采用细胞形态特征对比学习的肺癌图像分类
2023-10-10江海峰赵雪芬
贾 伟,江海峰,赵雪芬
1.宁夏大学 信息工程学院,银川 750021
2.宁夏医科大学总医院 病理科,银川 750021
3.宁夏大学 新华学院,银川 750021
肺癌是起源于肺部支气管和肺泡上皮细胞的肿瘤[1-2],其具有高发病率和高死亡率的特点,已经成为威胁人类健康和生命的恶性肿瘤之一[3-5]。对肺癌的准确分类有助于病理医生提高诊断的准确率,选择合适的治疗方案,以及提高患者的生存几率[6-7]。
近年来,深度学习在的病理图像分析中有着成功的应用[8-10],已经提出了一些肺癌病理图像分类方法。例如,Ali 等[11]对胶囊网络[12]的结构进行改进,提出基于多输入双流胶囊网络的分类方法(multi-input dual-stream capsule network-based classification method,MCM)对肺癌病理图像进行分类,该方法使用传统的卷积层、可分离的卷积层和胶囊层去提高特征学习能力。Li 等[13]提出基于卷积神经网络和相关特征算法[14]的分类方法(convolutional neural networks and relevant features algorithm-based classification method,CRM)对肺癌病理图像进行分类,该方法使用卷积神经网络提取肺癌病理学图像的多维特征,然后使用相关特征算法进行特征选择,最后采用支持向量机分类器对肺癌进行分类。
然而,由于肺癌细胞的形态结构复杂,使得标记肺癌病理图像的成本较高,导致已标记的肺癌病理图像较少,影响了现有分类方法的训练精度和分类效果。为解决训练数据不足的问题,He 等[15]提出一种无监督情况下的动量对比视觉表征学习(momentum contrast for unsupervised visual representation learning,MoCo),该方法使用具有队列和移动平均的动态字典编码器,通过查字典的方式进行对比学习,并引入动量更新方法。为了扩充对比学习中的样本数据,Chen 等[16]提出一种用于视觉表示的对比学习方法(simple framework for contrastive learning of visual representations,SimCLR),该方法通过对图像进行两次增广,对两张增广图像进行对比学习。为了增加对比样本数据的多样性,Dwibedi等[17]提出最近邻对比学习(nearest-neighbor contrastive learning of visual representations,NNCLR),该方法对一个数据增广图像和另一个增广图像的最近邻图像进行对比学习,但是该对比方法没有充分利用增广图像的最近邻图像,缺少对最近邻图像之间的对比学习。
为充分挖掘和利用已标记肺癌图像和未标记肺癌图像的细胞形态特征信息,在NNCLR方法的基础上,本文提出一种基于细胞形态特征对比学习的方法(cell morphology contrastive learning-based classification method,CCCM)对肺癌病理图像进行分类。该方法提出基于最远和最邻近的对比学习(farthest and nearestneighbors-based contrastive learning,FNNCL),将FNNCL用于提取已标记肺癌图像和未标记肺癌图像的细胞形态特征,并利用由未标记数据生成的伪标签对FNNCL和分类器进行辅助训练。在FNNCL 中,将基于可变形卷积[18]和动态卷积[19]的ResNet50(deformable convolution and dynamic convolution-based ResNet50,DD-ResNet50)作为特征提取网络,提取肺癌病理图像的形态特征信息,并对原图像增广后的两个图像及其相应的最远和最近邻图像进行对比学习,从而进一步增加对比学习中的数据多样性。此外,为衡量CCCM的分类结果与真实分类的差距,在NNCLR的基础上给出了CCCM的损失函数。
1 基于细胞形态特征对比学习的分类方法
CCCM 的整体框架如图1 所示,其包括三个阶段:第一个阶段是利用已标记肺癌病理图像进行对比学习训练,获得网络的参数。第二个阶段是利用训练后网络对未标记肺癌病理图像进行分类,然后,在分类结果中选择比例为α的高置信度未标记数据作为伪标签,并将这些伪标签混入到已标记肺癌病理图像中。第三个阶段是利用混入伪标签的肺癌病理图像进行对比学习训练。第二个阶段和第三个阶段反复进行迭代,训练网络。

图1 CCCM的整体框架Fig.1 Overall architecture of CCCM
NNCLR 的结构如图2 所示,其使用ResNet50 网络作为提取特征的编码器,对原图像进行两次不同的增广,得到增广图像x1和x2,分别对x1和x2进行编码,得到z1和z2,在z1的支持集Q中找到与z1最近邻的图像n1,将n1和z2作为正样本对,进行对比学习。

