基于局部窗口交叉注意力的轻量型语义分割 *
2023-10-12金祖亮隗寒冰ZhengLiu郑国峰
金祖亮,隗寒冰,Zheng Liu,2,娄 路,郑国峰
(1. 重庆交通大学机电与车辆工程学院,重庆 400074;2. University of British Columbia Okanagan, Kelowna, BC, Canada)
前言
自动驾驶汽车高度依赖于自车对场景的理解,例如湿滑地面检测[1]、交通标志检测[2]和障碍物检测等。在环视多相机语义分割任务中,前期研究基于DeepLap[3]、UNet[4]等单目相机分割得到2D 目标,然后采用跨相机后处理方式将分割结果投影至统一车身坐标系下获得3D 输出[5]。这类方法不能跨视图处理特征,分割结果容易受到环境影响而出现歧义,严重影响语义分割准确度。建立统一的鸟瞰图(BEV)矢量空间提取多视图相机内的特征已成为了当前代替单目后处理方式的主流方向。
建立统一矢量空间完成BEV 环视感知任务,需要网络能够在特征提取阶段之后完成透视图到BEV的转换。Philion 等[6]提出LLS(lift splat shoot)网络,该方法能显式预测出每个像素点深度的离散分布和上下文向量,从而通过离散分布和向量间内积确定沿相机射线方向上特征点的深度,然后结合相机参数将2D 特征提升到了统一3D 空间,最后借鉴PointPillars[7]中的体柱方法将特征解码得到分割结果。Hu 等[8]在LLS 的基础上提出了FIERY 网络,该方法在LLS 基础上有效地融合了时间序列,进一步提升了分割效果。Huang 等[9]也按照LLS 的视图转换方法完成了3D 目标检测任务。上述基于深度估计的方法随着感知距离增加,深度估计精度也会随之下降,并且逐点估计的伪点云方法会占用大量计算资源,导致推理时间长、速度慢,难以实时地完成自动驾驶感知任务。Pan 等[10]提出VPN 网络采用两层感知机(multi-layer perceptron,MLP),通过映射方式将透视图特征转化为BEV 特征。Li 等[11]提出的HDMapNet 网络同样采用MLP 的方式完成视图转换,为了确保转换有效性,该网络还将BEV 特征重投影回透视图,以对转换结果进行检查。基于MLP的方法速度虽然有所提升,但仍然没有使用相机内参作为几何先验以及缺乏深度信息。Zhou 等[12]提出基于Transformer[13]完成视图转换的CVT 网络,该网络通过构建BEV 查询(query),采用交叉注意力(cross attention)完成与图像特征之间的查询,且图像特征添加了由相机参数计算得到的位置嵌入以提供较好的先验。