基于BERT-BiLSTM-CRF 的网络敏感词及变体实体识别∗
2023-10-20郑贤茹李柏岩冯珍妮刘晓强
郑贤茹 李柏岩 冯珍妮 刘晓强
(东华大学计算机科学与技术学院 上海 201620)
1 引言
近年来,随着信息技术的高速发展,我国互联网普及率迅速提高。与此同时,用户的大量增长也带来了互联网信息的急剧膨胀,一些不法分子出于各种目的,往往会在Web网页上发布包含有暴恐反动和低俗辱骂等不良信息。为了躲避相关部门的审查,其发布者往往会使用“火星文”的形式,将敏感信息通过繁体化、字形拆分、首字母缩写、谐音变换等各种变体来替代原来的词,例如,“法轮功”变形成如“法輪功”、“三去车仑工力”,“FLG”“发论功”等形式,这样既可以逃避系统的审查又可以顺利传达出其要表达的信息。这类敏感词变体往往会导致传统检测方法失效,因此,准确检测敏感词及其各种变体,净化网络环境,成为一个亟待解决的研究课题。
敏感词变体种类繁多[1],由于其产生规则各异,相应的处理方法也互不相同[1~2],缺少一种能够统一检测、识别各种敏感词变体的方法。近年来,基于深度学习的命名实体识别(Named Entity Recognition,NER)技术在自然语言处理领域取得了显著进展[3~5],为敏感词变体识别提供了一种新的有效途径。本文将敏感词及变体作为实体识别的目标,标注了包含敏感词及变体的实体识别数据集,提出了结合中文预训练模型BERT 的敏感词命名实体识别方法,使用BERT-BiLSTM-CRF 框架对网页上多种敏感词变体进行端到端的统一检测。通过与现有方法的比较,本文所提出的模型在标注的语料库上取得了较好的效果。
2 相关工作
最早的敏感词识别方法主要是敏感词表匹配法,这种基于字符串匹配的方法能够快速有效找到文本中的敏感词[6]。该类方法技术实现简单但扩展性不强,需要动态更新敏感词词典。对此,文献[7]提出的ST-DFA 算法对传统DFA 算法改进,当敏感词语料库发生更新时可实时更新决策树进行多次检测过滤,但该方法对敏感词的变形体检测准确率不高。在敏感词变形体检测方面,文献[8~10]提出了一种基于变体识别的敏感词相似度计算方法。文献[11]提出了一种基于决策树的敏感词识别算法。这些方法虽然在一定程度上能达到检测出敏感词及变形体的目的,但计算较为复杂,随着敏感词及其变体数量的增大,检测时间变长,难以实际应用。
由于传统算法在敏感词及变体识别上存在一定缺陷,部分学者开始将文本敏感信息检测看作命名实体识别任务展开研究。文献[12~13]提出了一种面向安全漏洞领域的命名实体识别方法,文献[14~16]针对通用领域模型无法有效解决信息安全领域的实体识别问题提出一种BiLSTM-CRF 模型。借鉴这些成果,本文通过人工标记低俗辱骂类敏感文本数据集和构建命名实体识别模型,为网页中相关敏感词及变体的识别提出了一种更有效的解决方案。
3 敏感词变体分析及处理方法
3.1 敏感词变形体
通过对互联网中出现的各种敏感词变体进行分析可以发现,尽管这些变形体形式上变化多端,但主要生成方法大致可分为以下几类。
1)用特殊字符产生变体
