基于生成对抗网络与特征融合的多尺度音频序列生成方法
2023-10-18许华杰张勃
许华杰 张勃

摘 要:音频数据规模不足是语音识别过程中的一个常見问题,通过较少的训练数据训练得到的语音识别模型效果难以得到保证。因此,提出一种基于生成对抗网络与特征融合的多尺度音频序列生成方法(multi-scale audio sequence GAN,MAS-GAN),包含多尺度音频序列生成器和真伪—类别判别器。生成器通过3个上采样子网络学习音频序列不同时域和频域的特征,再将不同尺度的特征融合成伪音频序列;判别器通过辅助分类器将生成的伪数据和真实数据区分开,同时指导生成器生成各类别的数据。实验表明,与目前主流的音频序列生成方法相比,所提方法的IS和FID分数分别提高了6.78%和3.75%,可以生成更高质量的音频序列;同时通过在SC09数据集上进行分类实验来评估生成音频序列的质量,所提方法的分类准确率比其他方法高2.3%。
关键词:音频序列生成; 生成对抗网络; 半监督学习; 特征融合
中图分类号:TP391.1 文献标志码:A
文章编号:1001-3695(2023)09-032-2770-05
doi:10.19734/j.issn.1001-3695.2023.01.0018
Multi-scale audio sequence generation method based on
generative adversarial networks and feature fusion
Xu Huajiea,b,c,d, Zhang Boa
(a.College of Computer & Electronic Information, b.Guangxi Key Laboratory of Multimedia Communications & Network Technology, c.Key Laboratory of Parallel, Distributed & Intelligent Computing, d.Guangxi Intelligent Digital Services Research Center of Engineering Technology, Guangxi University, Nanning 530004, China)
Abstract:Insufficient audio data scale is a common problem in the speech recognition process, and it is difficult to guarantee the effect of the speech recognition model trained with less training data. Therefore, this paper proposed a multi-scale audio sequence generation method based on generative confrontation network and feature fusion(MAS-GAN) , which consisted of a multi-scale audio sequence generator and a real/fake-category discriminator. The generator learnt the features of audio sequences in different time and frequency domains through three up-sampling sub-networks, and then fused the features of different scales into pseudo audio sequence. The discriminator distinguished the generated fake data from the real data though the auxiliary classifier, and guided the generator to generate data of various categories. Experiment shows