基于知识和改进深度学习的网络主题文本快速过滤方法
2023-10-10刘丽娟
刘丽娟
国家计算机网络应急技术处理协调中心上海分中心 上海 201315
引言
网络主题文本过滤是一个复杂的课题,目前存在手段单一、效率低下等问题。现阶段研究大部分依赖人工手段,效率低下,并且鉴于不同人思维存在局限性,评判标准不同[1],导致主题文本的过滤结果有差异。此外,自动化手段不能充分利用已有的经验知识[2],容易造成遗漏、误判的现象。常用方法有用推荐系统[3]进行过滤,通过word2vec[4]进行内容识别,用决策树[5]识别敏感词变体,但上述方法适用领域有限。因此,亟须一种智能方法将“被动”查找主题文本转变为“主动”关联知识、经验,提高网络主题文本的过滤效率。
目前知识图谱[6]理论为过滤文本主题信息提供良好方法,深度学习理论[7]为模型训练提供了良好途径,二者结合能智能化地实现网络主题文本过滤。
本文提出一种基于知识和改进深度学习的网络主题文本快速过滤方法。首先对主题文本进行理解,融合知识图谱作为内部知识嵌入;其次联系上下文,对待查找主题文本进行语义扩展,作为外部知识嵌入;最后用改进深度学习模型处理主题词向量,依据目标定位主题文本。实验表明,该方法鉴别网络主题文本的准确率较高,缩短运算处理时间。
创新点在于:①在融合内部知识基础上,知识图谱使理解的角度更为全面;②嵌入上下文外部知识扩展语义,使主题过滤过程更为准确;③融合上述内、外部层次知识作为深度学习模型训练向量,使模型识别更为高效。
1 基于知识嵌入的主题文本分析
网络主题文本鉴别是一个反复迭代的过程,主题文本知识是一个不断丰富完善的过程,需用知识嵌入方法解决。知识嵌入是知识产生者与知识接受者之间交互的重要手段。知识嵌入分为内部知识嵌入和外部知识嵌入。
1.1 内部知识嵌入(嵌入知识图谱)
内部知识嵌入指知识图谱的实体关系嵌入。传统的主题文本识别方法难以综合实体间关系,嵌入实体关系能完整语义表示知识单元,准确识别主题文本。
实体关系以知识图谱形式进行嵌入。知识图谱旨在描述真实世界存在的各种实体或概念及其关系,构成语义网络图,节点表示实体或概念,边由属性或关系构成。主题信息在知识图谱中直观表示为KG=<head,relation,tail>,其中head、tail分别是三元组的头实体、尾实体,是KG的实体集合,relation={r1,r2,……,r|R|}是KG的关系集合,包含R种不同关系。使用Neo4j图数据库构建知识图谱,经过规范化存储能清晰地描述知识。
核心步骤是整合结构化数据、实体抽取和关系抽取非结构化数据,经过初步层次知识表示,将实体关系转化为连续的向量空间,经过知识推理,发现知识,在保留知识图谱的原有结构基础上完整嵌入实体关系。
对文本进行分词、词性标注及主题实体识别,去除停用词和无意义的单字,得到一组包含n个描述主题特征的关键词。一条由n个特征词构成的主题特征为x=[ , ,…],其中 是完整主题文本中第i个位置上的词汇,将特征关键词转换为词向量,映射为对应的d维表示向量
1.2 外部知识嵌入(嵌入上下文)
