基于卷积神经网络的图像风格迁移研究
2023-10-19陈杰
陈 杰
(中国联合网络通信集团有限公司宣城市分公司,安徽 宣城 242099)
图像风格迁移是指将艺术大师的画风迁移到自己的图片上,使其看上去更富有艺术气息。近年来,图像风格迁移成为计算机视觉以及图像处理领域的热点研究方向。早期的风格迁移被视为纹理合成的拓展问题,也被称为纹理迁移。在基于纹理合成的年代,Julesz[1]率先提出基于纹理建模来提取图片特征的方法。该方法基于像素的底层特征,没有考虑到语义信息的丢失,所以迁移的效果并不理想。后来,风格迁移进入了基于非真实感渲染的年代,大体可以分为3种:笔触渲染的方法(Stroke-based Rendering)、基于图像类比的方法(Image Analogy)、基于图像滤波的方法(Image Filtering)。基于笔触渲染的方法有一个缺陷,在设计之前需要先将风格特征确定下来,如果迁移完成后进行其他风格的迁移,还需要重新设计一种风格;基于图像类比的方法要在真实场景中采集成对的图像数据,过程十分困难,几乎是不可能的;基于图像滤波的方法具有速度快、效果稳定的优点,能够满足工业界落地的需要,然而滤波器的值是由算法工程师不断调整得出来的,费时费力,且模拟出来的风格类型也有限。所以,这些方法并没有得到大规模的应用。
随着深度学习兴起,卷积神经网络(Convolutional Neural Networks,CNN)被应用到图像风格迁移上。Gatys[2]最早提出利用卷积神经网络,将图像表示为内容和风格两个部分,高层次卷积提取图像的内容特征,低层次卷积提取图像的风格特征,生成让人比较满意的艺术风格图片,在速度以及质量等方面也比传统方法更好。随后,孙劲光等[3]在残差式神经网络的基础上进行图像细节的风格化,但没有对风格迁移的转换网络进行研究。因此,本文在卷积神经网络的基础上加入注意力机制,以期达到更好的风格迁移效果。
1 卷积神经网络
CNN是一种带有卷积层计算的前馈神经网络,是深度学习(Deep Learning)的代表性算法之一[4],本质是一个多层感知机[5]。它在对图像进行处理的过程中采用了局部连接和权值共享的方式,一方面减少了权值数量,让网络优化更加方便,另一个方面降低了网络模型的复杂度,即降低了欠拟合发生的风险。在图像风格迁移领域,卷积神经网络可以更好地提取输入图像的特征以及重建输出图像的内容和风格。使用该网络可以将风格图像的风格特征逐层迁移到内容图像上,并将内容图像的内容特征很好地保留下来。本文选用的卷积神经网络为VGG-16网络,是公认的比较优秀的卷积神经网络。
2 注意力机制
注意力机制来自于人类大脑对事物的注意力[6]。例如,我们的视觉系统会更多地关注图像中一些亮眼的信息,忽略一些看上去无关紧要的信息。在某一时刻,眼睛的焦点只集中在一些相对重要的地方,而不是视野中的所有对象。这样大脑可以有效过滤大量无用的视觉信息,提高视觉系统的识别能力。
在计算机视觉其他领域中,输入图像的某些部分的重要程度的占比会比其他部分更大一些。例如,在图像分类问题中,输入图像中只有一些区域可能与判断出这一图像属于哪一类有作用。注意力模型结合了相关性的概念,允许模型动态地关注输入图片的某些部分。这些部分在执行接下来的任务时会比其他部分更加有利。神经网络中的注意力模型借鉴了该函数,使神经网络模型对输入数据的不同像素点给予不同的注意和权重[7-8]。
注意力机制包括强注意力机制(Hard Attention)、软注意力机制(Soft Attention)、时间注意力机制(Temporal Attention)、空间注意力机制(Spatial Attention)和双通道注意力机制(Convolutional Block Attention Module,CBAM),本文选用双通道注意力机制,并加入卷积神经网络,在通道和空间维度上更加关注目标物体,具有更好的解释性。
将给定的图片F∈RC×H×W作为输入。双通道注意力按顺序推理通道注意映射MC∈RC×I×I和空间注意映射MS∈RI×H×W,整体注意力处理可概括为:
F*=MC(F)⊗F
(1)
F**=MS(F*)⊗F*
(2)
式(1)~(2)中,⊗表示逐元素乘法算子。
通道注意映射是由特征通道之间的关系生成的,把每个通道都视为一个特征检测器,因此更关注给定输入图像中更有意义的部分。为了能有效地计算通道注意力,将特征映射的空间维数进行压缩,并在空间中将信息进行聚合,比较常用的方法是空间信息聚合average-pooling。max-pooling收集关于不同物体特征的另一个重要线索,以推断更详细的通道注意。因此,本文同时使用average-pooling和max-pooling 特征。共享网络由多层感知器(MLP)和1个隐藏层组成,利用特征间的空间关系生成空间注意映射。其通道注意力计算如下:
(3)
与通道注意力机制不同,空间注意力机制更关注图像输入的信息部分。这与通道注意力机制是互补的,空间注意力计算如下:
(4)
整体注意力机制CBAM流程如图1所示。

