基于多MEC 协作的移动VR 视频缓存和传输网络架构
2023-10-14郑成渝夏靖雯陈路遥
郑成渝,夏靖雯,陈路遥,唐 勇*,杨 挺,刘 强
(1.中国电信集团公司四川分公司 成都 610000;2.电子科技大学计算机科学与工程学院 成都 611731;3.澳门科技大学资讯科技学院 中国 澳门 999078)
虛拟现实(virtual reality, VR)视频是指全景视频,如水平 360°×垂 直1 80°全景视频、水平1 80°×垂直1 80°全景视频等,用户可借助VR 眼镜等虚拟现实设备观看全景视频,并获得身临其境的视觉感受[1]。其沉浸式体验对传输速率、时延和可靠性提出很高的要求。传输过程中的延迟和抖动会造成眩晕等症状,影响用户体验。在无线网络上传输的VR 视频也被称为移动VR 视频。移动VR 视频作为5G 无线网络的重要应用,其传输问题在学术界和工业界引起了广泛的关注。
在进一步分析移动VR 视频传输问题之前,先简要了解一种典型的 3 60°VR 视频的制作、传输与播放流程[1-2]。
1) 制作与编码VR 视频。一般使用多个摄像机拍摄画面并将抓捕的画面投影到球面空间进行缝合得到全景视频。接着利用等距柱状投影(equirectangular projection, ERP) 将二维球面视频图像映射成二维平面矩形视频图像,并切割成多个图像块,然后送进视频编码器进行编码。最终一个完整的VR 视频文件被转化为多个可独立编码和解码的分块视频文件。
2) 传输VR 视频。在非直播场景下,编码后的VR 视频被缓存在数据中心的内容服务器中。移动VR 设备在用户观看本地已缓存的VR 视频过程中,会提前向内容服务器请求本地未缓存的VR 视频。被请求的VR 视频经过互联网络、5G 核心网络、回传网络和前传网络传输最终抵达移动VR 设备[3]。
3) 播放VR 视频。请求的VR 视频由多个分块视频文件组成。移动VR 设备对这些分块视频文件解码,然后将视频图像投影到球面空间,最后渲染展示到设备屏幕上。
用户使用VR 设备观看VR 视频时,有一定的视角限制,只能看见 360°全景视野的一部分画面,这部分可见区域也被称为视场角(field of view,FoV)。在流行的移动VR 设备中,对于360°×180°的VR 视频而言,FoV 的大小在9 0°×90°左右[4],仅占全景视野的12.5%。于是现有传输方案[5–7]通常仅传输FoV 视频文件而非整个全景视频,以降低带宽消耗和请求超时的可能性。FoV 视频文件可以看成由多个分块视频文件组成。为了避免用户突然转动头部出现黑块,传输FoV 视频文件通常也指以高码率传输FoV 内的画面而FoV 外的画面采用低码率传输或者直接使用纯色填充。
由于核心网络和回程网络充满了不确定性,移动VR 设备直接向数据中心的内容服务器请求FoV 视频文件同样会使得分发时延过大。5G 网络架构中提出的移动边缘计算(mobile edge computing,MEC)技术可应用在VR 传输场景下缓解分发时延过大问题[8]。一种实践方案是将MEC 服务器部署在基站附近,为在基站信号覆盖范围内的移动VR 设备提供缓存服务。在VR 视频传输场景下,将热门VR 视频缓存到MEC 服务器中。当移动VR 设备发出对这些VR 视频的请求时,靠近该设备的MEC 服务器便可以直接处理该请求,降低请求的视频内容经过互联网和核心网再达到基站的时延。除此之外,MEC 服务器还可为移动VR 设备提供计算服务。播放VR 视频前,移动VR 设备需要对视频进行解码和投影操作。虽然这部分计算操作的复杂度比较低,但并不是所有移动VR 设备都具备符合需求的计算能力[9]。对于计算能力不足的移动VR 设备,考虑将其计算任务卸载到邻近的MEC 服务器上处理。
