基于LK 光流与实例分割的联合动态一致性vSLAM 算法
2023-10-11匡本发
刘 强,袁 杰,匡本发
(新疆大学 电气工程学院,新疆 乌鲁木齐 830017)
0 引言
近年来,机器人受到广泛的关注,投入到越来越多的场景中使用,这对同步定位与建图(SLAM)技术提出了新的挑战[1-3]。SLAM 按照传感器的不同,可以分为基于激光雷达的激光SLAM 和基于相机的视觉SLAM。视觉SLAM 因其传感器能提供的信息丰富而获得了较多的关注,因此众多的学者提出了许多优秀的SLAM 方案,如:MonoSLAM[4]、PTAM[5]、ORB-SLAM[6]、DTAM[7]和DSO[8]等。
这些算法能在静态环境取得不错的效果,而机器人的工作环境趋向于非结构环境,因此,视觉SLAM 需要能处理场景中的动态物体。
目前,针对动态物体的方法分为三类,分别为基于光流、几何以及深度学习。文献[9]通过计算光流的运动度量的方法来获取可能的移动物体。文献[10]检测动态特征采用的是对极几何与FVB(Flow Vector Bound)约束结合的方法。随着深度学习的快速发展,与深度学习结合的方法也迎来了巨大的飞跃。文献[11-12]通过先验语义信息对动态特征进行剔除。文献[13]提出了基于SegNet[14]的DS-SLAM 算法。文献[15]提出了基于Mask R-CNN[16]的DynaSLAM 算法。文献[17]提出了基于目标检测和语义分割的RDTS-SLAM。基于深度学习的方法中,在高动态场景中可以有效地剔除动态物体,但其对低动态场景直接利用先验语义信息剔除动态特征反而降低了算法的定位能力。