外部知识嵌入指嵌入上下文。由于文本在不同语境下含义不同,故需研究上下文,以便更准确地定位主题信息。结合主题文本过滤的范围、对象,借助关联关系,嵌入上下文进行语义扩展。主要过程是,定义主题文本上下文实体e,对上下文进行数据预处理,包括分词处理、去停用词、词频统计等,加入约束条件,获得提取主题特征结果的上下文向量。实体e的上下文向量context(e) ={ei|<e,r,ei>∈TopicInfoKG},是主题知识图谱TopicInfoKG相邻一跳的结点集合,实体关系r为上下文实体提供补充知识,扩展主题语义,提升主题的识别效率。
2 改进深度学习网络主题文本过滤模型
在知识嵌入基础上,建立改进深度学习网络主题文本过滤模型,如图1,共有四阶段,第一阶段是数据预处理,主要生成神经元网络输入数据和嵌入矩阵;第二阶段是神经元网络训练;第三阶段是特征组合;第四阶段用多重过滤机Multilayer Perceptron(MLP)实现分类。
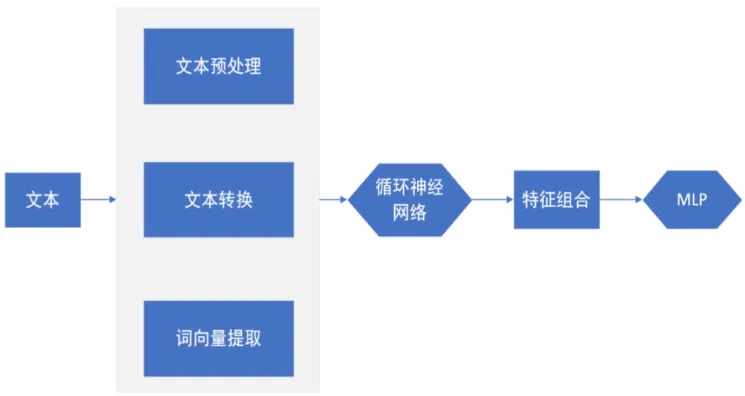
图1 模型处理阶段
网络输出层用Sigmoid函数进行二分类,定义域为0到1开区间,根据0.5进行分界,若结果大于等于0.5,说明为正样本,否则为负样本,从而实现分类,过滤主题文本信息。计算公式如下:
知识操作具体过程是,从知识提取中得到每个词语 对应的实体向量∈、实体上下文向量∈,k是实体嵌入的维数。对主题描述文本输入包括主题特征向量词语-实体对齐后的实体向量,实体上下文向量词语-实体对齐转换函数g(e)=tanh(Me+b),通过上述操作,将特征连接在一起,输入到词向量空间,保持原有空间关系。主题文本x用e(x)表示。Softmax分类器输入是主题描述文本e(x),经过归一化得到主题文本在第k种主题的输出概率,不断训练直到模型符合拟合要求为止。
3 实验分析
用准确度Accuracy、精度Precision、召回率Recall和F1值指标分别评价主题文本检测方法性能,比较关键词法、互信息法、深度学习法、基于知识嵌入的改进深度学习方法。TP表示正确分类下正样本数,TN表示正确分类下负样本数,FP表示负样本误分类为正样本数量,FN表示正样本误分类为负样本数量,公式分别如下:
针对“进口博览会”主题,对比上述方法,比较F1值,可知本文的知识嵌入改进深度学习法的F1值最佳,如图2。
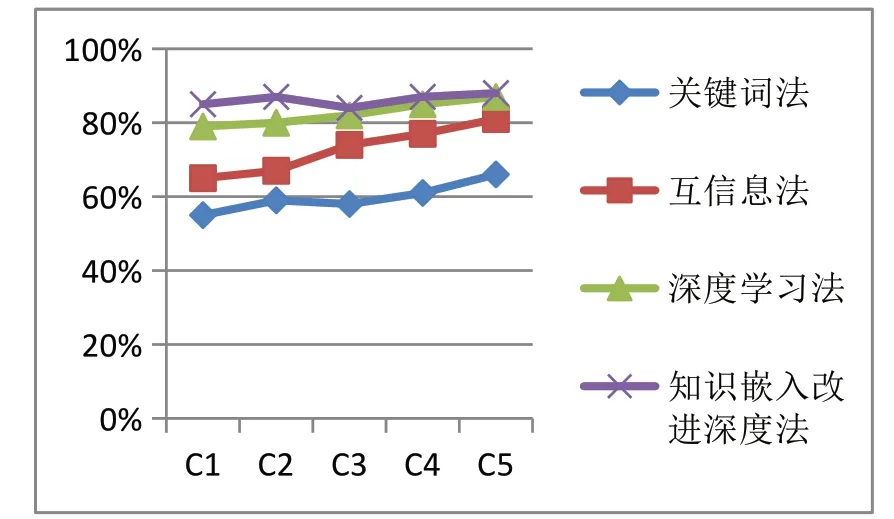
图2 不同方法的F1值比较
以响应耗时为检验指标,比较用不同方法处理100个、200个、400个……个节点的应用性能,如图3所示。可看出随着主题信息节点数量不断增加,不同算法响应耗时不断减少。关键词法、互信息法、深度学习法三种算法响应耗时均在2s以上。而知识嵌入改进深度学习法的处理耗时始终在1s内,平均处理耗时在0.9s左右。综上可看出,本文提出的方法能节省运算处理时间,实现网络主题文本准确、快速过滤。
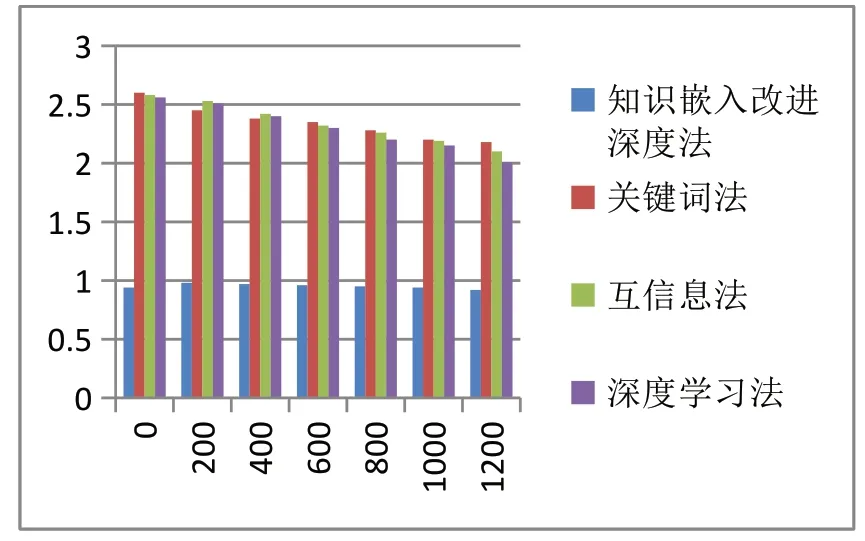
图3 不同方法的耗时响应时间
4 结语
本文提出一种基于知识和改进深度学习的网络主题文本快速过滤方法。贡献有:①利用图谱嵌入实体关系,获得主题内部知识;②通过嵌入上下文外部知识,丰富并扩展语义范围;③一个智能的改进深度学习网络主题文本快速过滤模型。
下一步工作重点将关注知识图谱嵌入的效率,重点考虑如何使知识描述更为丰富完整,并在此基础上加强扩展能力,增强处理能力。
