基于双阶段轻量YOLO的红外行人伪影检测算法
2023-10-24干宗良
沈 恒,干宗良
(南京邮电大学,江苏 南京 210009)
1 引 言
热红外成像[1]较可见光图像而言具有独特的优势,如不受光照强度影响且能在各种恶劣天气环境下工作,在城市安防监控、军事演练等领域得到广泛关注。但是红外图像在一些特定环境 (如办公厅、教学楼等光滑建筑环境)具有一定程度的反射现象,这直接干扰红外图像的后续处理过程。以红外行人检测为例,行人被镜面反射的能量会被热红外成像仪再次接收并以各种形式呈现出来,检测时误认为是发热物体导致不必要的工作。此外,反射回波具有与行人十分相似的轮廓和梯度信息,加上红外图像本身对比度低的特性,行人和对应的伪影往往具有十分相似的特征,无论是用人眼先验还是用计算机判别都耗时耗力且并不准确,易混淆行人和行人伪影。红外行人伪影检测技术就是针对性的标记行人伪影区域,让人们根据需求提取行人红外图像有用信息,方便后续使用。
红外行人伪影图像背景复杂,用传统红外目标检测方法,如max-mean[3]、图像分割[4]和偏微分方程[5]等受到单一场景的限制,难以分离伪影区域。而深度学习算法[6]具有对复杂上下文信息更好的特征表达能力,用来检测伪影区域的适用性更高。总体来说,基于深度学习的目标检测算法可分为两大类:一类是基于区域的双阶段目标检测算法,如R-CNN[7]( Region-based Convolution Neural Nedtwork)、Fast R-CNN[8]等。另外一类则是区域选择和目标检测统一的单阶段目标检测算法,典型的有SSD[9](Single Shot multibox Detector)和Redmon等提出的YOLO[10-14]系列算法。针对红外图像行人检测,研究者们分别对现有的单阶段和双阶段目标检测算法进行了改进,如Xie H等人[15]构建了多种类型的Fast R-CNN模型,适用于不同需求下的红外行人检测任务。Wang X等人针对YOLOv4提出了一种新的红外行人检测算法(RepVGG-YOLOv4,Rep YOLO)[16],提高了检测效率。Montenegro B等人[17]对YOLOv5s轻量算法进行了改进,使用2个YOLOv5s子网络构建红外行人检测模型,弥补了轻量网络检测精度低的缺陷。
由于红外行人伪影形态变化复杂,对比度低,使用单阶段目标检测算法检测精度不高。因此,本文借鉴双阶段目标检测算法的设计思想,使用两个轻量YOLO分别用于区域选择和红外行人伪影目标提取。满足检测精度要求的同时,避免了双阶段网络繁琐、实时性差的问题,工作如下:
(1)针对行人伪影直接检测容易出现的误检和漏检现象,构建基于轻量YOLO的双阶段行人伪影检测算法,先提取“行人-伪影”联合区域,后行人伪影精准定位。
(2)针对轻量网络检测精度不高的问题,本文对YOLOv5s进行了改进。我们在网络的主干部分使用改进的下采用模块[2]LSM替换FOCUs模块,增强低级语义信息提取能力,并减少浮点运算数。其次嵌入注意力模块[18](Convolutional Block Attention Module,CBAM),使网络更加关注有用区域,提高模型的检测精度。
(3)针对双阶段网络容易出现的模型繁琐问题,设计只有两个尺度输出特征层的轻量网络LS-YOLO,减少检测框数量,保证检测速度。
2 红外行人伪影分析
在行人热红外图像的拍摄场景中,红外图像的呈现效果取决于光敏元件捕捉的热辐射强度,由于电磁波的反射效应,如果行人所处环境中存在发射率低的材料,例如光滑镜面材料,它会反射行人及背景产生的热辐射,使得红外成像仪不仅仅接收到行人自身的热辐射,也有来自镜面反射的行人热辐射,如图1所示。最终成像中不仅包括行人本身部分,也有来自光滑镜面反射行人热辐射能量后的红外成像。
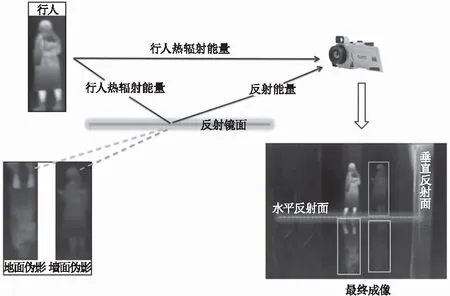
图1 行人伪影形成原理
行人所处环境复杂多变以及红外图像本身具有对比度低、分辨率差,使得同一行人在不同位置产生的伪影存在亮度、边沿形状以及尺度的巨大变化。如图2(a)所示,一个行人在图像中呈现多个形状、尺度不同的伪影,给检测带来极大干扰;图2(b)则展示了行人的部分伪影被背景块遮挡,丧失了真实的行人特性,虽然这种图能够用人眼先验判断,但是对于神经网络却很难做到。综上,一张行人红外成像可能出现多个伪影区域,不同位置的伪影变化很大,有些伪影与行人本身十分相似,用神经网络直接定位行人伪影复杂度较高。因此,本文提出一种基于联合区域的双阶段轻量YOLO检测算法,借鉴了双阶段网络能有效提高准确率的思想,降低了网络分离复杂背景环境和行人伪影的压力,同时轻量结构的设计也能满足实时检测要求。

