基于牛耳标OCR的牛身份识别研究*
2023-10-23童慧琳
童慧琳,李 琦
(内蒙古科技大学信息工程学院,内蒙古 包头 014010)
0 引言
在大规模化牛场中,要实现对牛个体自动化、信息化的日常精细化管理,实现对每头牛的健康状况追踪及奶源和肉制品追溯,须对牛的身份进行识别[1-4]。本文采用PP-OCR 框架对牛耳标进行识别,从而确定牛只身份。由于牛耳标区域在牛头部图像中占比较小,且多有耳标采用人为手写的方式,存在书写不规范等问题,对牛耳标区域的文本定位和识别造成了一定困难[5-7]。
1 PP-OCR网络结构
1.1 牛耳标整体识别框架
光学字符识别OCR 的概念于1929 年被首次提出,但由于当时软硬件技术的限制,这项技术并没有被实现。随着计算机设备的出现与应用,OCR 技术才得以实现。OCR 领域分为文本检测和文本识别两个主要研究方向。近年随着深度学习技术的出现,OCR技术在实践中取得了越来越多的成果。其中,PP-OCR是一套较为成熟的中英文OCR 方案,其重点在于解决不同语言的OCR 问题,PP-OCR 包含了很多的文本检测算法和文本识别算法,具体包括:不同的backbone网络,自定义的预测头网络,各种常见超参的选择,模型轻量化等。这些策略使得整体模型变得更加轻量高效,同时还提升了上线部署的效率。PP-OCR 主要由三个流程组成,分别是DB 文本检测、检测框校正、CRNN 文本识别。其中,绿色框中表示的是一些常用的轻量化方案,这使得PP-OCR 最终的模型大小可以达到MB 级别。在本文中,将采用PP-OCR 的整体技术流程来完成基于牛耳标的个体身份识别。
1.2 牛耳标文本检测器
如图1所示,文本检测器包括两部分:一个骨干网络和一个检测头网络。其中,骨干网络的大小决定了文本检测器的的网络模型大小,考虑到模型轻量化和模型精度之间的兼容,PP-OCR 采用MobileNetV3 作为文本检测器的骨干网络。另外,PaddleClas还提供了多达24种的图像分类网络结构,其中包含了如ResNet、SEResNeXt、Res2Net vd、DenseNet、EfficientNet、Xception、HRNet 等预训练模型以及训练配置方案。类似于FPN 的网络结构,检测头网络采用1×1 卷积,将不同分辨率上的特征图的通道数变为相同的数量,获得在各个图像感受野下的多尺度的特征图,再将各个感受野下的特征图进行加权合并,从而获得一个融合的特征图。

图1 牛耳标文本检测器网络结构
1.3 牛耳标文本方向检测器
由于文本方向检测器的训练比较容易,因此PPOCR 使用MobileNetV3 作为文本方向分类器的骨干网络。在大部分文本识别算法中,归一化图像的高和宽一般设置为32 和100,因为文本方向检测器的骨干网络非常轻量,所以,适当地提高输入图像的分辨率,并不会引起计算时间的显著增长,而且,随着输入图像的分辨率的提高,文本方向检测器的精度也会相应地得到提升。
1.4 牛耳标文本识别器
文本识别器使用了CRNN(Convolutional Recurrent Neural Network),如图2 所示它是一种比较常用的文本识别网络,能够识别较长的文本序列,主要包括卷积层、循环层和转录层。实际上,转录层相当于模型的损失函数,而卷积层与循环层可以看作由CNN 和RNN组成的网络。

