面向计算机课程教育数据挖掘与分析的认知诊断模型构建研究
2023-10-09吴强
吴 强
(安徽建筑大学 电子与信息工程学院,合肥 230088)
在素质教育理念不断深化的背景下,计算机课程的教学目标不仅要让学生掌握计算机系统的相关技术和应用,还要在此基础上实现学生真正意义上的计算机知识学习。[1]然而,就目前计算机课程的现状而言,由于传统教育观念的深刻影响,大多数学校仍然沿用传统的整课教学模式。[2-3]这就导致课堂气氛沉闷,很难调动学生参与的积极性,加上计算机是一门操作性很强的课程,仅仅依靠教师讲解理论知识,而不允许学生进行实际操作,学生很难真正掌握所学内容。[4-5]久而久之,学生就会对学习计算机课程失去热情,因此有必要对当前的计算机课程进行改革。而学生的文化背景可以通过影响学生的内隐状态对其学习状况产生直接的影响,对学生的教育背景进行数据挖掘,并且结合当前的计算机课程教育,可以了解影响学生在学习过程中的学习心态,并帮助教师及时调整教学方案。[6-7]另外,在现代课程不断发展、教育方法不断创新的背景下,认知诊断作为教育数据挖掘中的一项重要研究,在学生评价中发挥着举足轻重的作用。[8-10]因此,研究将教育背景特征引入学生在计算机课程学习中的认知状态诊断模型,提出了一种新颖的教育情境感知认知诊断(Educational context-aware Cognitive Diagnosis,ECD)框架,其中包含教育情境建模阶段和诊断增强阶段。
1 基于教育情境感知的认知诊断框架
1.1 基于教育情境感知的认知诊断问题定义与模型概述
教育情境是指与学生学习过程有关的各种特征,这些特征可能来自不同方面,例如父母的受教育程度、班级的学习风气等。以此为基础,研究探讨了教育情境感知的认知诊断问题的具体定义。
假设在一个学习系统中有N个学生,T个教育背景问题和M个练习,可以表示为S={s1,s2,…,sN} ,Q={q1,q2,…,qT} ,ε={e1,e2,…,eM} 。日志R由教育背景下的问题回应记录Rq和练习回应记录Re组成,被表示为三联体的集合(s,e,rq)和(s,e,re),其中s∈S,e∈ε,q∈Q,rq是学生s对教育背景问题q的回答,re是学生s对练习e的得分。那么这个问题可以正式定义为通过给出学生的日志R={Rq,Re} ,推断出学生的知识概念的熟练程度,并进行学生的表现预测。