由于语义分割任务采用BEV 网格这种密集的查询来完成BEV 下的分割,但网络复杂度和计算量与BEV 查询的分辨率和透视图特征分辨率相关,因此网络采用缩小分辨率的方式来减少计算量,提高推理时间。Li 等[14]提出的BEVFormer利用了可形变注意力机制用于BEV 分割,使注意力关注在BEV 重投影透视图的相关稀疏位置以减少计算量。Chen 等[15]提出的GKT 利用几何先验引导注意力聚集在2D参考点的核区域,并且建立BEV和2D 的查找表用于快速推理。基于Transformer 的方法能更好地完成视图转换且模型权重拥有强数据关联性,相比基于深度估计和MLP 的方法具有更好的鲁棒性和精度。尽管基于Transformer的方法达到了当前最佳的检测精度和计算速度,但其计算量仍然较大,模型推理速度高度依赖于高算力GPU。
针对上述问题,本文中提出一种轻量型实时BEV 语义分割模型,以完成对自动驾驶场景中道路边缘、车道线和人行横道线的分割。本文提出的BEV语义分割模型包含3个关键设计:
(1)借鉴特征金字塔(feature pyramid networks,FPN[16])思想对轻量型骨干网络EdgeNeXt[17]进行改进,以完成对多尺度特征的提取;
(2)构建交叉视图转换编码器来完成透视图特征到BEV特征转换;
(3)提出了一种局部窗口交叉注意力方式,由此完成视图转换,以解决视图转化中全局查询带来的计算量大的问题。
1 算法设计
1.1 网络整体设计
本文提出的网络整体结构如图1 所示。骨干网络采用改进的EdgeNeXt 网络,基本思想是在EdgeNeXt 基础上添加残差块[18]的方式构建特征金字塔来捕获全局和局部信息,完成特征提取和融合。交叉视图转换编码器用于透视图特征到BEV 特征的转换,编码器包含BEV 局部窗口查询向量构建、局部窗口交叉视图注意力。BEV 特征解码器用于BEV 特征解码,从而输出分割结果,解码器借鉴FCN[19]网络,通过多个上采样残差块(upsample block)得到分割结果。

图1 网络整体结构
1.2 骨干网络改进
在骨干特征提取网络上,本文中设计了一种改进型EdgeNeXt 网络。EdgeNeXt 作为一种快速推理的混合神经网络,结合了卷积神经网络CNN 和Transformer 模型的优势,能够有效地学习局部和全局信息。同时为了增强模型的表现力,获取更多的上下文信息,骨干网络通过构建特征金字塔来聚合多尺度特征。
1.2.1 骨干网络改进
如图2(a)中骨干网络整体框架所示,EdgeNeXt模型包含4 个Stage 模块。除Stage1 外,所有的模块都包含一个下采样、多个卷积编码器和一个深度转置编码器。为了减少冗余的位置编码带来的推理速度下降,仅需在第一个深度转置编码器前,即Stage2模块内添加一次位置编码。
