基于深度学习的软件自动修复方法的修复偏好研究
2023-10-12姜元鹏姜淑娟
姜元鹏,黄 颖,姜淑娟
1.中国矿业大学 图书馆,江苏 徐州 221116
2.中国矿业大学 计算机科学与技术学院,江苏 徐州 221116
软件缺陷修复是软件调试维护过程中的重要环节,并且随着软件复杂程度的增加以及软件规模的扩大,人工定位并修复软件缺陷越来越难实现,且面临成本昂贵、难以修复等问题[1-2]。而利用软件自动修复方法可以大幅度提高软件调试的效率,减少软件维护所耗费的开销。近年来,随着深度学习技术的发展,越来越多研究人员将深度学习方法引入到软件自动修复领域,软件自动修复方法成为软件工程领域研究热点[3-5]。
目前主要的传统的软件自动修复方法可以分为基于搜索的方法与基于语义的方法,国内外专家学者已经重点对传统的基于搜索的程序自动修复方法以及基于语义的软件自动修复方法进行了大量研究[6-9];近几年提出了不少基于深度学习的软件自动修复方法[10-12],基于深度学习的软件修复方法主要从使用学习模型学习正确补丁特征、学习搜索相似性代码以及学习错误代码与正确代码的转换等角度来生成正确补丁。
目前的深度学习的软件自动修复方法大多是通用的,即不针对某种特定的缺陷类型,更多的是引入深度学习模型与相关的程序分析技术尝试修复软件代码中的所有缺陷。而通用的自动修复方法由于针对性不强,因此对不同类型缺陷的修复效果通常是不同的。在已有的文献中,部分文献对修复的缺陷进行了简单的分类,但是并没有系统地对缺陷库中的缺陷进行分类;不同类型的缺陷以及补丁具有不同的特征,在基于深度学习的程序自动修复方法中,深度学习模型的选择是至关重要的,因为不同模型可能提取的特征不同。目前基于不同学习模型的程序修复方法针对不同类型缺陷的修复偏好尚不明确,在现存的文献中没有关于基于深度学习的软件自动修复方法以及不同学习模型对不同缺陷类型修复性能的研究,因此,本文拟在对缺陷分类的基础上通过分析比较近几年有代表性的深度学习自动软件修复方法对不同缺陷类型的修复偏好,可以帮助研究人员更好地了解不同的深度学习模型在软件自动修复当中的作用,以便更好地进行软件自动修复工作。
1 基于深度学习的软件修复工具
目前几种比较常用的基于深度学习的软件缺陷修复工具,其使用的深度学习模型包括自编码器、卷积神经网络、循环神经网络、长短期记忆模型,它们的相关修复工具信息如表1所示。

表1 修复工具信息Table 1 Ⅰnformation about repair tools
表1 的第一列为5 种自动修复工具;第二列是每种修复工具使用的模型,其中EDM指的是编码器-解码器模型(encoder-decoder model,EDM),LSTM-EDM 即为基于LSTM 的编码器-解码器模型,同理CNNs-EDM 是指基于CNNs的编码器-解码器模型,attention指注意力机制,copy 则是指复制机制;第三列是各种工具工作的代码粒度,包括了多粒度级、代码行以及方法级;最后一列则是各个工具用于评估的数据集,这5种自动修复工具都在Java程序的缺陷库Defects4J[13]上进行验证评估。
1.1 DeepRepair
DeepRepair[14]工具旨在通过深度学习代码的相似性排序并转换语句来推导程序修复成分,主要使用的学习模型为嵌入模型与自编码器。实现这一工具的技术方法可分为三个阶段:语言识别、机器学习与程序修复阶段。该工具的方法框架如图1所示。

