面向大规模AI 数据流的可靠接入研究∗
2023-10-20王季喜陈庆奎
王季喜 陈庆奎
(上海理工大学光电信息与计算机工程学院 上海 200093)
1 引言
随着物联网[1]应用的快速发展,大规模终端设备收集的数据远远超过了传统网络应用通信量,云计算[2-4]中心已无法承担规模庞大的终端设备数据接入、处理和存储等任务。近年来,人工智能[5]技术加速落地,硬件厂商们各自推出具有一定计算能力的终端设备,如Jetson Nano 等。物联网由“万物互联”向“万物智联”时代发展,“云-边-端”三体协同的边缘计算[6~8]架构应时而生。这种架构将数据的接入和处理放在靠近终端设备的边缘集群,不仅能够减轻云计算中心的带宽压力,而且还能减少数据的传输延时,加快服务的响应速度。
目前,基于视频、图像的AI 任务不仅需要传输大量的数据,还需要较强的设备计算能力。为降低边缘数据中心带宽压力,充分利用终端设备的计算能力,AI 模型分层计算的方法被提出[9~10],即不同计算能力的终端设备执行不同层次的AI 算法。首先,本课题根据终端设备计算能力,将OpenPose 深度学习网络模型[11]拆分为两部分,第一部分部署于智能终端,对采集的视频帧进行AI 任务预处理生成中间结果,称为AI 数据单元,同一终端设备基于时间序列生成的AI 数据单元形成一路AI 数据流;智能终端进行视频帧采集、AI 预处理和发送需要的时间为轮转周期,不同处理能力的终端设备生成的AI 数据流具有不同的轮转周期。其次,设计AI数据流并发接入模型,将数以千计的AI 数据流进行汇集,形成矩阵形式的并发AI 数据流,并将并发AI 数据流交由GPU 计算集群。最后,GPU 计算服务器执行分层模型的第二部分,对AI 数据流进行深入特征提取,完成相应的AI 任务。本课题设计最终用于某养老照护机构,对老人姿态进行识别,及时对老人摔倒动作发出报警。
关于智能终端AI任务模型预分层和GPU 服务器集群内AI 任务分发调度的相关工作,已有课题组其他成员进行研究并另行刊发。本文承担大规模AI 数据流并发接入工作,对大规模并发AI 数据流高可靠接入和接入服务器并发量进行研究,并向GPU 计算服务器对相同轮转周期并发AI 数据流的SPMD(Single Program Multiple Data)计算[12]提供技术支持。
2 相关工作
人工智能的边缘化,促进了智能终端设备的发展。以实时视频分析为例,终端设备周期性工作原理使得预处理得到的AI 数据流具有很强的周期性特征。随着终端设备规模的扩大,不同轮转周期的AI 数据流线性涌入远端GPU 计算服务器,严重影响GPU 计算节点的SPMD 计算性能。针对以上挑战,提高边缘服务器对大规模AI 数据流的并发接收能力,并支撑GPU 的SPMD 高效计算成为问题的关键。
