程
2.3 动态手语识别
2.3.1 CNN 特征提取
卷积神经网络(CNN)是一个多层感知(MLP)的变体模型[15],通常由卷积层、池化层和全连接层三部分组成。卷积层负责特征提取的过程,通过奇数大小的卷积核对收集的数据信息进行卷积运算并提取其局部特征,降低了输入数据的维度且更新需要输出的参数值。池化层是对卷积层输出的特征图中某些特征区域内的特征进行采样并删除多余的信息,以此来表征该特征区域的整体特征值,减少需要在下一层进行处理的数据量。最后,通过全连接网络、权重矩阵将卷积层、池化层提取到的局部特征组合成完整图像并重新进行分类。实际上,CNN 的多个卷积核是在不同维度上对输入数据进行特征提取,并通过抽象得到表征全局的特征。但是,传统的CNN 模型参数过多,训练数据不足,容易导致过度拟合。
2.3.2 门控循环神经单元
GRU 是从LSTM 中发展并对LSTM 的三个门函数进行优化而来,将LSTM 中的遗忘门和输出门集成为单一的更新门,并引入了重置门的概念[16]。对于规定的时间步输入,重置门控制前一时刻的状态信息忽略程度,更新门控制当前状态对前一时刻的状态信息的接收程度。GRU 通过变量h传递数据特征[17]。为了防止出现梯度消失或梯度爆炸问题,GRU在前一时刻网络状态ht-1和当前网络状态ht之间添加线性依赖关系。
2.3.3 CNN-GRU 网络
CNN 卷积神经网络模型适用于特征提取,GRU 网络模型适用于处理空间时序数据和反向传播中的梯度消失和梯度爆炸问题,而动态手语的识别任务是对三维空间中手部动作变化的角度、角速度、加速度等时间序列进行分类识别,因此本文采用CNN-GRU 混合网络模型的方法进行动态手语识别。如图5 所示,本文设计动态手语识别流程主要包括三部分。第一部分是由卷积层和池化层构成的输入部分,第二部分是由GRU 单元构成的中间部分,第三部分是由全连接和Softmax 分类构成的输出部分。
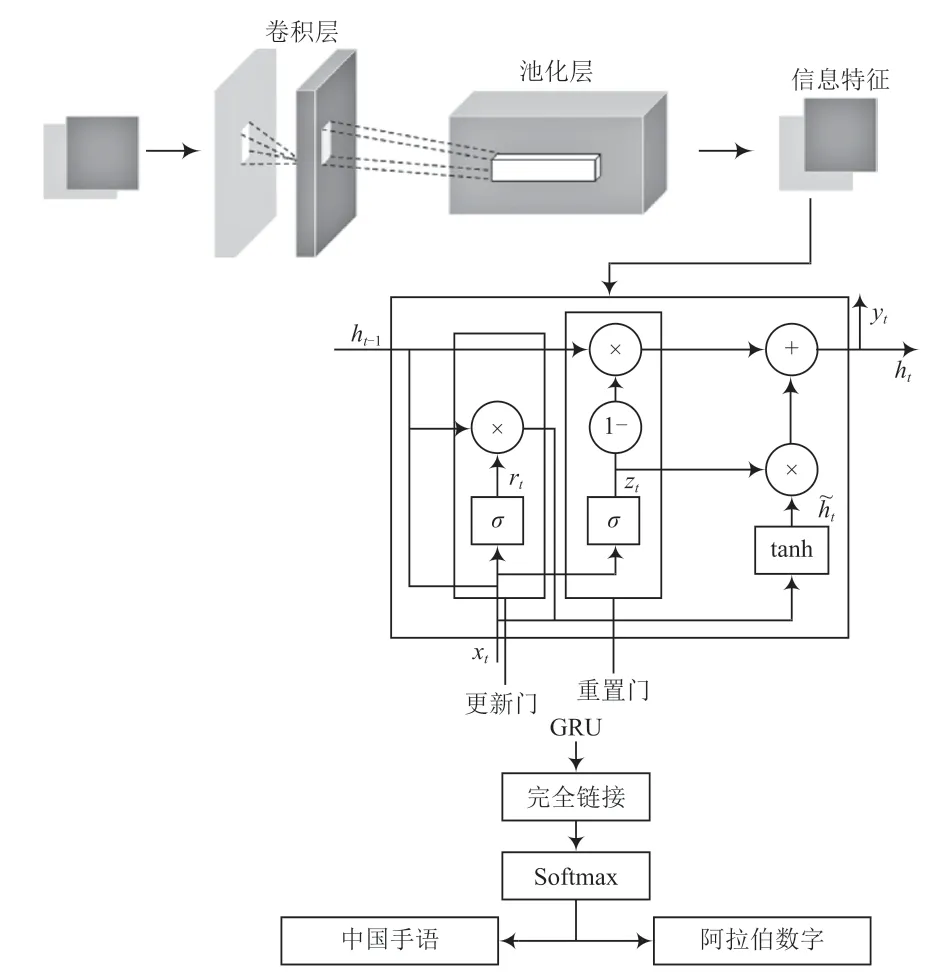
图5 动态手语识别流程框图
2.4 模型训练结果