ECD框架的整体架构由两个阶段组成:教育情境建模阶段和诊断增强阶段。一般来说,练习答题过程可以表述为式(1)。
式(1)中r指的是学生的反应,θ表示学生的知识熟练程度,θ表示练习参数e。F表示人工设计的认知行为函数,它对学生和练习参数之间的相互作用进行建模并输出反应。考虑到学生的教育背景,研究进一步将θ分为两部分,如式(2)。
在式(2)中,其中θcontent是受教育情境影响的学生外部特质,θinner是传统认知诊断关注的学生内在特质,G表示两个学生特质的影响函数。是学生的教育背景,H表示教育背景对学生外部特质的影响函数θcontent,研究中主要关注这个问题。
ECD 框架的整体架构由两个阶段组成:教育情境建模阶段和诊断增强阶段。在教育情境建模阶段,研究设计了注意网络来模拟教育情境对θcontent的影响。具体来说,研究首先将不同的教育情境分为几个领域,并分别用情境过滤层模拟个性化的影响。然后,研究在情境交互层中对不同领域之间的内在相关性进行建模。之后,情境聚合层捕捉领域层面的个性,并生成学生的外部特征θcontent。在诊断增强阶段,研究将θcontent和θinner相结合,然后用认知行为函数输出预测得分。用学生的日志进行训练后,可以得到每个学生的θ作为诊断结果。
1.2 基于教育情境的模型建立
在教育情境建模阶段,研究设计了注意网络来模拟教育情境对受教育背景影响的学生外在特质θcontext的影响,整个网络由四层组成:嵌入层、上下文过滤层、交互层和聚合层。
在嵌入层,该层用于为每个教育背景条目uj和每个学生st分配可训练的仿真标签。为每个上下文条目分配一个影响关键向量ck∈和一个影响值标量cv,分别表示该上下文条目的潜在特征及其影响强度。对于每个学生st,指定一个可训练的学生潜在特征向量xt∈捕捉st对不同语境条目的适应度。d1是手动设置的向量尺寸。值得注意的是,同一语境特征的不同语境条目不会出现在一个学生身上。因此,对于m不同的语境特征,每个学生最多有m语境条目。在语境过滤层,教育情境可能涉及不同方面的特征,导致不适合对其影响进行统一建模。因此,研究将教育背景条目U归入背景字段C={C1,C2,…,CU} ,根据其内容,其中Ci={Ci1,Ci2,…,Cimi} 。一般来说,一个上下文字段Ci包含上下文特征mi的条目。在此基础上,考虑到对每个学生进行个性化的情境影响,研究利用注意力机制来获得不同情境条目的权重。图1显示了以注意力为基础的过滤方法在每个情境领域的应用。