图2 NNCLR的结构Fig.2 Structure of NNCLR
为提升对比学习的性能,本文在NNCLR的基础上,提出FNNCL,在增加最近邻图像多样性的同时,还将离样本点距离最远但是属于同一类的样本作为正样本,用于对比学习,其目的是增加正样本学习的难度,提升对比学习的性能。FNNCL的模型结构如图3所示,首先通过两种不同的增广方式对原图像进行两次不同的增广,得到两个增广图像c1和c2,然后利用DD-ResNet50 对c1和c2进行编码,得到e1和e2,在e1的支持集R1中找到与e1最远和最近邻的图像f1和f3,在e2的支持集R2中找到与e2最远和最近邻的图像f2和f4,最后对f1和e2,e1和e2,f2和e1,f1和f2,f3和e2,f4和e1,f3和f4,f1和f4,f2和f3进行对比学习。
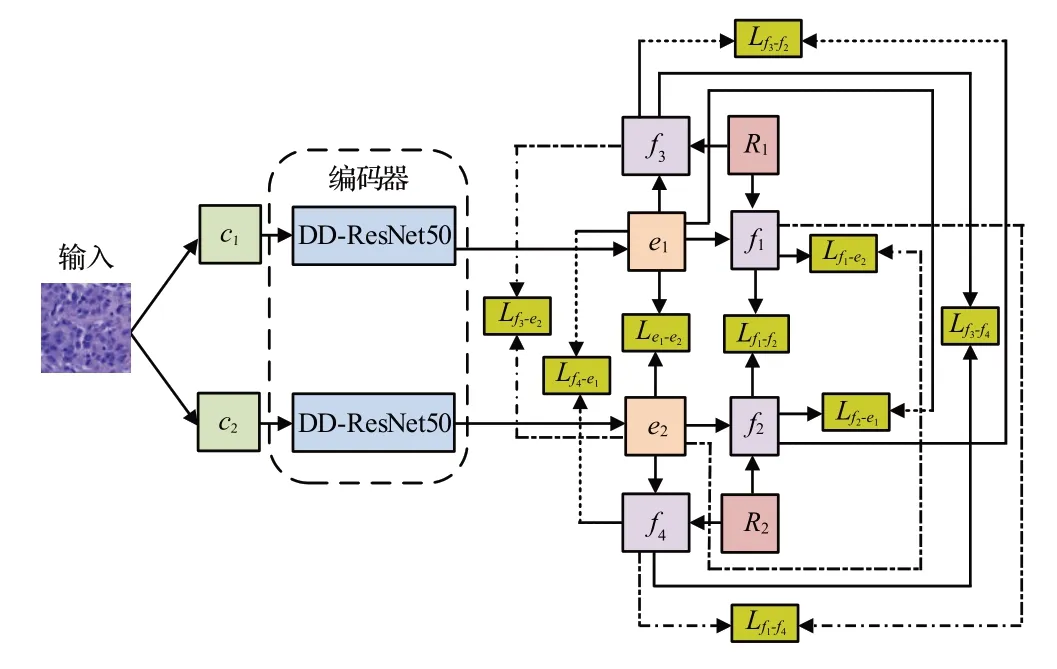
图3 FNNCL的结构Fig.3 Structure of FNNCL
1.1 特征提取网络
为增强ResNet50 网络对肺癌细胞的特征提取能力,编码器使用DD-ResNet50,将可变形卷积和动态卷积应用到ResNet50网络中,其结构如图4所示。第一个阶段由多尺度可变形卷积模块(multi-scale deformable convolution module,MDCM)、批归一化(batch normalization,BN)、激活函数ReLU 和全局最大池化(global max pooling,GMP)组成,利用MDCM具有自适应物体形态变化的特征表达能力,对不规则和形态复杂的肺癌细胞边界、形状和排列结构进行采样,获得更准确的特征信息。第二个到第五个阶段,分别使用融合可变形卷积和动态卷积的模块(deformable convolution and dynamic convolution-integrated module,DDⅠM)提取特征,DDⅠM 在第二个到第五个阶段的数量分别为2 个、3个、5个和2个。通过DDⅠM的可变形卷积确保深层网络的有效感受野,并利用动态卷积更好地提取与噪声无关的特征信息。第六个阶段由一个全局平均池化(global average pooling,GAP)和一个全连接层(fully connected,FC)组成。

图4 DD-ResNet50的结构Fig.4 Structure of DD-ResNet50
1.1.1 多尺度可变形卷积模块
对于一个输入的二维特征图,普通卷积使用规则网格R对特征图x进行采样,然后对采样点进行加权运算,对于一个卷积为3×3,膨胀率为1的R可表示为:R={(-1,-1),(-1,0),…,( 0,1),( 1,1) },则可通过下式计算输出特征图中的每个位置p0:
其中,p0枚举R上的所有位置,w(⋅)是当前卷积核的位置权重,x(⋅)是特征图对应的位置值。
对于可变形卷积,通过在R上增加偏移量{Δp|n=1,2,…,N},N=|G|,对R进行扩张,得到下式:
由于Δp通常是小数,通过双线性插值法计算x,计算公式为:
其中,p是任意位置,q是枚举特征图中的空间位置,G( ⋅,⋅)表示双线性插值核。
二维卷积可以分解为两个一维内核:
其中,g(a,b)=max( 0,1-|a-b|)。
普通卷积与可变形卷积对肺癌病理图像的采样结果如图5 所示,从图中可以看出,与普通卷积的采样结果相比,可变形卷积的采样位置更符合肺癌细胞的复杂形态,有利于提取更准确的特征信息。