根据思科的最新报告显示,到 2023 年,连接到 IP 网络的设备数量将是全球人口的3 倍以上,移动数据流量将占到总IP 流量的75%以上[10]。单MEC 服务器的缓存能力与数据中心海量存储能力相比十分局限,而这日益增多的数据量使得这差异愈发明显。此时单MEC 服务器的优势已不再显著。为满足更多用户的需求,多MEC 服务器协作传输VR 视频正成为一种可行方案。
近年来,越来越多研究人员也对移动VR 视频传输问题展开研究。文献[11]提出了基于分块来传输VR 视频的方案,但没有考虑到利用MEC 技术来加快传输移动VR 视频的可能性。文献[2,12]提出了基于MEC 网络架构来传输移动VR 视频的方案。文献[2]提出了一种基于FoV 来传输VR 视频的专用网络架构方案。文献[12]把联合优化计算和缓存作为VR 视频传输的关键问题,并通过仿真实验证明了方案收益。然而这两项研究都仅在单MEC 服务器下工作,没有考虑多MEC 服务器协作的潜在可能。
本文提出一种基于多MEC 服务器协作的VR 视频传输网络架构,阐述多MEC 协作缓存和传输VR 视频的方式。然后以降低VR 视频平均分发时延为优化目标,建立混合整数线性规划(mixed-integer linear programming, MILP)模型,通过求解模型得到缓存方案。最后通过实验证明多MEC 协作缓存和传输VR 视频可有效降低VR 视频的分发时延。
1 系统模型
1.1 多MEC 协作网络架构
基于多MEC 协作的VR 视频缓存和传输网络架构如图1 所示。该传输网络架构由远程内容服务器、5G 核心网络、MEC 协作域3 个部分组成。远程内容服务器主要负责VR 视频的前期制作与分发,包括视频拼接缝合、VR 视频映射和编码,以及将编码后的视频分发到网络边缘的MEC 服务器上。

图1 多MEC 协作缓存和传输移动VR 视频架构
在未引入MEC 的网络中,被请求的VR 视频数据在跨越多个网络后才会抵达移动VR 设备。此传输模式将使得分发时延过大和5G 核心网络承受较大流量压力。为弥补此传输模式的不足,本文在传统网络中引入MEC 服务器并将其部署在基站(base station, BS)附近。单个MEC 服务器的缓存能力相较于数据中心是十分有限的,为了满足更多请求,本文提出多MEC 协作方式。
因为一个5G 基站的覆盖范围比较小(≤ 500 m[13]),一个生活/商业区域通常会部署多个基站,于是可以人为地将这些地理位置相近的多个基站以及部署在其附近的MEC 服务器划分成一个协作区域,让其共享存储空间与计算资源。下面简称协作区域为协作域。
多MEC 协作系统周期性地运行缓存算法,每次选择协作域中负载最低的MEC 服务器来计算缓存方案,并将方案下发给其他MEC 服务器。收到缓存方案的MEC 服务器把与方案中一致的已存内容保留,然后再向其他MEC 或者远程内容服务器请求方案中的其余内容。每台MEC 服务器中都维护一张资源访问表,该表记录了协作域内每台MEC 服务器缓存的内容。当本地缓存未命中时,MEC 服务器根据资源访问表将请求转发给缓存了目标内容的MEC 服务器,让其来处理请求。
