高效视频编码帧内预测算法优化与硬件架构设计
2023-10-11熊启金丁永强林志坚
熊启金,丁永强,林志坚
(福州大学 物理与信息工程学院,福建 福州 350108)
0 引言
随着信息技术的发展,视频行业正在从高清向超高清时代转变。为了满足在有限的带宽下传输更高质量的视频数据,视频编码联合组提出了新一代高效视频编码(High Efficiency Video Coding,HEVC)标准。与上一代视频编码标准(Advanced Video Coding,AVC)相比,HEVC采用更加灵活的四叉树块划分结构[1]和丰富的帧内预测模式[2],在保证相同视频质量条件下,码率可节省50%,但计算复杂度也成倍增加[3],不利于编码器的硬件实现。
帧内预测利用相邻像素之间的关系消除图像空域上的冗余[4],是HEVC的重要环节之一,其硬件实现成为研究人员关注的热点。文献[5]提出一种基于残差哈达玛变换和头比特代价补偿的帧内预测模式决策算法,简化了帧内预测率失真优化硬件实现的预处理过程,但没有考虑粗选代价对预测块划分决策的影响;文献[6]提出一种简化的预测模式和块划分决策,在一定程度上简化了帧内预测率失真过程,但没有突破帧内预测对重构数据的依赖性,无法对整个硬件回路进行全流水线设计;文献[7]提出一种9路预测模式并行的硬件架构,但其并行模式没有充分利用预测电路的并行性,导致电路利用率不高;文献[8]提出一种对64×64和32×32预测单元进行下采样成16×16大小进行预测计算,在一定程度上缩小了电路面积,但下采样方式的准确度不高,且该方法使用较多的时钟周期,无法实现实时的超高清视频编码。
为了能够在更小的电路面积下实现更高分辨率和帧率的实时视频编码,本文提出了一种帧内预测模式高度并行的全流水硬件架构设计,具体工作如下:① 在模式决策时,采用经哈达玛变换后的绝对误差和(Sum of Absolute Transformed Difference,SATD)与预测模式编码的码率之和作为帧内率失真代价,从而打破了帧内预测对重构数据的依赖,为硬件实现全流水电路设计提供了条件。② 在编码单元(Coding Uint,CU)层间划分决策时,采用代价补偿的方式对子块的代价进行补偿,解决由于粗选代价导致CU层间划分不合理的情况。③ 在硬件架构上,提出基于4×4基本块的18路预测模式并行的全流水硬件电路,在节省硬件资源的同时,充分利用电路的复用性,极大提高了数据吞吐率。
1 本文算法
1.1 帧内模式决策