针对上述问题,本文提出了一种结合实例分割与光流的视觉SLAM 算法,能够对图像中的动态物体与潜在动态物体进行运动状态精准判定,然后再剔除从动态物体处提取的特征点,最后利用静态特征点进行相机位姿估计。
1 算法框架
图1 为本文算法的系统框架。系统输入为RGB-D图像序列,实例分割线程对RGB 图像进行分割获取掩码信息;跟踪线程收到RGB 图像后,先对其提取ORB[18]特征,在等待实例分割掩码的时候对其进行稀疏光流处理,然后结合实例分割掩码与先验语义信息对光流信息进行处理得到非动态物体、动态物体和潜在动态物体的光流位移增量,再结合光流信息与实例分割掩码进行联合动态一致性检查并剔除动态特征,最后利用静态特征估计机器人位姿;局部建图线程对地图点进行实时更新;回环检测线程对相机轨迹检测回环,并进行全局优化。
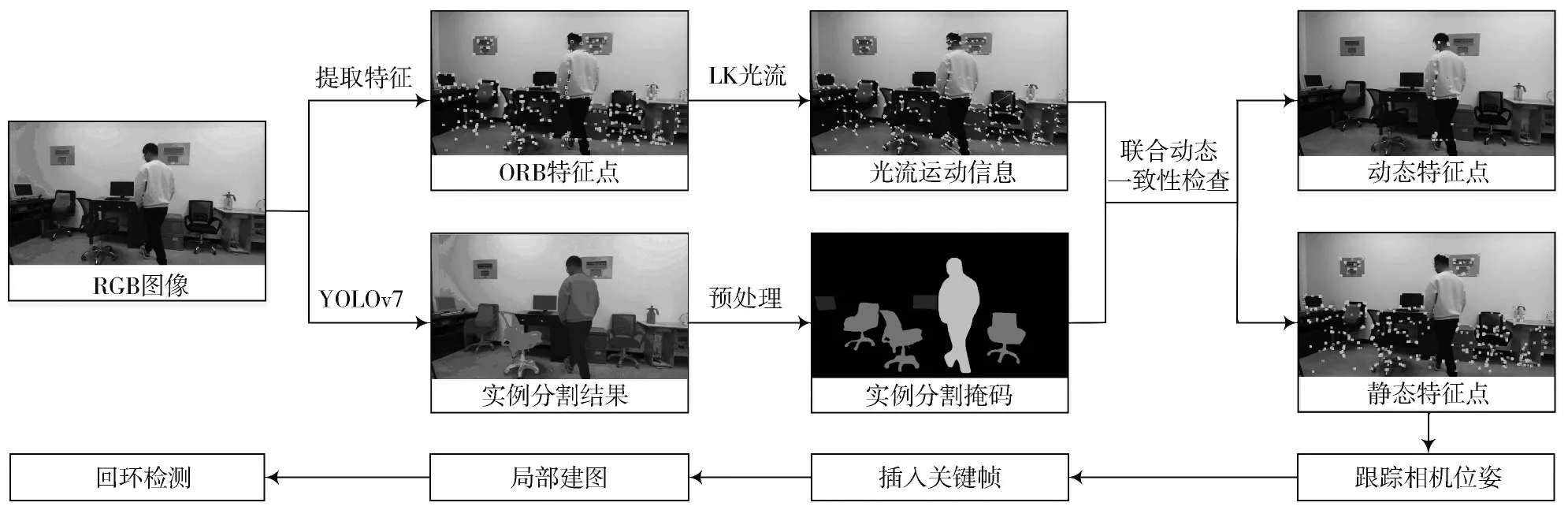
图1 本文算法系统框图
1.1 LK 光流
光流是一种描述像素随时间在图像之间运动的方法,按照计算像素的多少分为了稀疏光流和稠密光流。稀疏光流中最具代表的是Lucas-Kanada 光流[19],稠密光流中最具代表的是Horn-Schunck 光流[20]。稀疏光流因计算像素较少,具有良好的实时性。本文算法中仅需要计算部分像素,故采用LK 光流。
在LK 光流中,假设同一个空间点被不同位姿下的相机观测到的灰度值固定不变,根据假设有:
式中:Ix、Iy、It为该空间点灰度值在x、y、t方向上的偏导;u、v为该空间点对应像素点光流在x、y方向上的运动。
LK 光流存在的另一个假设是:某一像素和附近小邻域Ω内像素运动一致。假设小邻域内有n个像素点,可建立n个约束方程,为:
