基于龙芯2K1000 处理器和复旦微FPGA 的全国产RapidIO 解决方案研究
2023-10-11郭佳,张渊,冯伟,吴骏
郭 佳,张 渊,冯 伟,吴 骏
(中国船舶集团有限公司 第七二二研究所,湖北 武汉 430205)
0 引言
RapidIO 总线协议[1]经过20 多年的发展,已成为基于数据分组交换的高性能系统互联[2]首选解决方案之一,广泛应用于无线通信、军事、超算、医学图像处理和工业控制等多个领域,而这些领域无一例外地关系到国计民生和国家安全。目前,提供RapidIO 总线接口的芯片主要来自美国恩智浦公司的PowerPC、德州仪器公司的C6000 系列DSP、瑞萨公司的TSI 系列RapidIO 交换芯片和PCIe 转RapidIO 桥片,以及赛灵思公司的RapidIO IP 软核,而国内则鲜见对标上述芯片的国产化替代方案。
本文提出一种基于龙芯2K1000 处理器[3]和复旦微FPGA 的全国产RapidIO 解决方案,并结合具体项目验证该方案的可行性。
1 方案设计
1.1 总体设计
复杂的嵌入式设备,如核心网高端交换机、路由器、5G 基站、飞机航电系统等,一般采用多子卡机架式设计,这些子卡由机架背板布线信号联通,从而实现相互间的通信。子卡间的通信一般包括数据平面通信和控制平面通信。数据平面通信一般要求实现高可靠、高带宽、低延迟的全双工通信,相应的数据平面系统互联方案包括RapidIO 总线、以太网和PCIe 总线等,而RapidIO总线以其传输带宽高、互联信号线少、抗干扰性强、易于扩展等优势成为如飞机航电系统等复杂系统的首选子卡数据平面高速互联方案。
龙芯2K1000 处理器(下文简称CPU)是中科院计算所研发的面向网络应用、工业控制等领域的嵌入式SoC处理器。片内集成两个64位的双发射超标量GS264处理器核,兼容MIPS64 体系结构,主频为1 GHz,集成64 位DDR3控制器、SATA3控制器、2个x4的PCIe 2.0控制器、2 个千兆以太网控制器等多种外设。