含有特殊字符的敏感词变形体分为两种情况:1)字符起填充作用,比如在“法轮功”这个敏感词之间插入非中文字符形成变形敏感词“法/轮/功”。2)字符起替代作用,比如用“*”替代“法轮大法”一词中的某个字形成变形敏感词“法轮*法”等。
2)利用语音相似产生变体
汉字一般由声母、韵母和声调三部分组,一音多字。利用汉字的发音相似性,可以把敏感词用相似语音的词或拼音字母替代。发音替换并不是任意的,而是有一定的规则,根据网络统计,常用的是改变字符的初始辅音或最终音节,如图1所示。
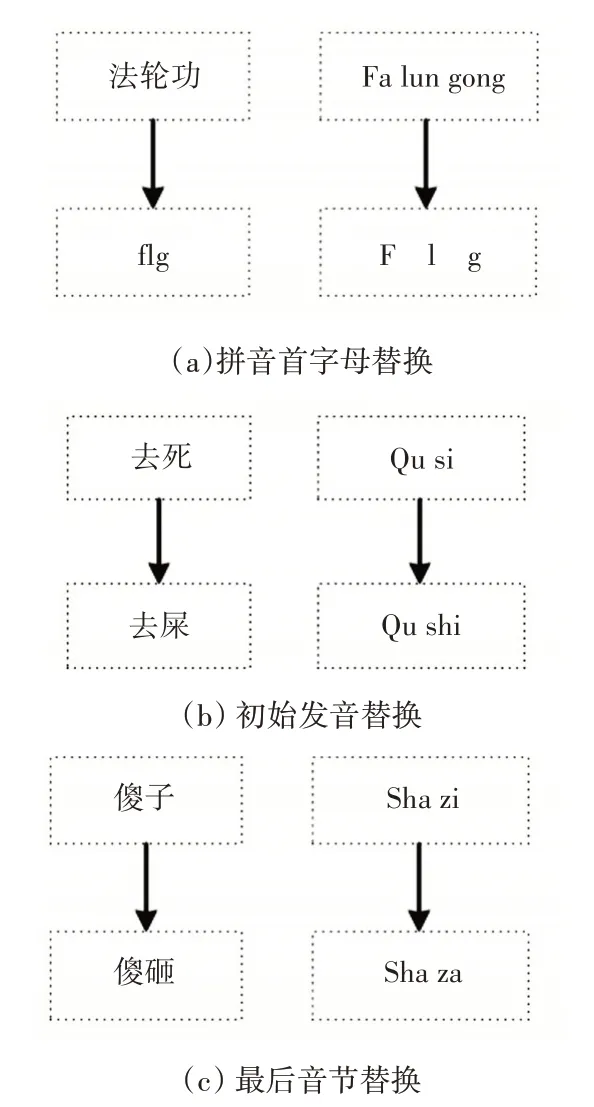
图1 语音相似敏感词变体常用替换方法
3)利用汉字的结构产生变体
汉字依其构成单位可分为独体字和合体字两大类。通常来说,敏感词结构拆分类的变体会选择符合汉字组成规则的合体字,根据偏旁部首等进行单个字符拆解,如将“抵押贷款”拆成“扌氐扌甲贷款”。
3.2 敏感词变体的处理方法
与基于字符匹配的检测方法不同,本文不根据变体产生的规则来识别,而是利用敏感词变体的各种产生规则直接生成该敏感词各种常见的变体,将这种工具称为敏感词变体生成器,然后用这些生成的变体在语料集中替换该敏感词,扩充语料集,进行数据增强,最后用增强后的训练语料集对模型进行训练。生成器首先维护一个敏感词字典集,在添加新敏感词的时候,选择适合该敏感词的各种生成规则。敏感词的生成规则大致有如下几种。
1)特殊字符变形体
规则1:在敏感词中插入特殊符号,常用符号有“/”、“”、“-”和“%”等。
规则2:用计算机中常用的通配符“*”对敏感词部分文字进行替换。如“法轮大法→法轮*法”。
2)语音相似变形体
规则3:用敏感词的拼音首字母生成变体,如“法轮功→flg”、“他妈的→tmd”。
规则4:利用同音字生成敏感词变体,选择其中常见的组合,如“发轮功”、“他妈滴”。
3)字形变形体
规则5:用繁体字生成变体,如“法轮功→法輪功”。
规则6:用字形拆分生成变体,如“法轮功→三去轮功|三去车仑功|三去车仑工力”。
3.3 敏感词检测模型
本文把敏感词及变体看成一种领域内的特殊实体,利用NER 技术可以准确高效地识别文本中的敏感词实体,相较于一般的字符串匹配和计算相似度等方法,在处理敏感词集的规模和速度上有较明显的优势。本文所构建的敏感词命名实体识别模型BERT-BiLSTM-CRF 的框架如图2 所示。模型在结构上大体分三部分:预训练模型BERT、双向长短时记忆网络模型BiLSTM 和条件随机场模型CRF。首先对标注好并经过数据增强的敏感词训练语料集,使用预训练模型BERT 获取含有语义信息的向量表示,然后将得到的向量输入到BiLSTM模块做特征提取,以捕获文本序列的特征表征,最终由CRF模块结合上下文序列标签的相关性,对各个实体进行提取分类,输出最终的标记序列。
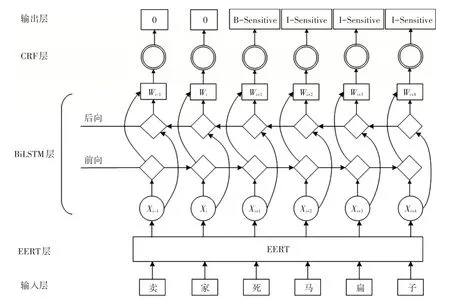
图2 BERT-BiLSTM-CRF模型框架