图1 整体注意力机制CBAM流程
3 转换网络
本文的转换网络由下卷积层与双通道注意力结合的卷积层、残差层以及上卷积层组成。TransformerNet转化网络模型如图2所示。
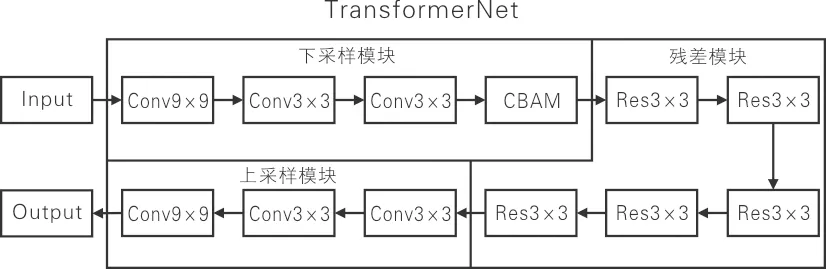
图2 TransformerNet转化网络模型
首先,图片经过3层下采样卷积层,每1个卷积层中都包含1个InstanceNorm2d归一化层以及一个ReLU激活函数层。其中,归一化层主要运用在风格迁移领域。在风格迁移过程中,某张具体的图片实例对迁移结果更具有依赖性。所以,风格迁移不会对整个批次做归一化处理,转而对图片的高(H)以及宽(W)做处理,计算其均值,以加速模型的收敛,并保持每个图像之间的独立性。InstanceNorm2d归一化层的数学公式如下:
(5)
式(5)中,E(x)是batch的均值;Var(x)是batch的方差;ε是常数;γ是对应batch学习到的权重;β是偏置。ReLU激活函数的收敛速度快,不会出现梯度消失的问题。
其次,图片经过5层残差层,每个残差层中包含2个卷积层,每个卷积层的卷积核都是3×3。由于残差网络的特性,图片经过每个残差层的输入以及输出是相等的。残差网络被用来加深网络深度。
最后,图片经过3层上采样层,得到迁移后的结果图。InstanceNorm2d激活函数层的数字公式如下:
(6)
4 风格损失函数
风格迁移的损失函数分为内容损失与风格损失,总的损失函数如下:
Ltotal=αLcontent+βLstyle
(7)
式(7)中,α、β分别代表内容损失与风格损失的权重,本文设置的α/β=1×10-5。
4.1 内容损失
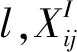
(8)
4.2 风格损失
风格迁移领域的风格损失使用格拉姆矩阵(Gram Matrix)来定义。格拉姆矩阵为:
(9)
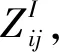
(10)
5 实验结果与分析
5.1 实验环境
本文实验环境为在Ubuntu18.04下和pytorch深度学习框架和在ImageNet上预训练好的VGG-16网络权重。机器的显存为11 GB,CPU为Intel 6×Xeon E5-2678 v3,内存为62 GB,硬盘大小为100 GB,并使用NVIDIA GeForce RTX 2080 Ti进行GPU加速。
5.2 结果分析
数据集选用的是COCO2014的train2014数据集。将加入双通道注意力的结果图与没加双通道注意力的结果图进行比较。风格迁移对比图如图3所示。从图3中可以发现,加入双通道注意力之后的风格迁移更加注重时钟主体部分,并且在颜色的渲染方面也比传统的VGG迁移效果要好一点,显得更加自然。

(a) 内容图片 (b) 原VGG迁移效果
引入峰值信噪比(PSNR)与结构相似比(SSIM)来对结果进行评价:PSNR越大,说明图像的失真越小;SSIM越大说明两幅图像越相似。2种模型的评价指标及网络迭代速度见表1。

表1 2种模型的评价指标及网络迭代速度
从表1可以看出,加入双通道注意力之后,迁移效果有了显著提升,网络迭代速度也比传统VGG16迁移有所提升。
6 结束语
采用了基于卷积神经网络的风格迁移模型,并在此基础上加入双通道注意力机制,达到了更好的风格迁移效果,提高了图片生成的质量与速度,让图片更好地进行主体部分的风格迁移。引入计算机视觉领域常用的评价指标SSIM与PSNR以及2种模型的网络迭代速度进行对比。实验结果表明,迁移效果和网络迭代速度均有所提升。