that the IS and FID scores are increased by 6.78% and 3.75% respectively compared with the current mainstream audio sequence generation methods, the proposed method can generate higher quality audio sequences; at the same time, it evaluated the quality of the generated audio sequences by performing classification experiments on the SC09 dataset, the classification accuracy is about 2.3% higher than other methods.
Key words:audio sequence generation; generative adversarial network; semi-supervised learning; feature fusion
0 引言
语音识别是当前计算机声学领域的热点研究问题之一,而音频数据规模不足严重制约了该领域的相关研究工作的展开[1]。通过合成音频数据扩充音频数据集来提高语音识别的效果,是解决这一问题的有效方案之一[2],在人机交互、智慧医疗、安全生产、灾害预警等多各方面具有重要意义。
音频信号具有很高的时间分辨率,学习音频信号的方法必须能在高維空间上有效执行,生成对抗网络(generative adversarial network,GAN)是一种将低维潜在向量映射到高维数据的无监督学习方法[3]。随着研究的深入,一些半监督的生成对抗网络也被提出,如ACGAN[4]在生成对抗网络的基础上增加了辅助分类器,使GAN获得了分类功能从而可以生成特定类别的样本,学习方式由无监督学习变成半监督学习,进而提高生成样本的质量。近年来,生成对抗网络已经成功地应用于各种计算机视觉任务,如超分辨率任务、语义分割等,并且已经被证明在图像生成方面是有效的。而将GAN拓展到音频领域解决数据规模不足问题也是当前机器学习领域的一个热点,如Sahu等人[5]使用合成特征向量来提高分类器在情绪任务上的性能;Chatziagapi等人[6]通过GAN合成声谱图,达到了平衡数据集的目的,与一系列如时域、频域变换的传统数据增强方法相比有较大的性能提升。
目前,使用生成对抗网络来生成音频数据一般有两种做法。一种做法如MelNet[7]等是对音频的时频表示(声谱图)进行操作,这种做法存在不足:由于生成声谱图的分辨率依赖于不同的参数,存在因参数原因导致特征丢失的问题[8];同时,因为感知信息最丰富的声谱图是不可逆的,要将声谱图转换为原始音频序列,必须通过反演模型,而在这一过程中,会丢失大量的音频信息,导致生成的音频序列效果较差[9]。另一种做法是直接采用原始序列进行建模,如WaveGAN[10]是一种将生成对抗网络用于原始波形音频的经典无监督合成方法,能够合成较高质量的且具有全局相关性的音频片段。通过原始音频序列进行建模,直接从原始音频序列中提取特征,减少了由于参数原因导致的特征丢失;同时由于没有从声谱图转换为原始音频序列的过程,所以丢失的音频信息更少,但是这种原始序列的音频生成方法也存在不足:由于音频信号同时包含时域和频域的特征,比图像信号更有可能表现出强周期性,而这种做法通常情况下更关注音频数据的时域特征,忽视了音频数据在频域上的分布情况[11]。
由于采用原始序列进行建模比采用声谱图建模的方式减少了音频特征的丢失,同时WaveGAN是采用原始序列建模的经典无监督学习方法,可以合成较高质量的且具有全局相关性的音频片段,所以本文方法以WaveGAN为基础架构。但是WaveGAN存在只关注时域特征而忽略频域特征的问题。在采样环节,本文借鉴多尺度上采样块的做法,通过不同大小的卷积核提取音频信号时域和频域的不同特征,解决Wave-GAN不能兼顾音频信号时域和频域特征的问题,提升网络对于音频信号的特征提取能力;同时,在音频序列生成环节,本文借鉴辅助分类器的做法,通过构造辅助任务将无监督学习转换为半监督学习以提高生成音频数据的性能,进一步提升生成音频序列的质量。