图5 普通卷积与可变形卷积的采样比较Fig.5 Sampling comparison between standard convolution and deformable convolution
MDCM 的结构如图6 所示,其使用了卷积核为3×3、5×5和7×7的三个并行可变形卷积和一个作为残差分支的1×1卷积。三个可变形卷积可以获得不同尺度下的形态特征信息,对于从两个不同尺度的可变形卷积获得的形态特征,利用特征融合模块(feature fusion module,FFM)进行形态特征融合。
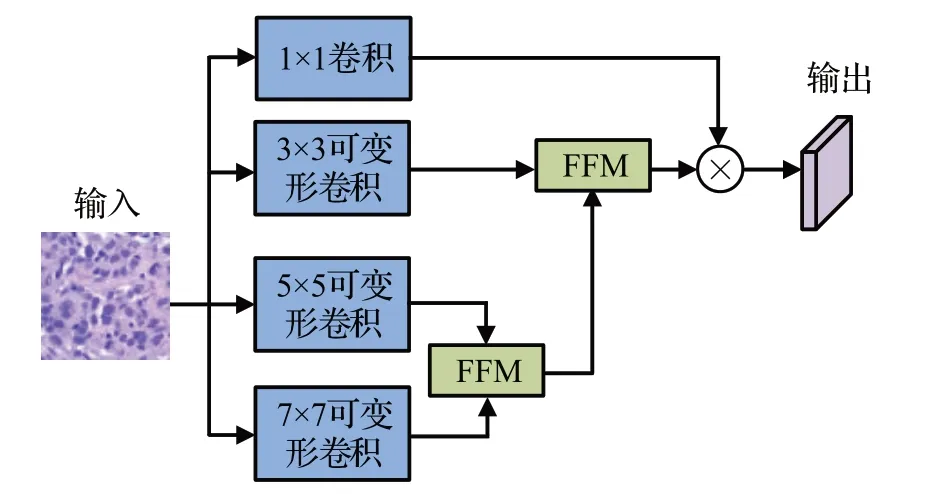
图6 MDCM的结构Fig.6 Structure of MDCM
FFM的结构如图7所示,对使用两个尺度可变形卷积获得的A1和A2分别进行1×1卷积,然后进行连接,再进行两次3×3可变形卷积、BN和ReLU处理,利用Softmax函数得到两个权重值W1和W2,通过W1⊗A1+W2⊗A2计算得到加权融合的形态特征A3,再对第二次3×3 可变形卷积、BN 和ReLU 的处理结果进行两次1×1 卷积,并将卷积结果与A3进行乘运算,得到特征融合结果。
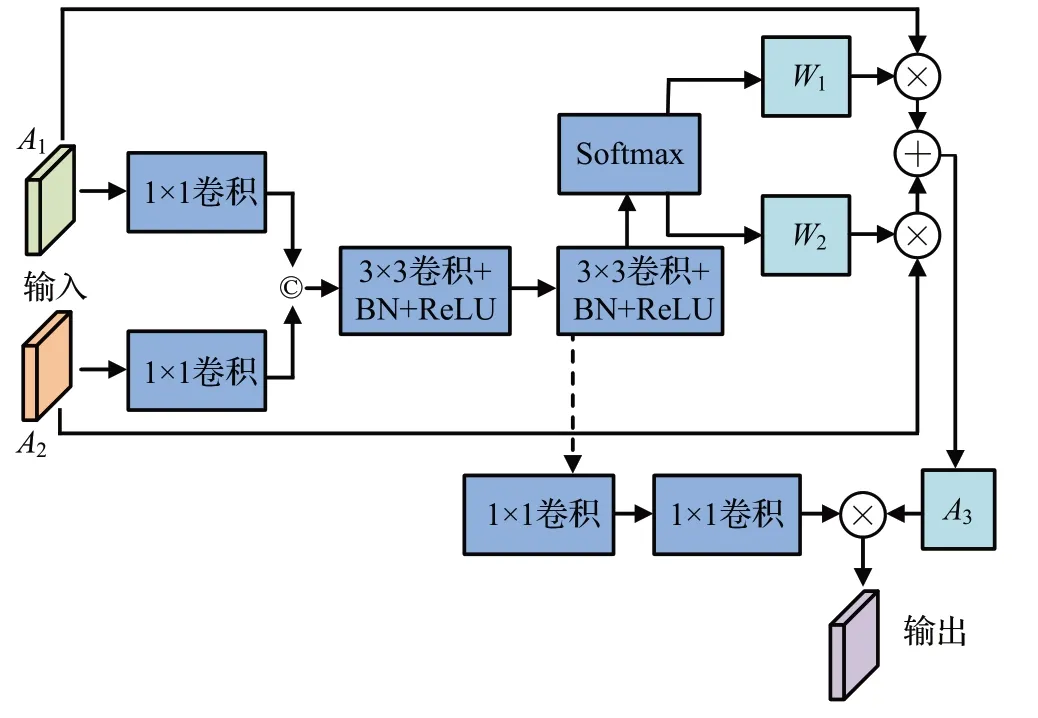
图7 FFM的结构Fig.7 Structure of FFM
1.1.2 融合可变形卷积和动态卷积的模块
动态卷积的结构如图8所示,由系数预测模块和动态生成模块组成。根据输入的图像,系数预测模块负责预测系数,该模块由GAP 和Sigmoid 激活函数组成。GAP 将输入的特征图聚合成1×1×Cin向量,然后通过全连接层将特征映射为1×1×C向量,从而预测固定的多个卷积核之间的相关系数。根据预测的相关系数,动态生成模块负责生成一个动态的卷积核,对于一个权值为[Cout×gt,Cin,k,k]的动态卷积层,其对应了Cout×gt个固定核和Cout个动态核,每个核的大小为[Cin,k,k],gt表示组大小,属于超参数。

图8 动态卷积的结构Fig.8 Structure of dynamic convolution
使用系数预测模块获得相关系数后,生成的动态核为:
其中,wti是固定核,w͂t是动态核,ηit是相关系数,且t=0,1,…,Cout,i=0,1,…,gt。
在训练中,使用基于相关系数的训练方案,实现特征图的融合,训练方案可用下式表示:
文献[17]给出一种动态卷积模块(dynamic convolution module,DCM),在ResNet50 中增加动态卷积的方式,其结构如图9所示,包括三个分支,第一个分支由一个GMP 和两个FC 组成,用于减少梯度消失,第二个分支包括三个动态卷积,第三个分支是残差分支。
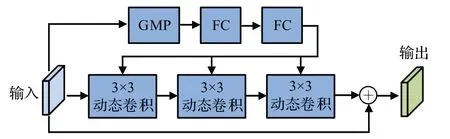
图9 DCM的结构Fig.9 Structure of DCM
在DCM 的基础上,本文将可变形卷积和动态卷积同时增加到ResNet50 中,给出的DDⅠM 结构如图10 所示,DDⅠM包括两个分支,第一个分支包括两个子分支,分别采用GMP 和GAP,目的是从两个不同的表征中获得特征信息,其中,第一个子分支由一个GMP 和两个FC组成,用于提取肺癌病理图像的纹理特征信息,第二个子分支由一个GAP和两FC组成,用于保留局部空间信息。对两个子分支进行乘运算,目的是整合纹理特征信息和局部空间信息。将第一个部分获得的特征信息分别与第二个部分的三个卷积连接,从而提取更准确的全局特征和局部细节特征。