式(2)为超定线性方程,通过最小二乘对其求解,得到像素点光流运动信息u、v。利用像素点光流的运行信息,可以确定其在下一图像中出现的位置,即为光流匹配点。为了让LK 光流具有更强的鲁棒性,引入图像金字塔提取多层次的光流信息。
1.2 YOLOv7 实例分割
本文中采用YOLOv7[21]实例分割网络来获取像素级语义分割掩码。YOLOv7 是一种新的体系结构,并且使用了相应的模型缩放方法,该方法提高了参数的利用率和计算效率。YOLOv7 在准确性和速度方面都具有优越的性能。
YOLOv7 网络模型如图2 所示,由输入(Input)、主干网络(Backbone)、头部网络(Head)3 个主要模块构成。输入模块的功能是将输入的图像调整为固定的尺寸大小,使其满足主干网络的输入尺寸要求。CBS卷积层、EELAN 卷积层和MPConv 卷积层组成了主干网络。MPConv 卷积层是在CBS 卷积层上加入了最大池化层(Maxpool),构成上下两个分支,最终利用Concat 操作对两个特征提取分支进行融合,从而提升了主干网络提取特征的能力。
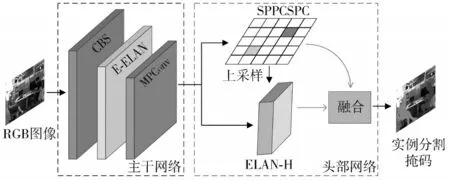
图2 YOLOv7 网络模型
E-ELAN 卷积层是高效层聚合网络,可以在保持原始梯度路径不变的状态下,提升网络的学习能力,同时也可以引导计算块学习更多样化的特征。头部网络先通过采用SPP 金字塔结构,提高头部网络的多尺寸输入适应能力;再使用聚合特征金字塔网络结构,使得底层信息可以自底层向上传递到高层,融合了不同层次的特征;最后生成实例分割掩码。YOLOv7 的损失函数由定位损失、置信度损失和分类损失三部分构成,前者采用CIoU 损失,后两者采用BCELoss 二值交叉熵损失。