鉴于敏感词的复杂形态,一般分词工具不可能将这些词准确切分到一起,因此本文对输入文本不做切分处理,而将单个汉字看作独立的单位,提取其丰富特征。由于Word2Vec在处理多义词上具有较大的局限性,故本文选择能根据语境动态输出词向量的BERT模型来向量化输入文本。Google的中文BERT-Base 模型的隐藏层是768 维,有12 层Transformer,对每个词进行3 个嵌入,分别是Token Embeddings、Segment Embeddings 和Position Embeddings。一段长度为n 的输入文本分别经过三个嵌入后,将所得的三个向量表示求和,生成的张量作为输入表示传递给BERT 的编码器层进行特征提取。编码器Transformer 是一个基于自注意力机制的深度网络,由6 个同构层构成,每个层由两个子层组成,分别为多头自注意力层和全连接前馈神经网络。全连接前馈网络的两层激活函数分别是ReLU 和一个线性激活函数,在每个子层后使用一次残差连接,并进行层归一化。
BiLSTM 模块作为BERT 的下游任务负责进一步获取文本序列的特征和语义信息。它由前向LSTM 与后向LSTM 组合而成,可以结合语料从前到后和从后向前的两部分信息,更好地捕捉一段文本双向的语义依赖关系。它接受经由BERT 处理后的向量化输入,输出包含敏感文本正向和逆向语句的序列状态信息。在敏感文本中,BiLSTM 可以通过前向和后向的组合信息提取敏感文本的丰富特征,进而准确识别出敏感词及变体所在。
经过BiLSTM 层处理后,模型能够输出每个字对应各个标签的分数,这些分数将作为CRF层的输入,分数数值越大表示越有可能预测为对应的标签。BiLSTM 层只考虑了含有上下文信息的字向量而忽略了标签之间可能存在的关系,例如在标注数据时,一般不存在诸如I作为开头的词、两个连续的B 等一些情况,因此CRF 层的作用主要就是通过学习标签之间的约束和依赖关系来修正BiLSTM层的输出以保证预测标签的合理性。
4 实验及结果分析
4.1 数据集
由于网络上公开的敏感词语料集很少,本文使用的语料由作者自己收集,其中很大一部分语料是从淘宝产品评论(http://detail.tmall.com)中爬取,并经过手工筛选得到。数据集中人工标注的包含敏感词及变体的文本数据共5000 条,再利用敏感词变体生成器扩充语料,生成用于训练模型的语料集。在收集到满足要求的语料集之后,需要对这些语料进行实体标注。命名实体识别任务常用的标注体系有BIO、BIOE 及BIOES 等,本文采用BIO,它要求输入的每行只包含单字、空格和该字对应的标签,最终得到的语料标注形式如图3 所示。图中,标签B 代表B-sensitive,即敏感词的开始部分;I 代表I-sensitive,即敏感词的中间部分;O 代表Other,即文本的其他非敏感无关字符。准备好数据集之后,将数据集按照8∶1∶1 的比例划分为训练集、测试集和验证集,输入到模型中进行训练。

图3 语料标注的最终格式示例
4.2 实验环境与评价指标
本文的实验在Linux 操作系统环境下进行,支持软件版本为Python 3.6、Tensorflow 1.13.1。执行训 练 的 服 务 器CPU 为Intel(R)Xeon(R)Silver 4208,64G内存,GPU为4核GTX2080Ti。