目前,针对大规模AI 数据流的相关研究较少,而研究人员对流式数据的普遍研究,大多集中于流式数据传输协议和数据接入可靠性。如文献[13]设计了灵活的双TCP-UDP 流协议FDSP(Dual TCP-UDP Streaming Protocol,FDSP),将TCP的可靠性与UDP 的低延迟相结合,使用TCP 传输流数据的关键部分,其余部分通过UDP 传输。文献[14]提出数据流分割处理模型,将数据流分为正常数据流和延迟数据流,在对无序数据的延迟和处理结果正确性之间进行权衡,以求提高流数据处理结果可靠性。文献[15]设计了数据中心网络虚拟化架构SecondNet,通过在服务器管理程序中分发所有虚拟到物理的映射、路由和带宽保留状态等,以保证数据接入带宽。
基于前人的研究成果,本文针对大规模AI 数据流并发接入场景,设计基于UDP 的AI 数据流通信协议和高可靠旁路控制机制,从物理线路上隔离数据通道和控制通道,大大提高了并行通信的效率,满足AI 数据流对接入系统的实时高可靠要求。同时,采用基于AI 数据单元的组确认通信机制,大大减少了通信确认造成的额外开销。最后,设计AI数据流周期同步机制以支撑GPU 服务器的SPMD高效计算。
3 系统模型与算法
3.1 AI数据流通信协议
在大规模AI 数据流接入系统中,AI 数据流的特征取决于前端设备的物理特性和计算能力。为方便对AI 数据流通信协议进行设计,现给出如下定 义:AI 数 据 单 元 为U(S_Id,S_Period,TIMESTAMP)。其中,S_Id 指AI 数据单元所属数据流编号,S_Period 指AI 数据单元对应轮转周期,TIMESTAMP表示AI数据单元生成时间。AI数据流US={U1,…,Ut},Ut表示t 时刻生成的AI 数据单元。数以千记的AI 数据流组成并发AI 数据流USS={US1,US2,…}。
在边缘计算场景中,AI 分层计算产生的AI 数据单元为大量浮点数组成的数字矩阵,传统通信技术往往需要对数字矩阵进行文件形式转换,不适用于数字矩阵的传输。为此,本文设计基于UDP 消息的AI 数据流传输协议。由于底层以太网帧长度的限制,本文设计大小为750B 的AI 数据流消息包格式。如图1 所示,每一个消息包中都包含有Dst_Ip(接入服务器地址),Src_Ip(终端设备地址),TIMESTAMP(数据单元时间戳),Pkt_Num(单元内分片编号),Seg_Len(数据长度)以及AI 数据流头部的S_Id(数据流编号),S_Period(轮转周期)。本文规定Pkt_Num 为0 的数据包表示对应AI 数据单元的结束包,该数据包数据部分只携带对应AI 数据单元分片总数total_num,用于系统进行基于AI数据单元的组确认通信机制。