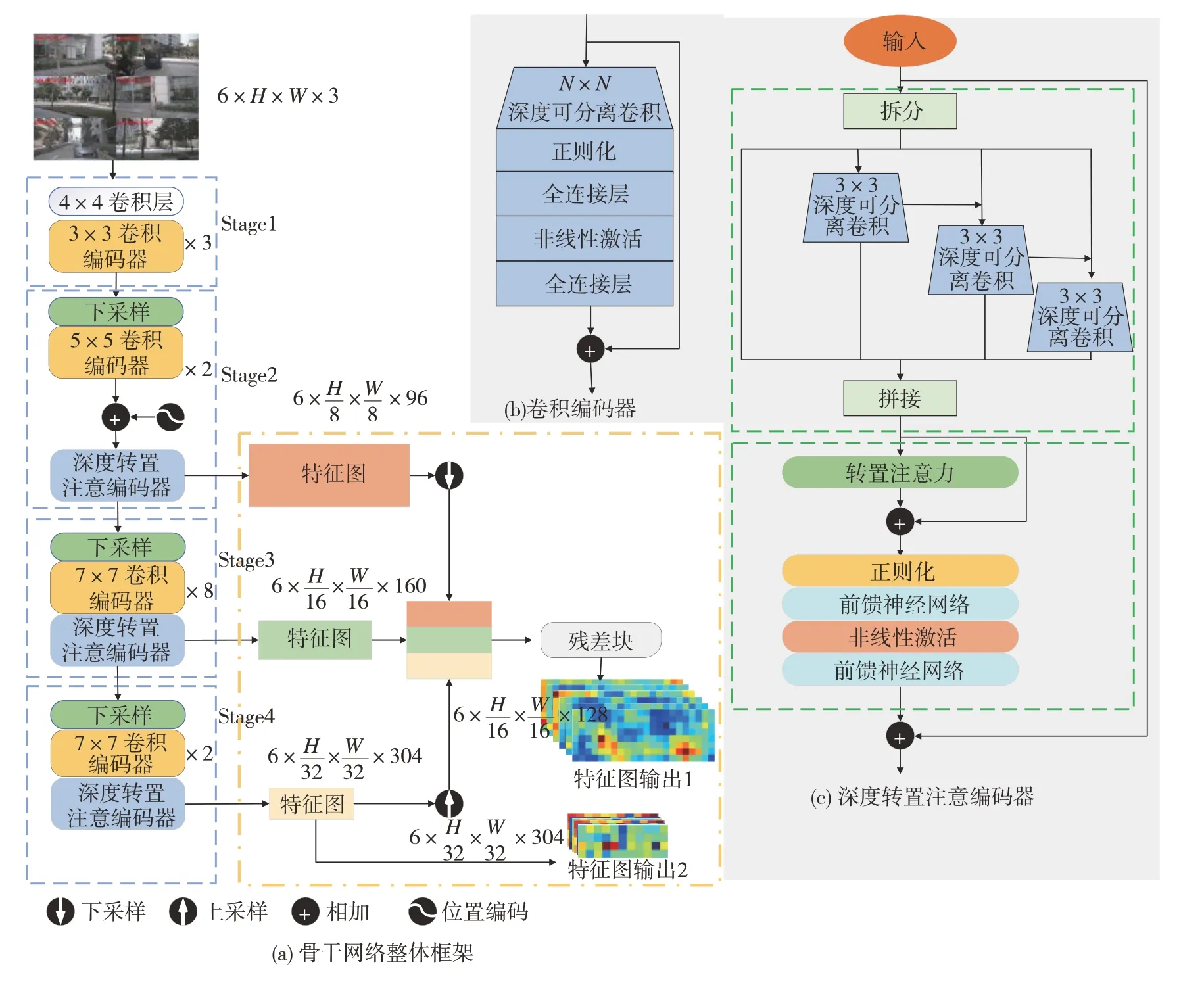
图2 骨干网络结构
特征金字塔如图2 中的黄框所示,金字塔搭建在Stage 2、3、4的输出上,图像经过多个Stage得到宽高下采样8 倍、16 倍、32 倍的特征图。对Stage 2 的输出下采样2 倍,Stage 4 的输出上采样2 倍率,同时与Stage 3 的输出拼接,拼接结果通过一个残差块聚合特征。高层特征和浅层特征在通过残差块融合,进一步增强了特征的表达能力。骨干网络的金字塔的输出,分别为宽高下采样32倍和下采样16倍大小的特征图。
1.2.2 卷积编码器
受到MobileNet[20]和ConvNeXt[21]启发,卷积编码器由一系列深度可分离卷积和残差连接组成,深度可分离卷积由深度卷积和逐点卷积组成。对应不同的骨干网络模块,深度卷积采用不同的卷积核大小来提取特征,同时使用正则化和高斯误差线性单元(GeLU)非线性激活特征映射,如式(1)所示。
式 中:xi∈RH×W×C为输 入特征 图;xi+1∈RH×W×C为输出特征图;Pw为逐点卷积;Dw为深度卷积;N为正则化;G为GeLU激活函数。
1.2.3 深度转置注意力编码器
深度转置注意力编码器由两个基本模块组成。在第1个模块内,输入由通道方向被切分为均等的4个子集,每个子集由上一个子集的输出特征融合后,再通过3×3大小的深度可分离卷积得到,最终将4个子集拼接后得到不同空间级别的多尺度感受野特征。模块2 通过转置注意力编码全局图像特征表示,不同于传统多头自注意力对空间维度的外积计算,转置注意力对跨通道维度外积,从而生成全局表示的潜在表达注意力特征图。具体步骤如下。
(1) 将输入特征图转化为序列向量,通过一个线性投射层得到查询(Query,Q)、键(Key,K)和值(Value,V),即
式中:M为线性投射层;Xp为图像特征,Xp∈RC×H×W。
(2)Q的转置和K点乘计算并通过softmax 归一化后和V相乘得到自注意力图,即
(3) 将得到的注意力图与输入残差连接并将序列向量变换回特征图,如式(4)所示。
式中:Xo∈RC×H×W为输出特征图;R为resize操作。
1.3 交叉视图转换编码器
为了实现透视图特征到BEV 特征的转换,CVT网络提出了交叉注意视图模块,该方法构建的BEV查询与全部视图进行交叉注意力操作,带来了一定的计算资源消耗。本文在此基础上提出的交叉视图转换器通过将BEV 网格划分为多个窗口,窗口内的BEV 查询仅和自身感兴趣视图完成交叉注意力,这种方式能够为窗口内的查询提供显式的指引,带来一定的性能提升,并且有效地降低模型计算量。