1 相关工作
生成对抗网络(GAN)能直接生成“以假乱真”的与训练数据非常接近的新数据[12]。ACGAN是GAN的一种拓展,采用辅助分类器(auxiliary classifier)来判断输入图像所属的类别,它不仅在很大程度上解决了GAN模型崩溃的问题,而且有助于生成高分辨率的图像[4]。GAN只有随机噪声z(noise)作为输入变量,而ACGAN与GAN不同的是多了一个分类变量;同时GAN只对数据的真伪做判断,而ACGAN除了对数据的真伪作出判断,还增加了类别判断。ACGAN将鉴别器与辅助部分结合,使得改进后的鉴别器不仅可以识别数据的真伪,还可以区分不同的类别,进一步提高了生成的伪样本的质量。WaveGAN基于深度卷积生成对抗网络(deep convolution gene-rative adversarial network,DCGAN)改进而来[13]。DCGAN是在GAN的基础上设计的架构,可以实现高质量的图像生成,在DCGAN中,生成器使用转置卷积操作迭代地将低分辨率特征映射到高分辨率的图像中,但是由于音频序列本身是一种一维序列数据,并且比图像信号表现出更强的周期性,所以Wave-GAN通过将DCGAN生成器的二维转置卷积修改为一维转置卷积来适应音频信号的特点。
在多尺度上采样块进行采样,再用融合块进行堆叠的做法,最早出现在图像领域,在Google于2014年提出的GoogLeNet[14]中采用,其引入inception模块对图像特征进行采集,利用不同大小的卷积核提取不同尺度的特征,最后将所有输出结果进行融合并拼接为一个深度特征图,以获取多样化的特征。除此之外,研究人员还基于GoogLeNet提出了Xception[15]等改进,进一步提升网络的性能。在音频领域,Vasquez等人[7]提出的音频生成模型MelNet中使用了多尺度的方法,首先生成低分辨率的声谱图用于捕捉高层特征,通过反复迭代生成高分辨率的声谱图,再通过反演模型将声谱图转换为音频序列。
ACGAN通过辅助分类器的做法,将GAN从无监督学习转变成半监督学习,可以学习到更具特异性的特征;WaveGAN基于音频信号的特点,使用原始音频序列进行建模,减少了网络在特征提取过程中损失的音频信息;多尺度上采样块,适应音频信号的特点,可以获取多样化的特征。本文针对WaveGAN网络存在的问题,结合上述方法,提出了一种基于生成对抗网络与特征融合的多尺度音频序列生成方法,提升生成音频序列的质量。
2 基于生成对抗网络与特征融合的音频生成方法MAS-GAN
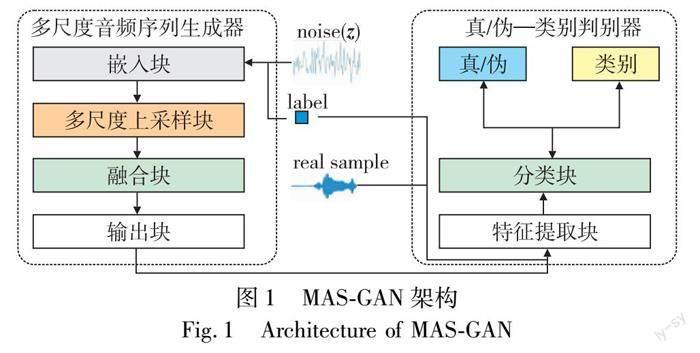
本文提出的MAS-GAN旨在结合GAN对抗学习的思想,通过博弈训练生成更多特定标签的音频序列数据。如图1所示,MAS-GAN由多尺度音频序列生成器MASG(multi-scale audio sequence generator)和真/伪—类别判别器RFCD(real/fake-category discriminator)组成。MASG首先通过嵌入块将100维噪声向量与标签label进行融合,融合后的向量经过多尺度上采样块和融合块扩张到与真实样本相同的尺寸,合成伪音频MASG(z,label);判别器RFCD的输入是带标签的真实音频数据(x,label)和带标签的MASG合成的伪音频数据MASG(z,label),通过特征提取块提取音频数据的特征,然后通过分类模块将真实音频数据和伪音频数据区分开来,同时对类别作出判断。在这个过程中,生成器试图通过生成趋近于真实数据分布的伪数据来欺骗判别器,判别器则希望更准确地区别真实数据和伪数据。
2.1 多尺度音频序列生成器
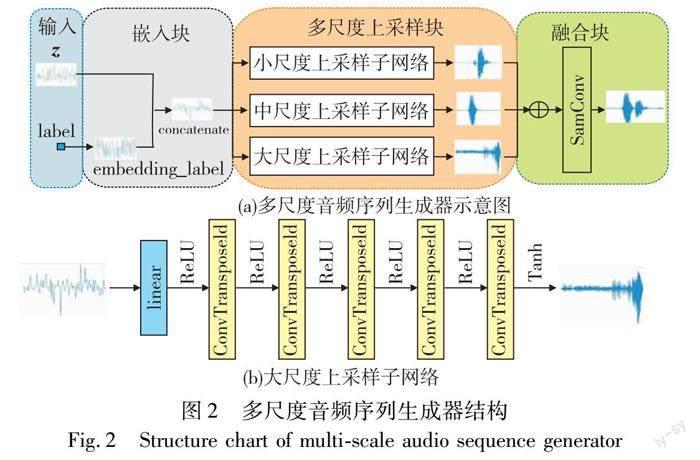
多尺度音频序列生成器MASG使用原始序列进行建模,如图2(a)所示。输入(input)包含一个100维的噪声向量z和一个类别标签label;嵌入块(embedding block)首先将类别标签label映射到多维空间,使其维度与噪声向量z的维度相同,然后再将噪声向量z与类别标签向量组合起来;多尺度上采样块(multi-scale up-sample block)包含三个不同尺度的上采样子网络,分别以不同大小的卷积核对嵌入类别标签之后的噪声向量进行上采样,得到不同尺度的上采样结果;融合块(fusion block)首先将上采样块得到的结果在维度上堆叠起来,最后经过一个same卷积层将维度压缩到1维,得到伪音频序列样本。