图2 文本识别器网络结构
在CRNN 模型中,卷据层是通过多组卷积、池化层和批量归一化层来构建的。与其他CNN模型类似,该方法将图像转换成含有图像深度特征的特征图,然后将特征图输入到后面的循环层。首先将输入图像以计算出的比例进行缩放,以确保图像输入一致。由于卷积神经网络包含了卷积层和最大池化层,因此网络对于输入图像具有平移不变性的特征。卷积神经网络中的感受野的定义是,经过卷积层输出的特征图的各个像素对应着输入图像多少个像素,它和特征图上的像素自左向右,自上而下是的各个像素是一一对应的。尽管卷积神经网络因其具有的优点而被广泛应用到了视计算机领域中,但因为它经常需要将输入图像缩放成相同的大小,所以对于一些尺寸变化较大的数据,例如文本信息,就不能发挥出很好的作用。为了更好的对时序信息进行处理,在卷积层之后加入了一个通过RNN 组成的循环层。在PP-OCR 中,卷积层使用MobileNetV3作为网络backbone。
选择循环层的主要原因有三个。①卷积神经网络对于数据的上下文信息提取能力较差,而循环神经网络正好可以弥补这一不足;②在反向传播时,循环层得出的关于误差的梯度可以反馈到卷积层,所以循环层和卷积层的网络参数能够一起调整;③最关键的是,循环神经网络能够处理不同长度的数据,卷积神经网络则无法处理这种数据。普通的循环神经网络存在着相同的缺点,即如果输入数据的序列过长,在反向传播的时候就会出现梯度消失的问题,这很容易使得循环神经网络所能学习的上下文信息的长度有限,并且训练也更加困难。因此,使用长短时记忆网络LSTM 来取代一般的循环神经网络,利用门机制将长期和短期的记忆融合到一起,从而解决普通循环神经网络的问题。
在一个序列中,由于某个变量不仅与之前的信息相关,还与其之后的信息相关,因此,采用双向的LSTM 可以更好地发挥上下文信息的作用。此外,经过实验验证,通过增加双向LSTM 的层数,可以有效地提高识别的精度。我们采用了两层的双向LSTM,在实际应用过程中,我们可以根据实际情况来做相应的调整。利用卷积层得到的特征序列经过循环层两个双向LSTM 的处理后,可以对图像中的文本信息做出更精准的识别。由于卷积层的输出特征的维度与LSTM 的输入特征的维度不同,为了实现维度的变换,还需构建一个线性层,将其作为卷积层到循环层的过渡,从而满足循环层的输入需求。
转录层的作用是将由循环神经网络预测的序列转换成标记序列,从而得到最后的识别结果。该层的原理是在标记序列中的各个分量中,选择概率最大的索引,作为识别结果,并将其组成为最后的识别序列。本文引入CTC 算法中定义的条件概率应用于序列的转换问题中。
2 训练
2.1 牛耳标数据集准备与标注
牛耳标数据集利用三千万像素照相机,对在养殖状态下的个体牛进行拍摄从而获得牛耳标图像,构建了一个牛耳标图像数据集,如图3 所示。本数据集来自内蒙古锡林郭勒盟苏尼特左旗的一个牧区,共包含133头受试牛,每头牛的牛照片为5-100张图像。图像中的耳标截面倾斜角度应控制在-45 度到45 度之间,剔除角度过大的图像,避免因角度过大造成字符畸变而影响识别结果;同时一头牛的耳标图片不适宜挑选太多张,因为耳标的字典较少,如果相同受试牛的照片挑选过多,会造成数据集的数据泛化性过低。经过筛检后,耳标图像总计3457张图像。将牛耳标数据集命名为eartagDATA。

图3 牛耳标数据集eartagDATA
本文将采集筛检后的3457 张牛耳标数据集eartagDATA 使用PPOCRLabel 标注工具对其进行标注。PPOCRLabel是一款功能强大的半自动化OCR标注工具,它支持中英文与数字识别,以及法文、德文、韩文、日文多种语言的检测。PPOCRLabel 默认使用PaddleOCR 中的轻量化PPOCR 模型,同时也支持用户使用自定义模型。针对标注过程中的误识别、漏检测等问题,PPOCRLabel提供自动标注、手动标注、重新识别、手动更改识别内容、批处理、撤销等功能PPOCRLabel能够导出直接用于PPOCR检测和识别模型训练的数据格式,主要包括Label.txt,fileState.txt,Cache.cach,rec_gt.txt,crop_img 识别数据等。其中,Label.txt 是检测标签,行数据包含图片对应的路径、检测到的多个文本框坐标及其对应的文字或数字;fileState.txt是图片状态的标记文件,保存当前文件夹下已经被用户手动确认过的图片名称;Cache.cach是缓存文件,保存模型自动识别的结果;crop_img是按照检测框切割后的图像;rec_gt.txt是识别标签。
2.2 牛耳标图像预处理
由于牛耳标照片的拍摄距离不同,所以耳标图像的分辨率也不同,会对耳标识别的准确率造成影响。使用三次双线性插值将耳标图像的分辨率进行统一。经过三次双线性插值耳标图像分辨率统一后,分辨率大小均为1024*1024dpi,如图4所示。
图4 牛耳标图像统一分辨率结果示意图
在数学中,双线性插值是对两个变量的插值函数进行线性插值扩展。首先,在x方向做线性插值,可得到式⑴和式⑵:
接下来在y方向上进行线性插值,得到式⑶:
结果f(x,y)如式⑷:
接下来对统一分辨率后的牛耳标图像进行腐蚀膨胀处理,腐蚀类似“领域被蚕食”,是将图像中高亮区域或白色部分进行缩减细化。而膨胀类似于“领域扩张”,将图像的高亮区域或白色部分进行扩张,运行结果图比原图像高亮区域更大。腐蚀和膨胀都是对图像的高亮区域或白色部分而言。
腐蚀是X 用S 腐蚀的结果是所有使S 平移x 后仍在X 中的x 的集合。换句话说,用S 来腐蚀X 得到的集合是S 完全包括在X 中时S 的原点位置的集合,其公式表达如下:
而膨胀可以看做是腐蚀的对偶运算,其定义是:把结构元素B 平移a 后得到Ba,若Ba 击中X,我们记下这个a 点。所有满足上述条件的a 点组成的集合称做X被B膨胀的结果。其公式表示如下:
耳标图像经过腐蚀和膨胀处理后能够有效消除噪声、分割出独立的图像元素和寻找到图像中的明显的极大值区域或者极小值区域。
对图像先腐蚀、后膨胀,叫开运算,用式⑺表示。其作用是:分离物体,消除小区域。
图5是经过图像腐蚀膨胀处理的部分实现源码和处理后的图像示意图。我们可以明显看出经腐蚀膨胀后的耳标更加清晰,下文的实验分析中会通过具体的实验数据来验证。