图10 DDⅠM的结构Fig.10 Structure of DDⅠM
第二个分支由一个3×3可变形卷积和两个3×3动态卷积串联组成,目的是利用可变形卷积对肺癌细胞的边界、形状和排列结构进行采样,再通过两个动态卷积进一步获得与噪声无关的特征信息。为加强输入图像与各卷积的联系,并提升不同卷积之间的特征融合,对输入图像和各卷积的结果进行1×1卷积处理,再将当前1×1 卷积的结果与前一个1×1 卷积的结果进行连接,然后将当前卷积结果、两个1×1卷积连接结果和前一个卷积的结果进行乘运算,作为下一个卷积的输入。
1.2 损失函数
设给定一批图像{x1,x2,…,xn} ,对每一个图像xi,通过两种不同的图像增广方法,再经过编码器,得到特征zi和z+i,则NNCLR的损失函数[17]可由下式计算:
其中,τ是可调参数,NN(zi,Q)是最近邻算子,将其定义为:
本文在NNCLR 的基础上,给出CCCM 的损失函数,设给定一批图像{c1,c2,…,cn} ,对每一个图像ci,通过两种不同的图像增广方法,再经过编码器,得到特征ei和e+i,则CCCM的损失函数可由下式计算:
其中,是ei的最远图像与e+i的对比损失函数是ei与e+i的对比损失函数,是e+i的最近邻图像与ei的对比损失函数,是ei的最远图像与e+i的最远图像的损失函数,是ei的最近邻图像与e+i的对比损失函数,是的最近邻图像与ei的对比损失函数,是ei的最近邻图像与e+i的最近邻图像的损失函数,是ei的最远图像与e+i的最近邻图像的对比损失函数,是ei的最近邻图像与e+i的最远图像的对比损失函数,这九个损失函数分别通过下列公式计算:
其中,F(e,R)是最远算子,其定义为:
2 实验分析
2.1 实验数据
实验中的数据来自于肺癌病理图像分类实验常用的开源数据集癌症基因组图谱公共数据库(the cancer genome atlas,TCGA)[20]和LC25000[21],以及宁夏医科大学总医院病理科提供的肺癌病理图像。其中,TCGA包括肺腺癌病理图像522张和肺鳞状细胞癌病理图像504张,LC25000 包括肺腺癌、肺鳞状细胞癌和良性肺组织三种类型,每种类型包含5 000张病理图像,宁夏医科大学总医院病理科的肺部病理图像包括肺腺癌、肺鳞状细胞癌和良性肺组织三种类型,共有500张已标记图像和3 100张未标记图像。
2.2 评价指标
本文使用准确率、精确率、召回率和F1-Score 四个指标对分类效果进行评价,准确率越高,表示对阳性样本和阴性样本的分类越准确。精确率越高,表示在分类为阳性的样本中,真正为阳性的样本所占的比例越高。召回率越高,表示分类正确的阳性样本数在实际阳性样本中的比例越高。利用F1-Score 评价分类性能在精确率和召回率上的总体表现,F1-Score 的值越高,表示精确率和召回率在分类上的总体表现越好,准确率、精确率、召回率和F1-Score的计算公式分别为:
其中,TP是分类为阳性的阳性样本数,FP是分类为阳性的阴性样本数,TN是分类为阴性的阴性样本数,FN是分类为阴性的阳性样本数。
2.3 实验结果与分析
在实验中,使用Python3.6 实现肺癌病理图像分类方法,将Keras 作为深度学习框架,使用Windows 10 操作系统,在Ⅰnteli9-10900K和NVⅠDⅠA TⅠTAN RTX的硬件平台上运行。
2.3.1 参数设置
图像增广方式采用随机增广方式,例如,随机裁剪、旋转、随机颜色失真和高斯模糊等。使用随机梯度下降优化器优化模型,基础学习率为0.05,批大小设置为64,使用余弦衰减策略,动量设置为0.9,训练迭代次数为500次。
在CCCM中,从未标记肺癌病理图像中选择不同比例的高置信度未标记数据作为伪标签,对分类结果有重要影响。为确定高置信度未标记数据的比例α,分别选取10%、20%、30%、40%、50%、60%、70%、80%和90%的高置信度未标记数据作为伪标签,应用到CCCM的第三阶段中。
在确定α值的实验中,为增加肺癌数据的多样性,从癌症基因组图谱公共数据库、LC25000和宁夏医科大学总医院病理科的肺部病理图像中选取3 900张肺部病理图像形成混合数据,其中,已标记肺癌病理图像共有900张,包括肺腺癌、肺鳞状细胞癌和良性肺组织3种类型,每种类型包含300 张病理图像,未标记肺癌病理图像共有3 000 张。在实验时,将900 张已标记肺癌病理图像中的80%数据作为CCCM 第一阶段的已标记的训练数据,即得到720张已标记数据作为第一阶段的训练数据。将3 000张未标记肺癌病理图像作为CCCM第二阶段的未标记训练数据,将900张已标记肺癌病理图像中剩余的20%数据作为验证集,即得到180张已标记数据作为验证集。
不同α值对分类效果的影响如图11所示,从图中可以看出当α的取值在20%时,四项评价指标均能达到较高的值,说明此时CCCM的分类效果较好。当α的取值在10%时,可用于CCCM 第三阶段的伪标签数量较少,CCCM 不能充分挖掘和利用伪标签中的特征信息。当α的取值在30%、40%、50%、60%、70%、80%和90%时,分类效果逐渐变差,这是因为随着伪标签数量不断增多,存在大量质量不高的伪标签,将这些质量不高的伪标签加入到CCCM第三阶段的训练中,导致第三阶段的训练效果不好,影响了CCCM的分类效果。因此,在CCCM中,使用比例为20%的高置信度未标记数据作为伪标签。