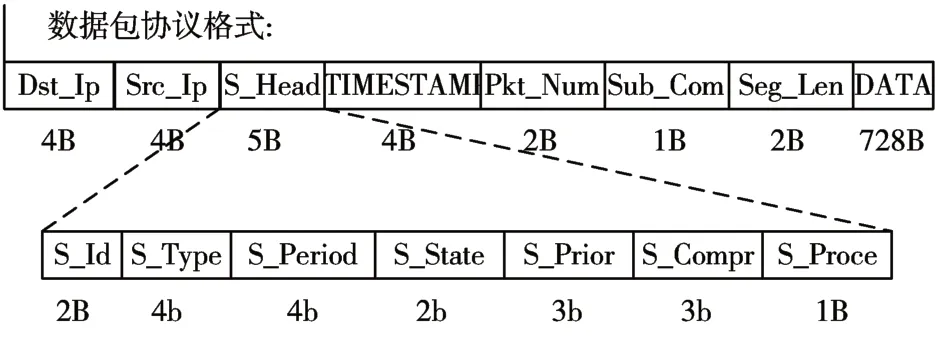
图1 数据包协议格式
3.2 旁路控制机制与组确认通信
3.2.1 旁路控制机制
采用UDP 的AI 数据流通信协议设计,克服了基于连接的可靠通信机制占用通信资源的缺点,大大提高边缘服务器集群的并发接入能力。但考虑到UDP 的不可靠特性,不能保证AI 数据流可靠性的并发接入系统势必会影响后端GPU 计算服务器的AI分层计算任务。为提高AI数据单元的交付成功率,本文设计基于双消息队列的旁路控制机制,该机制独立于AI 数据流通道,通过旁路控制机制的专有物理网口和通信线路,终端设备、接入服务器和GPU 计算服务器可以进行控制类型消息传输。
如图2 所示,本文设计通用控制包格式,并对重传控制包进行详细设计。每一个控制包都含有Flag(目的消息队列标识),SRC_IP(控制包源地址),DES_IP(控制包目的地址),COM_TYPE(命令类型),LC(生存周期),COM_STATE(控制包状态)。 其中,LC 生存周期为正整数类型;COM_STATE 为1 表示控制包已发送,COM_STATE为2 表示对应控制包的确认包;重传控制包DATA域指明发生丢包的AI 数据单元对应的源智能终端信息,Rtr_Pkt_N 指明对应AI 数据单元丢包个数,对应Data 域每两个字节标识一个丢失数据包在AI数据单元内编号。

图2 控制包协议格式
如图4 所示,通过独立交换机将各设备控制端口进行旁路连接,数据包和控制消息将通过独立的物理线路进行并行传输。标号1-4 表示控制包通信过程,譬如当AI 数据单元发生数据包丢失(数据包丢失检测机制将在3.2.2 节进行描述),对应接收线程Recv2 生成重传控制包,控制进程Ctr2 解析重传控制包DST_IP 域,将重传包发送至对应终端设备控制端口;终端控制进程Ctr1 收到重传包后,根据Flag字段将其放入目标消息队列,并向Ctr2发送相应重传确认包;终端设备Recv1 线程解析重传包,查找对应重传缓冲区进行AI 数据单元丢失包的重传。在旁路控制机制中,控制进程维持控制包条目表(如图3 所示),根据条目表执行如下控制包确认算法:

图3 控制包条目格式
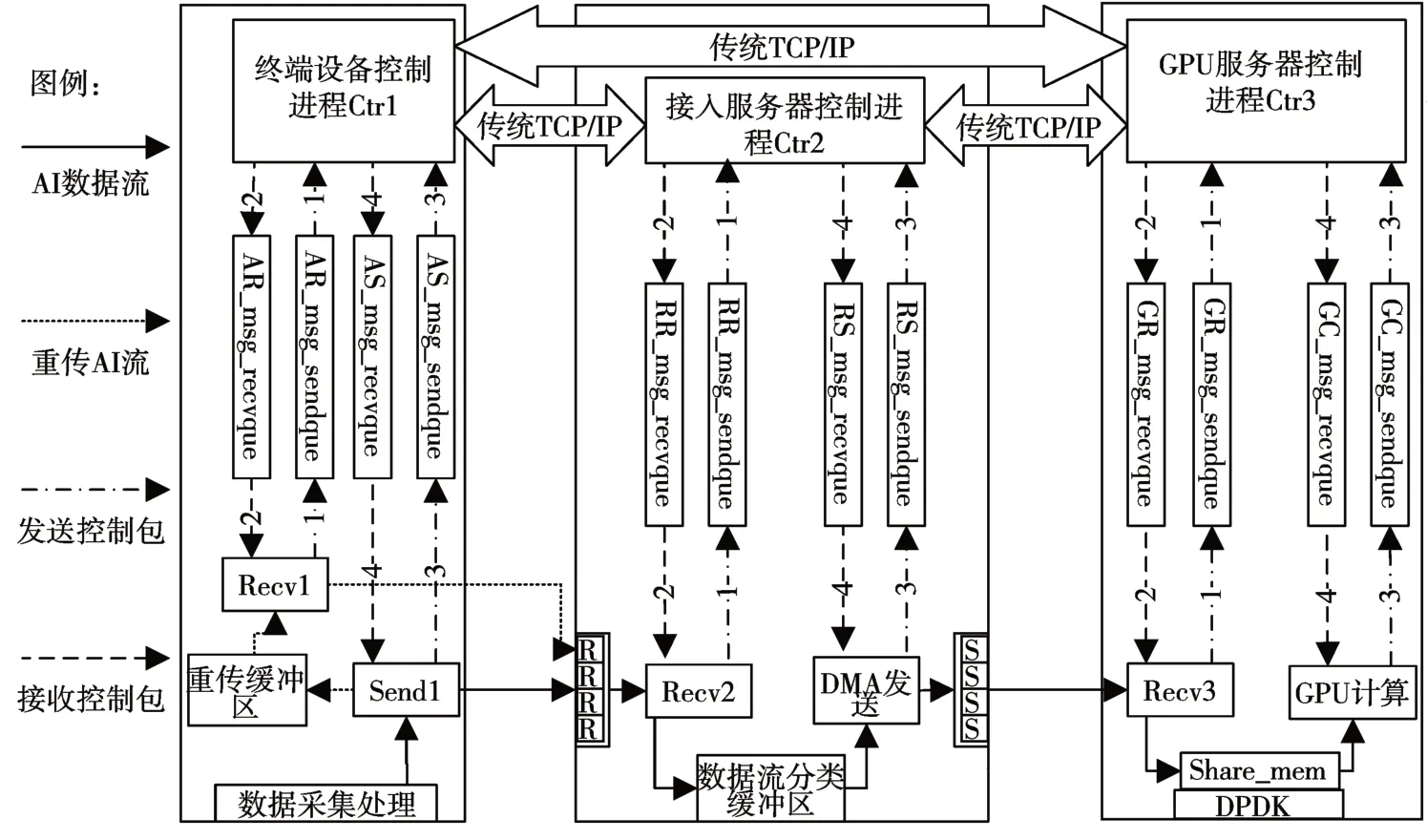
图4 集群旁路控制机制
算法1:控制机制确认算法
Start
Step 1:发送控制包
控制进程转发消息队列中的控制包