图1 DeepRepair方法框架Fig.1 Framework of DeepRepair
1.2 SequenceR
SequenceR[15]是一种基于序列到序列的端到端的程序修复方法,该方法主要使用两层的双向长短期记忆模型。这一技术主要分为两个阶段:训练以及推理阶段。如图2为SequenceR的方法框架。
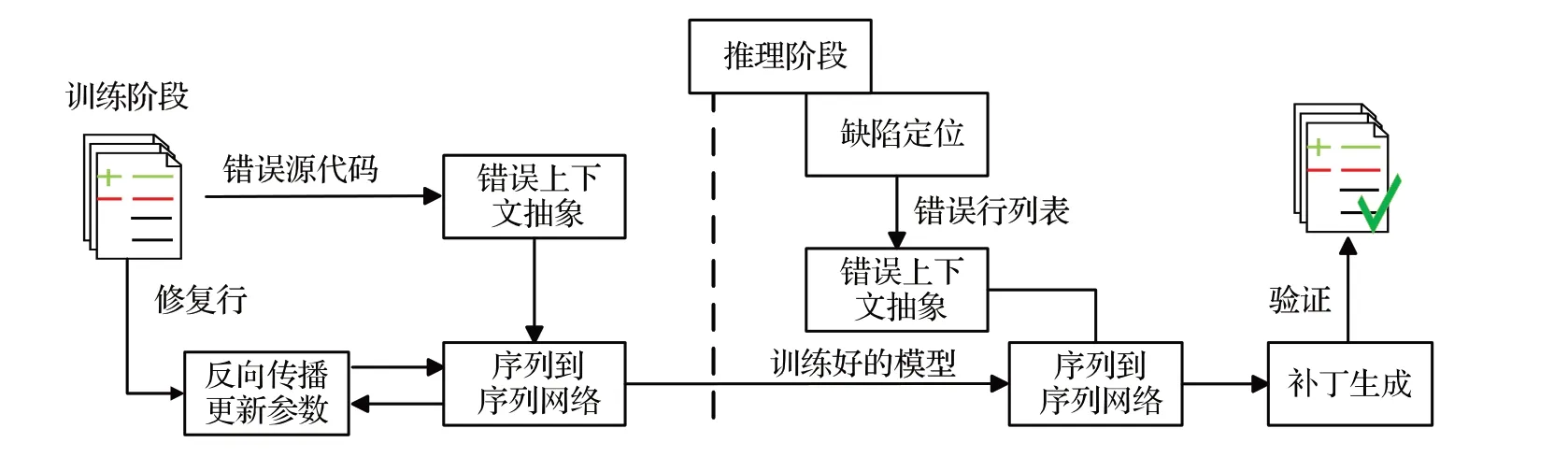
图2 SequenceR方法框架Fig.2 Framework of SequenceR
1.3 CODIT
CODⅠT[16]使用基于树的神经网络对源代码更改进行建模并学习代码更改模式,即利用一个基于树神经机器翻译模型来学习代码中更改的概率分布,该方法包括两个模型,使用的都为LSTM。如图3 所示,实现这一工具同样为三个阶段:补丁预处理、模型训练、模型测试阶段。
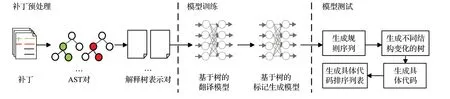
图3 CODⅠT方法框架Fig.3 Framework of CODⅠT
1.4 DLFix
DLFix[17]是用于程序自动修复的基于上下文的代码转换学习方法,使用的是双层基于树的深度学习模型,该深度学习模型同样为LSTM。工具实现主要分为四个阶段:预处理、模型训练、程序分析过滤和补丁重排序阶段。如图4为DLFix的方法框架。

图4 DLFix方法框架Fig.4 Framework of DLFix
1.5 CoCoNuT
CoCoNuT[18]结合上下文感知的神经机器翻译模型并使用集成学习来进行跨多语言的自动修复,主要使用的神经网络模型为卷积神经网络,这是卷积神经网络在程序自动修复中的首次应用。如图5所示,这一技术同样包括三个阶段:训练、推理和验证阶段。

图5 CoCoNuT方法框架Fig.5 Framework of CoCoNuT
2 缺陷分类研究
2.1 缺陷分类
缺陷分类有很多种方法,根据不同的分类目的,缺陷分类的过程、复杂度和应用领域也不同。在程序修复领域,Pan 等人[19]提出了针对Java 程序中的缺陷分类方法,并将缺陷根据语句特征分为9 大类。参照Pan 等人[19]及Liu 等人[20]提出修复模式,总结了10 个缺陷修复模式,并对缺陷库Defects4J中缺陷进行分类。
通过对Defects4J 中的补丁进行分析,总结了基于代码更改操作的10 个基本的缺陷类型,每个类型下会有不同的子类型。
(1)ⅠF语句:这一类是与ⅠF语句相关的缺陷,包括增加/删除ⅠF谓词、增加/删除ⅠF主体、增加/删除else语句、ⅠF条件表达式的更改,以及ⅠF语句与其他语句的替换。
(2)方法语句:这一类是与方法语句相关的缺陷。包括增加/删除/更改方法声明、增加/删除方法调用、更改调用方法、更改参数值或参数数量、其他语句与方法调用的替换。
(3)循环语句:这一类是与循环语句相关的缺陷。包括增加/删除循环、循环条件更改以及其他语句与循环体之间的替换。
(4)赋值语句:这一类是与赋值语句相关的缺陷。包括增加/删除赋值语句以及赋值表达式的更改。
(5)switch:这一类是与switch语句相关的缺陷。主要包括增加/删除case分支/switch条件的更改。
(6)try/catch:这一类是与try/catch 语句相关的缺陷。包括添加/删除try语句或catch语句块。