由于音频序列信号在时域上表现为幅值随时间的变化,在频域上表现为幅值随频率的变化,不同的音频序列信号在时域上和频域上差别较大,所以增强网络对音频信号时域和频域的理解对生成更真实的伪样本有十分重要的作用。通常在特征提取过程中,可以通过增加卷积核尺寸的方式获得更多的信息量。根据音频序列的特性,本文提出了一种多尺度上采样块作为多尺度音频序列生成器的核心模块,多尺度上采样块中的三个上采样子网络采用不同的网络长度和卷积核,使得网络可以表达音频序列的多尺度信息,提高网络的学习和表达能力。
表1给出了多尺度上采样块中的小尺度、中尺度、大尺度三个不同尺度上采样子网络的结构参数。其中d是一个控制网络宽度的参数,当d的值变大时,网络宽度增加,训练网络的时间成本增加;反之,则提取到的特征会减少,导致生成的伪样本质量下降。在质量和效率之间权衡,本文中d的大小设置为8。以大尺度上采样子网络为例,如图2(b)和表1所示,首先将嵌入块输出的1×100维向量经过一个线性层(linear)扩大到1×512d,再将其维度变换为32d×16,经过卷积核大小为24、步长为4的deConv1层后,输出16d×64维特征矩阵,然后经过四个同样参数的deConv层之后,最终输出维度为1×16 384,除最后一层使用tanh激活函数外,其他层均使用ReLU作为激活函数。
将多尺度上采样块三个尺度的输出作为融合块(fusion bock)的输入,首先将多尺度上采样块输出的三个尺度的结果在通道上堆叠起来,得到的矩阵维度为3×16 384,该矩阵经过一个same卷积层将维度压缩到1维,得到最终生成的伪音频样本进行输出。多尺度音频序列生成器所涉及的计算过程为
MASG(z,label)=φ(SameConv(SU(F)⊕MU(F)⊕LU(F)))(1)
其中:MASG(z,label)表示多尺度音频序列生成器生成的伪音频样本,φ表示tanh激活函数,SameConv表示same卷积层操作符,SU、MU、LU分别表示多尺度上采样块中小尺度、中尺度和大尺度上采样子网络操作符,F表示嵌入块(embedding block)输出的向量。
2.2 真/伪—类别判别器
受ACGAN的启发,真/伪—类别判别器RFCD采取了带辅助分类器的做法,如图3所示。这样的做法使得GAN从原本的无监督学习变为半监督学习,判别器负责指导生成器生成逼真数据,又通过类别标签将不同类别的数据区分开来,指导生成器生成各类别的数据。通过真/伪—类别判别器,可以使得多尺度音频序列生成器生成的伪音频样本MASG(z,label)相比无监督学习生成的样本更具有特异性。
真/伪—类别判别器的输入(input)包含音频样本及其所对应的类别标签label,输入的音频样本是真实的音频样本(x,label)或者由多尺度音频序列生成器生成的伪音频样本MASG(z,label),特征提取块(feature extraction block)负责对真/伪音频样本进行特征提取,得到真/伪样本的全局特征向量,进而得到预测结果。预测结果包含分别为真/伪标签和类别标签两部分,目的是将真实音频数据和伪音频数据区分开来,同时对类别作出判断。表2给出了真/伪—类别判别器的相关参数。输入(input)的一维音频序列维度为1×16 384维,经过卷积核大小为25,步长为4的Conv1层后,输出维度为d×4 096维,再经过四个卷积核与步长相同的Conv层之后,输出维度分别为2d×1024、4d×256、8d×64、16d×16维,这五个Conv层的激活函数均为Leaky_ReLU,将16d×16维的输出特征向量维度变换为256d×1,然后输入一个线性层linear,得到32d×1维度的特征向量。由于真/伪—类别判别器包含样本的真/伪判断和类别判断,所以网络最后的全连接层包含的神经元个数为(1+C),其中C代表数据集中类别的数量(本文中C设置为10),第一个神经元的输出采用sigmoid作为激活函数,定义为真/预测向量,后面C个神经元的输出采用softmax作为激活函数,定义为类别标签预测向量。
2.3 方法实现流程