图2 行人伪影
3 红外行人伪影检测算法设计
本文提出的双阶段红外行人伪影检测算法结构如图3所示,第1阶段使用LSM双分支结构替换YOLOv5s网络的FOCUs模块,添加注意力感知使网络更加关注具有行人和对应伪影的联合区域,提高了检测精度。第2阶段,消除背景后行人和伪影信息相对突出,结合轻量YOLO思想设计行人伪影精准定位模型LS-YOLO,最后整合两个轻量网络完成红外行人伪影检测任务。下面将着重介绍我们的改进工作,关于YOLOv5s主干特征提取和多尺度特征融合的更多细节可以参考文献[14]~[19],在这不再赘述。

图3 红外行人伪影检测算法框图
3.1 LSM模块
Focus模块是YOLOv5s模型在图像进入主干特征提取网络前的预处理部分。如图4所示,将像素点与像素点进行步长为2的跳跃连接,原始输入为640×640×3的图像切片后变成320×320×12尺寸。

图4 Focus切片操作
Focus的设计者认为通过切片再下采样的方法能够减少浮点运算数(FlOPs)。FlOPs在神经网络中常用来衡量算法或模型的复杂度,表达式为:
(1)
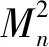
(2)
在YOLOv5s中,输入图像经Focus切片操作后会进行两次下采样卷积得到160×160×64的特征图,两次卷积核大小都为3×3。由上述,可计算出YOLOv5s中使用FOCUs并将输入图像转换为160×160×64的特征图所需的浮点操作数和参数数量为:
FLOPs(Focus)=3202×32×12×32+1602×32×32×64=825753600
(3)
Params(Focus)=32×12×32+32×32×64=21888
(4)
实际上,Focus切片操作在没有进行特征提取的情况下进行像素空间跳跃连接会损失部分空间信息。因此,本文使用LSM模块替换原Focus结构,满足减少浮点运算数的同时避免丢失信息,如图5所示。