1.3 联合动态一致性检查
实例分割线程为跟踪线程提供了实例分割掩码,通过掩码信息,将出现在相机视野中的物体分为3 大类,分别为:静态物体、动态物体和潜在动态物体。其中潜在动态物体主要是指椅子和书等较大可能处于被运动状态的物体。首先计算得出光流运动信息中的非动态物体(潜在动态物体与静态物体总称)的平均位移增量S0,再计算每个潜在动态物体以及动态物体的位移增量,分别为、。
利用实例分割掩码信息对3 类物体初始运动概率赋初值:
式中:P1、P2、P3分别为静态物体、潜在动态物体和动态物体的初始运动概率。再计算出Smax与Smin作为位移增量判定上下界:
本文算法中有一个基本假设:静态物体的状态一直为静止,故其联合运动概率为:
结合动态物体和潜在动态物体光流位移增量,按照公式(7)、公式(8)计算联合运动概率:
最后将>0.75 的潜在动态物体作为运动状态进行剔除,将<0.75 的动态物体作为静止状态进行保留。将保留的特征用于相机运动估计。
本文算法不是直接剔除先验动态物体上提取的特征,而是通过上述公式计算先验语义信息与LK 光流信息的联合运动概率,结合了语义信息与光流信息后,物体的运动判定更加准确。特别是,当RGB 图像中先验动态物体占据较大部分比例时,语义SLAM 若直接剔除未运动的人时,会导致估计的相机轨迹与真实轨迹之间的误差过大。
2 实验结果与分析