在HEVC标准测试模型(HEVC Test Model,HM)中[9],帧内模式决策会经过预测模式粗选和细选两个阶段[10]。在模式粗选过程中,首先将基于残差的SATD值从35种预测模式中得到若干个最佳预测模式并放入侯选模式列表中;然后参考上方和左侧预测单元(Prediction Unit,PU)的最佳预测模式生成当前PU最可能的模式列表(Most Probable Mode,MPM),并将其添加到侯选模式列表中。在细选阶段,将粗选过程中得到的侯选模式列表中若干个模式采用码率失真优化(Rate Distortion Optimization,RDO)计算得到率失真代价(Rate Distortion cost,RDcost)并决策出最佳预测模式,RDcost计算公式如下:
(1)
式中:J表示RDcost的值,D表示重构像素与原始像素之间的失真情况,由原始像素和重构像素之间的平方误差和(Sum of Squared Difference,SSD)得到,R表示当前模式编码后的码流比特率,λ为拉格朗日常数,用以平衡图像失真情况和码率的比重,与量化参数(Quantizer Parameter,QP)相关,Oorig为原始像素值,Rreco为重构像素值,| |表示取绝对值。
RDO过程是帧内预测最复杂的部分[11-12],其过程如图1所示。帧内预测的失真情况需要经过预测、变换量化、反变换反量化后,通过对原始像素和重构像素求SSD值得到。帧内预测的码率需要经过预测、变换量化、熵编码等完整的编码过程[13]后得到。最后通过对二者求和,才能得到最终RDcost。
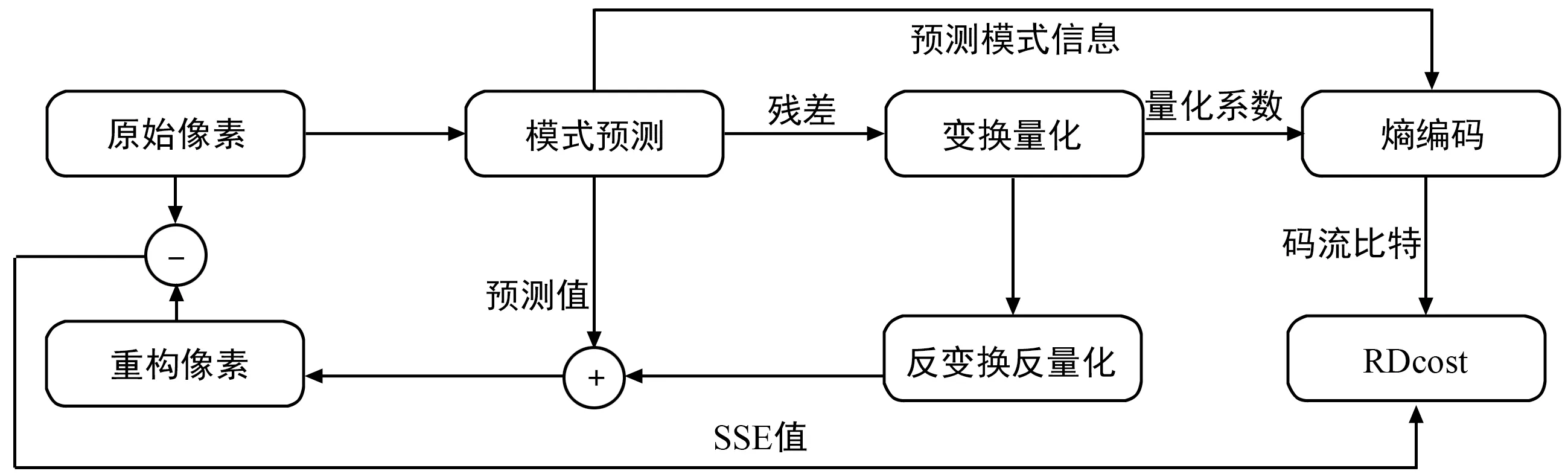
图1 HM帧内预测RDcost计算过程Fig.1 Calculation process of HM intra prediction RDcost
由图1可知,HM提供的RDO算法进行代价计算将会消耗大量的硬件资源且无法满足帧率较高的实时编码需求。为了降低RDO的计算复杂度,文献[14]采用残差的绝对误差和(Sum of Absolute Difference,SAD)估算RDcost,但是SAD仅能反映残差时域的信息,虽然可以降低计算复杂度,但会导致编码器性能的明显下降。文献[15]采用残差的SATD值估算RDcost,尽管SATD值能够反应残差在频域的信息,且性能接近于离散余弦变换后的残差值,但是忽略了帧内预测编码后的头信息码率。HEVC在编码时,对于预测模式属于MPM列表中的模式,编码其在MPM列表中的索引号,而对于不在MPM列表中的模式则采用5 bit固定码长的语法元素进行编码。为打破帧内RDO对重构数据的依赖,降低硬件设计的复杂度,并保持一定的性能,本文采用残差的SATD和模式号的编码比特数来估算帧内预测的RDcost,以简化帧内预测的率失真优化过程,其计算过程如图2所示。