龙芯2K1000 处理器具有丰富的外设资源,适合作为控制子卡的处理器,但由于片上没有集成RapidIO 控制器,比较可行的替代方案是使用复旦微JFM7K325T FPGA配合RapidIO IP软核来实现RapidIO 总线接口,再选取PCIe 2.0总线接口作为龙芯2K1000 处理器与复旦微FPGA 之间交换数据的通路。FPGA 端RapidIO 总线采用LP-Serial x1 物理层接口,工作频率为3.125 GHz,数据带宽为2.5 Gb/s。软件方面,在龙芯2K1000处理器上运行国产锐华实时操作系统,并研发锐华系统下的PCIe 驱动程序和RapidIO 驱动程序;硬件方面,使用中航通用公司自行研发的国产RapidIOIP 软核。以龙芯2K1000 处理器和复旦微电JFM7K325T FPGA 为核心构建最小子系统,系统总体设计方案[4]如图1所示。
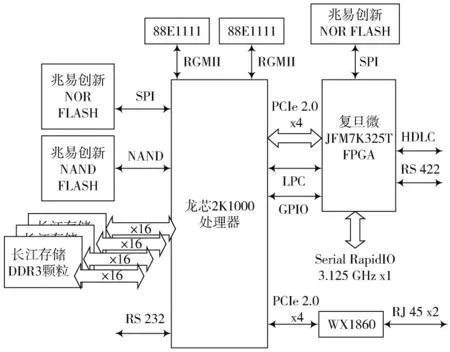
图1 系统总体方案设计示意图
CPU 与FPGA 之间通过PCIe 总线和LPC 总线相连,其中高速信号使用PCIe 总线传输,控制信号使用LPC总线传输。RapidIO 差分信号由FPGA 引出。CPU 和FPGA 均使用基于SPI 总线的NOR FLASH 存储启动固件,CPU 的大容量文件存储使用并行的Nand FLASH,CPU 外接4 片x16 的国产DDR3 颗粒,CPU片上集成的两路GMAC 以太网控制器通过RGMII 接口外接88E1111 千兆以太网PHY。FPGA 除引出RapidIO 信号外,还实现了HDLC 同步串口信号和RS 422 高速串口信号。子系统的外围均使用国产化芯片,例如兆易创新公司研发的FLASH 芯片、长江存储公司研发的DDR3 芯片和中电32 所研发的88E1111 以太网PHY 芯片等。