本文将与移动VR 设备通信的基站,称为该移动VR 设备的Home BS,称部署在Home BS 附近的MEC 服务器为其Home MEC 服务器。在基于多MEC 协作缓存和传输的网络架构中,移动VR 设备请求的视频将由以下3 条路径之一来响应。路径①:Home MEC 服务器上缓存命中,由Home MEC 服务器来直接响应请求。路径②:Home MEC 服务器上缓存未命中,由Home MEC 服务器向协作域内缓存了目标视频的MEC 服务器请求。路径③:协作域内所有的MEC 服务器都没有缓存目标视频,那么Home MEC 服务器就向远程内容服务器处请求。通过后两种方式获得的视频都将被回传给Home MEC 服务器,最终再由它传输给移动VR 设备。3 条路径对应的内容分发时延是不同的。对于同一请求来说,路径①的分发时延最低,路径②次之,路径③最长。于是通过多MEC服务器协作,尽可能地让请求在协作域内被处理,会大大降低VR 视频平均分发时延,从而提升用户的体验质量。
1.2 缓存和请求模型
多MEC 协作系统可提供服务的移动3 60°VR 视频集合为N={1,2,···,n}。 这些 360°VR 视频均采用ERP 方式投影到二维平面。为了便于移动VR 设备请求和服务器端传输,二维平面视频被划分成时长固定为 Δt秒的连续视频片段。每个视频片段按行和列划分成i×j个可独立编码和解码的分块视频文件。每个VR 视频都支持以两种相差较大的码率来编码。对于VR 视频n来 说,其持续时长为dn,支持低码率 lbrn和 高码率 hbrn。 于是得到VR 视频n的大小为Sn=dn×lbrn+dn×hbrn。
协作域内的MEC 服务器集合为M={1,2,···,m}。MEC 服务器m具 备Cm的缓存空间。一个VR 视频的所有分块视频文件将存放在同一个MEC 服务器上。在MEC 服务器缓存空间限制下得到如下约束不等式:
式中,变量xm,n∈{0,1}表 示VR 视频n是否被缓存在MEC 服务器m中。
在用户观看 [t,t+Δt]时段的VR 视频过程中,移动VR 设备预测用户 [t+Δt,t+2Δt]的头部运动轨迹并得到预测FoV,接着向Home MEC 服务器请求下一视频片段的FoV 视频文件。
同文献[5–7]的传输方案[5–7]一样,本文对构成FoV 的多个分块视频文件采用高码率传输,而对构成非FoV 的多个分块视频文件采用低码率传输。用户在球面空间中的FoV 投射到二维平面可以近似看成由k×k个分块组成[14]。于是高码率分块占全景画面的比例为w=k×k/i×j, 低码率分块占全景画面的比例为 ( 1-w)。服务器端最终需要传输的数据量为=w×hbrn×Δt+(1-w)×lbrn×Δt。
1.3 时延模型
传输架构中涉及的通信过程可用概括为3 段通信过程:1)MEC 服务器与移动VR 设备之间的通信,简记为MEC-MVRD 通信;2)MEC 服务器与MEC 服务器之间的通信,简称为MEC-MEC 通信;3)MEC 服务器与远程内容服务器之间的通信,简称为MEC-DC 通信。
在MEC-MVRD 通信过程中,MEC 服务器所在基站到移动VR 设备是单跳无线网络,无线电信号在空气中的传播速度近似于光速,且移动VR 设备与基站之间的距离不超过1 km,因而它们之间的传播时延可忽略不计。同理,MEC 服务器所在的基站之间通过X2 接口进行通信[15],底层物理链路为光纤,是单跳有线网络且距离不超过10 km,由此MEC 服务器之间的传播时延也可不用考虑。当MEC 服务器负载过高时,数据会排队等待发送。于是MEC-MVRD 和MEC-MEC 段通信过程引起的时延主要为排队时延和发送视频内容的时延。