图5 LSM结构
LSM模块的特点在于通过双分支结构使网络映射不同感受野,由于3×3卷积和最大池化具有不同的特征表达,如最大池化更有利于纹理特征的提取,所以两个分支分别通过3×3卷积和最大池化操作提取不同特征并压缩图像,再用1×1卷积整合特征,最后拼接两个分支得到160×160×64的特征图,综上LSM模块的复杂度为:
FLOPs(LSM)=3202×32×3×32+3202×12×32×16+1602×32×162+1602×12×16×32+1602×22×32+1602×12×32×32=242483200
(5)
Params(LSM)=32×32×3+12×32×16+32×16×16+12×16×32+12×32×32=5216
(6)
与Focus模块相比,采用LSM的浮点运算数和参数量分别缩减约为原来的1/3,1/4,模型更为轻量,且LSM在特征提取之前不会损失信息,具有更好的特征表达能力。
3.2 添加注意力感知模块CBAM
第一阶段“行人-伪影”联合区域的检测是后续处理的基础,因此,本文注重提升网络的注意力焦点,使网络更关注来自目标区域的特征点,提高检测的准确率。添加空间-通道注意力感知模块(CBAM)[18]是实现网络自适应注意的一种方式,CBAM结构如图6所示。
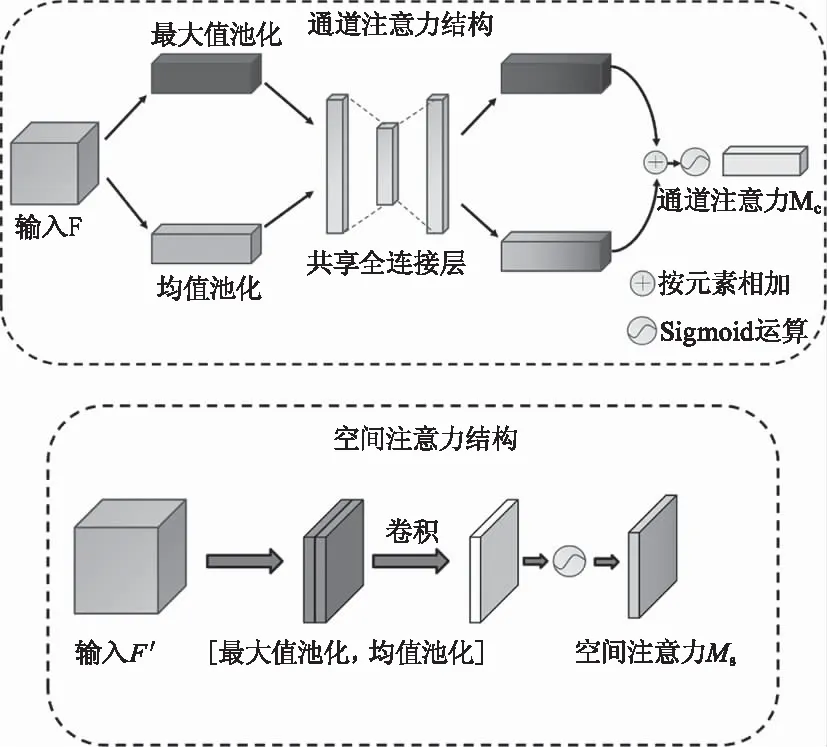
图6 CBAM通道注意力和空间注意力结构
简言之就是通过双池化操作分别按通道和空间对特征映射进行压缩,再通过全连接和卷积增强注意力模块非线性表达的能力,使用sigmoid函数归一化后获得每个通道和空间的权重(0~1之间),最后以相乘形式把权重加权到输入特征图上,实现越重要的特征加权越多并抑制无用信息。CBAM是一个轻量级的通用模块,如图3所示,本文将注意力添加到YOLOv5s的主干特征提取网络之后,对已经提取到的深层特征进行注意力加权,使第一阶段网络自适应的聚焦目标区域。
3.3 LS-YOLO网络设计
第二阶段的任务是从“行人-伪影”联合区域中定位行人伪影,由于联合区域消除了原本的复杂背景,因此这一阶段需要减少模型复杂度,本文借鉴轻量YOLO的思想设计了LS-YOLO网络,对于本身特征不充分的行人伪影具有很好的定位能力。
如图3所示。LS-YOLO网络首先使用LSM模块提取浅层特征并将特征图尺寸调整为160×160×64,主干部分由Resblock_body[14]残差结构组成,如图7所示,Resblock_body先用卷积对输入特征进行整合,之后将整合后的特征层划为两部分,一部分作为大残差边route。另一部分的通道进行1∶1分割,取后者作为分割的主干部分,然后对主干部分进行3×3卷积并引出小残差边route_1,小残差边会与再次卷积后的主干部分相接调整通道,对相接的结果做1×1卷积处理,并与大残差边拼接,拼接后的特征图通道数是之前2倍,最后经过最大池化操作将宽高缩减为原先的一半实现下采样。在LS-YOLO网络中,每一次Resblock_body后都会引出一个分支去构建特征金字塔[20](Feature Pyramid Network,FPN),将浅层边缘细节特征和高层语义特征融合实现特征增强效果。具体为第一次Resblock_body后引出的特征图经过一次下采样卷积,尺寸调整为40×40×256,这个特征图会与第二次Resblock_body的结果进行融合得到40×40×512的特征图。第三次Resblock_body后引出的特征层经过两次卷积对特征进行整合,整合后的特征图一个分支为第一个尺度的特征输出层,其尺寸为20×20×1024;另一分支首先经过卷积将通道数调整为512,再通过最邻近上采样后与上述40×40×512的特征图有效融合作为第二个尺度的特征输出层,尺寸为40×40×1024,最后预测头部根据这两个输出特征层进行结果预测并输出行人伪影的位置,预测头部实现可参考文献[13]。
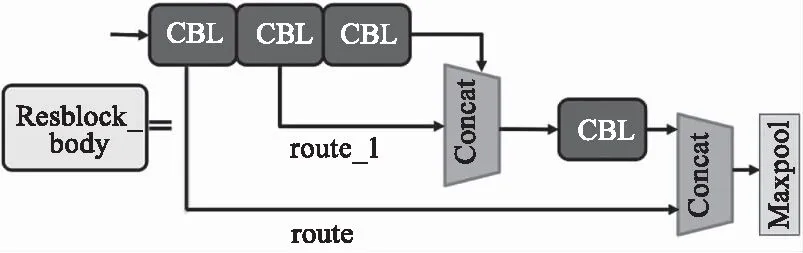
图7 Resblock_body结构
4 实验及结果分析
4.1 实验设计
为了评估双阶段算法的性能,实验使用fluke公司发行的TiX640型长波红外热成像仪拍摄红外行人图像来构建一个新的红外行人数据集,采集了包含不同类型反射物质的场景,如现代教学楼、办公厅、和一些特定的户外环境。收集到的图像分为三类,分别为只有行人、某一种类型的伪影(如地面或者是墙面),以及混合地面和墙面伪影的红外图像,示例见图8。在数据预处理阶段,本文采用labelImg图片标注工具分别对“行人-伪影”联合区域模型和“行人伪影”模型按照7∶2∶1比例进行训练集、测试集、验证集的划分,并使用mosaic-4[14]数据增强的方法对训练集进行样本扩充,增强后训练集图片共有4216张。