1.2 数据传输
FPGA 与CPU 之间通过PCIe 总线[5]交换数据的方式主要有两种,分别是PIO 方式和DMA 方式。PIO 方式的原理是:FPGA 在PCIe BAR 区间划出一定范围,实现数据寄存器、控制寄存器和状态寄存器,CPU 使用MMU 映射PCIe BAR 空间,并基于简单的数据拷贝算法实现数据交换[6]。使用PIO 方式进行PCIe 数据传输时,CPU 每次读、写数据寄存器都会触发PCIe 的TLP 事务包,当数据寄存器为4 B 时,净荷数据只占到TLP 事务包的4 256,加上PCIe 每次TLP 事务建立开销,容易得出PIO方式效率低的结论,因此不适合作为高速RapidIO 总线的数据通路。
DMA 方式使用FPGA 中的DMA 通道,在CPU 内存和FPGA 内存间搬运数据,每次搬运时尽可能保证TLP事务包中的净荷数据最大,且搬运过程不需要CPU 参与。当CPU 向FPGA 发送数据时,CPU 仅向FPGA 告知需要发送数据的地址和长度,由DMA 通道负责搬运数据,数据搬运完成后,FPGA 以PCIe MSI 中断的异步方式通知CPU 数据搬运完成;当CPU 从FPGA 接收数据时,CPU 首先告知FPGA 写入数据的内存地址,当FPGA数据就绪时,DMA 通道将数据搬运到该内存地址中,然后向CPU 发送PCIe MSI 中断,通知CPU 数据搬运完成,CPU 可以通过读取FPGA 特定的寄存器来获取搬运数据的实际长度。
本方案采纳的是一种改进的XDMA 方式[7],该方法的核心思想是使用数据描述符链表来控制CPU 与FPGA 之间的PCIe 数据收发与同步。XDMA 数据描述符如图2 所示,数据描述的长度为固定的32 B,存储数据描述符的缓冲区地址要保持与CPU 缓存行对齐,保证内存吞吐效率最优。