本节将从定位准确度和真实场景两个方面对本文算法进行验证。此外,还将本文提出的算法与其他先进的SLAM 算法在TUM[22]中RGB-D 数据集上进行实验对比。由于实验需要,将选取TUM 中fr3 数据集中的4 个高动态场景和4 个低动态场景。绝对轨迹误差(Absolute Trajectory Error,ATE)是相机位姿真实值与估计值的差值,本文将选择ATE 作为定位准确度评价指标。
本文所用的实验平台为联想Y9000P 笔记本电脑,CPU 为11th Gen IntelⓇCoreTMi7-11800H,RAM 为双通道16 GB,GPU 为RTX 3060 Laptop,显存6 GB。运行系统为Ubuntu 18.04,实例分割环境为CUDA 11.3,PyTorch 1.8,Python 3.8。
2.1 定位准确度
为了验证本文算法对运动物体处提取的特征点剔除后对定位性能的提升,将本文算法的ATE 与ORBSLAM2 进行对比,如表1 所示。从表中数据可以看出,本文算法在4 个低动态数据集中相对提升率最高可达52.04%;在4 个高动态数据集中提升率最高达到了98.11%,最低达到了93.35%;在数据集s_x 中,本文算法的ATE 较ORB-SLAM2 的ATE 要大,经分析在s_x 数据集中,剔除运动的特征点后的特征点数量较少,导致改进后的定位精度反而比ORB-SLAM2 要低。
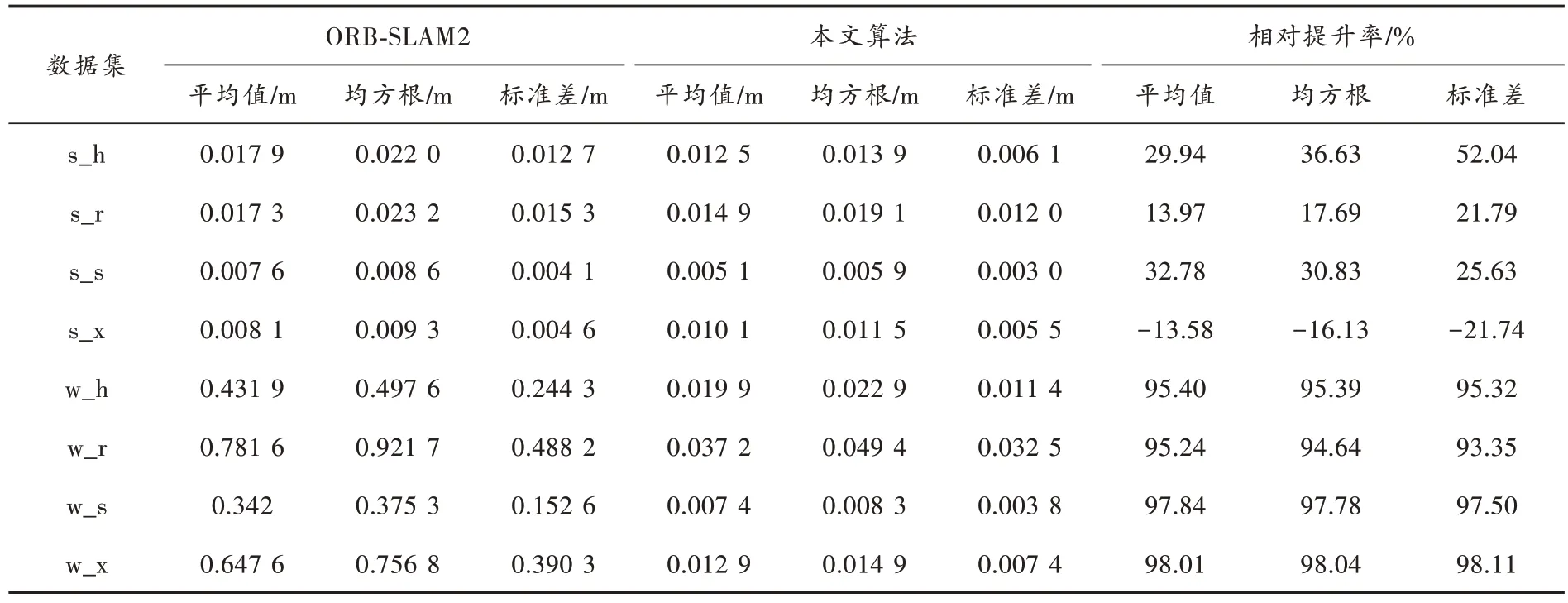
表1 本文算法与ORB-SLAM2 算法的绝对轨迹误差对比
将本文算法的ATE 与仅使用YOLOv7 删除先验动态物体处提取的特征点的ATE 相对比,如表2 所示。