图8 数据集部分红外图像示例
实验使用的硬件配置信息如图表1所示。算法检测性能的评估由模型检测速度和检测精度衡量,检测精度采用公信力最高的平均精度均值 (mean average precision,mAP)和模型训练的最终损失值大小进行比较,精度的计算又由准确率(Precision)和召回率(Recall)来决定,当预测框与真实框的交并比(intersection over union,IOU)大于设定的某个值(本文设定0.5)时可认为预测正确,统计后可计算出准确率和召回率;检测速度则通过模型每秒能够处理并返回的画面帧数(Frames Per Second,FPS)衡量。

表1 实验环境信息
训练时,由于网络结构改变,从0开始训练的模型权重过于随机,引起网络震荡。本文先对模型预训练10个迭代作为权重初始值,再分别训练“行人-伪影”联合区域模型以及伪影定位模型300和100个epoches,训练时选择Warmup=3的预热学习率的方式,使得开始训练的3个epoches内学习率较小,模型可以慢慢趋于稳定。预热后初始学习率为0.01,其他为默认设置。
4.2 结果分析
本文使用YOLOv5s、YOLOv4、RepYOLO[16]、YOLOv3[12]、Faster R-CNN等算法模型与本文模型进行比较,其中,RepYOLO和YOLOv3是Montenegro B等人针对红外图像行人检测提出的改进算法。结果表明双阶段轻量YOLO算法性能更加出色,能完成实际应用中针对特定场景行人伪影检测的任务。
4.2.1 LSM+CDAM模块解耦对比试验
为验证第一步中LSM和CDAM改进的有效性,实验以YOLOv5s为基准模型,对“行人-伪影”联合区域进行检测。其中LSM替代原网络的Focus下采样模块,CDAM添加到网络的主干特征模块后,其他参数均一样。结果如表2、3所示,相较于YOLOv5s基准模型,LSM模块替换原先的Focus模块减少了浮点运算数,对于整个网络运算数和参数减少不多,FPS有轻微提升,但是LSM能够更有效的增强网络低级特征提取能力,使得整个网络精度提升2.69%;再添加CDAM模块对提取的特征整合以及增加注意力,最终在满足检测速度不下降的同时整个网络的精度提升了5.46%。表3展示了不同的模型在“行人-伪影”联合区域的检测性能,与红外行人检测算法RepYOLO以及原基准模型相比,本文改进后的模型由于整合了注意力,训练时自适应聚焦于红外行人图像中具有行人和伪影的联合区域,检测效果最好。