为验证使用BERT-BiLSTM-CRF 模型对敏感词及变体检测的可行性和准确性,本文采用召回率R、精准率P 和F1 值来评判模型的性能,各评价指标的计算方法如下:
其中,s 是识别正确的敏感词实体数,X 是实际所有敏感词实体数,Y是识别出的实体数。
4.3 实验结果及对比
为了使模型具有更好的效果,在训练过程中需要不断进行参数调整优化,经过反复的训练实验后,模型训练主要参数设置如下:learning_rate:0.00002,max_seq_length:500,batch_size:2,bilstm_size:128,drop_out:0.5,模型训练采用Adam 优化器、交叉熵损失函数,实验采用在预训练语言模型BERT 上做微调(Fine-tuning)的训练方式,利用BERT 提取敏感词变体的结构特征,这样既可以使训练的收敛速度更快,也能确保模型在较少的训练样本上也能取得不错的效果。
根据上述参数设置,对模型进行训练的实验结果如表1 所示。为了证实所提出模型的有效性,本文在同一标注数据集上分别训练了BiLSTM 和BiLSTM-CRF 模型。从表中可以看出,BiLSTM-CRF模型在精准率、召回率和F1 值上均优于BiLSTM 方法,这是因为BiLSTM 模型虽然能根据目标实体自动提取文本序列特征,却无法学习到输出的标签之间的约束条件和依赖关系,从而影响模型效果。BERT-BiLSTM-CRF模型则既兼具了BiLSTM-CRF模型的优点又在此基础上对文本向量化过程加以改进,利用预训练语言模型BERT 的优势自动提取文本序列丰富的语义特征、词级特征和语法结构特征,因此对敏感词变体的实体识别效果明显优于其他两个模型,精准率、召回率和F1 值分别达到了95.00%,92.68%和93.83。
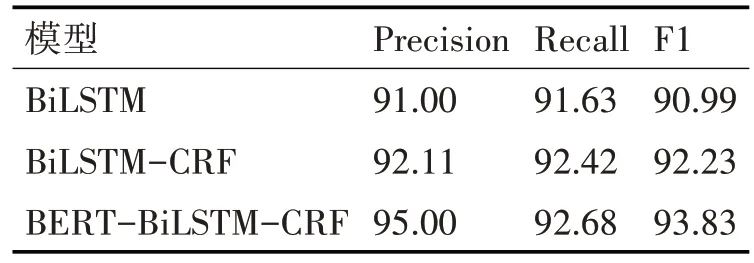
表1 不同模型结果比较(%)
5 结语
敏感词及其变体检测是过滤网络信息内容、清洁网络环境的一个重要手段。而敏感词变体层出不穷,变化多端也为这项工作不断提出新的挑战,因此,找到一种检测速度快,准确率高、扩展能力强,并能适应多种敏感词变体的检测方法十分必要。本文利用深度学习命名实体识别技术的最新成果,提出了基于BERT-BiLSTM-CRF 敏感词及变体的检测模型,把敏感词及其变体的检测,转换成命名实体的识别问题,把匹配复杂多样变体的问题,转换为针对包含敏感词语料的数据增强。实验结果表明,本文提出的方法,检测速度快,准确率高,可扩展性强,而且不需要敏感词及其变体字典的在线支持。本文将BERT-BiLSTM-CRF 模型与BiLSTM 和BiLSTM-CRF 模型在同一标注数据集上进行了对比实验,精准率、召回率和F1 值都有显著提高,证明其效果显著。然而由于敏感词的变体特征多样,含义隐晦,本文标注的语料库仍有不足,且尚未覆盖一些文本色情、暴恐反动、政治敏感等语料,今后将继续扩充数据集并增加标注不同种类的敏感文本及变体数据,进一步扩展模型的识别范围。