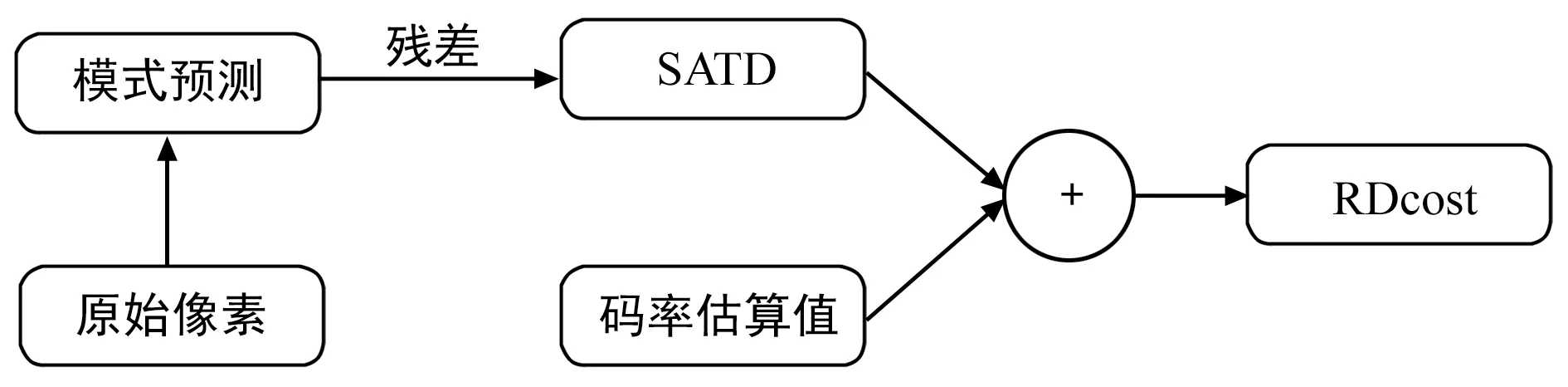
图2 本文帧内预测RDcost计算过程Fig.2 Decision process of this paper RDcost partition
考虑到帧内预测的码率信息不仅仅包含预测模式,还涉及划分方式、量化系数等头信息,故为了平衡SATD与码率的比重,通过对不同权重的拉格朗日系数进行实验统计分析,根据性能测试结果,提出采用3.5×sqrt(λmode)作为拉格朗日系数。考虑到浮点数不利于硬件实现,对码率值进行向下取整,最终得到本文的RDcost算法模型,其计算公式如下:
(2)
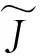
1.2 CU层间决策
在编码结构层面,HEVC采用更加灵活的四叉树块编码划分结构,编码树单元可根据四叉树向下划分成64×64~8×8四个层次的CU。对于帧内预测中CU又可根据N×N和2N×2N的方式向下划分成PU。对于CU层间划分决策,HM采用了自下而上,迭代处理的计算方式。如图3所示,首先计算出4个子块最佳模式的率失真代价之和并与其父块最佳模式的率失真代价进行比较,选择小的代价作为当前CU的代价,并确认当前CU的划分方式。然后依次向上迭代,最终获取当前编码树单元中所有CU的最佳划分方式和对应的最佳预测模式。

图3 CU块划分决策过程Fig.3 Decision process of CU partition
对于CU的层间决策,为了简化硬件实现的复杂度,现有的方案均直接采用粗选代价直接作为CU层间决策的代价。文献[8]采用残差的SATD值与头比特估计值之和的粗选代价作为CU层间决策的代价,其CU层间划分结果如图4(a)所示。相较于基于标准测试模型HM16.7的CU层间划分结果,如图4(b)所示,其4×4和8×8的块相对较多。

(a) 粗选代价

(b) HM16.7

(c) 代价补偿图4 不同代价下的CU划分结果Fig.4 Results of CU partition at different costs
这是由于图像中存在相对不平坦的区域,使用较小的预测块进行预测时,预测值和原始像素的接近程度越高,残差的SATD值越小,从而在此区域中决策出较多的小块。若图像存在较多的小块,则会对编码器后续的重构和熵编码模块造成巨大的负担,从而影响硬件编码器的速度。