描述符中存储了DMA 通道需要搬运数据的长度、数据的源地址(从CPU 向FPGA 搬运数据时使用)/目的地址(从FPGA 向CPU 搬运数据时使用);控制字字段包括数据搬运完成标志位,用于标识数据搬运的状态。描述符之间通过下一个相邻描述符地址字段连接成单向链表,链表中最后一个描述符的该字段为空,作为链表尾部标识。CPU 在接收和发送数据前按需准备好数据描述符链表,并把链表首个描述符的地址设置到FPGA 的XDMA 寄存器中。
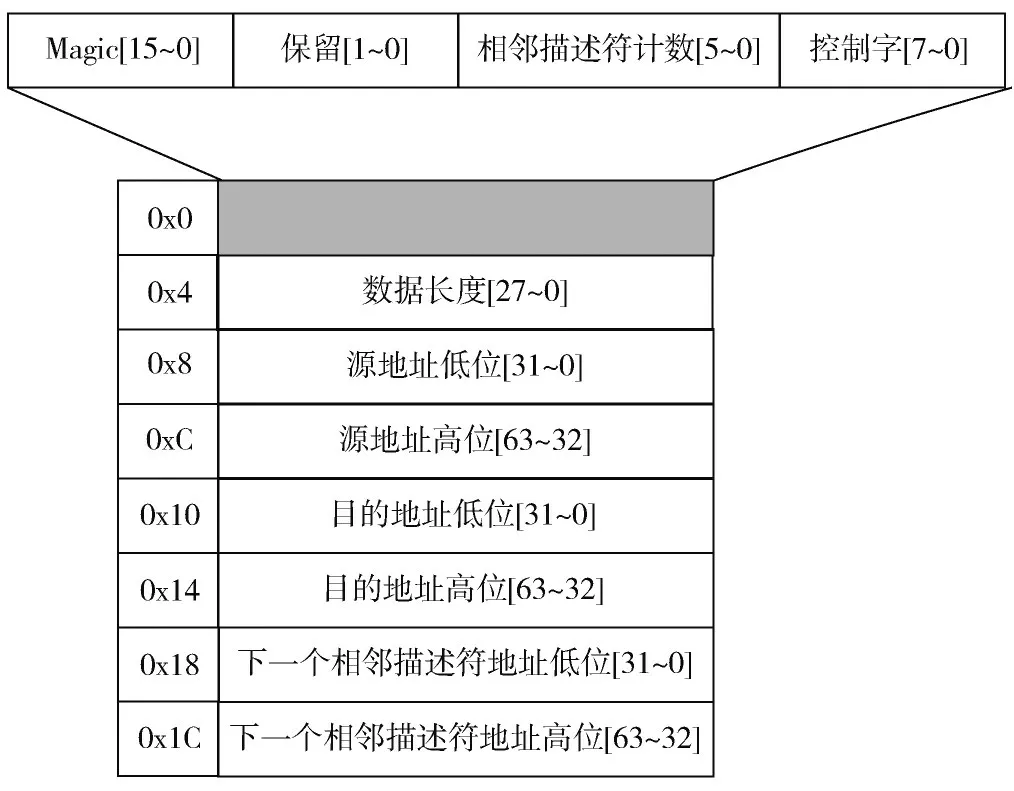
图2 XDMA 数据描述符
基于XDMA 的数据传输方向包括CPU 到FPGA 方向和FPGA 到CPU 方向,两个方向上数据传输的原理基本相同,都是由CPU 使用数据描述符队列控制FPGA 的DMA 通道进行数据搬运。二者区别在于:PCIe MSI 中断的含义不尽相同,前者代表DMA 通道完成从CPU 到FPGA 的数据搬运,后者代表DMA 通道完成FPGA 到CPU 的数据搬运。共同点在于中断总是代表DMA 操作的结束。图3 以CPU 搬运数据到FPGA 为例描述了XDMA 的具体过程,FPGA 到CPU 的数据搬运如前所述,过程大致相同,这里不做赘述。
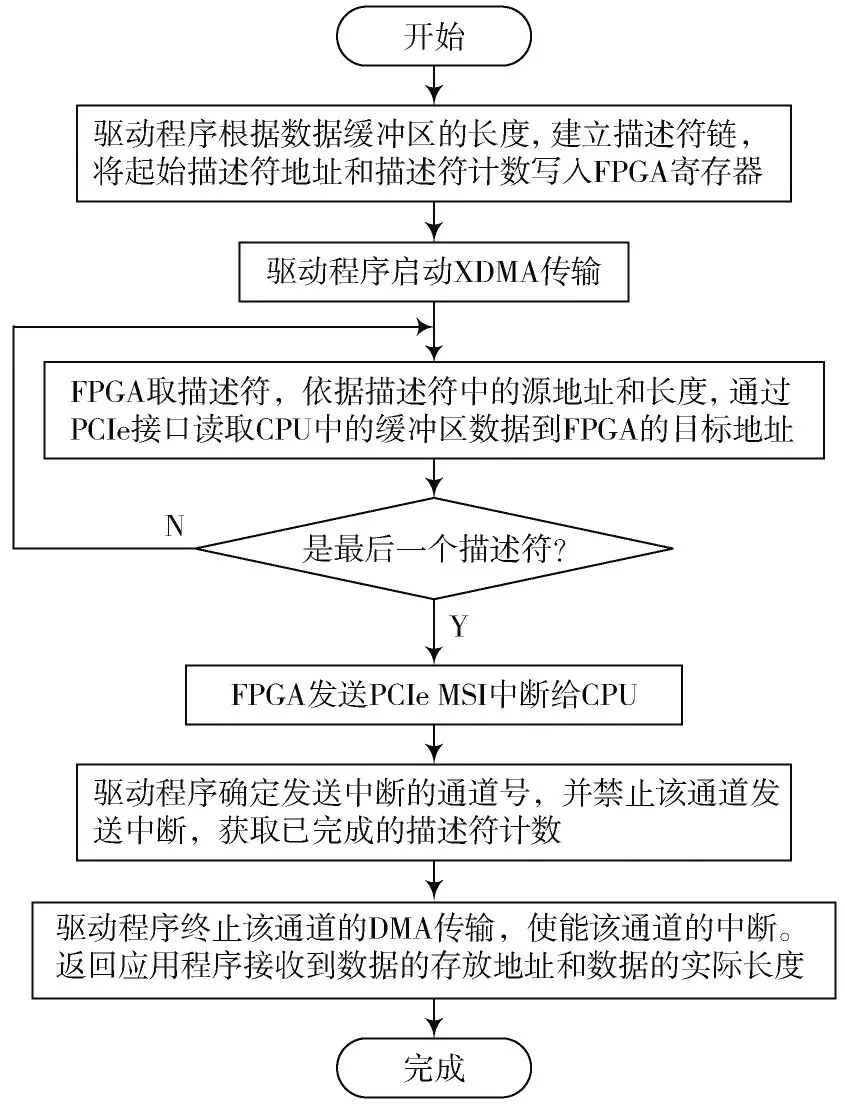
图3 XDMA 流程
当数据由CPU 搬运到FPGA 后,FPGA 通过AXI 总线把数据路由到RapidIO IP 软核[7-8],该IP 软核经过处理,把数据重新打包成符合RapidIO 协议的逻辑层和传输层帧格式,并最终通过SerDes 接口实现8B/10B 编码和数据串行化,最后把数据送到RapidIO 物理链路上。当RapidIO 物理链路上的数据到达FPGA 时,SerDes 接口对数据进行串并转换和8B/10B 解码,解析并提取RapidIO 帧的数据部分,并通过AXI 总线传递给DMA 模块,然后使用1.2 节描述的方法,把数据搬运到CPU 的内存中,并以PCIe MSI 中断的方式通知CPU 数据搬运完成。RapidIO IP 软核的功能模块结构如图4 所示。