本文提出的多尺度原始序列音频生成方法MAS-GAN具体通过MASG与RFCD的博弈训练实现,其训练过程可分为两个步骤:训练真/伪—類别判别器RFCD和训练多尺度音频序列生成器MASG。通过MASG与RFCD之间的博弈,当MASG生成的伪数据的概率分布和真实数据的分布接近时,MASG生成的伪样本接近真实样本,博弈训练结束。
算法1 MAS-GAN model training
输入:带标签的真实音频样本D={x,label}。
输出:多尺度音频序列生成器MASG。
1 for number of training iterations do
2 for k steps do
3 sample minibatch of m samples{(z,label)} from noise prior pg(z) and random sampling label from 0 to C;
4 sample m samples {(x,label)} from D;
5 calculate the loss of RFCD LRFCD;
6 update the parameters of RFCD by LRFCD;
7 end for
8 sample minibatch of m samples {(z,label)} from noise prior pg(z) and random sampling label from 0 to C;
9 calculate loss of MASG LMASG;
10update the parameters of MASG by LMASG;
11 end for
算法1主要包括以下两个步骤:
a)训练真/伪—类别判别器RFCD,对应于算法1中的第2~7行。首先将真实的音频样本(x,label)和多尺度音频序列生成器生成的伪音频样本MASG(z,label)输入到真/伪—类别判别器,模型中的特征提取块对输入的音频样本进行特征提取,得到真/偽预测向量和类别标签向量yc,根据式(2)计算损失函数LRFCD,对真/伪—类别判别器进行优化。
LRFCD=-[Eyc[label*log(yc)]+Ex~Pr[log(RFCD(x))]+Ez~Pf[log(1-RFCD(MASG(z,label)))]](2)
其中:Pr和Pf分别代表真实数据(real data)和伪数据(fake data)的概率分布;RFCD(x)表示x来自训练数据(real data)的概率;z为输入到生成器的随机噪声;label表示输入到网络中的类别标签;yc表示判别器RFCD输出的类别标签预测向量。
b)训练多尺度音频序列生成器MASG,对应于算法1中的第8~11行。首先将步骤a)中训练得到的真伪—类别判别器RFCD的参数固定,然后将随机生成的带标签的噪声数据(z,label)输入到MASG中,生成对应的伪音频样本数据MASG(z,label),根据式(3)计算损失函数LMASG,对多尺度音频序列生成器进行优化。
LMASG=-[Eyc[label*log(yc)]+Ez~Pf[log RFCD(MASG(z,label))+13LML]](3)
其中:LML表示多尺度上采样子网络损失,如式(4)所示。
LML=13[Ez~Pf[log RFCD(SU(z,label))]+ Ez~Pf[log RFCD(MU(z,label))]+Ez~Pf[log RFCD(LU(z,label))]](4)
其中:SU、MU、LU分别表示多尺度上采样块中小尺度、中尺度和大尺度上采样子网络得到的数据。
训练的过程中MASG和RFCD交替训练,保证每k个batch训练一次MASG,每一个batch训练一次RFCD,本文中k设置为2,网络在通过交替训练优化后,生成器和判别器之间达到平衡,得到最终的MAS-GAN模型。
3 实验及其结果分析
通过开展两方面的实验测试所提出的MAS-GAN的性能:实验1使用IS、FID等客观评价标准将所提出的方法与其他音频序列生成方法进行性能比较,验证所提出方法的有效性;实验2进一步将所提出的方法作为数据增强方法,通过分类任务评估生成音频序列的质量,与其他方法进行对比。
3.1 实验数据和参数