基于以上考虑,本文统计了常用QP下不同尺寸CU不向下划分的概率,如表1所示。其中8×8 CU表示的是划分为2N×2N模式PU的概率。为了CU划分更加合理且易于硬件实现,本文在CU层间决策时,对子块的代价和添加一个补偿值,然后再与父块的代价进行比较,从而增加划分大块的概率。对于补偿值的研究,本文通过统计常用QP下各尺寸CU下子块的代价之和与父块的代价差距分布,以表1中各尺寸CU下向下划分的概率为基准,提出表2所示的各尺寸CU子块对应的补偿值。经测试,添加补偿值后图像CU层间划分结果如图4(c)所示,可见在采用本文所提对粗选代价进行补偿的方式下,图像CU层间划分结果明显好于粗选代价直接划分,且接近于HM划分情况。

表1 不同尺寸CU不向下划分概率Tab.1 Probability of CU with different sizes not partition downwards under

表2 不同尺寸CU的代价补偿值Tab.2 Cost compensation value of different size CU
1.3 算法性能
如表3所示,针对不同类型的测试序列,基于标准测试模型HM16.7对本文所提优化算法性能进行测试。由表3可以看出,本文算法在同等码率下的视频质量指标BD-PSNR的损失仅为-0.343 5 dB,编码性能指标BD-rate对比HM16.7也仅增加5.91%,说明本文算法对编码器性能的影响不大,可用于硬件设计上的实现。
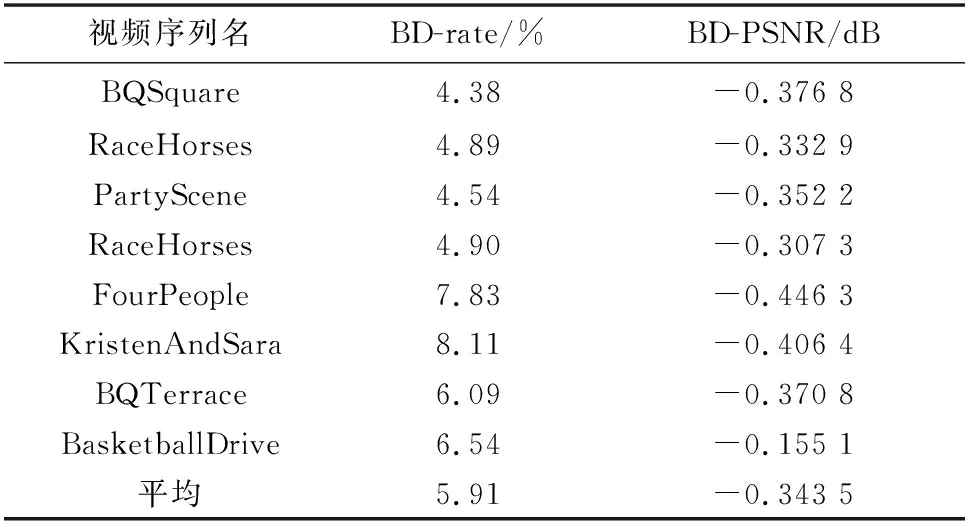
表3 本文算法的编码性能Tab.3 Coding performance of the algorithm in this paper
2 硬件架构设计
2.1 预测模式并行设计
如图5所示,HEVC帧内预测定义了35种预测模式,包含直流模式,平面模式和角度模式。角度模式中将模式2~17作为水平预测模式,19~34作为垂直预测模式。水平模式采用左侧参考像素作为主参考像素,垂直模式采用上方参考像素作为主参考像素。对于预测电路的设计,传统方案均采用预测模式并行的方式来提高吞吐率,文献[5]采用4路预测模式并行的方式,但其数据吞吐率低,无法满足高帧率高分辨率的视频实时编码需求。由图5可知,水平模式和垂直模式关于模式18对称,在预测过程中,预测点的权值和参考像素在主参考像素列表中的位置完全一样。因此,参考像素滤波模块只需要按照水平预测模式和垂直预测模式对滤波后的参考像素进行整理,对称的预测模式可以采用同一个预测电路进行预测。

图5 帧内35种预测模式Fig.5 35 prediction modes of intra
为提高帧内预测的精度和效率,HEVC采用一维3抽头低通滤波器对不同尺寸不同模式下的预测块选择性地进行平滑滤波处理。本文对不同预测模式下需要进行滤波的尺寸进行了归纳统计,如表4所示。

表4 不同模式下需要滤波的PU大小Tab.4 Filtering PU size required for different modes