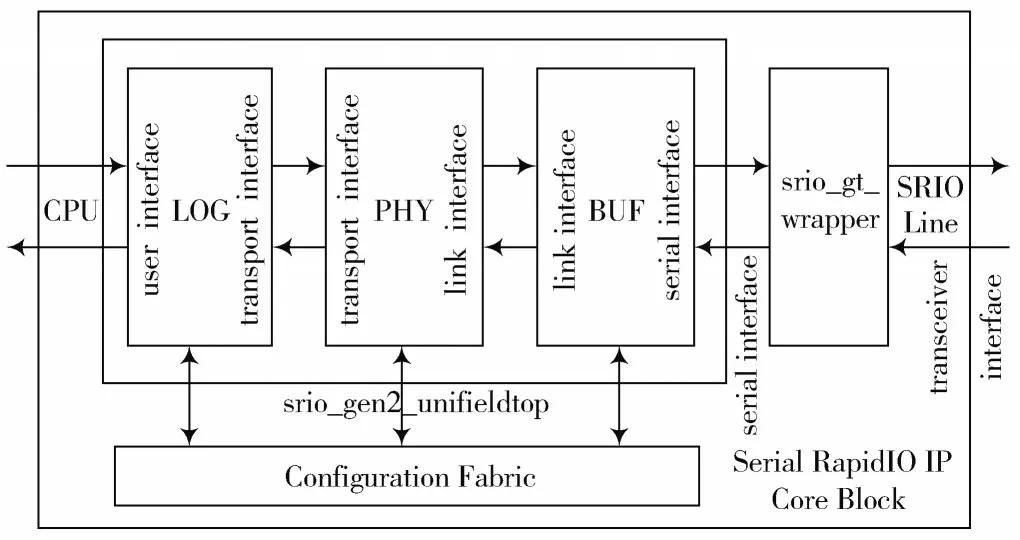
图4 RapidIO IP 软核的功能模块结构
2 方案论证与性能分析
2.1 方案论证
为了论证本文提出的RapidIO 国产化方案,选取某国产通信系统[9]的主控子卡和接入控制子卡,用龙芯2K1000 处理器和复旦微FPGA 组成的最小子系统替换原有的基于美国恩智浦公司PowerPC 8569E 方案。
如图5 所示,该通信系统是由多张子卡组成的复杂机架式系统,该系统的子卡可划分成三类,分别是控制子卡、业务子卡和业务辅助子卡。图5 中的两个灰色方块分别代表主控子卡和接入控制子卡,二者硬件组成上基本一致,接入交换芯片的RapidIO 信号均工作在x1 3.125 GHz 模式。业务子卡采用国防科大研发的M6678国产DSP 芯片,片上集成2 个RapidIO 端口。控制子卡与业务子卡均由RapidIO 差分信号通过连接器引出并经由背板布线信号接入国产TSI578RapidIO 交换芯片。按照本通信系统设计,控制子卡与业务子卡间有大批量、高实时性的业务数据传递需求。采用本国产化RapidIO 方案替换恩智浦公司的进口方案后,按照系统原有的设计用例进行回归测试显示,国产化方案在功能和性能上均满足设计要求。
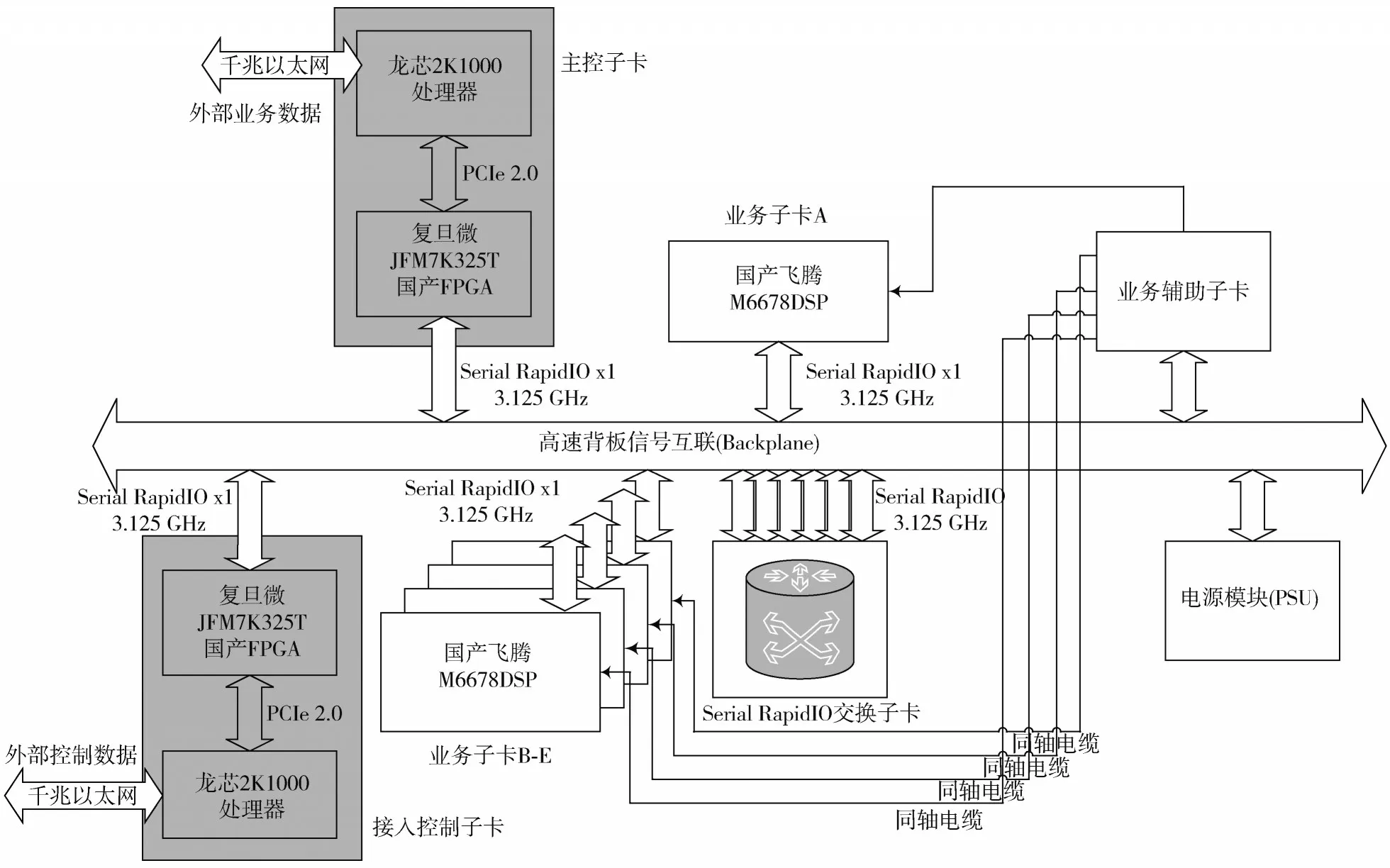
图5 某国产通信系统
2.2 性能分析
采用数据回环的方法测试CPU 与DSP 之间RapidIO 通信的性能[10],即CPU 通过RapidIO 接口发送不同长度的数据报文给DSP,DSP 收到数据后立即回环给CPU,CPU 通过记录数据发送时的时间戳和收到回环数据时的时间戳,计算回环数据时延。