从表2 中数据可以得出,LK 光流与YOLOv7 实例分割结合的方法与仅使用YOLOv7 实例分割的方法相对比,在4 个低动态数据集中,LK 光流与YOLOv7 实例分割结合的方法的相对提升率均为正值;在4 个高动态数据集中,两个为正值两个为负值;相对提升率最小为-49.7%,经分析,w_r 数据集中因相机旋转导致光流精度受限,因此最终的定位精度反而较仅使用YOLOv7 实例分割的方法小。
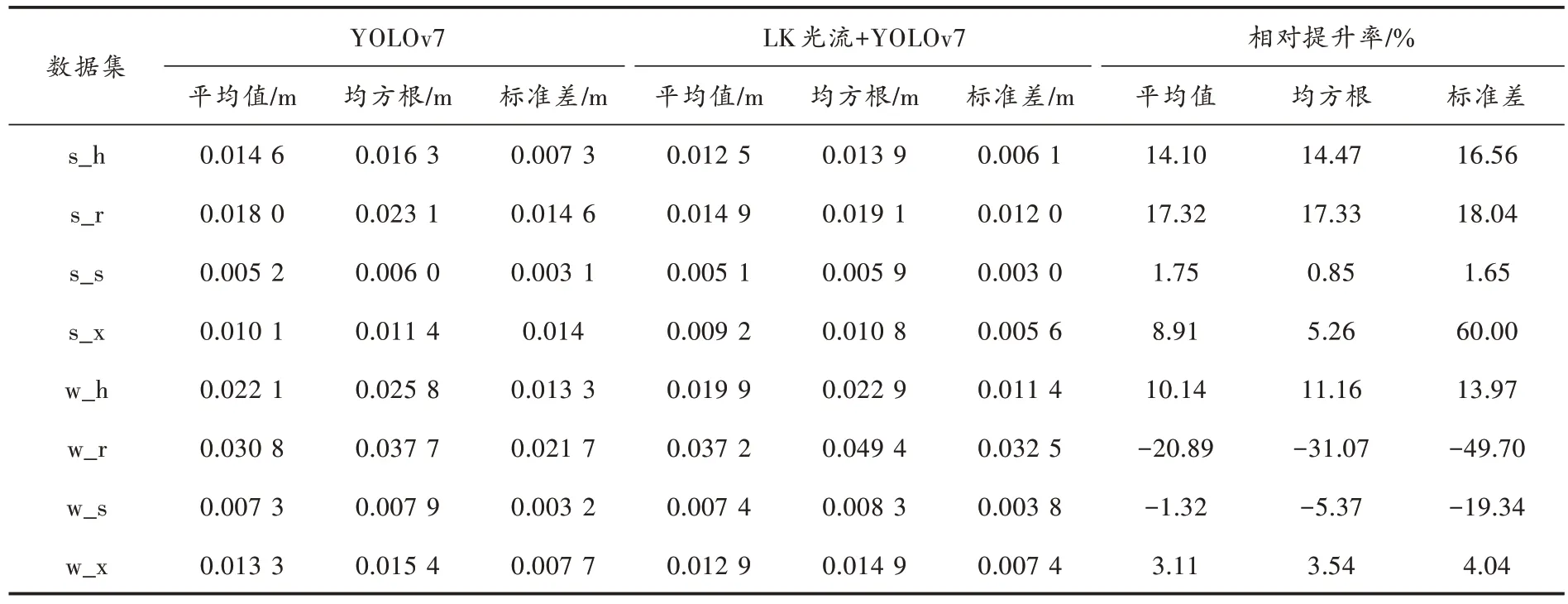
表2 本文算法与仅使用YOLOv7 剔除动态特征方法的绝对轨迹误差对比
结合表1 和表2 数据不难得出,本文算法在低动态数据集中的定位效果要比仅利用YOLOv7 实例分割剔除动态特征的定位效果好,在高动态数据集中的定位效果也有不弱于仅利用YOLOv7实例分割剔除动态特征的方法。图3为ORB-SLAM2、YOLOv7与LK光流+YOLOv7估计的相机运动轨迹对比图。图中实线为相机的真实轨迹,点线为算法估计的轨迹,从图中可以看出,本文算法在s_h、s_r、w_h 数据集中估计的相机轨迹更加贴合真实估计,估计轨迹与真实轨迹的误差更小,直观地体现了本文算法的先进性。
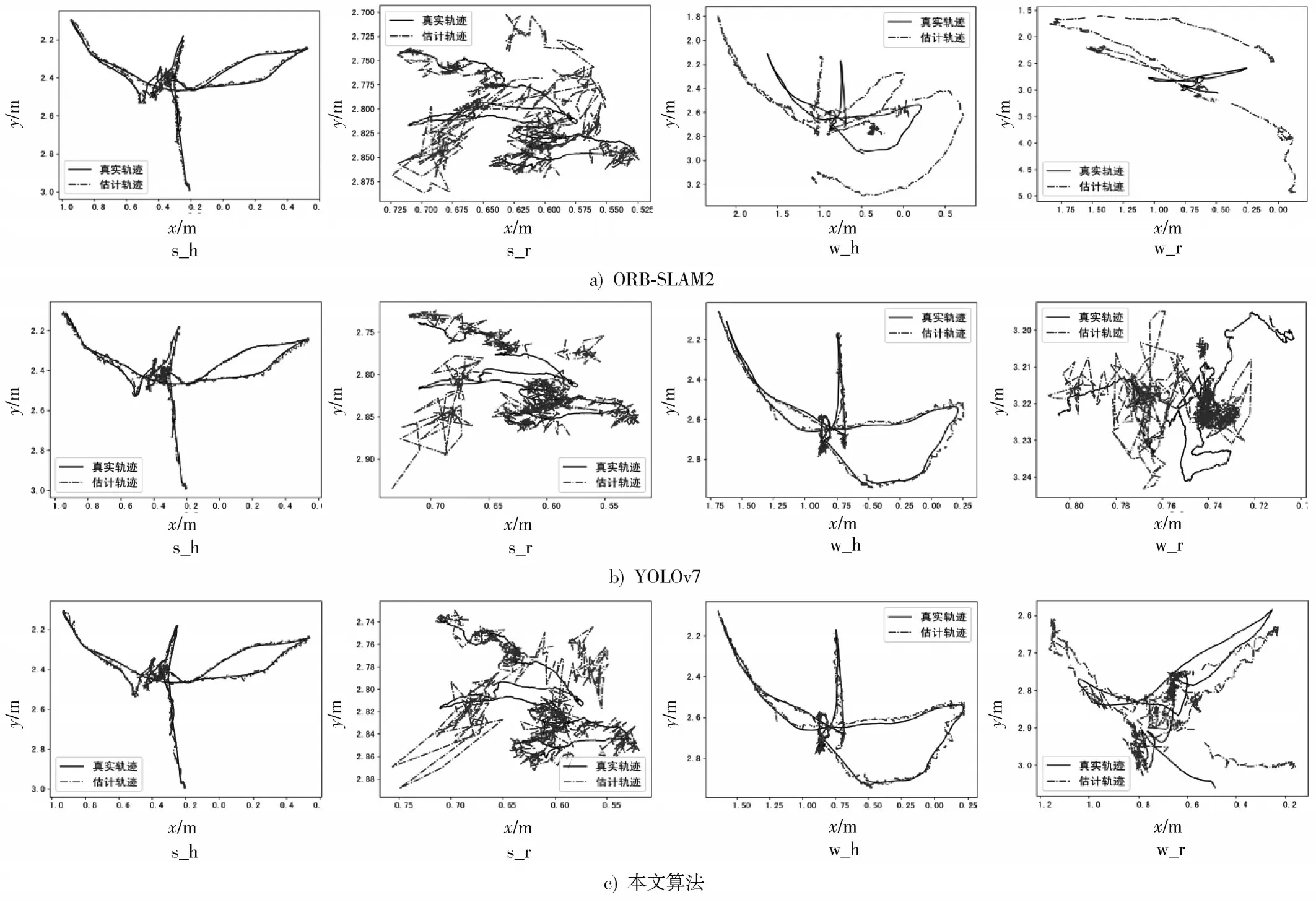
图3 本文算法与ORB-SLAM2 的跟踪轨迹对比
将本文算法的ATE 与其他优秀的语义SLAM 相对比,如DS-SLAM、DynaSLAM,结果如表3 所示。
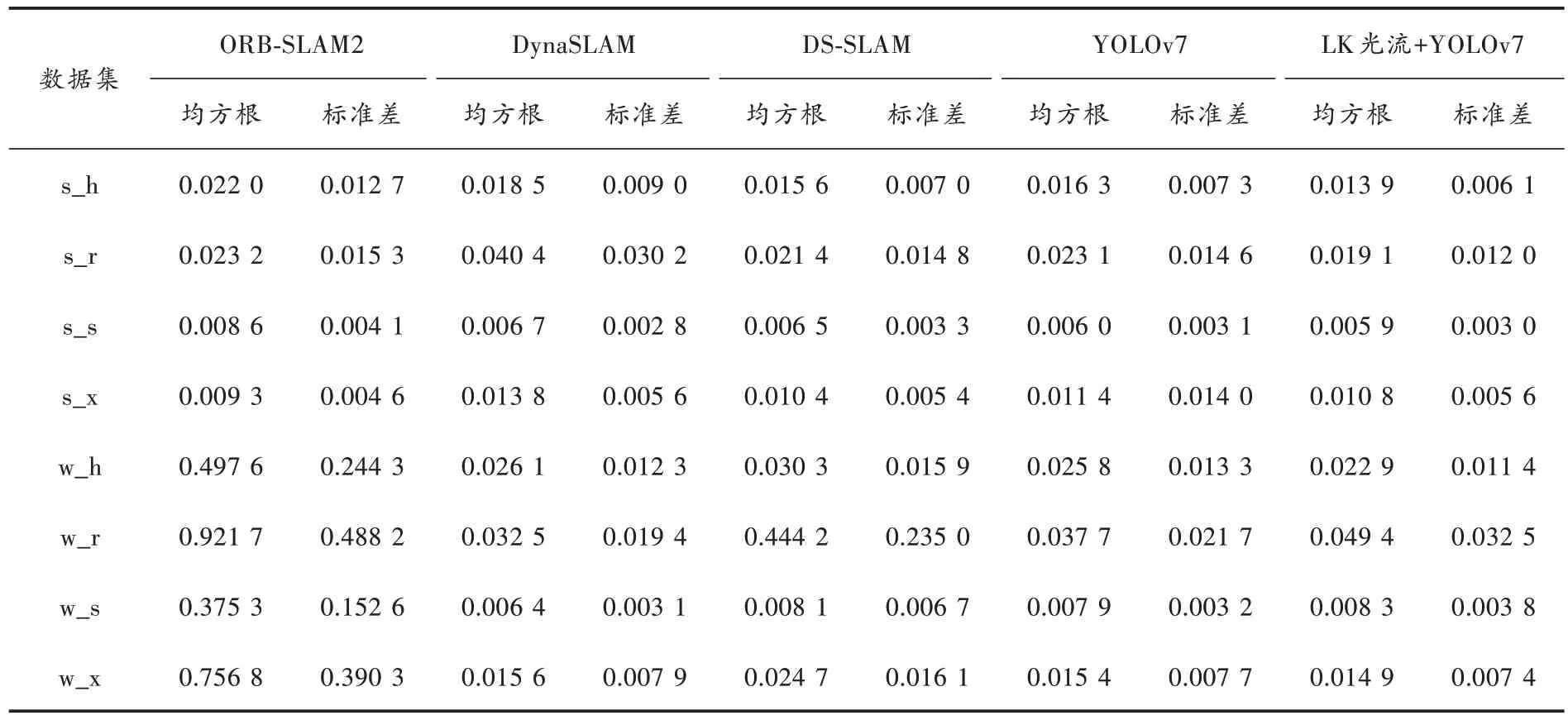
表3 本文算法与经典SLAM 算法的绝对轨迹误差对比 m