图11 不同α 值对分类的影响Fig.11 Effects of α on classification
2.3.2 消融实验
在消融实验中,采用在确定α值实验中使用的混合数据作为实验数据。
本文在编码器ResNet50 中加入MDCM 和DDⅠM,采用消融实验评价MDCM 和DDⅠM 对分类效果的影响,采用不同方式替换FNNCL中的编码器,包括七组实验,每组实验依然将900张已标记肺癌病理图像中80%的数据作为CCCM第一阶段的已标记的训练数据,即得到720 张已标记数据作为第一阶段的训练数据。将3 000张未标记肺癌病理图像作为CCCM第二阶段的未标记训练数据,将900张已标记肺癌病理图像中剩余的20%数据作为验证集,即得到180 张已标记数据作为验证集。第一组是ResNet50,第二组是在ResNet50中只加入可变形卷积,即ResNet50+DE,第三组是在ResNet50中只加入动态卷积,即ResNet50+DY,第四组是在ResNet50中加入可变形卷积和动态卷积,即ResNet50+DE+DY,第五组是在ResNet50 中加入MDCM,即ResNet50+MDCM,第六组是在ResNet50中加入DDⅠM,即ResNet50+DDⅠM,第七组是本文提出在ResNet50中加入MDCM和DDⅠM的方法DD-ResNet50。
表1 是不同模块加入到编码器ResNet50 的分类效果比较,从表中可以看出,使用ResNet50的分类效果低于其他六组,说明在ResNet50 加入可变形卷积和动态卷积之后,能够提取到更准确的肺癌病理特征,有利于后续的对比学习。ResNet50+DE+DY 的分类效果优于ResNet50+DE 和ResNet50+DY,说明将可变形卷积和动态卷积相结合,有利于获得更全面的特征信息。ResNet50+MDCM 和ResNet50+DDⅠM 的分类效果分别优于ResNet50+DE 和ResNet50+DY,说明通过对可变形卷积和动态卷积的改进,能够进一步提升ResNet50的特征提取能力,DD-ResNet50的分类效果优于其他六组,说明将MDCM和DDⅠM同时加入到ResNet50中,能够在全局和局部细节方面获得更加准确的特征信息。
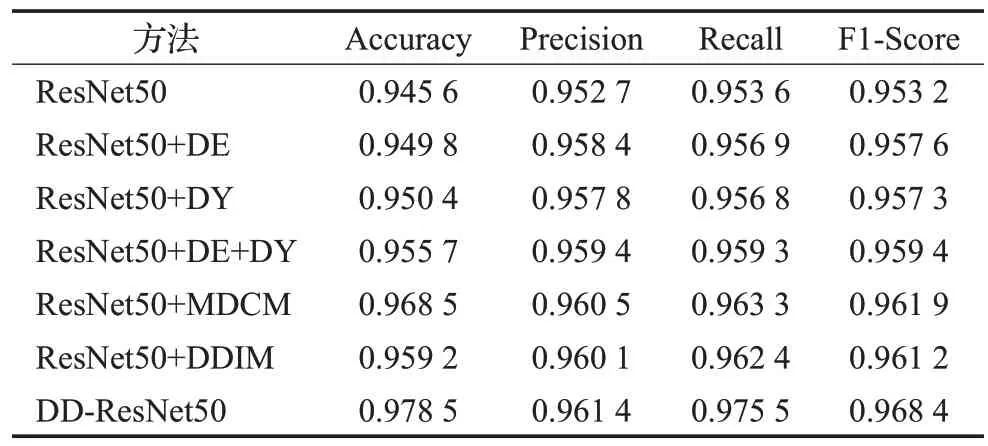
表1 不同模块加入编码器的实验结果Table 1 Experimental results of different modules added to encoder
SimCLR 使用增广图像e1和增广图像e2进行对比学习的策略e1e2,NNCLR使用e1最近邻的图像f3和e2进行对比学习的策略f3e2。在本文给出FNNCL的对比策略中,提出同时对增广图像e1,增广图像e2,e1的最远图像f1,e1的最近邻的图像f3,e2的最远图像f2,e2的最近邻图像f4进行对比学习的策略,即第一组f1与e2的对比学习f1e2,第二组e1与e2的对比学习e1e2,第三组f2与e1的对比学习f2e1,第四组f1与f2的对比学习f1f2,第五组f3与e2的对比学习f3e2,第六组f4与e1的对比学习f4e1,第七组f3与f4的对比学习f3f4,第八组f1与f4的对比学习f1f4,第九组f2与f3的对比学习f2f3。
下面通过消融实验,验证SimCLR、NNCLR和FNNCL提出的对比学习策略对分类效果的影响。将3 种对比学习的策略加入到本文提出的编码器为DD-ResNet50的对比学习分类方法中,得到的分类效果如表2 所示。从表中可以看出,e1e2的分类效果低于其他两组,f3e2优于e1e2的分类效果,这是因为与SimCLR的对比学习策略相比,NNCLR采用了e1的最近邻图像进行对比学习,增加对比学习中的数据多样性。采用FNNCL 的对比学习策略所得到的分类效果明显优于其他两种对比学习策略,说明通过在对比学习策略增加最远和最近邻图像的对比学习,能够进一步增加正样本学习的难度和数据多样性,从而更充分地使用癌症病理图像的特征信息,使得分类效果越好。

表2 不同对比学习策略的实验结果Table 2 Experimental results of different contrastive learning
2.3.3 分类方法的比较
在分类方法的比较实验中,通过与现有分类方法MCM[11]、CRM[13]、MoCo[15]、SimCLR[16]和NNCLR[17]比较,验证本文的分类方法CCCM 对肺癌病理图像的分类效果。
为了在分类性能方面对各分类方法进行详细的分析和比较,将实验中的数据分为开源数据集和混合数据,开源数据集包括TCGA 和LC25000 两个开源数据集,混合数据采用确定α值实验中使用的数据,目的是通过混合多种来源的数据,增加肺癌病理图像的多样性,对分类方法进行综合分析。
在使用开源数据集进行实验时,为说明不同比例已标记数据对分类方法的影响,将实验分为三组,第一组分别将两个开源数据集40%的已标记数据作为现有分类方法和CCCM 第一阶段的已标记训练数据,即从TCGA 中选取410 张已标记病理图像,从LC25000 中选取6 000张已标记病理图像。再分别将两个开源数据集10%的已标记数据作为未标记数据,用于CCCM第二阶段的未标记训练数据,即从TCGA中选取103张已标记病理图像作为未标记数据,从LC25000 中1 500 张已标记病理图像作为未标记数据。分别将两个开源数据集剩余的已标记数据作为验证集,即得到TCGA中剩余的513已标记病理图像,LC25000中剩余的7 500张已标记病理图像。第二组分别将两个开源数据集中的60%已标记数据作为现有分类方法和CCCM 第一阶段的已标记训练数据,即从TCGA 中选取616 张已标记病理图像,从LC25000 中选取9 000 张已标记病理图像。再分别将两个开源数据集10%的已标记数据作为未标记数据,用于CCCM第二阶段的未标记训练数据,即从TCGA中选取103 张已标记病理图像作为未标记数据,从LC25000 中1 500 张已标记病理图像作为未标记数据。分别将两个开源数据集剩余已标记数据作为验证集,即得到TCGA 中剩余的308 已标记病理图像,LC25000 中剩余的4 500张已标记病理图像。第三组分别将两个开源数据集80%的已标记数据作为现有分类方法和CCCM第一阶段的已标记训练数据,即从TCGA中选取821张已标记病理图像,从LC25000中选取12 000张已标记病理图像。再分别将两个开源数据集10%的已标记数据作为未标记数据,用于CCCM第二阶段的未标记训练数据,即从TCGA中选取103张已标记病理图像作为未标记数据,从LC25000 中1 500 张已标记病理图像作为未标记数据。分别将两个开源数据集剩余已标记数据作为验证集,即得到TCGA中剩余的102张已标记病理图像,LC25000中剩余的1 500张已标记病理图像。
使用各分类方法对两个开源数据集进行分类,三组实验的四项评价指标的比较结果如表3~6所示。从表3可以看出,在对两个开源数据集进行分类时,CCCM 使用不同比例的训练数据得到的准确率均高于其他分类方法,说明CCCM 的分类结果更接近实际的整体分类结果。