图5 牛耳标图像腐蚀膨胀处理示意图
3 实验
3.1 实验参数设置
牛耳标文本检测实验利用MobileNetV3 作为骨干网络,网络的输入是牛耳标图像,输出是牛耳标文本检测结果,具体的实验参数如表1所示。

表1 牛耳标文本检测参数设置
牛耳标文本识别实验利用CRNN 作为骨干网络,网络的输入是牛耳标文本图像,输出是牛耳标文本识别结果,具体的实验参数如表2所示。
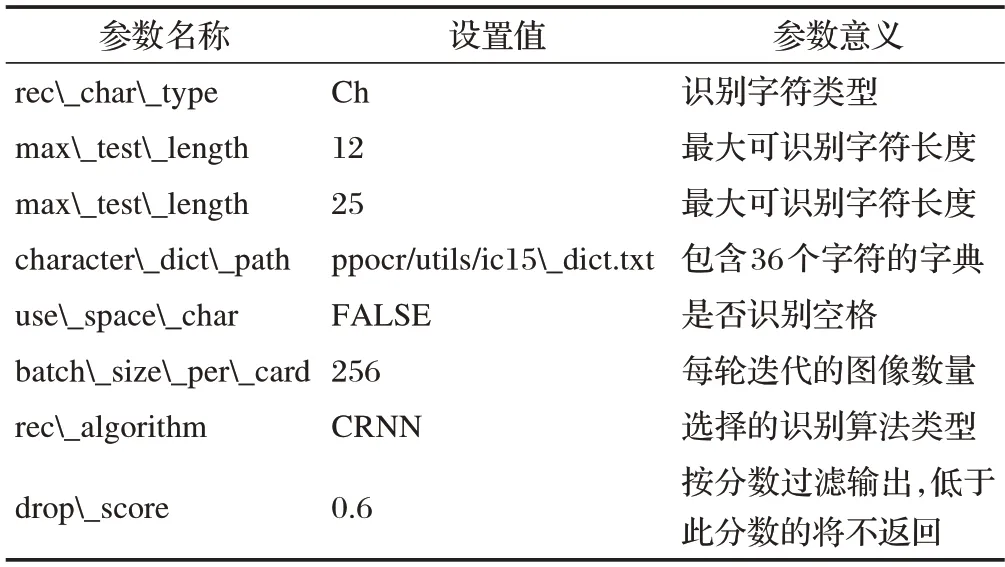
表2 牛耳标文本识别参数设置
3.2 实验结果
本实验运行在ubuntu16.04 系统上,使用的编程语言是Python,深度学习的环境使用PaddlePaddle,CUDA版本为9.0。训练程序时使用的显卡为NVIDIA GTX2080Ti×2,显存为32G,测试程序时在保证CPU和内存基本为空的情况下测试(为了准确测试时间)。
本文的牛耳标文本检测采用DB 算法,通过扫描输入的耳标图像,设置阈值来判断每一个像素是否属于文字区域,进而完成文本定位。图6 展示了牛耳标图像文本检测的效果。绿框部分表示DB 算法检测出的文本,并把文本从耳标图像中分割出来,形成右边对应的文本行图片。算法对像素的扫描顺序为从左至右,从上至下。

图6 牛耳标文本检测结果
检测框校正是对文本检测后分割出的文本行部分进行角度校正的操作。在现实场景下,有较大可能性会出现文字颠倒的情况,使用检测框校正可以有效地提高文本识别的准确率。检测框校正采用一个方向分类器将文本行部分进行0 和180 度的角度分类,其中,180度的文字行图片会被旋转操作实现转正。
输入牛耳标图像,在经过检测网络后,将其输入到识别网络,可以得到牛耳标识别结果,从图7 可以看到,在识别结果中,标出了牛耳标数字的具体坐标以及每个坐标的ID 识别结果、识别置信度和识别所用时间。

图7 牛耳标识别结果
分别对原始牛耳标图像和腐蚀膨胀后的耳标图像进行耳标识别测试,测试结果如表3。

表3 牛耳标图像文本识别结果
4 结束语
本文介绍了使用牛耳标进行牛个体识别的整体思路,文本检测器、文本方向检测器和文本识别器的网络结构。接下来介绍了对牛耳标图像预处理及其原理,使用腐蚀膨胀处理提高图像的可识别性。在针对耳标场景设置好实验的超参数后对耳标原图像和腐蚀膨胀后的图像分别进行了测试,最后展示了测试结果,证明了本课题使用的预处理方法可以提高牛耳标图像的识别准确率。