向控制包条目表添加对应控制包条目,新表项buffer指针指向该控制包缓冲区,在未收到确认时对控制包重传
丢弃超时(LC大于设定值)的控制包条目
重传未超时且未收到确认(条目表COM_STATE==1)的控制包,重传的控制包LC++
Step 2:接收控制包
解析控制包命令状态COM_STATE
If:COM_STATE==2 then
修改对应控制包条目表COM_STATE为2
Else:COM_STATE==1 then
控制进程解析控制包,进行相关操作
并向对端发送对应控制包确认
End
3.2.2 流周期同步模型与组确认通信
前面提到大规模不同轮转周期的AI 数据流线性涌入GPU 服务器,大大降低了GPU 服务器的SPMD 计算性能。如图5 所示,在AI 数据流并发接入的基础上,本文提出AI 流周期同步模型,以支撑GPU 服务器对不同轮转周期AI 数据流的SPMD 计算;并采用基于AI 数据单元的组确认通信机制,减少了通信确认造成的额外开销。

图5 AI流周期同步机制
如图5所示,针对不同轮转周期的AI数据流设置不同数据流分类缓冲区,DMA(Direct Memory Access直接内存存取)[16]发送机制将具有相同轮转周期的并发AI 数据流交由GPU 集群进行后续AI分层计算任务。在多端口进行AI 数据流并发接入过程中,接收线程组Recv2 和DMA 发送机制共享数据流分类缓冲区。在每个数据流分类缓冲区(矩阵形式)中,每行存储一条AI 数据流,每列表示该一个时间周期内同一轮转周期AI 数据流的数据单元,每个数据单元包含一组单元内数据包。当服务器有新的AI 数据流接入时,对应的流分类缓冲区动态的纵向扩展,若接收的数据包来自下一个周期,流分类缓冲区将动态进行横向扩展。在数据流分类缓冲区中,虚线框中的并发AI数据流,即DMA发送线程单次发送单位。DMA 发送机制将并发AI数据流转发至GPU 服务器集群,支撑GPU 服务器高效计算。
针对数据包丢失问题,终端设备会对AI 单元进行缓存。不同于滑动窗口严格可靠机制,为保证AI 数据流的实时性,终端设备采用环形缓冲区,只保持规定时间内的AI 数据单元,若收到AI 数据单元的重传包,则进行相应AI 数据单元丢包重传。在图5 中,校验矩阵对应数据流分类缓冲区,每一个存储单元记录对应AI 数据单元收包总数recv_num 和各数据包标志位flag,用于对AI 数据单元进行组确认。基于AI 数据单元的组确认通信和数据流周期同步机制算法如下:
算法2:数据单元组确认与流周期同步机制
Start
Step 1:接收数据包
从网卡接收数据包
解析数据包,获取单元内编号pkt_num
If:pkt_num==0 then