记录时间戳的方法[11]采用龙芯2K1000 处理器内部的125 MHz 的HPET 高精度定时器,理论计算精度为8 ns。为了计算方便,假设CPU 通过RapidIO 发送数据给DSP 的时间与DSP 通过RapidIO 发送数据给CPU 的时间大致相同,取回环数据时延的1 2 为CPU 到DSP 的数据发送时延。依据该方法测试,得到时延与带宽数据如表1所示。
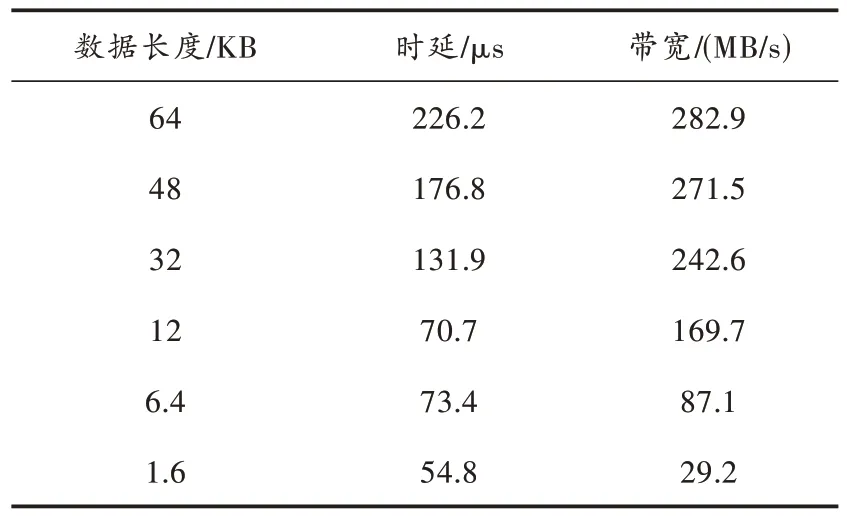
表1 时延和带宽统计
CPU 发送RapidIO 数据给DSP 的时延可大致分解成4 个阶段[12]。记这4 个阶段分别为T1~T4,如图6 所示。
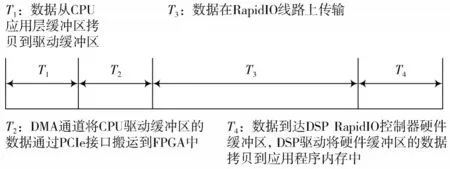
图6 时延组成的4 个阶段
图6 中:T1表示数据从CPU 应用层缓冲区拷贝到驱动缓冲区的时延;T2表示DMA 通道将CPU 驱动缓冲区的数据通过PCIe 接口搬运到FPGA 中的时延;T3表示数据在RapidIO 线路上的时延;T4表示数据到达DSP RapidIO 控制器硬件缓冲区后,DSP 驱动将硬件缓冲区的数据拷贝到应用程序缓冲区的时延。
表2 是依据上述4 个阶段,CPU 发送RapidIO 数据给DSP 时延的理论最优估算值。
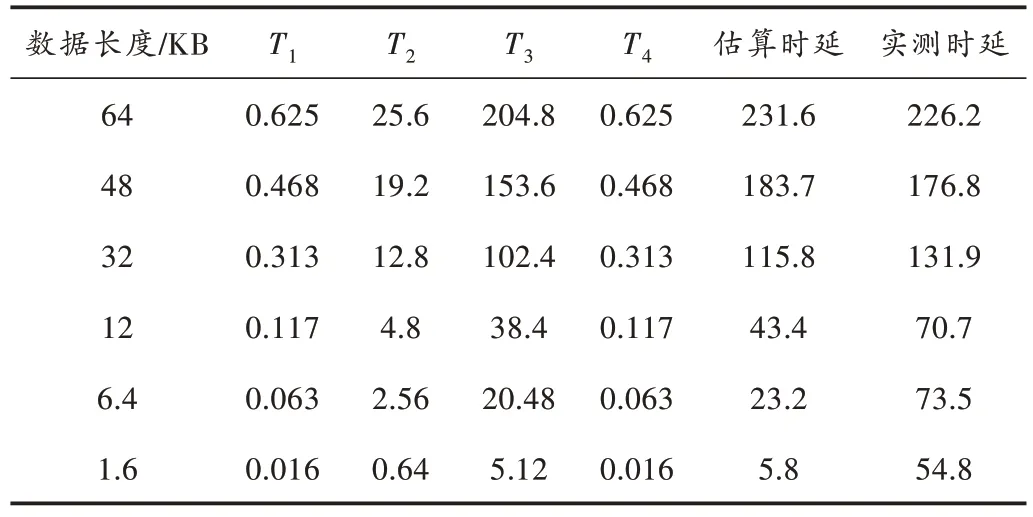
表2 T1~T4 阶段时延估算值 μs
表2 中:T1和T4是内存拷贝时延;T2是PCIe 总线传输时延;而T3是RapidIO 总线传输时延。龙芯2K1000 处理器和M6678 国产DSP 的工作主频均为1 GHz,均外接4 片DDR3 内存颗粒,总线宽度为64、内存工作频率为400 MHz;PCIe 接口符合PCIe 2.0 标准,由4 条差分信号对组成的x4 链路,单条链路的速度为5.0 GT/s;RapidIO总线工作在3.125 GHz,考虑到物理层采用8B/10B 编码,有效带宽为2.5 Gb/s。