由于云端内容服务器到MEC 服务器的网络状况比较复杂,包括多跳有线和无线链路,精确计算云端内容服务器到MEC 服务器的通信时延比较困难,本文使用平均通信时延Tdc→m来表示MECDC 通信过程的引起的时延。
在本文中,移动VR 设备按照是否有投影计算能力分为计算能力不足的U1类移动VR 设备和计算能力充足的U2类移动VR 设备。在播放视频之前,U1类移动VR 设备会将投影计算任务卸载到其Home MEC 服务器上,从而引起额外计算时延。在MEC 服务器m上 执行关于VR 视频n的投影计算任务而产生的计算时延为:
式中,zn表 示计算VR 视频n每比特数据所会消耗的CPU 周期数;fm表 示MEC 服务器m的CPU 计算频率。
在实际中,可配置物理层和更高层来设定所有基站对移动VR 设备都具备相同的数据传输速率R1, 各基站之间通信具有相同的数据传输速率R2。
从上述分析中可以得到,从服务器端下发FoV视频文件到移动VR 设备端的分发时延主要由计算时延、排队时延和发送时延构成。由此可总结出两类移动VR 设备请求关于VR 视频n的FoV 视频文件经由3 条路径产生的分发时延。
U1类移动VR 设备的请求通过路径①得到响应引发的分发时延可表示为:
式中,Tque表示请求的内容在协作域内传输过程中等待发送经历的排队时延;表示经过计算膨胀后的数据量,通常α ≥2[9]。
U2类移动VR 设备的请求通过路径①得到响应引起的分发时延可表示为:
U1类移动VR 设备的请求通过路径②得到响应引起的分发时延可表示为:
相比从路径①得到视频内容,从路径②获取视频内容会多出一个发送时延,即视频内容从协作域内其他MEC 服务器中被发送出去的时延。同理,U2类移动VR 设备的请求通过路径②得到响应的分发时延可表示为:
U1类移动VR 设备的请求通过路径③得到响应引起的分发时延可表示为:
U2类移动VR 设备的请求通过路径③得到响应引起的分发时延可表示为:
从1.1 节可以得知,MEC 服务器m服务范围内的移动VR 设备向其请求VR 视频n只会从3 条路径之一得到响应。下面引入3 个请求路径变量来分别表示VR 视频n的3 种获取位置。ym,n∈{0,1}表示VR 视频n是否从Home MEC 服务器m处获取,∈{0,1} 表 示VR 视频n是否从协作域内MEC 服务器k处获取,∈{0,1} 表 示VR 视频n是否从远程内容服务器中获取。因为VR 视频n只能从一个位置获取,于是存在约束:
引入请求路径变量后,U1类移动VR 设备向MEC 服务器m请 求VR 视频n引起的分发时延可整合表示为:
U2类 移动VR 设备向MEC 服务器m请求VR视频n引起的分发时延也可整合表示为:
1.4 问题建模
用户获取视频的平均分发时延是一项衡量用户体验质量的重要性能指标[16]。平均内容交付时延越小,意味着越多的用户请求能由协作域内的MEC服务器满足,用户的体验质量也就越高。于是本文以最小化协作域内VR 视频平均内容分发时延(average delivery latency, ADL)为优化目标建立MILP模型,简称为MADL。MADL 具体表示如下:
约束式(1)确保了每台MEC 服务器缓存的VR视频大小总和不会超过其最大存储空间限制。约束式(9)确保了对VR 视频n的请求只能在一个地方得到处理。约束式(12)和式(13)共同限制了只有当MEC 服务器上缓存了VR 视频内容n时,才能响应对VR 视频内容n的请求。式(14)表示模型要优化的目标函数,其中,表示U1类移动VR设备在MEC服务器m上的请求到达率;表示U2类移动VR 设备在MEC 服务器m上的请求到达率;表 示VR 视频n在 MEC 服务器m上的流行程度。