1.3.1 BEV局部窗口查询构建
将环视透视图特征F∈RN×H×W×C转换为BEV特征G∈RX×Y×C,H和W为像素大小,X和Y为网格大小,BEV 网格长度由感知距离与分辨率决定。为了减少交叉注意力计算的复杂度,模型先下采样BEV 网格尺寸,在完成视图转换后再通过上采样残差块还原BEV 原始大小。然后根据相机的内外参将BEV 网格投影至图像坐标系,并结合相机视角场(field of view,FOV),得出组成环视的6 个相机在BEV下的FOV,如图3所示。

图3 视图FOV
针对不同相机视图FOV 区域存在重叠,可根据相机视角FOV 确定BEV 网格内所有网格点所关联的视图。将BEV 网格划分为多个窗口,窗口内的网格查询只与该窗口对应的感兴趣视图进行交叉注意力。如图4 所示,本文将BEV 网格划分为4 个窗口,每个窗口会与3 个视图进行交叉注意力,如深蓝色窗口对应的FOV则为前视、左前视、左后视。

图4 BEV窗口对应视图
1.3.2 交叉视图注意力
BEV 坐标Xw通过相机内外参可以转化为图像坐标XI,计算公式如下:
式中:u、v为图像坐标;d为深度;I为相机内参矩阵;E为相机外参矩阵。
由上式可知,BEV 坐标能够通过内外参重投影回透视图坐标系。与之相反,由于缺少深度d,透视图坐标难以转换至BEV坐标系下。
本文通过构建透视图像反投影的BEV 坐标和BEV 网格坐标之间的余弦相似度完成交叉注意力,从而隐式学习图像深度完成视图转换。
交叉视图注意力具体实现过程如下。
(1) 根据透视特征图大小,构建特征图的反投影索引,并通过线性投射层得到Key,即
式中:Key∈Rn×hw×d;E为相机外参;I-1为相机内参的逆;M为线性投射层。
(2) 透视图特征经过线性投射层得到Value,即
其中Value∈Rn×hw×d
(3) BEV 查询Q、反投影K和图像特征V之间完成交叉注意力,如式(10)所示。
1.3.3 局部窗口交叉注意力
通过构建BEV 查询和所有视图之间的交叉注意力,即可以实现透视图到BEV 的特征转换。然而BEV 查询的网格点并不与所有视图都关联,该方式计算量如式(11)所示。本文提出的局部窗口交叉注意力如图5 所示,通过将查询划分为局部4 个窗口,每个局部窗口与3 个关联视图进行交叉注意力,局部窗口交叉注意力的计算量仅为全局交叉注意力一半,计算量如式(12)所示。通过建立窗口查询和关联视图之间的交叉注意力不仅能有效减少计算量,还能够指导BEV查询关注正确的局部区域。
