面向加密恶意流量的噪声标签检测方法
2023-10-11童家铖倪嘉翼
童家铖 陈 伟 倪嘉翼 李 频
(南京邮电大学计算机学院、软件学院、网络空间安全学院 南京 210023)
随着人工智能技术应用领域的扩展,越来越多的研究着眼于基于人工智能的网络安全防护,特别是在网络流量检测任务研究上取得很大进展[1-2].然而,基于人工智能的方法难免会遭受噪声标签的干扰,尤其是在加密恶意流量检测领域,专家都很难分辨样本的真实标签,确保大规模数据集中所有标签的正确性是非常具有挑战性的,因为产生加密恶意流量的技术和工具十分复杂且不断演变.这也影响了现在针对加密恶意流量检测模型的稳定性,进而增大了系统被恶意入侵的风险.
近年来,有不少噪声标签检测方法被提出,主要分为3类:1)剔除潜在的噪声标签数据;2)提高模型对于带噪声数据集的训练表现;3)检测出噪声标签后予以修正再进行训练.但是在二分类的加密恶意流量检测场景下,对攻击样本的数据收集本身有难度,并且恶意流量检测模型的精准度要求也比其他图片、语言类应用模型要高,因此第1类和第2类方法并不适用于网络安全领域,而第3类方法也存在噪声标签检测精度不理想的问题.
综上所述,处理有噪声的数据集以改进加密恶意流量检测模型的训练及其评估仍然是一项挑战.为此,本文提出了一种基于样本噪声权重计算与差分训练(KLIEP based relative probability density and differential training, KRPD-DT)的噪声标签检测方法,使用差分训练的思想记录样本在2个相同结构模型中训练的损失,根据干净样本和噪声样本在训练行为上的差异性来检测出噪声样本.同时,使用基于KLIEP-RPD的相对噪声权重估计方法,估计每个样本的相对概率密度,把它作为样本损失行为的权重来放大样本间的损失差异.本文针对恶意DoH加密隧道流量的检测场景验证了该方法的有效性.
1 相关工作
检测和去除噪声标签对于确保机器学习模型的准确性和稳健性至关重要.近年来,国内外关于噪声标签检测的研究比较多.
Ren等人[3]提出了一种元学习算法,该算法根据训练样本的梯度方向为其分配权重,为了确定样本权重,该方法对当前的小批量样本权重执行元梯度下降步骤,以最大限度地减少干净无偏验证集的损失.实验证明该方法在类不平衡和损坏标签问题上实现了不错的性能,但是在高噪声率的数据集上表现不佳.Arazo等人[4]提出了一种贝塔混合模型作为样本损失值的无监督生成模型,以此在训练期间估计样本被错误标记的概率,并通过深度神经网络的预测来校正损失.Xu等人[5]提出了一个通用框架来降低训练数据的噪声水平,用于训练任何基于机器学习的Android恶意软件检测,该框架利用2个相同的深度学习分类模型的所有中间状态,为每个输入样本生成噪声检测特征向量,并应用一组异常值检测算法降低给定训练数据的噪声水平,该方法在3种Android恶意软件数据集上都取得了较好的降噪效果[5].
2 本文方法
2.1 总体设计
本文基于差分训练的思想进行改进,为样本计算相对噪声权重来更好地区分干净样本和噪声样本.整体方法架构如图1所示:
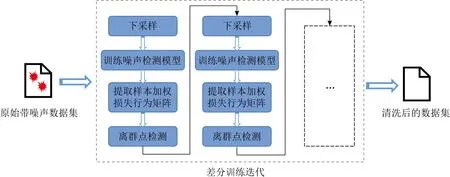
图1 KRPD-DT方法架构
本文利用迭代的思想,在每个迭代中通过训练2个结构相同的深度学习模型,获取每个样本在训练过程中的训练行为,这里的训练行为由样本在训练期间的每个epoch产生的损失串联形成,然后给每个样本的训练行为乘以一个权重KLIEP-RPD,形成最终的样本损失矩阵.最后根据干净样本和噪声样本在损失上的差异性,将其送入离群点检测算法,进行噪声标签的检测.在进行多个迭代后可以有效地降低数据集中的噪声样本数量,从而提高模型再训练的精度,优化增量模型的检测效果.下面将对该方法的各个模块进行介绍.