2 实验与结果分析
2.1 实验参数设置
在实验参数设定方面,本文依据现实物理情况并参考相似研究来设置实验参数值。设定一个协作域内的MEC 服务器数量为10,此协作域的服务范围可完整覆盖一个大型商场[13],在实际情况中可根据真实需求适当地增加或者减少MEC 服务器的数量。每个MEC 服务器都具备10 GB 的存储空间,计算频率为20 GHz。基站到移动VR 设备的数据发送速率为100 Mbps,基站之间的数据发送速率为500 Mbps[17]。在MEC 服务器上执行计算任务,每比特VR 视频数据需要消耗10 个CPU 周期[9],计算后数据量的膨胀系数α =2[9]。
系统提供了500 个不同的 3 60°VR 视频,时长为[1, 5] min,低码率为[3, 8] Mbps,高码率为[15,32] Mbps。以 Δt=1 s 将 360°VR 视频经过ERP 映射后的平面视频分段,每个视频片段被切分成4×8个分块,FoV 平均由 2 ×2 个分块组成[14]。假设360°VR 视频的流行度服从偏斜系数 γ=0.56的Zipf 分布[16],偏斜系数 γ表示内容流行度分布的偏斜程度。U1和U2类移动VR 设备在每台MEC 服务器上的请求分别服从到达率为50 和100 的泊松分布[3]。通信过程中的排队时延为[1, 3] ms,远程内容服务器传输移动VR 设备请求的FoV 视频文件到协作域内MEC 服务器上的通信时延为[50, 100] ms[18]。
2.2 性能对比方案和指标
将本文的MILP 模型与另外两种传统缓存算法(Distributed 算法和Self-Top 算法[3])进行性能对比。在Distributed 算法中,协作域内每台MEC 服务器均缓存完全不同的VR 视频,以实现在协作域内缓存尽可能多的内容。在Self-Top 算法中,协作域内每个MEC 服务器都缓存其服务范围内最热门的VR 视频。由于地域相似性,一个协作域内的用户对VR 视频的偏好是比较近似的,于是在Self-Top 算法下每台MEC 服务器上缓存的内容具有很高的相似度。
对于MILP 模型,本文实验使用商业软件AMPL/Gurobi 进行求解,版本号为9.5.0,模型求解精度为MIPGAP=0.005。
对于性能分析,主要以协作域的平均内容分发时延(ADL)作为算法性能的评估指标。在仿真实验中,研究系统参数对缓存性能的影响,包括MEC 服务器缓存空间大小、MEC 服务器计算频率、VR 视频数量、Zipf 分布的偏斜系数 γ和移动VR 设备请求达到率。
2.3 结果分析
图2 描述了在单MEC 服务器缓存空间变化下3 种缓存算法在ADL 方面的性能对比。从图2 中可以看出,所有缓存算法的ADL 都随着MEC 服务器缓存空间的增大而减小。这是因为随着缓存空间的增大,更多的VR 视频可以被缓存在MEC协作域中,从而更多的请求可以在协作域内直接得到响应。实验结果表明,MADL 具有较低的ADL。当协作域内MEC 服务器的缓存空间不足以缓存下所有VR 视频时,MADL 较于Self-Top 和Distributed 的性能表现更加优越。例如,在单MEC服务器缓存空间从10 G 到40 G 变化时,MADL下的ADL 比Self-Top 和Distributed 分别低约17%~55%,11%~16%。

图2 MEC 服务器缓存大小变化下缓存算法性能对比