(7)return:这里的return 指代是return/break/continue/throw(抛出异常)语句,这类缺陷是指与它们相关的缺陷。包括增加/删除这些语句、return 表达式的更改,以及这些语句之间的替换。
(8)类字段:这一类是与类字段相关的缺陷。包括类字段声明更改、执行多个类实例创建。
(9)移动语句:这一类主要是指需要改变语句所在位置的缺陷。
(10)其他:这一类缺陷的修复包括类型更改、运算符更改、变量更改、整数除法更改。这些类型排除之前提到过的相关类型。
2.2 评测对象
由于目前Defects4J 是软件自动修复工具最常使用的基准集,且进行比较的几种基于深度学习的软件自动修复工具都可在Defects4J 上进行评估,Defects4J 缺陷库中的缺陷类型包括6 个项目,如表2 所示。这里使用的是Defects4J-v1.1.0

表2 Defects4J 的组成Table 2 Composition of Defects4J
在使用Defects4J数据集时,需要根据不同的模型对数据集进行不同的预处理。比如,在使用工具SequenceR时,由于SequenceR 专注于修复单行缺陷代码,所以需要排除掉Defects4J中的非单行缺陷;在使用CODⅠT时,则需要从Defects4J的6个项目中创建一个代码更改集。
2.3 Defects4J缺陷类型分析
Defects4J中全部缺陷类型组成,如表3所示。

表3 Defects4J中缺陷的类型Table 3 Types of defects in Defects4J
Defects4J中与ⅠF语句相关的缺陷多达230个,占所有缺陷的58.5%,其中类型为“增加ⅠF主体的缺陷”数量最多,有120个,占ⅠF语句缺陷类型的51.9%,其次有80个缺陷为“ⅠF条件表达式更改”类型,占ⅠF语句缺陷类型的34.6%;方法语句类型:Defects4J 中与其相关的缺陷有92 个,是全部缺陷的23.3%,是除ⅠF 语句类型外最多的缺陷类型,而其中“更改方法调用参数”类型的缺陷数量最多;除此之外,Defects4J 中与return 语句类型相关的缺陷数量最多,共50个,占Defects4J中缺陷的12.7%;最少的是try/catch类型。要注意的是,由于Defects4J中的缺陷一般包含多个错误行,因此一个缺陷可能和多种缺陷类型相关,在表3 中,将Defects4J 中的缺陷归到某一类时,主要是指该缺陷包含该缺陷类型的错误行,所以每种缺陷类型的缺陷数量之和会超过Defects4J中的缺陷数量395,因为同一个缺陷可能会与多种缺陷类型相关。
3 实验
该实证研究的目的是研究基于深度学习的软件自动修复方法对不同类型缺陷的修复偏好。为此,首先分析基于深度学习模型的软件自动修复方法整体上对不同类型缺陷的修复概率,然后比较不同学习模型对不同类型缺陷的修复偏好,并比较分析每种方法各自更倾向于修复哪一类型的缺陷。
本文实验的运行环境为64 位Windows 与Linux 系统,编译环境为Python3。
3.1 不同缺陷类型的总修复概率
表4展示了5种修复工具通过实验修复的不同类型缺陷的总的修复概率。由第三列可以看出,5种修复工具修复的缺陷类型涉及了除try/catch语句之外的9种基本类型,修复的缺陷数量最多的3种缺陷类型依次为ⅠF语句类型、方法语句类型以及return语句类型,然后是赋值语句与类字段类型的缺陷。而try/catch 语句类型的缺陷没有得到修复的原因,可能是Defects4J 中这一类型的缺陷量最少,总共只有5个。