2.2 构建差分训练模型
在本文提出的噪声标签检测方法中,使用CIC实验室的DoH数据集,将其中的标签按百分比进行随机翻转,作为原始噪声数据集,称之为WS.随后在WS中使用Down Sampling下采样方法分离出一部分带噪数据集,我们将这一部分带噪数据集称为DS.在生成WS和DS后,这2部分带噪数据集将分别送入2个结构相同的LSTM模型进行训练,需要同时训练2个模型,分别称为WS-LSTM和DS-LSTM,使用Keras建模并保持2个模型的初始状态、参数设置以及网络结构的一致.在每次的迭代训练中采用差分学习率的方法进行训练,随着每次的训练,动态地更新WS-LSTM和DS-LSTM的学习率,并且始终保持2个模型的学习率一致.
2.3 建立样本加权损失行为矩阵
KLIEP-RPD是基于KLIEP的相对概率密度(RPD)估计方法,根据不同类别标签噪声的对比度来衡量一个样本是否为噪声样本的概率.根据文献[6]中的结论,噪声点会影响模型拟合过程中的决策曲线,即模型在拟合不同标签的异质样本时噪声样本的概率密度是稀疏的;当模型在拟合相同标签的同质样本时概率密度保持稠密.
因此,可以定义来自不同类的样本概率密度为异质概率密度P(X=xi|Y≠yj),来自同一类的样本概率密度为同质概率密度P(X=xi|Y=yj),并将RPD定义为两者的比率,这样噪声样本的RPD就比较大,而干净样本的RPD就比较小,因此有助于放大干净样本和噪声样本间的差异.
(1)
式(1)定义的相对概率密度具有自然的比率结构,因此可以直接使用强大的估计方法KLIEP直接评估RPD值,避免分别计算分子和分母而带来的计算复杂度[7].本文使用python中的pykliep扩展库实现这样的计算.
由于DS中包含更多的噪声样本,所以根据每条DoH流量样本的会话流通信五元组进行定位,分别获取DS中每条样本在WS-LSTM和DS-LSTM这2个模型中的训练损失,并且将2部分损失按照时间顺序进行拼接,拼接完成后就形成初始的样本损失行为矩阵.接下来,根据上文中计算的样本相对噪声权重KLIEP-RPD,将每条样本的损失矩阵都乘以这个权重,形成最终需要的样本加权损失行为矩阵.
2.4 离群点检测模块
通过上文所描述的方法提取到样本加权损失行为矩阵之后,将其送入最后的集成型离群点检测模块中,如果1个样本的加权损失行为矩阵被该模块判断为是1个离群点,那么就认为它是1个噪声样本,并将它在WS数据集中的标签翻转.本模块共选取9种离群点检测算法构成一个投票器,涵盖了基于密度的算法、基于距离的算法、基于集成思想的算法等,能够从多方面评估输入的样本是否为异常值,以上9种算法均来自于python中的离群点检测算法包PyOD.
以上介绍的构建差分训练模型、建立样本加权损失行为矩阵、离群点检测3个步骤构成1轮迭代,每轮迭代都能在一定程度上减少WS噪声数据集中的噪声标签数量,设置一个停止标准,当连续3次迭代后降低的噪声标签比例小于0.5%时停止迭代.
3 实验与评估
3.1 数据集与评估指标
本文针对DoH数据集的噪声检测进行研究,在目前的开源数据集中,加拿大CIC实验室在2020年捕获的DoH数据集已经被广泛用于研究[8],因此本文也将截取其中的一部分进行实验.需要注意的是,我们默认该数据集中的标签全部正确,并通过按照百分比随机翻转标签的形式模拟一个有噪声的DoH数据集,初始的噪声标签比例设置为20%,实验数据集如表1所示:
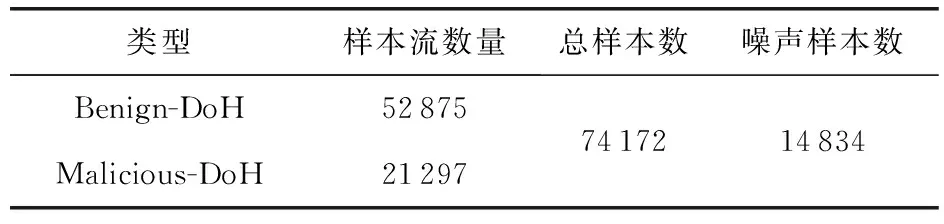
表1 实验数据集
本文实验中,定义TP为检测出的噪声标签数量,FP为误检出的噪声标签数量,于是,定义实验的评估指标为数据集净化率DPR和噪声清洁率NCR.