图3 描述了在单MEC 服务器CPU 计算频率变化下3 种缓存算法在ADL 方面的性能对比。从图3中可看出,所有缓存算法的ADL 一开始随着MEC 服务器的CPU 计算频率增大而减小,随后趋于稳定。这是因为U1类移动VR 设备将计算任务卸载到Home MEC 服务器上产生的计算时延会随着服务器的计算能力增强而降低。当MEC 服务器的计算能力提升到一定程度时,计算时延对最终的分发时延不会造成重要影响。由数值结果可以看出,当MEC 服务器的CPU 计算频率从5 GHz 到50 GHz变化时,MADL 下的ADL 一直低于Self-Top 和Distributed,且差值分别稳定在16%和10%。

图3 MEC 服务器CPU 计算频率变化下缓存算法性能对比
图4 描述了在VR 视频内容数量变化下3 种缓存算法在ADL 方面的性能对比。从图4 中可看出,3 种缓存算法的ADL 都随着VR 视频内容数量的增加而增大。因为MEC 服务器的缓存空间有限,随着视频内容的不断增多,越来越多的请求无法从协作域中得到满足。实验结果显示,当视频内容数量从100 到500 变化时,MADL 的ADL 比Distributed 低约7%~11%。在视频内容数量为100 时,MADL 的ADL 比Self-Top 低67%,当视频内容数量为500 时,MADL 的ADL 比Self-Top低18%。
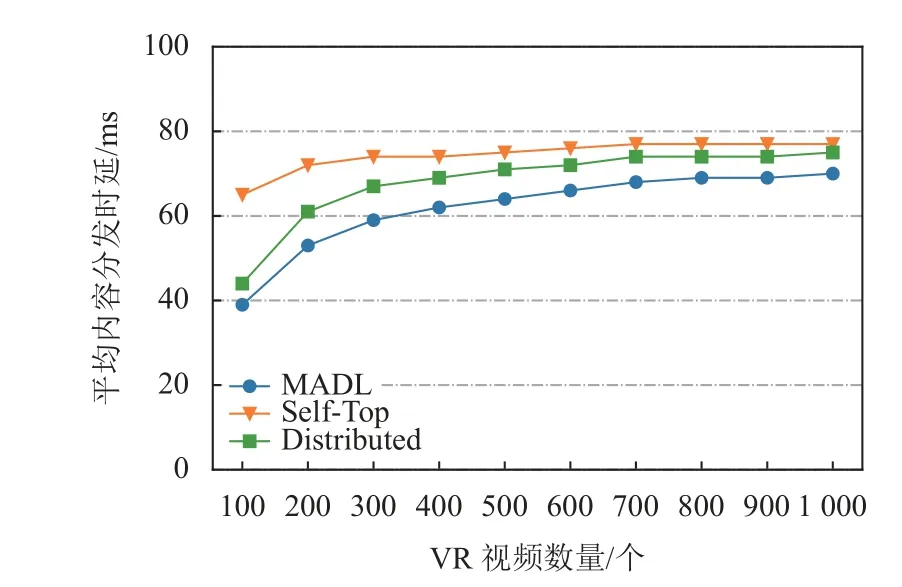
图4 VR 视频内容数量变化下缓存算法性能对比
图5 描述了在Zipf 分布的偏斜系数 γ变化下3 种缓存算法在ADL 方面的性能对比。从图5 中可看出,所有算法的ADL 随着 γ的增大而减小并且算法之间的性能差距也在逐渐减小。这是因为随着 γ增大,流行的视频变得更加集中。此时少量的视频会占据绝大部分的请求流量,而在协作域中缓存这些少量且热门视频便几乎能满足所有移动VR 设备的请求。于是出现随着 γ增大3 种算法之间的性能差距减小的现象。
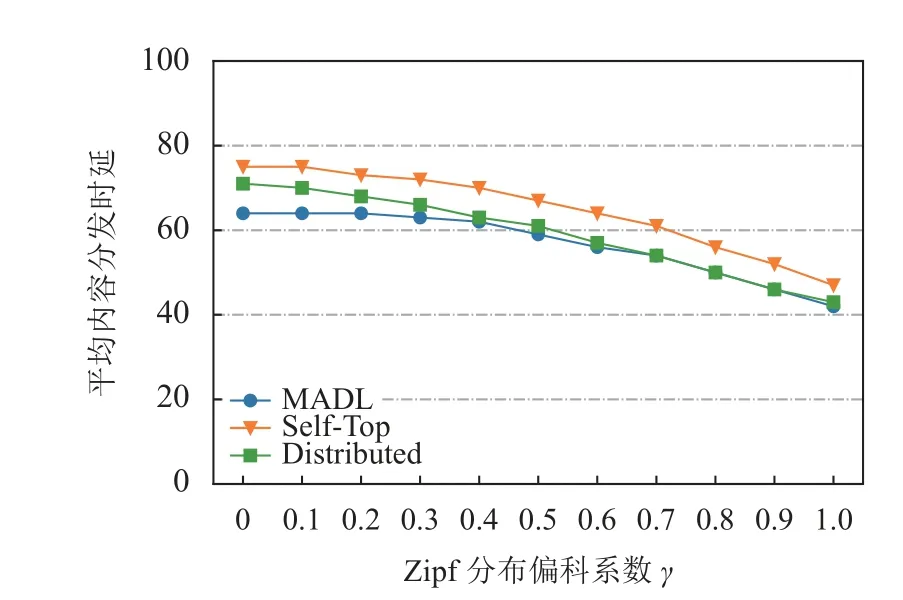
图5 Zipf 分布偏斜系数γ 变化下缓存算法性能对比
图6 和图7 分别描述了在计算能力不充足的U1类 和计算能力充足的U2类移动VR 设备的请求到达率变化下3 种缓存算法在ADL 方面的性能对比。从图6 中可以看出,随着U1类移动VR 设备请求到达率增高,所有算法的ADL 也随之增大。由于U1类移动VR 设备会将计算任务卸载到Home MEC 服务器上,所以当这类设备的请求数增多时,总分发时延将增大,从而使得ADL 增大。从图7 中可以看出,随着U2类移动VR 设备请求到达率增高,所有算法的ADL 却降低。U2类移动VR 设备发出的请求不会产生额外的计算时延,所以这类设备的请求数增多,将削弱U1类移动VR 设备请求带来的高分发时延影响,因而ADL 会降低。

图6 U 1类VR 设备请求到达率变化下缓存算法性能对比

图7 U2类VR 设备请求到达率变化下缓存算法性能对比
3 结 束 语
为了降低VR 视频分发时延以提升用户体验质量,本文提出了一种基于多MEC 协作的VR 视频缓存和传输网络架构。在考虑协作域内计算能力充足和计算能力不足的两类移动VR 设备的请求来决定VR 视频的缓存位置的基础上,建立以最小化平均内容分发时延为目标的MILP 模型,并通过Gurobi 商业求解器得到VR 视频的最佳缓存位置。仿真实验证明,本文提出的缓存和传输策略在降低VR 视频的平均内容分发时延方面是有效的。
本文研究得到“确定性工业互联网技术研究项目(220481)”支持,在此表示感谢!