表3 开源数据集的准确率比较Table 3 Accuracy comparison of open source datasets
从表4 可以看出,在对两个开源数据集进行分类时,CCCM使用不同比例的训练数据得到的精确率均高于其他分类方法,说明使用CCCM对阳性样本的分类准确程度较高。
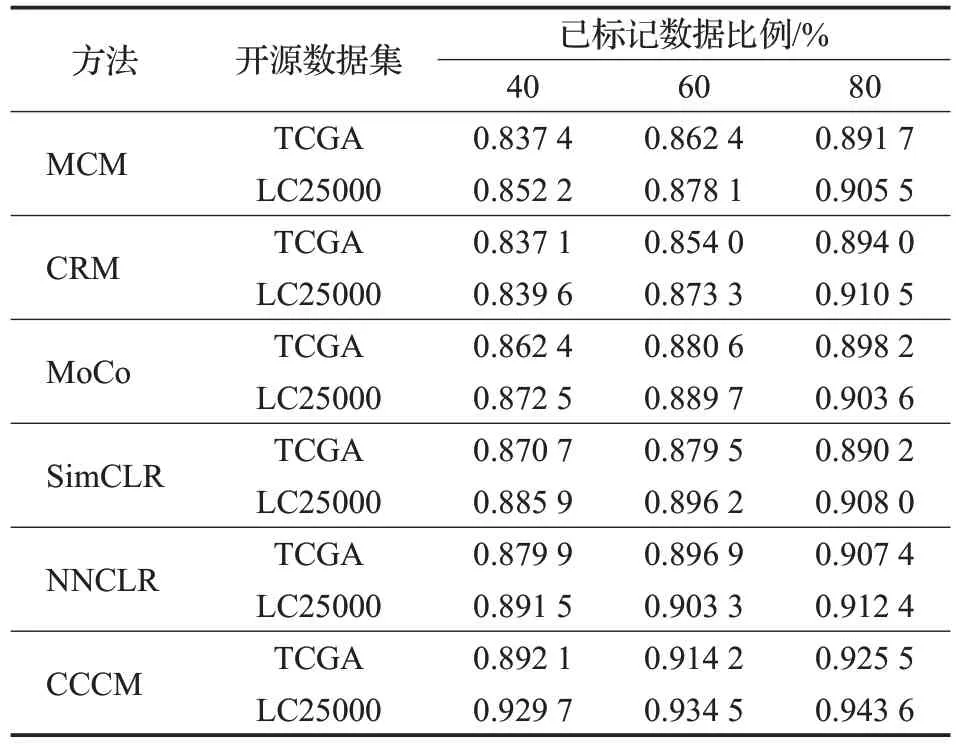
表4 开源数据集的精确率比较Table 4 Precision comparison of open source datasets
从表5 可以看出,在对两个开源数据集进行分类时,CCCM 使用不同比例的训练数据得到的召回率均高于其他分类方法,说明CCCM 对阳性样本的识别能力较好。
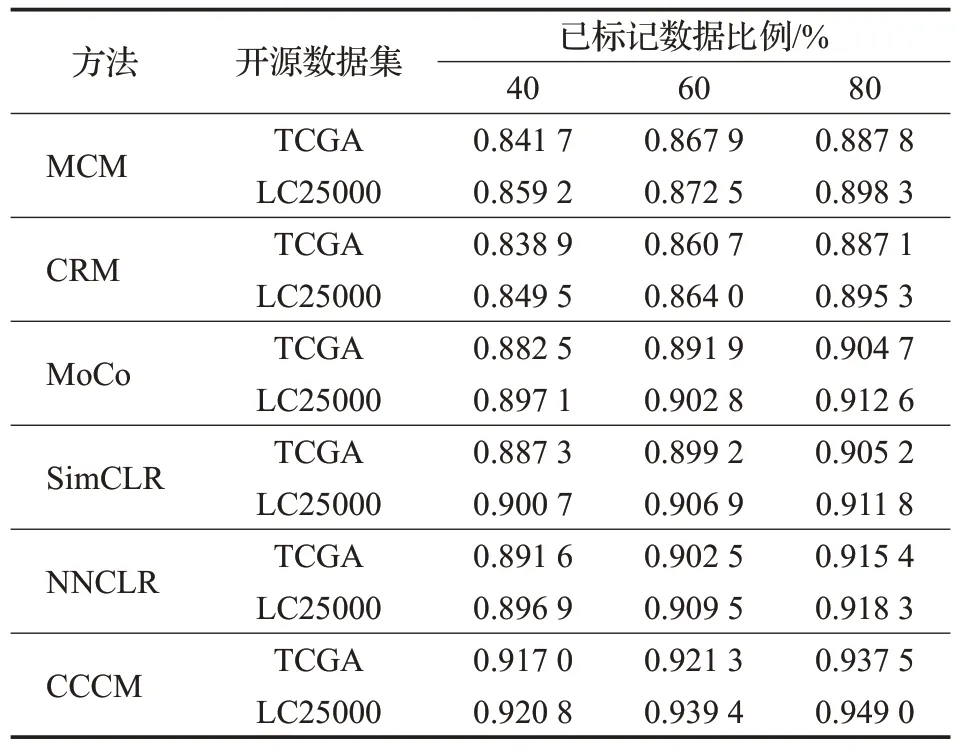
表5 开源数据集的召回率比较Table 5 Recall comparison of open source datasets
从表6 可以看出,在对两个开源数据集进行分类时,CCCM使用不同比例的训练数据得到的F1-Score值均高于其他分类方法,说明CCCM在精确率和召回率两个方面的综合表现较好。