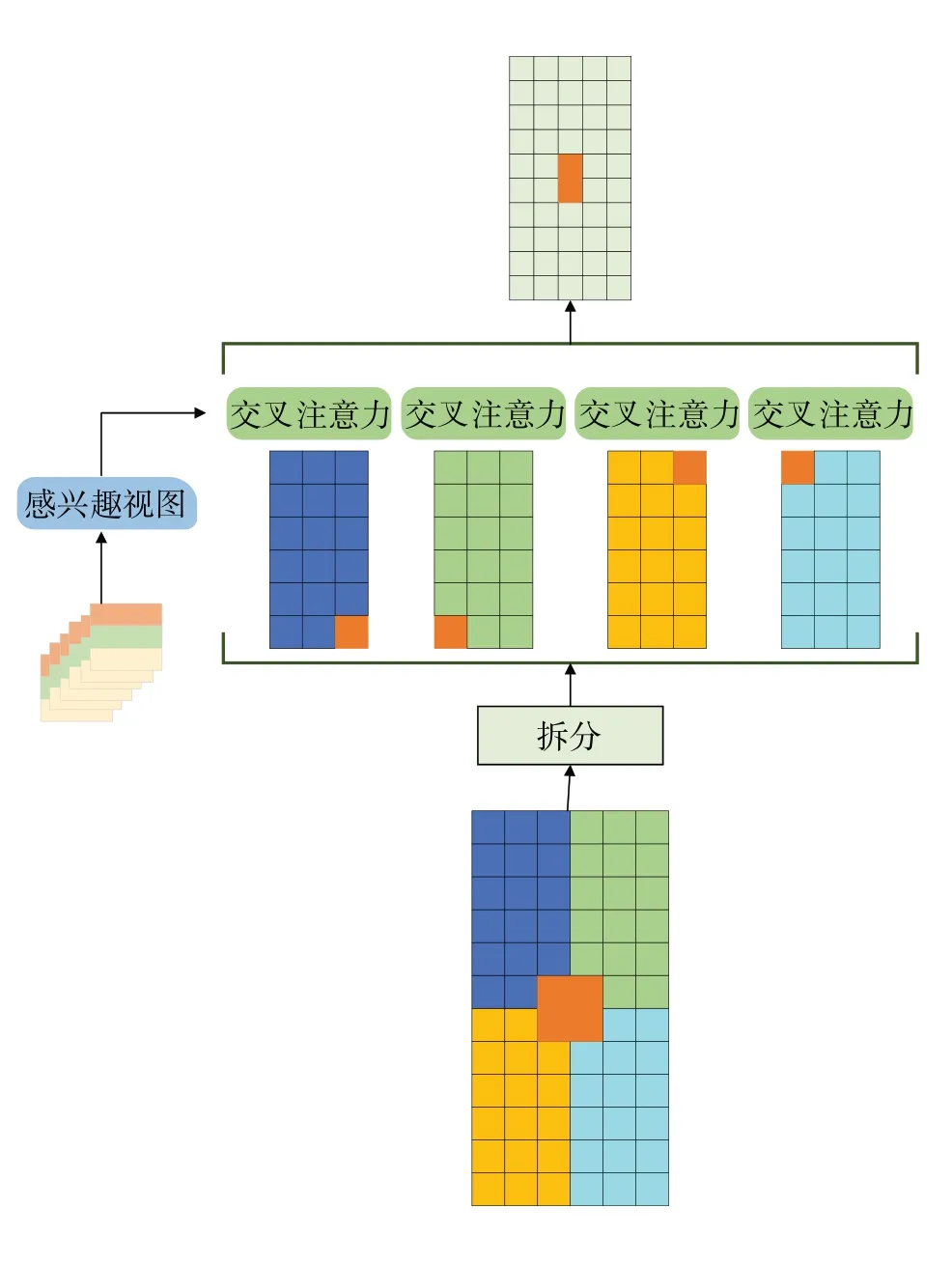
图5 局部窗口交叉注意力
式中:F为计算量;n为视图数量;xy为BEV 查询网格总数;hw为透视图像素数;C为注意力通道数。
1.4 BEV特征解码器
BEV 特征解码器由上采样残差块和分割头组成,交叉视图转换编码器得到的BEV 特征图通过上采样残差块进一步提高BEV 分辨率,最终通过分割头解码得到图像语义分割结果。
2 实验结果和分析
2.1 实验设置
图像原始尺寸为1600×900,被调整到128×352作为网络输入。BEV网格X轴范围为[-30 m,30 m],Y轴范围为[-15 m,15 m],间隔为0.15,BEV 分辨率为400×200。BEV 查询8倍下采样后,BEV 网格查询大小为50×25。模型训练时采用AdamW 优化器,初始学习率为1e-4,权重衰减为1e-7。模型框架使用Pytorch1.12.1+Cuda11.6。模型使用的硬件为Intel i5-13600kf CPU, GeForce RTX 4090 GPU,32 GB 内存,操作系统为Ubuntu22.04。
2.2 实验结果
图6为本文方法在晴天、雨天和黑夜3种不同能见度场景下的推理结果。如图6(a)所示,晴天场景下特征非常明显,模型能有较好的分割结果,精确度最高且尺度基本一致。雨天场景下能见度下降,且由于雨水落在车道上导致部分静态车道特征变化,雨天分割结果精度下降。但本文方法在雨天环境仍有相对较好的分割精度,如图6(b)所示,红色框对应的道路边缘区域在预测图中也能被很好地分割。黑夜场景下,能见度不足导致模型难以提取出有效的特征,并且对远距离的目标分割存在一定难度,因此通常难度远大于晴天和雨天场景。图6(c)红色框内区域为左转路口,在透视图像中的特征不明显,容易被认定为直行区域,从而使模型推理困难。但本文方法仍能对此做出合理的推理,强大的骨干特征提取网络能够有效利用局部特征,从而认定道路边缘分割存在向左趋势。可以认为,本文所提方法在不同能见度场景下都能有着不错的分割结果。

图6 模型推理结果
2.3 消融实验
为了验证改进型EdgeNeXt 骨干网络和局部窗口交叉注意力对模型性能的影响,对EdgeNeXt 骨干网络、金字塔结构、局部窗口交叉注意力进行多组消融实验。初始模型为骨干使用EfficientNet-B0 的CVT方法,实验结果如表1所示。

表1 消融实验结果