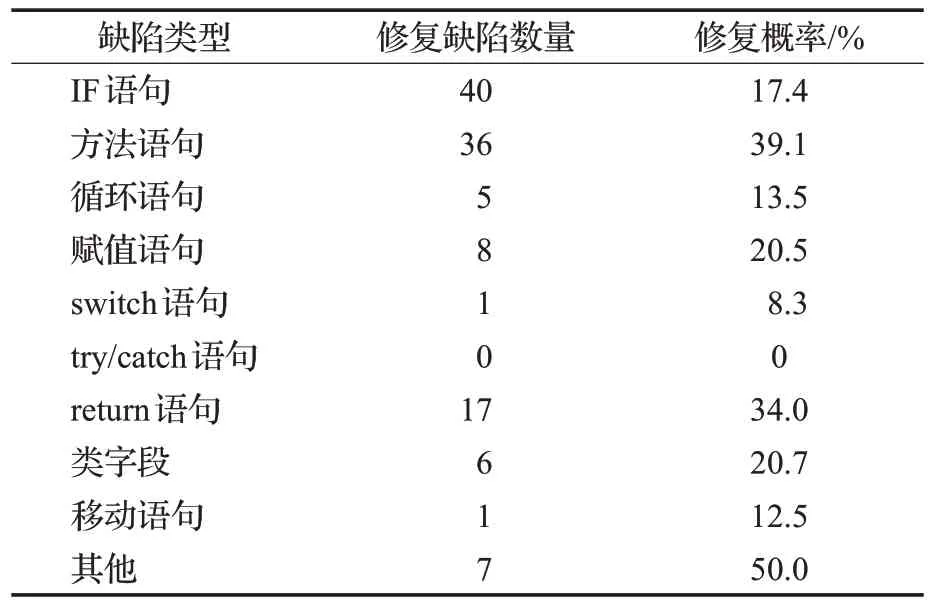
表4 所有修复缺陷的缺陷类型Table 4 Types of all repaired defects
表4所示的修复概率可以看出,其他类型的缺陷修复概率最高,其次是方法语句类型的缺陷,然后是return语句类型,赋值语句与类字段类型的修复概率相当,其后才是ⅠF语句类型的缺陷。可以看出,修复概率与修复缺陷数量并不是成正比的关系,基于下面的原因。
首先,其他类型的缺陷基本上只包含运算符更改、类型更改等简单易修复的缺陷,而且数据集中这一类缺陷数量较少,因此尽管结果显示这一类缺陷修复概率较高,但这只是表明修复方法倾向于修复复杂程度低的缺陷,而方法语句与return语句类型的修复概率较高,与之对应的修复缺陷数量也较高,可以得出基于深度学习的软件自动修复方法对这两种缺陷的修复偏好是较高的;对于赋值语句与类字段类型来说,由于类字段类型当中包括类字段的声明与赋值,所以这两种在很大程度上可以看作是赋值语句类型,因此两者的修复数量与概率都相差不大;对于ⅠF语句,从缺陷分类的结果可以看到,数据集中与这一类型相关的缺陷数量最多,而复杂程度较高的缺陷基本都与这一类型相关,复杂程度越高越难以修复,因此这一类型相关的缺陷修复概率与前面几种相比显得不高。
因此,经过综合分析后可以得知:对于修复的缺陷数量来说,基于深度学习的软件自动修复方法修复最多的是ⅠF 语句类型、方法语句类型、return 语句类型的缺陷,但是对于缺陷修复的概率来说,由于受到缺陷复杂程度的影响,基于深度学习的软件自动修复方法对ⅠF语句的修复概率较低,其他类型的缺陷修复概率较高,同时修复方法语句类型、return语句类型、赋值语句与类字段类型缺陷的概率也较高。
3.2 缺陷的修复偏好比较分析
表5 展示了基于不同深度学习模型的软件修复工具在Defects4J上修复的不同类型的缺陷数量。第一列为缺陷类型,第二至六列是5种缺陷修复工具的修复缺陷数量;最后一行的缺陷总数总是小于等于10 种缺陷类型的修复缺陷数量之和,因为存在同一缺陷与多种缺陷类型相关的情况。

表5 各修复工具修复缺陷的缺陷类型组成Table 5 Types composition of defects repaired by each repair tool
如果仅从表4的占比来看,每一种类型缺陷的修复偏好相差不大,其根本原因在于现有的缺陷自动修复方法修复能力不足。例如,表5 中所示的修复Defect4J 数据集缺陷最多的DeepRepair 方法,仅仅修复了51 个缺陷,占总缺陷数的12.9%(51/395),使得每一种类的修复占比都比较低,差距小。在此背景下,DeepRepair 修复24个ⅠF语句类型缺陷,10个方法语句缺陷,前者是后者的2.4倍,由此可以看出修复偏好相差较大。