实验采用的数据集为SC09(speech commands zero through nine dataset)语音数据集[11],该数据集包含18 620个音频样本,分为10类,分别为不同的人朗读0~9(zero-nine)共10个数字的音频,每个音频样本的长度为1 s,采样率均为16 kHz,数据集已划分好训练集、验证集和测试集。借鉴相关文献[4,10]的经验,训练过程都使用Adam优化器,betas设置为0.5和0.9,学习率设置为0.000 5,batch-size设置为64,通过上述策略对MAS-GAN训练3 000个轮次。实验在PyTorch框架下实现,实验环境如下:Windows 10 64位操作系统,8核心AMD Ryzen7 3700X CPU(3.6 GHz),NVIDIA GeForce RTX2070 Super显卡(GPU),32 GB内存。
3.2 实验结果及分析
本文所提出的MAS-GAN是基于原始序列直接建模的音频合成算法,因此实验部分主要与同类型的WaveGAN作对比,同时为了进一步测试方法的有效性和性能,实验还加入了近年来主流的基于声谱图的生成对抗网络音频合成算法MelGAN[16]、VocGAN[17]和MB-MelGAN[18]作对比。
3.2.1 采用标准IS和FID的评价结果及分析
实验1通过IS(inception score)和FID(Fréchet inception distance)[19]两种客观评价标准分别从生成样本的质量和多样性两个角度对MAS-GAN的性能进行评估,IS和FID都是通过Inception v3模型输出的样本属于某个类别的概率来判断生成样本的质量,通常被用来衡量GAN生成数据的质量。
- IS结果比较 采用IS作为各网络合成的音频质量评估标准,将生成的样本送入训练好的Inception模型,通过输出样本属于某个类别的概率来评价生成的样本质量,IS的数值越大,代表生成的音频样本质量越接近真实样本。IS评价结果如表3所示,其中SR代表音频表示方法(Mel表示网络从声谱图中提取特征进行建模,z表示网络直接从原始序列中提取特征进行建模),ground truth代表真实样本的分布。由表3可知,本文提出的MAS-GAN生成的伪音频序列样本的质量优于WaveGAN、MelGAN、VocGAN和MB-MelGAN。通过IS对几种音频序列生成网络生成的伪音频序列样本的质量进行分析,结果可知,MAS-GAN的性能相比WaveGAN、MelGAN、VocGAN和MB-MelGAN分别提升了33.74%、17.99%、6.78%和9.54%,这说明本文提出的MAS-GAN在生成的音频样本质量上更接近真实样本。
2)FID结果比较 FID标准基于IS改进而来,FID计算真实样本、生成样本在特征空间中的距离,本文采用FID作为各网络合成的音频多样性评估标准。首先利用Inception网络来提取特征,然后使用高斯模型对特征空间进行建模,通过求解两个特征之间的距离作为FID,FID的值越小,代表生成样本与真实样本的分布越接近。FID评价结果如表4所示。由表4可知,与WaveGAN、MelGAN、VocGAN和MB-MelGAN相比,所提出的MAS-GAN的性能明显更好。具体而言,通过FID对几种音频序列生成网络生成的伪音频序列样本的多样性分析,利用本文提出的MAS-GAN合成的音频样本与真实样本在特征空间的距离小于WaveGAN、MelGAN、VocGAN和MB-MelGAN,分别提升了约31.05%、14.55%、5.93%和3.75%,说明本文提出的MAS-GAN在生成的伪音频序列样本多样性上更接近真实样本。
3)音频频谱分析 为了进一步探讨所提出的音频序列增强生成对抗网络(MAS-GAN)产生效果背后的原因,将多尺度音频序列生成器的三个尺度上采样子网络输出的序列和最终生成的音频样本分别做短时傅里叶变换计算,并根據计算结果绘制声谱图,横坐标代表时间,纵坐标代表频率,如图4所示。
由图5可以看出,大尺度上采样子网络主要关注于5~7 kHz的频率,中尺度上采样子网络主要关注于2~3.2 kHz的频率,小尺度上采样子网络主要关注于0.5~1 kHz的频率;同时,三个不同尺度的子网络在时域上关注的点也有所区别,三个子网络的输出结果融合成最终结果,形成伪音频样本。这说明本文提出的三个不同尺度的上采样子网络可以适应音频信号的特点,提取到不同频段的音频信号的特征,同时又兼顾到了音频信号的时域特征。