goto Step 2
Else:
goto Step 3
Step 2:数据包为数据单元结束包
解析数据单元包总数total_num
从校验矩阵获取数据单元收包总数recv_num
If:total_num==recv_num then
goto Step 4
Else:
对丢包AI数据单元进行丢包重传
Step 3:数据包非AI数据单元结束包
解析S_Period,将数据包缓存至对应流分类缓冲区
校验矩阵对应数据包标志位flag 由0 为1,对应AI 数据单元recv_num++
Step 4:DMA机制发送流分类缓冲区并行AI数据流
If:定时器到时
发送未丢包的并发AI数据流
丢弃并发数据流内丢包的AI 数据单元Uk,修正对应轮转周期k的AI数据单元丢弃总量Ndrop_Uk
修正对应轮转周期k 的AI 数据单元丢包总量Ndrop_P_Uk
Else:
对丢包AI数据单元进行丢包重传
End
4 实验
4.1 实验环境
为验证本文并发接入模型性能,本文选用实验室主机作为接入服务器节点,其配置信息如表1 所示。

表1 接入服务器配置信息
为模拟大规模并发AI 数据流,我们利用两台配备图像采集设备的Jetson Nano开发板,周期性进行实时图像采集和AI 预处理,生成两路真实AI 数据流。另采用10台计算机多线程周期性发送Nano开发板预处理获得的AI 数据单元,模拟其余并发AI数据流。每台模拟机详细配置信息如表2所示。

表2 模拟机配置信息
4.2 评估指标
根据对Nano 开发板前期实验可得,本实验中Nano采用27层AI分层模型I可在轮转周期为1s内完成图像采集、AI 预处理和周期性发送任务。经过OpenPose分层模型预处理后的AI数据单元大小约为672KB,采用前文所设计AI 数据包大小,实验中单个AI 数据单元将被封装成957 个AI 数据包。假定发送AI 数据单元周期数为T,单个周期AI 数据单元并发量为N,通过对丢包率、数据单元丢弃率的分析,对本系统的并发接入能力和可靠性进行评估。
丢包率DPR 是指连续发送周期T 内AI 数据流丢包总量占数据流包总数的比例,数据单元丢弃率UDR指周期T内AI数据单元丢弃数量占并发AI数据流总数据单元数量的比率。以上指标可以对接入系统并发能力和旁路控制机制性能进行评估。
4.3 实验结果与分析
首先,我们对并发接入系统的旁路控制机制可靠性进行测试。该测试中采用单节点单张网卡进行数据流接入,使用Nano 开发板和模拟机模拟单位时间内不同并发量的AI 数据单元,每次发送周期T 取100s,进行多次实验对周期T 内的丢包率DPR、数据单元丢弃率UDR取平均值。