整体来看,除了CODⅠT之外,其他每种修复工具与3.1节的结论相符,修复最多的缺陷为ⅠF语句类型、方法语句类型以及return 语句类型的缺陷;对于CODⅠT,除了方法语句类型以及return语句类型的缺陷,修复的类字段类型的缺陷比ⅠF语句类型的缺陷更多。从最后一行可以看到,基于自编码器且在多粒度上运行的Deep-Repair 修复的缺陷最多,与其他的修复工具相比,它修复的ⅠF语句类型、循环语句类型、赋值语句类型以及类字段类型相关的缺陷数量明显高于其他工具,原因是DeepRepair使用了多个修复策略,并在多个粒度上寻找补丁。由此可知,修复策略、工作粒度对学习模型的修复效果具有极大的促进作用;而SequenceR修复的缺陷数最少,因为它只针对单行缺陷。下面详细分析比较几种修复方法的修复结果。
(1)基于LSTM、AE以及CNNs模型修复工具的修复结果分析
由于SequenceR、CODⅠT 与DLFix 使用基本的深度学习模型都为基于LSTM的编码器-解码器的神经机器翻译模型,可将三者的修复结果合为一体以LSTM 表示,与其他两种工具的修复结果进行比较;AE指的是基于自编码器的DeepRepair 的结果;CNNs 指的是基于CNNs的CoCoNuT的结果。
如图6通过韦恩图表示了3种学习模型所修复缺陷的重叠的情况,重点关注修复结果的不同之处,并结合表5分析图6中非重叠的部分的缺陷。

图6 3种不同学习模型修复缺陷的重叠情况Fig.6 Overlapping of repaired defects of three different learning models
首先,对于DeepRepair,非重叠部分的27个缺陷,其中有48.1%的缺陷与ⅠF语句类型相关,这表明与其他模型相比,它更擅长于修复ⅠF 语句类型的缺陷,这与表5中的结果一致;同时,DeepRepair 修复的缺陷种类数是最多的,只有它修复了一个移动语句类型的缺陷,而且它修复缺陷中的赋值语句类型的缺陷占比明显高于其他两种基本学习模型。这表明基于自编码器且拥有多种修复策略与工作粒度的软件自动修复方法在修复的缺陷数量和缺陷类型数量上具有一定优势。
其次,对使用基于LSTM 的编码器-解码器的神经机器翻译模型的修复方法来说,与其他两种模型相比,它们修复的26个缺陷中与方法语句类型相关的缺陷数最多,占比达到61.5%,这表明本文用于比较的3种基于LSTM 的修复方法整体上更倾向于修复方法语句类型的缺陷,这同样与表5中的结果一致;同时,只有它独自修复的缺陷中包含switch类型的语句。
最后,对于基于CNNs 的修复工具CoCoNuT 来说,不仅是从非重叠部分的11个缺陷的分析,还是从表5的分析中都可以发现,它的修复结果中,与ⅠF语句类型、方法语句类型以及return语句类型相关的缺陷数量相差不大,这表明它对这3 种类型缺陷的修复偏好相差不大。而从缺陷的复杂程度来看,DeepRepair 与CoCoNuT 能修复更高复杂程度的缺陷。
(2)SequenceR与CODⅠT的修复结果分析
对于同样使用LSTM模型的两种修复方法SequenceR与CODⅠT来说,SequenceR是序列到序列的神经机器翻译模型,CODⅠT 是基于树的序列到序列的神经机器翻译模型,如图7是SequenceR与CODⅠT的修复结果的重叠情况。
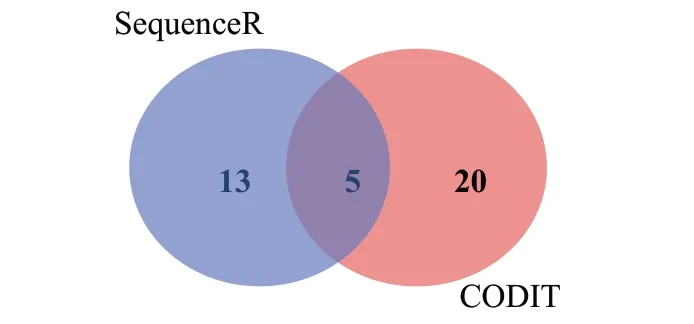
图7 SequenceR与CODⅠT修复缺陷的重叠情况Fig.7 Overlapping of repaired defects of SequenceR and CODⅠT