由表1 可知,模型骨干网络改进和局部窗口交叉注意力方式都能有效地提升模型的分割性能。具有Transformer 全局信息和CNN 局部信息捕获能力的改进型EdgeNext 相比较初始模型的EfficientNet-B0,能够以相同的推理时间达到更好的分割性能。同时在基本不增加推理延迟的情况下,局部窗口交叉注意力使BEV 查询落在感兴趣区域内,有效地提升了推理速度。在少量增加推理延迟情况下平均IoU提升近5%,实现了对车道线、人行横道和道路边缘的分割,证明了本文方法的有效性。
2.4 对比分析
本文的方法在nuScenes[22]验证集上与其他方法的实验结果对比如表2所示。

表2 语义分割结果
由表2 可知,本文提出的方法在各项子任务中超过了目前表现最好的HDMapNet 方法,IoU 分别提升1.6%、2.1%和2.9%,平均IoU 提升2.2%。图7为本文方法与LLS、HDMapNet 对比结果。可以看出本文方法对远处目标有着更好的分割结果,且在部分局部细节上远远优于其他方法,如图7 所示红色圆框区域。表2 中列出了不同方法的具体量化指标,与目前计算量最少模型GKT 相比,本文方法计算量仅为其51.2%,推理速度提高58.2%,也是表中FPS值唯一超过100的方法。
2.5 相机离线工况实验
车辆实际工作中相机可能因接触不良、相机故障等导致相机离线。为验证在特殊工况下模型的鲁棒性,本文进行了仅有前视和后视图像输入条件下的算法验证。本文提出的方法提取前视和后视的特征,通过局部窗口交叉注意力模型转换到BEV 视图,如图8 所示。根据前视和后视FOV 在本文方法的图上分别绘制两条FOV 虚线,前视和后视的静态车道线被成功分割出来且位于虚线内,虚线外的其他视图由于缺少输入并未被分割。相比之下,HDMapNet 的视图转换模块MLP 却将部分前后视图特征转换至虚线区域外,且位于前后视图内的区域分割结果也不理想。可以认为,本文方法在缺少其他视图情况下,仍能对前视和后视FOV 内的静态车道线准确推理,而HDMapNet 均推理失败,说明本文方法更具鲁棒性,在多个车载相机离线情况下仍然有较好的推理结果。

图8 离线工况模型对比
3 结论
(1) 为解决多相机带来的计算量上升问题,本文提出基于局部窗口交叉注意力的轻量型语义分割方法,通过采用改进型EdgeNeXt 骨干网络和局部窗口交叉注意力使推理达到106 FPS,速度比GKT 模型提高58.2%,满足自动驾驶实时需求。
(2) 通过改进型骨干网络提取特征,并使用局部窗口交叉注意力完成对跨相机透视图之间的特征转换,使注意力查询落在感兴趣透视图上,以减少计算量并提高模型的分割性能。
(3) 与HDMapNet模型相比,平均IoU提高2.2%,达到了35.1%;进行了相机离线工况实验,能够有效转换对应的透视图,且分割结果位于视图FOV 内,表明本文方法具有更好的分割性能和鲁棒性。