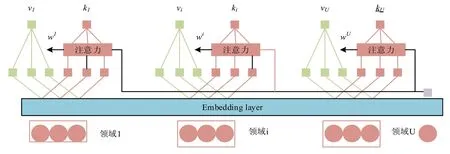
图1 以注意力为基础的过滤方法
研究首先计算了学生特征xt和情境影响关键向量之间的余弦相似度,计算方式如式(1)。
在式(1)中,sim表示余弦相似度函数,wi中的权重反映了学生在不同情境条目上的适应性。最后,每个教育情境领域的影响是由该领域不同特征的加权和产生的,计算方式如式(2)。
在式(2)中,是中的第j个权重。影响强度vi是在考虑不同领域之间的相关性之前,来自情境领域Ci对学生st的总体影响强度。影响力类型ki描述的是Ci的个性化潜在特征。而在语境互动层,为了模拟不同教育情境领域之间的内在关联性,研究在交互层中引入了一个自我关注模块。如图2所示,在情境过滤层之后,可以得到教育情境场Ci的影响类型ki和强度vi,这两者都是由公式(2)个性化的。通过对ki的自我关注机制和对vi的权重wi进行共享,可以模拟出教育情境领域之间的个性化的内在关联性。
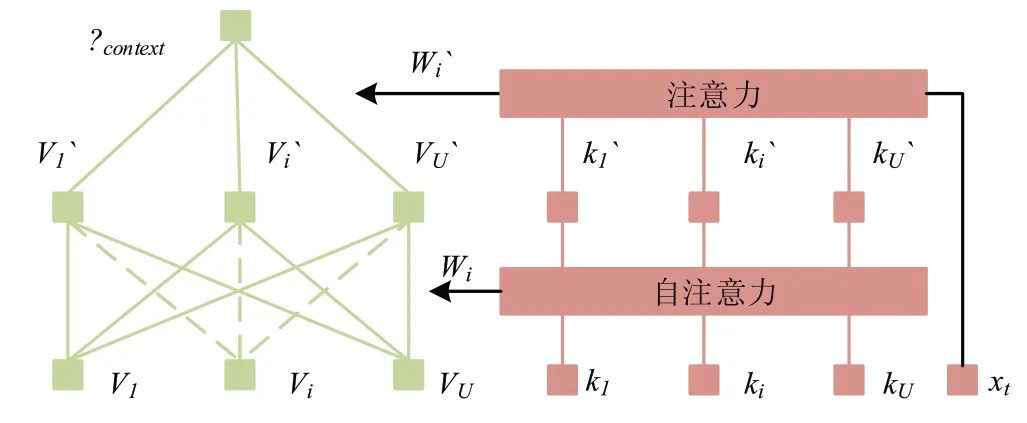
图2 上下文交互和聚合层
因此式(1)可以改写为式(3)。
在式(3)中,k=(k1,k2,…kU)。而影响类型ki的模拟结果为k'i。在聚合层中,学生的潜在向量xt被用来计算k'i之间的相似性,以确保上下文领域的个性,同样通过计算余弦相似度来进行。另外,学生的外部特质θcontext是对学生认知状态的全局性和不可察觉的影响,而从学生练习记录中推断出的学生内在特质θinner是学生能力或知识熟练程度的局部反映,因此,研究中需要综合考虑这两个因素。θcontext的计算方式如式(4)。
1.3 认知诊断增强与模型学习
在诊断增强阶段,研究结合学生外在特质θcontext和学生内在特质θinner然后用认知行为函数输出预测分数。用学生的日志R训练后,可以得到每个学生的θ作为诊断结果。具体来说,研究首先用学生的潜质向量来表示内在特质θinner。然后,选择一种自适应优化的个性化加权方法,将学生的外部特征和内部特征汇总为学生的最终状态θ,计算方式如式(5)。
在式(5)中,dt是对每个学生st个性化的可训练权重,θ是学生的最终知识水平。对学生在练习中的反应的预测可以表述为式(6)。