针对内存拷贝时延的估算,忽略DDR3 信号的建立保持时间,得到T1和T4时延估算公式为:
忽略协议帧开销,仅考虑净荷数据,忽略物理层协议应答帧的时间开销,得到T2和T3的时延估算公式分别为:
表2 中的数据仅仅是一个粗略的估计[13],真实的时延计算需要考虑的问题比上述简化估算公式要多得多,为了计算方便,估算公式仅考虑各时间阶段最耗时的操作,且均以最优方式为衡量。不难看出,在发送数据长度大于等于32 KB 时,理论估计时延和实测时延吻合得较好,而数据长度小于等于6.4 KB 时,二者的误差则较大,原因在于:数据量较小时,CPU 时间戳计时的精度、CPU 数据缓存、CPU 时钟中断的粒度、CPU 任务上下文切换和中断上下文切换的时间、FPGA 封包RapidIO 协议帧以及SerDes 编码和串并转换的时间等因素给总时延带来的影响不可忽略。
3 结论
本文阐述的基于龙芯2K1000 处理器和复旦微FPGA 的国产RapidIO 解决方案可以实现与其他支持RapidIO器件(如飞腾M6678国产DSP)互通,本方案应用在2.1 节介绍的某通信系统中,可以实现原位替换原有的进口方案主控子卡和接入控制子卡。使用本国产RapidIO 方案替代后,该通信系统运行稳定,在进行大量数据传输的系统实验中,丢包率、误码率满足原系统设计要求。龙芯2k1000 处理器在运行主控子卡和接入控制子卡的业务逻辑代码中也展现了比较好的性能[14]。
综上,国产自主可控替代方案,一方面要考虑到性能指标是否能达标或者基本达标,另一方面也要考虑国产芯片的产能等一系列的问题。龙芯2K1000 处理器作为中科院计算所自主研发的国产CPU,制造工艺为28 nm,该制程在国内芯片制造厂家可以实现量产,不受美国实体清单的制约。因此,本文方案所涉及的芯片选取、FPGA 逻辑开发、操作系统的选取、驱动开发等多个方面都能实现自主可控、性能达标,具有一定的现实价值。