通过上述实验与分析可知,本文方法在生成样本的质量和多样性上优于其他方法,造成这一结果的原因可能有:a)MAS-GAN采取一维卷积对音频序列进行处理,比二维卷积的做法更适合处理音频一维序列;b)多尺度音频序列生成器中的多尺度上采样子网络通过采用大小不同的卷积核,使得网络不仅能够学习音频序列的时域特征,而且能够学习音频序列的频域特征;c)特征融合模块将不同尺度的音频信息从时域和频域上结合起来,使得最终生成的伪音频样本相比其他音频生成方法生成的特征更为丰富。
3.2.2 分类任务结果及分析
为了进一步测试MAS-GAN的性能,本文分别使用WaveGAN、MelGAN、VocGAN、MB-MelGAN和MAS-GAN生成的音频序列样本扩充样本数量有限的训练集,然后进行分类实验,通过分类效果评估生成音频序列的质量。从SC09数据集10类数据的每个类中随机选取30个样本作为分类任务的训练集,然后分别使用WaveGAN、MelGAN、VocGAN、MB-MelGAN和MAS-GAN生成的伪音频序列样本对训练集进行扩充,扩充的数量分别为训练集的50%、100%和200%,用于对在ImageNet上经过预训练的ShuffleNet模型进行训练并进行分类实验,结果如图5所示,其中baseline表示未对训练集进行扩充的分类实验结果。
由图5可以看出,使用经过WaveGAN、MelGAN、VocGAN、MB-MelGAN和MAS-GAN扩充的训练集训练分类模型,获得的分类准确率对比baseline都有较为明显的提升,其中本文提出的MAS-GAN取得了最高的分类准确率,在扩充数据集200%的情况下达到了84.5%,比其他四种方法高出4.1%、2.7%、2.3%和2.4%。导致这一结果的可能原因有两个方面:首先,真伪—类别判别器中添加对于类别的判断,指导多尺度音频序列生成器生成序列,通过半监督学习使得生成器生成的音频样本更具特异性;其次,特征融合的引入有助于生成器学习到多尺度的音频信息,包含的音频序列信息比其他音频合成方法更多,使得生成器生成的音频数据的分布更接近于真实样本的分布,因此以这些样本扩充训练集得出的模型整体分类准确率比其他方法更高。
4 结束语
针对语音识别过程中通常数据集规模不足导致的识别效果差的问题,基于无监督原始序列音频生成方法,提出一种基于生成对抗网络和特征融合的多尺度原始序列音频生成方法。以多尺度音频序列生成器MAS-GAN为核心,利用三个不同尺度的上采样子网络来表达音频序列时域和频域上不同尺度的信息;同时在判别器中增加对于音频类别的判断,将原始GAN的无监督学习方式转换为半监督学习,实现了高质量的音频序列样本生成。在SC09音频数据集上的实验结果表明,本文方法生成的样本的IS分数(反映样本质量)和FID分数(反映样本多样性)比同类其他主流方法高出6.78%和3.75%,同时通过在SC09数据集上进行分类实验来评估生成音频序列的质量,采用所提方法进行数据增强后的分类准确率比同类主流方法高2.3%,验证了该方法的有效性。本文方法可以合成高质量的伪音频片段,可以广泛应用于小样本音频分类和语音识别等领域,通过本文方法生成的伪音频数据扩充数据集,从而达到以少量音频训练样本获得较高分类或识别准确率的目的。
本文方法采用的多尺度特征融合策略虽然在客观评价标准和分类结果上优于其他方法,但是仅采取三个尺度的上采样子网络来构建生成网络,并不能完整地反映音频序列的时域和频域特征,如何使网络自适应地对音频样本进行建模,是下一步的研究方向。
参考文献:
[1]Yu Jianbo, Zhou Xingkang. One-dimensional residual convolutional autoencoder based feature learning for gearbox fault diagnosis[J]. IEEE Trans on Industrial Informatics, 2020,16(10): 6347-6358.
[2]Mirheidari B, Blackburn D, OMalley R, et al. Improving cognitive impairment classification by generative neural network-based feature augmentation[C]//Proc of InterSpeech. 2020: 2527-2531.