在式(6)中,CDMethod表示现有的认知诊断模型,φe表示采用的传统认知诊断模型中与运动有关的参数(如运动难度b)。在模型学习过程中,研究在上下文建模中训练参数,权重变量dt和现有方法中的参数φe和θinner。研究应用多重学习方法来处理。具体来说,与二分类任务中的常见方法一样,研究中使用交叉熵作为损失函数,如式(7)。
在式(7)中,r是模型的预测值,label是学生对练习的反应的基本事实。为了使所有的参数得到良好的训练,研究调整损失函数如式(8)。
在式(8)中,rc表示只用来自教育背景的学生外部特质进行预测,rexist表示只用现有方法进行预测。α、β是权衡这三种损失的超参数,loss'是最终损失函数。
2 模型性能仿真分析
2.1 模型性能测试
研究使用PISA 2015数据集对所提出模型进行训练和测试。研究主要选取了亚洲、欧洲、美洲三个地区的数据,每个数据集中有300个与不同教育背景特征相关的不同问题,并分别得到学生对总共260个科学认知练习的回答记录。最终,数据集中有80%用于训练,另外20%用于测试。
为了验证ECD模型情境过滤层的有效性,实验分析了教育情境特征的关注权重和学生的成绩之间的关系。图3中展示了来自教育情境领域“ESCS”家庭的十个不同学生的情境特征的例子。可以看出,前5名学生(编号0-4)的平均得分较低,而后5名学生(编号5-9)的成绩较高。具体来说,“书籍”指的是“你家里有多少书?”这个问题,数字越大表示书越多。显然,学生的答案和他们的表现之间存在着关联,即更多的书对学生的表现有更积极的影响。如图3所示,低分段的学生对消极答案(如1、2)的关注度较高,而积极答案(如4、5、6)在高分段的学生中比重较大。此外,值得注意的是,对于一些高分的学生(8-9分)来说,书并不总是很多。在这种情况下,其他一些特征,如“电视”和“乐器”,可能会对学生产生积极的影响,与图3样本性质相似。这说明情境过滤层的关注机制可以合理地模拟不同特征对学生的个性化影响。
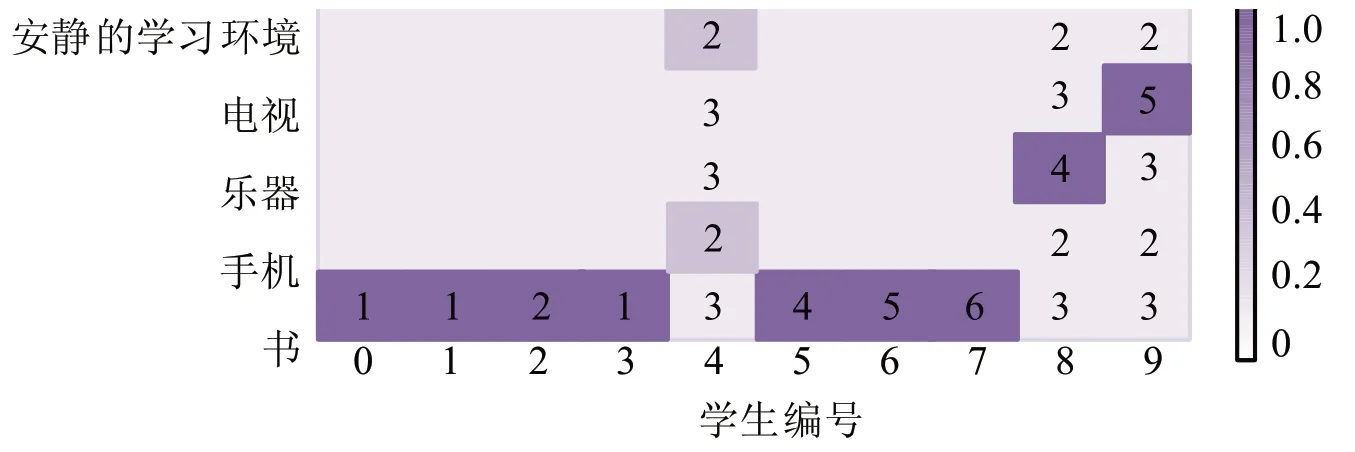
图3 情景特征案例
为了说明ECD框架的有效性,研究将各地区的平均诊断结果与PISA报告进行了比较。具体来说,在PISA报告中,学生的科学素养被评估为区域层面的分数。研究以来自不同大陆的四个代表性地区为例,即新加坡、日本、美国和法国,它们的分数分别为54、53、49、49,在每个地区,首先计算出平均知识熟练度,然后,把在所有知识概念中的分布情况直观地显示在图4中。可以发现,各地区的顺序与PISA的报告一致。