完成上述数据预处理和参数设置后,启动模型训练任务,将训练数据集分成20 组进行模型训练,创建优化器和损失函数,定义学习率的衰减点,训练到50%和70%,学习率降低到1/10,将每次训练的损失存入平均交叉熵中,在每组训练完成后得到一组训练损失、验证损失和最佳验证损失,并用所得数据不断更新学习率,直到所有20 组都得到训练。该模型对中国手语和阿拉伯数字的最终识别精度为95.52%。
3 手语生成
手语生成是指将文本或语音转换成相应的手势动画的过程,涉及自然语言处理、句子分词以及动画拼接。该系统采用语音识别技术,无障碍患者输入语音或文本,经过自然语言的处理、句子分词自动匹配DEVISIGN 手语数据集中相应的中文手语图片,使用OpenCV 图像处理技术将帧率设置为1,将图片以序列显示的方式[18]拼接成动画并生成视频文件,以AVI 格式显示生成的手语视频。流程如图6所示。
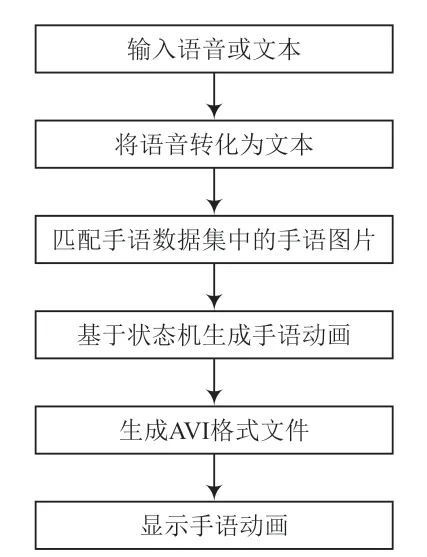
图6 手语生成流程
3.1 文本分词并查找同义词
将语音转化为文本或无障碍患者直接输入文本后,系统对文本进行分词,将一段文字拆分成多个单词或短语。
3.2 基于状态机的动画拼接
从DEVISIGN 手语数据集中找到词汇序列所对应的图片,使用OpenCV 图像处理技术,设置帧率为1,将图片以序列显示的方式拼接成动画并生成视频文件。在手语视频拼接过程中,有如下规则:
定义1:SL(手语词汇库)=(S1,S2, ...,Sn),其中Si代表第i个手语词汇。当i<j时,Len(Si)<Len(Sj)。
定义2:词汇Si的手语词汇动画视频。T(Si)={W1,W2, ...,Wn},其中Wi代表对应手语词汇的手语动画。
把每个手语动画序列看成一个状态,则手语动画生成方法如图7 所示。
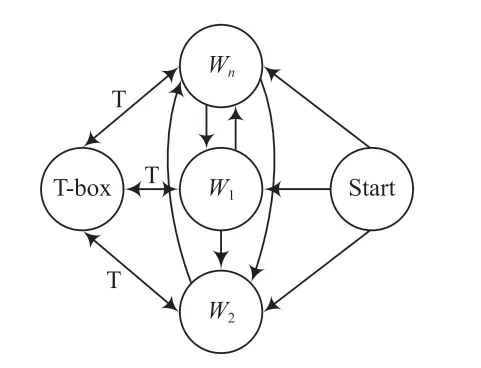
图7 手语动画生成规则
4 结 语
本文设计了一个基于计算机视觉的手语双向通信系统,利用AlexNet 神经网络提取DEVISIGN 数据语料库的特征,实现静态手语的识别和翻译输出;利用CNN 神经网络提取DEVISIGN 数据语料库的特征,并将其放入GRU 分类器中,实现动态手语、阿拉伯数字的识别和翻译输出。同时,基于状态机将用户输入的文本或语音转换为相应的中国手语或阿拉伯数字手语动画,实现手语的生成。实验测试手语识别准确率为95.52%,手语翻译准确率为93.3%,能够满足基本需求,为听障群体打开沟通之门。