表6 开源数据集的F1-Score比较Table 6 F1-Score comparison of open source datasets
此外,从表3~6 还可以看出,各分类方法对TCGA的分类表现低于对LC25000 的分类表现,这是因为与LC25000相比,TCGA包含的已标记数据和未标记数据的数量都比较少,导致可用于各分类方法的训练数据较少,造成对TCGA的分类效果低于对LC25000的分类效果。由于CCCM 能够利用少量的未标记数据中的细胞形态特征信息,使得其在TCGA 中具有较好的分类表现。当已标记训练数据分别为40%、60%和80%时,现有分类方法的四项评价指标值都发生一些变化,尤其是对于完全依赖已标记数据的分类方法MCM和CRM,其四项分类评价指标发生较大变化,说明现有分类方法对已标记数据的依赖程度较大,还没有将未标记数据中的信息有效地应用到分类过程中,而对同一开源数据集,在已标记训练数据变化且未标记数据的数量不变的情况下,CCCM 的四项分类评价指标的变化较小,说明增加已标记训练数据的数量对提高CCCM 的分类效果有一定的帮助,但是CCCM对已标记训练数据的依赖程度较小,利用一定数量的未标记数据,就能保持较好的分类效果。
在使用混合数据进行实验时,为说明不同比例已标记数据对分类方法的影响,实验分为三组:第一组将900张已标记肺癌病理图像中40%的已标记数据作为现有分类方法和CCCM第一阶段的已标记训练数据,即得到360 张已标记数据训练数据。将3 000 张未标记肺癌病理图像作为CCCM第二阶段的未标记训练数据,将900张已标记肺癌病理图像中剩余的已标记数据作为各分类方法的验证集,即得到540张已标记数据作为各分类方法的验证集。第二组将900 张已标记肺癌病理图像中60%的已标记数据作为现有分类方法和CCCM 第一阶段的已标记训练数据,即得到540张已标记数据作为训练数据,将3 000 张未标记肺癌病理图像作为CCCM第二阶段的未标记训练数据,将900张已标记肺癌病理图像中剩余的已标记数据作为各分类方法的验证集,即得到360 张已标记数据作为各分类方法的验证集。第三组将900 张已标记肺癌病理图像中80%的已标记数据作为现有分类方法和CCCM 第一阶段的已标记训练数据,即得到720 张已标记数据作为训练数据。将3 000 张未标记肺癌病理图像作为CCCM 第二阶段的未标记训练数据,将900张已标记肺癌病理图像中剩余的20%数据作为各分类方法的验证集,即得到180 张已标记数据作为各分类方法的验证集。
使用各分类方法对肺癌病理图像进行分类,得到三组实验的比较结果分别如图12~15 所示。从图中四项评价指标的比较可以看出MoCo、SimCLR、NNCLR 和CCCM 的分类效果优于MCM 和CRM,这是因为MCM和CRM的分类需要大量的已标记肺癌病理图像作为训练集,在缺少足够已标记数据作为训练集的情况下,MCM和CRM的分类效果不好,而在已标记肺癌病理图像较少的情况下,MoCo、SimCLR、NNCLR 和CCCM 能够获得较好的分类效果。由于NNCLR增加的对比学习的多样性,使得其分类效果优于MoCo 和SimCLR。与现有分类方法相比,CCCM 能够达到较好的分类效果,这是因为CCCM 的MDCM 和DDⅠM 提升了ResNet50的特征提取能力,在NNCLR 的基础上使用了更多的对比学习策略,进一步增加了对比学习中正样本学习难度和数据的多样性,从而提高了对比学习的性能。
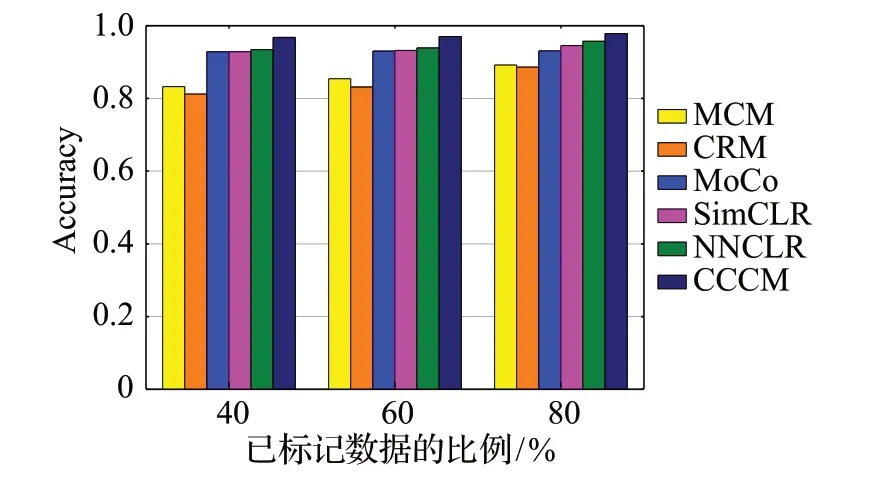
图12 准确率的比较Fig.12 Comparison of accuracy

图13 精确率的比较Fig.13 Comparison of precision
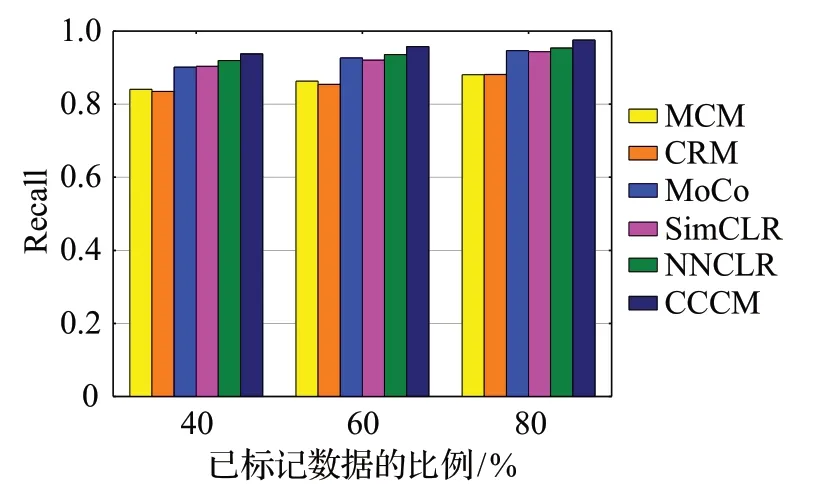
图14 召回率的比较Fig.14 Comparison of recall
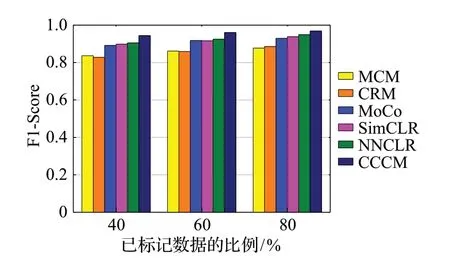
图15 F1-Score的比较Fig.15 Comparison of F1-Score
与图12~15相对应的各分类方法的详细比较信息如表7~10所示。从表7的比较可以看出,在增加数据多样性后,CCCM使用不同比例的训练数据得到的准确率依然高于其他分类方法,也说明CCCM能够从混合数据中能学习更多的细胞形态特征信息,尤其是未标记数据的细胞形态特征信息,使得其分类结果更接近实际的整体分类结果。
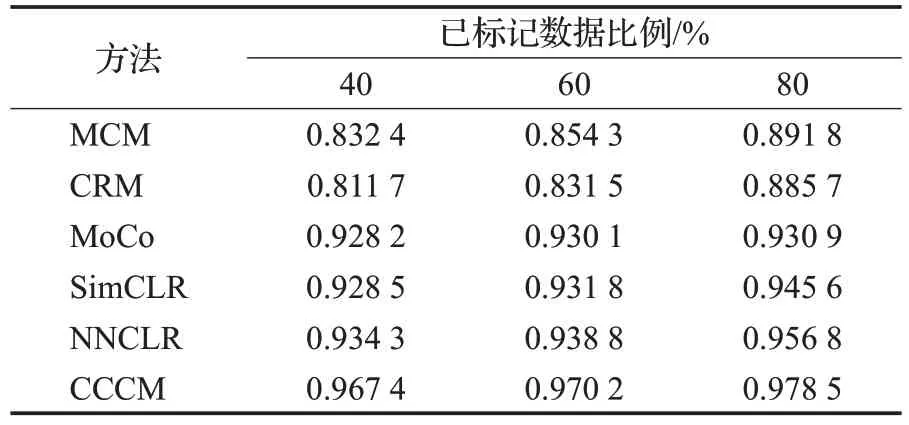
表7 混合数据的准确率比较Table 7 Accuracy comparison of hybrid data
从表8的比较可以看出,在增加数据多样性和未标记数据后,CCCM使用不同比例的训练数据得到的精确率依然高于其他分类方法,说明对多种来源的数据进行分类时,CCCM对阳性样本的分类准确程度较高。