其中SequenceR 单独修复13 个缺陷,而CODⅠT 单独修复20个缺陷。在非重叠部分,SequenceR修复更多的是与ⅠF 语句类型相关的缺陷,而CODⅠT 修复更多的是与方法语句类型相关的缺陷。造成这一结果的原因是SequenceR 是序列到序列的模型,针对的是代码行,而CODⅠT和DLFix都是方法粒度的。这说明工作粒度在很大程度上影响了修复的缺陷类型。
(3)CODⅠT与DLFix的修复结果分析
对于使用LSTM 模型的两种修复方法CODⅠT 与DLFix来说,CODⅠT是基于树的序列到序列的神经机器翻译模型,而DLFix则是双层基于树的代码转换的神经机器翻译模型,如图8是CODⅠT与DLFix的修复结果的重叠情况,CODⅠT单独修复缺陷17个,而DLFix单独修复缺陷32个。对图8的非重叠部分的缺陷进行分析,并结合表5可以看到,使用DLFix比CODⅠT能够修复更多缺陷;同时,从表5中可以看到,CODⅠT主要修复方法语句类型缺陷而较大程度上忽略ⅠF 语句类型的缺陷,而DLFix则弥补了这一缺陷,它对这两种类型缺陷的修复偏好相差不大。
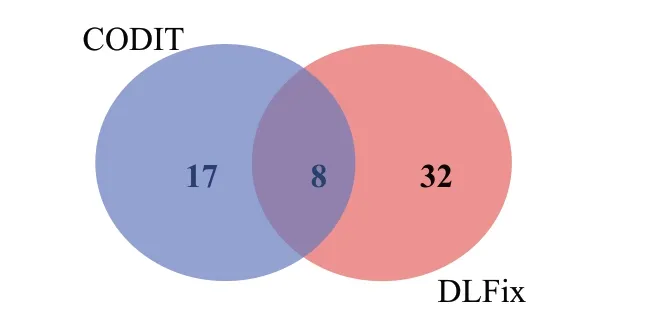
图8 CODⅠT与DLFix修复缺陷的重叠情况Fig.8 Overlapping of repaired defects of CODⅠT and DLFix
3.3 有效性影响因素分析
可从内部有效性和外部有效性两个方面来分析可能影响到本文实证研究结论有效性的影响因素。
影响内部有效性的因素主要来自两个方面,一个是缺陷分类的标准,另一个是用于比较的修复方法。对于缺陷分类,本文参考了多篇文献,根据修复模式逐个对缺陷进行了分类,保证了分类的准确性;对于修复方法,本文主要比较的是文中选取的五种修复方法的结果,而其他修复方法的结果如何有待进一步研究。而且在研究不同模型对缺陷类型的修复偏好时,其他因素(如工作粒度等)的影响较大,之后的工作可以进行探讨。
而影响外部有效性的因素主要来源于缺陷库。Defects4J中部分项目的缺陷数量较少,因此在分析不同项目内的缺陷时对结果的影响较大,但是本文主要是针对整体缺陷进行研究,因此很大程度上可以避免这一影响;而Defect4J 数据集不涉及深度学习模型的训练,只是对训练后的深度学习模型进行评估。本文之所以选取Defect4J进行分析,是因为本文中所有的方法在评估时都用到了该数据集。同时,Defect4J数据集是一个被广泛使用的缺陷基准数据集,涉及的缺陷类型全面,适合进行缺陷修复偏好研究。为了进一步减少数据集方面存在的有效性威胁,在未来的工作中,将进行更全面的实验,从而分析本文中的这些方法在更多缺陷基准中的修复偏好性。
4 结束语
本文根据缺陷修复模式对Defects4J 中的缺陷进行分类,通过实验给出了5种基于不同学习模型的修复工具 在Defects4J 上整体的修复概率,同时分析这5 种修复工具各自在Defects4J 上的修复结果,并对各类缺陷的修复偏好进行比较分析。实验结果表明,基于深度学习的软件自动修复方法倾向于修复ⅠF语句类型、方法语句类型、return 语句类型的缺陷。基于自编码器的软件自动修复方法DeepRepair 更倾向于修复ⅠF 语句类型的缺陷,选取的基于LSTM 的编码器-解码器的修复方法整体上更倾向于修复与方法语句类型相关的缺陷,而基于CNNs 编码器-解码器的修复方法则对ⅠF 语句类型、方法语句类型以及return语句类型这3种类型缺陷的修复偏好相差不大。