从表4可以看到,在不同模式下,需要滤波的预测单元尺寸呈现一定的规律性。本文充分利用此特性,从滤波电路复用的角度,提出如表5所示的18路预测模式并行的方案进行预测电路的设计,充分发挥预测电路的复用性,提高电路的数据吞吐率。按照本文预测模式并行的设计方案,在第1路预测模式中,只有模式1在非4×4 PU下需要滤波,其余情况不需要滤波。第2路预测模式不需要滤波,第3~4路非4×4 PU下需要滤波,第5~16路16×16及以上PU需要滤波,第17~18路只有32×32及以上PU需要滤波。因此,在滤波后的参考像素中只需分成五类进行整理,并按照垂直和水平模式的不同将最终的参考像素分为主副参考像素输入到预测电路中,每个批次就可以使用相同的预测电路。此方案可以充分发挥电路的复用性,在节省电路面积的同时提高数据吞吐率。

表5 18路预测模式并行方案Tab.5 18-path predictive mode parallel scheme
2.2 全流水硬件架构设计
对于不同尺寸的PU,传统硬件架构通常单独使用一个电路。如文献[14]提出4种不同尺寸的PU并行预测,虽然在一定程度上提高了运行速度,但是占用了大量的硬件资源。因此,本文提出基于4×4基本块复用的18路预测模式全并行流水的硬件架构,将CTU按Z扫描顺序划分成256个4×4的基本块,依次对不同尺寸的预测单元流水处理,充分利用了电路的复用性。本文所设计的硬件架构如图6所示。
主要包括参考像素获取电路、参考像素滤波电路、预测电路、残差计算电路、哈达玛变换电路等。其中参考像素获取电路采用原始像素作为输入,根据4×4基本块的位置和PU尺寸的大小获取当前PU上方和左侧参考像素。参考像素滤波电路分为强滤波电路和常规滤波电路,二者同时对输入的参考像素进行滤波处理后输入到参考像素整理电路。参考像素整理电路对滤波后的参考像素和未滤波的参考像素按照并行预测模式的需要进行分类整理,并按照垂直模式和水平模式的不同,将最终的参考像素整理成主参考像素和副参考像素输入到并行预测电路。预测电路根据输入的参考像素完成预测并和原始像素求差得到4×4基本块的残差值输入到哈达玛变换模块。哈达玛变换模块按照PU块的尺寸不同,对变换后的值进行累加得到当前PU最终的SATD值。码率值获取电路是按照本文帧内模式决策的算法根据QP的不同提前将码率值计算好并存储在只读存储器中,使用过程中采用查表的方式进行读取,以此简化硬件实现复杂度。