在4 个低动态数据集中,本文算法有5 个最优,且ORB-SLAM2 有2 个最优,其他优秀算法仅1 个最优;在4 个高动态数据集中,本文算法有4 个最优。本文算法在低动态数据集中的表现优于其他算法,在高动态数据集中也有不弱于其他算法的表现,充分验证了本文算法的优越性。
2.2 真实场景
为了评估本文算法在真实场景中的性能,使用Kinect v2 深度相机对实验室的日常场景进行图像信息提取,并输入本文算法,对算法运行中的特征提取、实例分割、光流运行信息、动态特征剔除进行可视化展示,如图4 所示。从图4 第一列图像可以看出,当人坐在椅子上处于低动态时,本文算法认定其为静止状态,不剔除其上特征点;图中第二列,当人从座位中起身时被认定为动态状态,剔除其上特征点;图中第三列和第四列,人处于行走时,本文算法认定人处于运动状态,剔除其上特征点。综合图4可以得出,本文算法可以精准地对运动特征进行剔除。

图4 真实场景验证
3 结语
本文将物体分为3 类:静态物体、动态物体和潜在动态物体,通过YOLOv7 实例分割掩码与先验信息,对其运动概率赋予初值,然后将YOLOv7 实例分割与光流运动信息相结合,分别计算每一个动态物体和潜在动态物体光流位移增量,根据位移增量判定其是否运动,最终对运动物体上提取的特征点进行剔除。本文算法能很好地判定物体的运动状态,不像其他语义SLAM,直接对先验动态物体进行剔除,忽略了余留的静态特征太少,导致算法定位精度降低。在TUM RGB-D 数据集中对本文算法进行验证,实验结果表明:本文算法在低动态数据集中定位效果优于其他算法,在高动态数据集中也处于一流的水平。本文算法在真实场景中的运行过程展示了对于动态物体的运动状态判别精准,能有效地帮助提高算法的定位能力。在未来的工作中,将探索以物体作为地标的语义SLAM。