表2 LSM+CDAM消融实验

表3 不同模型检测联合框的结果
4.2.2 LS-YOLO实验分析
本文提出的LS-YOLO是针对第2阶段行人伪影精细定位设计的轻量模型,权重大小只有18.75M。为了验证性能,我们与基准模型YOLOv4-tiny[13]做对比试验,结果如图8所示,可以看出模型改进后,可训练性更强,且训练效果更加出色,YOLOv4-tiny收敛后的损失值在4.6左右,而LS-YOLO则降低到了2.7附近,并且模型在测试集上的泛化能力较好,与训练的损失值十分接近,说明没有发生过拟合现象。图9是测试时具有代表性的结果反馈,LS-YOLO的网络损失比YOLOv4-tiny更低,对伪影的位置定位更准确。
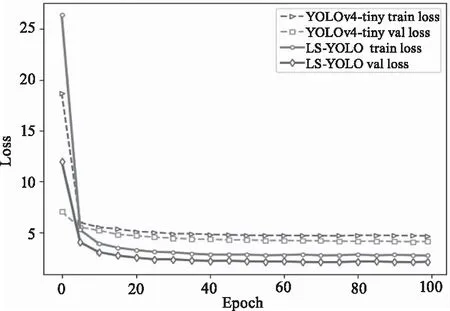
图9 LS-YOLO损失函数曲线对比图
4.2.3 二步算法综合性能分析
如表4所示,与其他模型结果对比可知,双阶段轻量YOLO行人伪影检测算法相对于YOLOv5s,RepYOLO,YOLOv4,YOLOv3,SSD,Faster R-CNN直接检测的网络精度分别提升6.52 %,8.04 %,3.14 %,9.25 %,17.66 %,26.33 %。直接检测法中YOLOv4的检测效果最好,mAP达到92.33 %,但是YOLOv4网络权重大小有240M,是LS-YOLO的10倍,模型过于复杂。检测速度方面,YOLOv5s实时性能最好,精度却相对一般。我们提出的模型结合了两个超轻量的网络,所以检测速度比不过YOLOv5s,不过仍然能够满足实时检测的要求。为了更直观的比较不同模型的性能,图10展示了我们从测试结果上挑选的一部分检测实例,对于严重残缺的行人伪影目标来说,直接检测法效果不佳。如图10的(a)、(d)所示,SSD和YOLOv3等算法无法有效识别目标。面对背景复杂,行人和伪影特征不突出的环境时易出现错检情况,如(c)中将行人误检为伪影,(f)目标漏检。行人伪影检测时,基于YOLOv4的模型对特征信息变化十分敏感,当背景特征与行人伪影特征相似时容易出现误检现象,如(h)和(i)所示。相比之下,本文算法从原理上降低错检、漏检的风险,检测精度高,并且模型轻量,满足实时部署的要求。
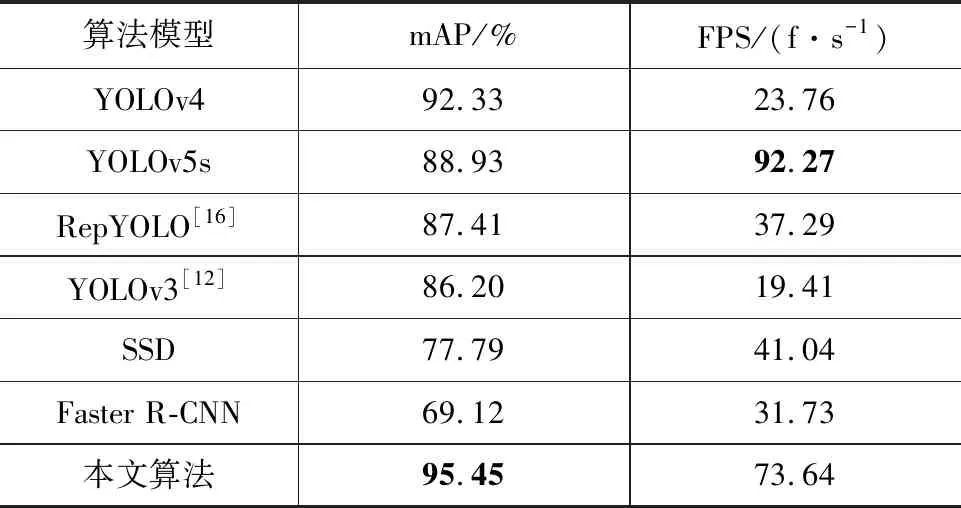
表4 二步算法性能对比试验结果

图11 不同算法检测效果图
5 结 论
在分辨率差、背景不突出的红外图像中,由于镜面回波形成的伪影具有与行人以及某些环境物体相似的特征信息,主观先验法无法判断伪影位置,而深度学习领域的目标检测算法依赖于对目标与环境背景的精细分离和信息整合、判断,直接检测法往往效果不佳。本文提出了一种基于“行人-行人伪影”联合区域的二步检测轻量算法,整个网络模型大小只有41 M,平均精度均值达到95.45 %。第一步中只需要检测“行人-行人伪影”联合区域,从原理上增大了目标的面积,减少了误检和漏检概率,并对基础模型改进,提高准确率。第二步针对联合区域的伪影检测设计了一个仅包含两个尺度特征输出层的轻量网络LS-YOLO,与原模型对比,该算法针对特征突出、背景环境单一的联合区域具有较高的准确率,验证了二步算法的可行性。综上所述,本文提出的二步轻量算法在保证较高准确率的条件下也能达到实时检测要求,解决了直接行人伪影检测算法中伪影漏检和定位不准确问题,对后续针对行人的处理有很大帮助。下一步,我们将针对红外行人图像环境中的通用物体进行检测,进一步排除影响红外图像后处理过程的因素。