(2)
(3)
本文定义1-DPR(t)作为数据集整体净化率(t代表最后一次迭代),使用1-DPR(t)和NCR评估迭代结束后的整体检测效果.此外,还使用F1-score指标评估净化后的数据集对恶意DoH流量检测模型效果的提升,使用groud-truth标签数据集训练一个集成学习模型,该模型被验证在恶意DoH流量检测上有不错的表现,F1-score达到99.4%[9].使用相同方法,对模拟的噪声数据集与清洗后的数据集分别训练,来验证KRPD-DT方法的实用性.
3.2 整体去噪效果评估
本节实验将本文提出的KRPD-DT方法与其他一些噪声检测方法进行对比,本文选取的基线方法有decoupling双模型解藕[10]、co-teaching联合教学[11]、原始的DT差分训练[5],co-teaching和decoupling也是基于双模型训练的方法,为了公平起见,3种基线方法中的深度学习模型均设置为与本文参数一致的LSTM网络.本文将这些方法应用于相同数据集上,仍然设置初始噪声率为20%,评估不同方法的检测性能,以及数据集净化后的恶意DoH流量检测表现,具体如表2所示,其中NSleft代表数据集清洗后剩下的噪声样本数量,CD-F1代表经过清洗后的数据集(clean-data)训练的恶意DoH隧道流量检测模型的F1-score,ND-F1代表本文模拟的噪声DoH数据集(noisy-data)训练的模型F1-score,GT-F1代表在groud-truth数据集上训练的模型F1-score.
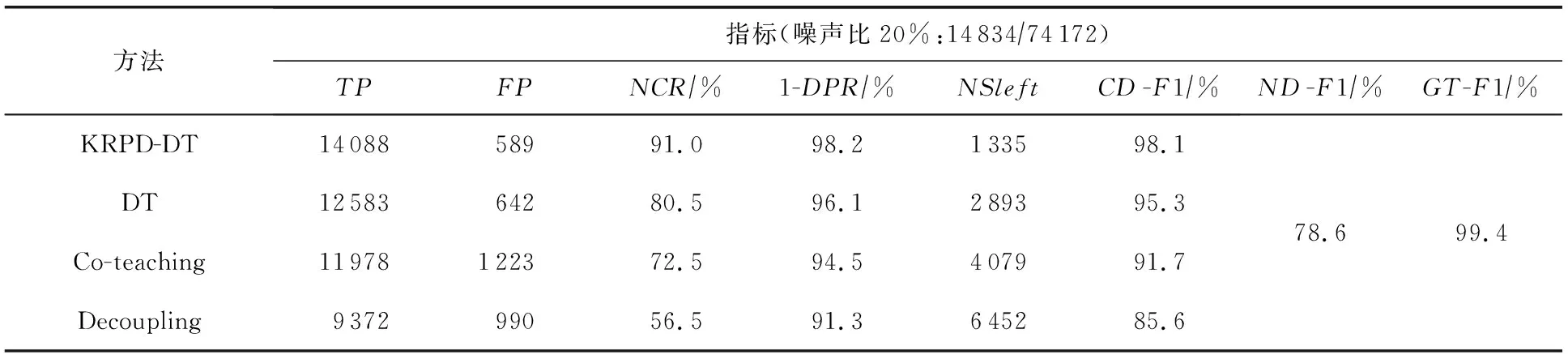
表2 不同方法的噪声检测效果对比
DT,Co-teaching,Decoupling利用不同的策略来处理噪声样本.原始的差分训练根据样本在整个训练过程中的所有损失值将其识别为噪声,而联合教学则根据样本在每个小批量中的单个损失值将样本视为潜在的干净样本,解耦则根据其预测结果将噪声样本识别为仅与其在上一个历元中的损失值相关.本文的实验表明,改进的KRPD-DT方法所使用的策略在检测噪声标签方面比联合教学和解耦所使用的其他策略更可靠.
4 结 语
本文提出了一种基于KRPD-DT的噪声标签检测方法.在该方法中,使用差分训练的思想同时训练2个相同的模型,提取样本在2个模型中训练的损失,根据干净样本和噪声样本在训练行为上的差异性来检测出噪声样本;同时,为了放大样本间损失上的差异,提出了基于KLIEP-RPD的相对噪声权重估计方法,估计每个样本的相对概率密度,并把它作为样本损失行为的权重;最后送入集成的离群点检测模块进行噪声标签检测,并将清洗后的数据集进行恶意DoH隧道流量检测模型的训练.
实验表明,本文方法在DoH数据集上都有不错的表现,最高检出率达到91%,同时净化率也达到98.2%,优于其他几种噪声监测方法,并且经过本文方法清洗后的DoH数据集,使恶意DoH检测模型的F1值恢复到98.1%,接近于groud-truth数据集的99.4%.