如图6(a)所示,节点单张网卡接入不同数量的AI 数据单元,计算丢包率DPR 随单位时间内发送数据包总量的动态变化。可以看出,当单位时间内数据单元并发量达到90,对应数据包数量为86130时,传统UDP 通信已出现包丢失现象;而本文旁路控制通信方案在AI数据单元并发量接近120,对应数据包数量为114840 时,才出现包丢失现象。通过对比发现,在不发生数据包丢失情况下,本文通信方案比传统UDP 通信单端口通信性能提升约30%。同时,本文也对数据单元丢弃率UDR进行统计分析。如图6(b)所示,在AI 数据流并发量低于120 时,本文旁路控制通信方案未出现数据单元丢弃情况,而传统UDP 通信方案已发生严重数据单元丢弃。对比图6(a)和图6(b)可知,丢包率对数据单元丢弃具有一定影响,而本文的旁路控制机制可以及时地对AI 数据单元进行组确认重传,以降低数据单元丢弃率。
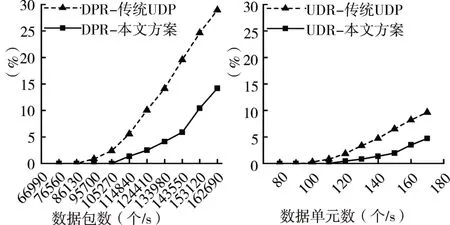
图6 单节点单张网卡的DPR和UDR
此外,我们也对接入系统进行了扩展,测试旁路控制机制在扩展后的系统中对系统性能的影响。该测试将单节点网卡数量扩展到了4 张,单次实验模拟机发送周期T 仍取100s,节点各网卡接入AI数据单元并发量相同。进行多次实验,对周期T内节点的丢包率DPR、数据单元丢弃率UDR 取平均值。
如图7所示,通过不断增加并发AI数据单元数量,可以看到,当节点AI数据单元并发量超过360,对应数据包量为344520 时,节点丢包率DPR 开始加速上升。在各网卡平均数据单元并发量为170时,与单节点单网卡实验相比,UDP 通信方案丢包率增加了5%,AI数据单元丢弃率也随之增加,这表明随着接入并发AI 数据流规模的不断扩大,传统UDP通信在性能上下降明显;而本文旁通信方案丢包率和AI 数据单元丢弃率相对稳定,未对系统性能造成较大的影响。
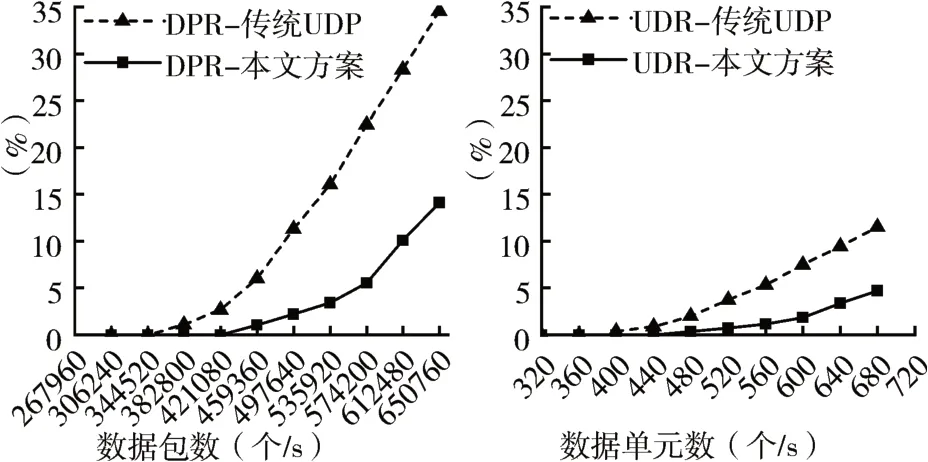
图7 单节点四张网卡的DPR和UDR
5 结语
针对大规模AI 数据流周期性并发接入问题,本文设计基于UDP的AI数据流通信协议和独立于数据包通道的旁路控制机制,以满足AI 数据流实时高可靠性要求,降低高并发AI 数据流丢包率,并支撑GPU 服务器SPMD 高效计算。实验结果表明,在无数据包丢失情况下,利用本文旁路控制机制,节点单网卡AI 数据单元并发量可提升约30%。特别地,接入网卡的扩展并未影响旁路控制机制性能,这对未来大规模智能终端AI 分层计算任务进行边缘汇集的研究具有重大实际意义。未来将对多核多端口并发接入过程CPU 核休眠机制进行研究,以求降低核无效运行时间,提高CPU 资源利用率。