表8 混合数据的精确率比较Table 8 Precision comparison of hybrid data
从表9的比较可以看出,在增加数据多样性和未标记数据后,CCCM使用不同比例的训练数据得到的召回率依然高于其他分类方法,说明对多种来源的数据进行分类时,CCCM对阳性样本的识别能力较好。

表9 混合数据的召回率比较Table 9 Recall comparison of hybrid data
从表10 的比较可以看出,在增加数据多样性和未标记数据后,CCCM 使用不同比例的训练数据得到的F1-Score值依然高于其他分类方法,说明对多种来源的数据进行分类时,CCCM在精确率和召回率两个方面的综合表现较好。

表10 混合数据的F1-Score比较Table 10 F1-Score comparison of hybrid data
此外,从表7~10 还可以看出,在增加数据多样性后,当已标记训练数据分别为40%、60%和80%时,现有分类方法的四项分类评价指标值依然会发生较为明显的变化,而与现有分类方法相比,CCCM 的四项分类评价指标的变化仍然较小,说明对多种来源的数据进行分类时,增加已标记训练数据的数量对提高CCCM的分类效果有一定的帮助,但是CCCM对已标记训练数据的依赖程度较小,其通过挖掘和利用大量未标记数据的细胞形态特征信息,始终能够保持较好的分类效果。
在实验用到的TCGA、LC25000和混合数据中,TCGA的未标记数据最少,混合数据的未标记数据最多。当已标记训练数据为80%时,CCCM在上述开源数据集和混合数据的实验对比结果如图16所示,通过图中四项评价指标的比较可以看出,随着未标记数据的增多,CCCM能够取得更好的分类效果,这是因为CCCM的分类性能主要依赖于未标记数据的数量,利用模型充分挖掘和利用未标记数据是提高CCCM分类效果的关键环节。

图16 不同数据集的实验比较Fig.16 Experimental comparison of different datasets
2.3.4 收敛性分析
为了对CCCM 的收敛性进行分析,将CCCM 与MCM、CRM、MoCo、SimCLR 和NNCLR 的训练过程进行比较。在实验中,采用在确定α值实验中使用的混合数据作为实验数据,将900 张已标记肺癌病理图像中80%的已标记数据作为现有分类方法和CCCM 第一阶段的已标记训练数据,即得到720张已标记数据作为训练数据。将3 000张未标记肺癌病理图像作为CCCM第二阶段的未标记训练数据,将900张已标记肺癌病理图像中剩余的20%数据作为各分类方法的验证集,即得到180张已标记数据作为各分类方法的验证集。各分类方法的比较结果如图17 所示,从图中可以看出,MCM 和CRM 的迭代次数明显多于基于对比学习的分类方法MoCo、SimCLR、NNCLR 和CCCM,而现有的对比学习分类方法MoCo、SimCLR和NNCLR的迭代次数都高于CCCM 的迭代次数,而且收敛后的损失值也都高于CCCM 的损失值。CCCM 在迭代次数达到320 次左右时,损失值达到最小,说明CCCM在收敛性方面的表现优于现有的分类方法。

图17 训练过程损失值的比较Fig.17 Comparison of loss value in training process
各分类方法每次迭代的时间比较如表11 所示,从表11的比较可以看出,与其他分类方法相比,CCCM每次迭代耗费的时间较多,这是因为CCCM通过较为复杂的模型结构挖掘未标记数据中的特征信息,虽然迭代次数较少,但是由于每次迭代的计算量较大,导致CCCM需要耗费更多的时间完成分类任务。

表11 各方法每次迭代的时间比较Table 9 Comparison of time per epoch of different methods
3 结束语
本文提出一种肺癌病理图像分类方法CCCM,该方法对未标记肺癌病理图像进行对比学习和分类,并将获得的高置信度分类图像作为伪标签,应用到对比学习训练中。在ResNet50 中,利用MDCM 和DDⅠM 获取更准确的肺癌细胞的形态特征信息。为充分利用数量有限的训练数据,将最远和最近邻图像加入到对比学习中,增加了对比学习的正样本学习难度和数据的多样性。实验结果表明,CCCM在分类性能和收敛性方面优于已有的分类方法。在后续的研究中,将进一步研究如何挖掘未标记肺癌病理图像的其他特征信息,并应用到肺癌病理图像分类方法中。由于肺癌病理图像的已标记数据较少,为了挖掘和利用未标记数据的细胞形态特征信息,构建的CCCM在整个模型结构方面较为复杂,导致该模型以增加计算量为代价,提高分类的性能,这是目前该模型中存在的不足。在后续的研究中还需要进一步改进该模型的结构,并压缩模型参数,减少模型的计算量。