本文硬件架构采用高度并行的全流水线设计,电路开始工作时,第一个时钟开始对当前CU层编码树单元编号为0的基本块第一批预测模式处理,第二个时钟对其第二批预测模式处理,第三个时钟对编号为1的基本块第一批预测模式处理,依次类推,整个电路处于流水工作的过程,完成当前PU层编码树单元的256个基本块35种预测模式的计算后会继续计算下一个PU层的编码树单元,直至完成当前编码树单元5层预测单元的遍历计算。为了提高硬件的处理速度,对于64×64的预测单元,本文采用32×32预测单元的数据进行复用,以减少编码时间。本文硬件架构每个时钟周期可同时处理一个4×4基本块的18个预测模式计算,数据吞吐率可达288个像素每时钟周期,理论上完成一个编码树单元从64×64至4×4预测单元的遍历计算只需2 082个时钟周期。
3 实验结果与分析
在Xilinx Virtex-7系列型号为xc7vx485tffg1761-3 FPGA实验平台上对本文硬件架构进行综合实现,综合结果表明,本文架构使用的硬件资源为99 k查找表和57 k的寄存器,最高主频可达219 MHz,最大可实现1080P@210FPS或4K@52FPS全I帧模式下的视频实时编码,支持帧内35种预测模式和所有预测块尺寸。本文硬件架构与已有的设计方案对比结果如表6所示,文献[16]提出了一种全流水的帧内预测硬件架构,虽然在1080P和4K视频的实时编码帧率上与本文一致,但是其所消耗的LUT资源是本文的两倍以上,寄存器资源接近4倍,且其方案仅支持32×32~4×4大小的PU,不支持64×64的PU。文献[17]在帧内模式决策代价计算时考虑了变换量化和熵编码过程,其性能优于本文算法1.52%,但其所消耗的硬件资源是本文的两倍,且最大只支持1080P@45FPS的实时视频编码,不适用于高分辨率高帧率的应用场景。文献[18]虽然所消耗的硬件资源较低,但实时的编码帧率仅为1080P@60FPS,远低于本文架构。文献[19]采用残差的SATD值作为帧内模式决策的代价,但并没考虑帧内预测模式头信息编码比特率的影响,虽然降低了硬件实现的复杂度,但其编码性能指标BD-rate损失较大,高于本文算法6.75%,且仅支持1080P@30FPS的视频实时编码。
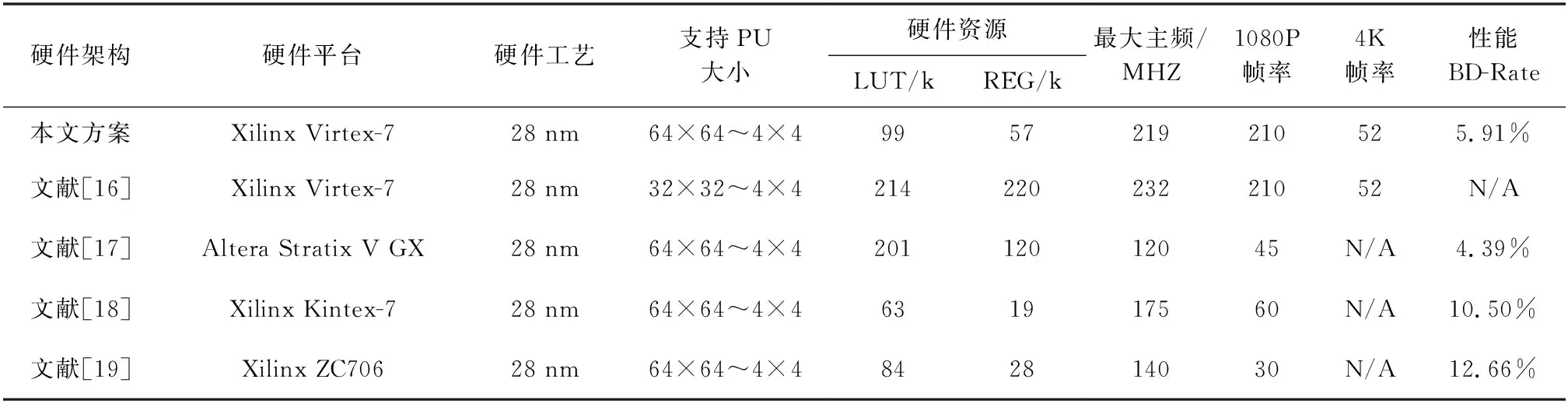
表6 硬件综合结果对比Tab.6 Hardware synthesis results and comparison
4 结束语
面对HEVC帧内预测硬件实现的高复杂度特性,本文在保证一定性能的前提下,面向硬件对帧内预测算法进行优化,打破了帧内预测过程中对重构数据的依赖,降低了硬件实现的复杂度。在硬件架构设计上,基于本文所提优化算法,设计出采用基于4×4基本块复用的18路预测模式并行全流水硬件架构,数据吞吐率可达每时钟周期处理288个像素,最高可实现4K@52FPS的实时视频编码。实验结果表明,本文方案综合性能优于其他已有方案。