[3]Goodfellow I, Pouget-Abadie J, Mirza M, et al. Generative adversarial nets[C]//Proc of International Conference on Neural Information Processing Systems Volume-2. Cambridge, MA: MIT Press, 2014: 2672-2680.
[4]Odena A, Olah C, Shlens J. Conditional image synthesis with auxiliary classifier GANS[C]//Proc of International Conference on Machine Learning. New York: ACM Press, 2017: 2642-2651.
[5]Sahu S, Gupta R, Espy-Wilson C. On enhancing speech emotion re-cognition using generative adversarial networks[EB/OL]. (2018-6-18) . https://arxiv.org/abs/1806.06626.
[6]Chatziagapi A, Paraskevopoulos G, Sgouropoulos D, et al. Data augmentation using GANs for speech emotion recognition[C]//Proc of InterSpeech. 2019: 171-175.
[7]Vasquez S, Lewis M. MelNet: a generative model for audio in the frequency domain[EB/OL]. (2019-06-04) . https://arxiv.org/abs/1906.01083.
[8]Engel J, Agrawal K K, Chen Shuo, et al. GANSynth: adversarial neural audio synthesis[EB/OL]. (2019-02-23) . https://arxiv.org/abs/1902.08710.
[9]尹文兵, 高戈, 曾邦, 等. 基于時频域生成对抗网络的语音增强算法[J]. 计算机科学, 2022,49(6): 187-192. (Yin Wenbing, Gao Ge, Zeng Bang, et al. Speech enhancement based on time-frequency domain GAN[J]. Computer Science, 2022,49(6):187-192.)
[10]Donahue C, McAuley J, Puckette M. Adversarial audio synthesis[C]//Proc of International Conference on Learning Representations. 2019.
[11]Shao Siyu, Wang Pu, Yan Ruqiang. Generative adversarial networks for data augmentation in machine fault diagnosis[J]. Computers in Industry, 2019,106: 85-93.
[12]Zhu Junyan, Park T, Isola P, et al. Unpaired image-to-image translation using cycle-consistent adversarial networks[C]//Proc of IEEE International Conference on Computer Vision. Piscataway, NJ: IEEE Press, 2017: 2223-2232.
[13]Radford A, Metz L, Chintala S. Unsupervised representation learning with deep convolutional generative adversarial networks[EB/OL]. (2015-11-19) . https://arxiv.org/abs/1511.06434.
[14]Szegedy C, Liu Wei, Jia Yangqing, et al. Going deeper with convolutions[C]//Proc of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2015: 1-9.
[15]Chollet F. Xception: deep learning with depthwise separable convolutions[C]//Proc of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2017: 1251-1258.
[16]Kumar K, Kumar R, De Boissiere T, et al. MelGAN: generative adversarial networks for conditional waveform synthesis[C]//Proc of the 33rd International Conference on Neural Information Processing Systems. 2019: 14910-14921.
[17]Yang J, Lee J, Kim Y, et al. VocGAN: a high-fidelity real-time vocoder with a hierarchically-nested adversarial network[EB/OL]. (2020-7-30) . https://arxiv.org/abs/2007.15256.
[18]Yang Geng, Yang Shan, Liu Kai, et al. Multi-band MelGAN: faster waveform generation for high-quality text-to-speech[C]//Proc of IEEE Spoken Language Technology Workshop. Piscataway, NJ: IEEE Press, 2021: 492-498.
[19]Kong Zhifeng, Ping Wei, Huang Jiaji, et al. DiffWave: a versatile diffusion model for audio synthesis[EB/OL]. (2020-09-21) . https://arxiv.org/abs/2009.09761.
收稿日期:2023-01-16;修回日期:2023-03-12 基金項目:国家自然科学基金资助项目(71963001);广西壮族自治区科技计划资助项目(2017AB15008);崇左市科技计划资助项目(FB2018001)
作者简介:许华杰(1974-),男(通信作者),广西南宁人,副教授,硕导,博士,主要研究方向为人工智能、声音信号识别和机器视觉(hjxu2009@163.com);张勃(1998-),男,陕西西安人,硕士研究生,主要研究方向为人工智能和声音信号处理与分析.