图4 各地区科学素养评分诊断结果对比
图5 为三种学习成效评估方法对比。其中,第一种学生成绩评价方式为百分制的学生知识掌握程度均值,第二种学生成绩评价方式为ECD模型,第三种学生成绩评价方式为评价分数的加权平均分。可以看出,以学生知识点掌握程度为基础得到的最终成绩与学生的期末测验得分有相似的波动趋势,图中两曲线的相关系数为0.77,说明使用数据集进行参数训练后对学生真实作答得分的拟合度高,能反映学生真实的知识状态。此外,ECD模型作为基准的评估方法与学生诊断结果的相关系数为0.83,以期末测验为基础的评估方法与总分的相关系数为0.71。可见ECD模型可以很好地评价学生的学习情况。
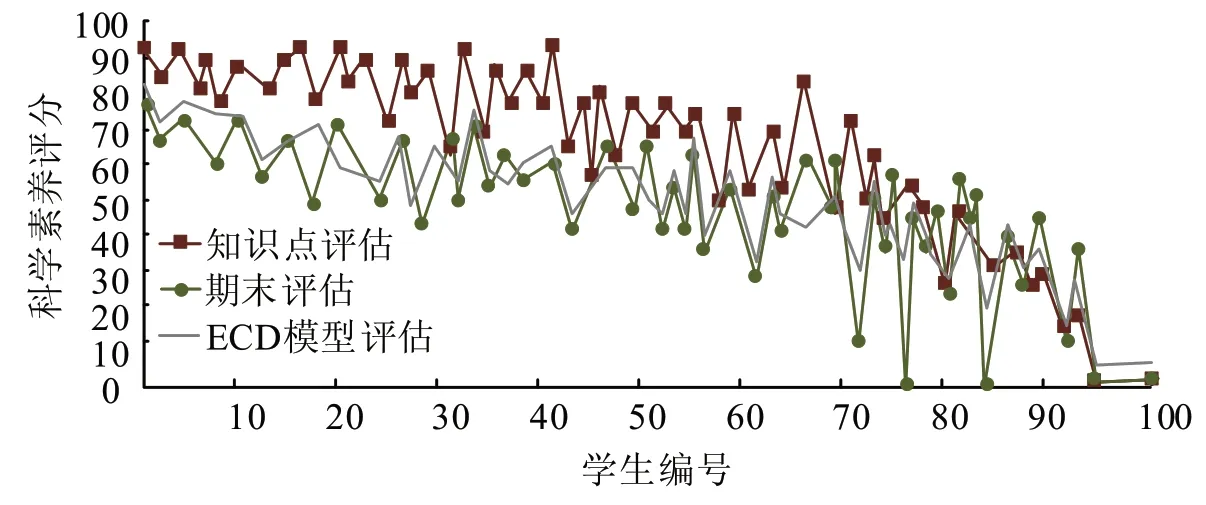
图5 学习成效评估方法对比
2.2 模型对比测试
在对比分析环节,研究使用了DeepFM以及NFM(Neural Factorization Machines)作为对比方法。
学生成绩预测的总体表现如表1所示。可以看出研究提出的ECD框架在三个数据集上的表现优于Deep-FM或NFM方法对所有认知诊断方法的表现。这说明该方法可以更有效地对教育背景进行建模。在三个数据集中,ECD方法对所有的认知诊断方法都有稳定的巨大改善,从AUC分值来看,ECD-NeuralCD的该项分值为0.744,高于其他方法,其他评价指标的分值显示了同样的结果。而DeepFM和NFM方法的表现则不稳定。因此,考虑到所有特征的情境建模有助于发挥ECD的优势。
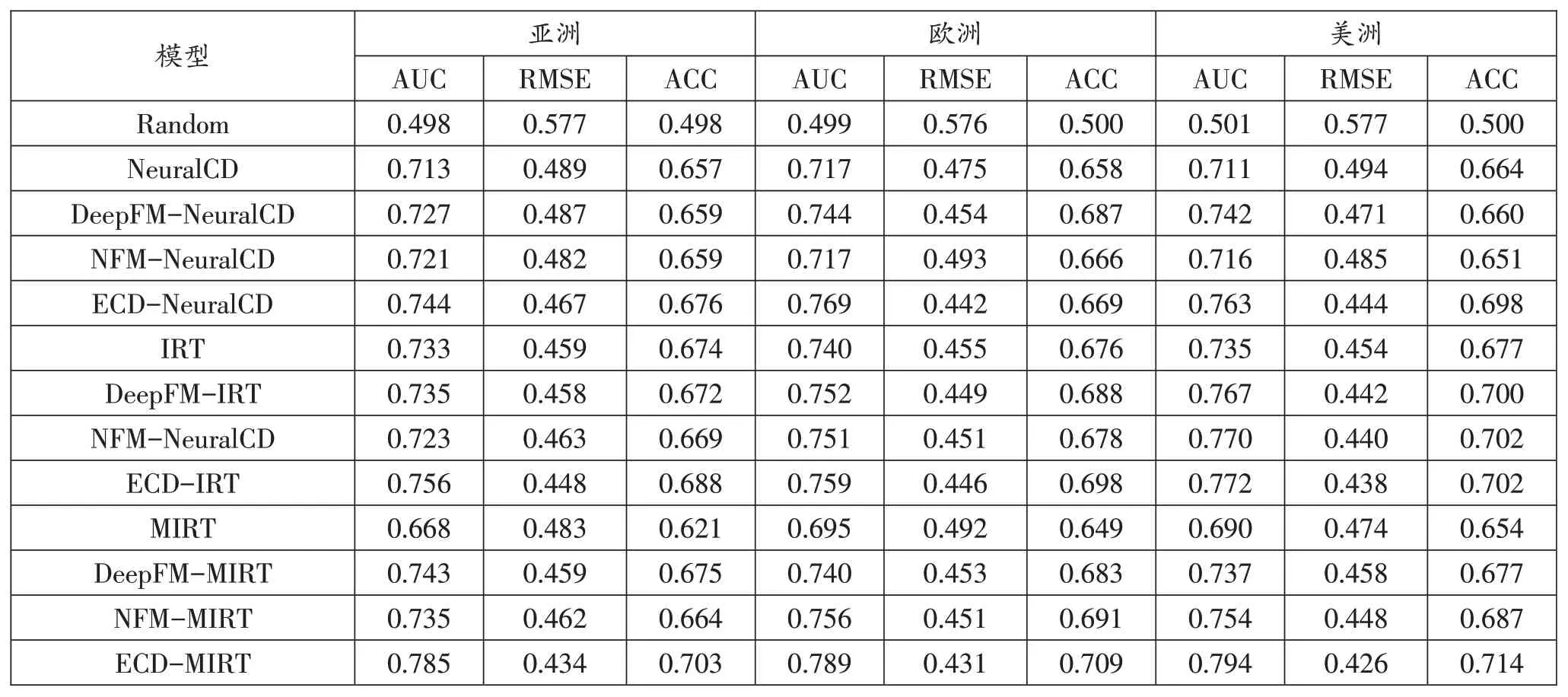
表1 学生成绩预测的总体表现
为了验证ECD 框架中所有三层的有效性,研究进行了消融实验,表2 展示了每种情况的结果,以ECDNeuralCD 的交互层为例,当交互层被替换,其AUC 的评分由0.744 降为0.735,而聚合层被替换该分值降为0.737。可以看出,无论哪一层被替换,最终的性能都有一定程度的下降。这表明每一层都对最终表现做出了贡献,即建模的个性化影响和内在的相关性。而当情境聚合层被替换时,最终的性能受到了极大的损害,这表明在情境领域层面的个性化在教育情境建模中起着非常重要的作用。
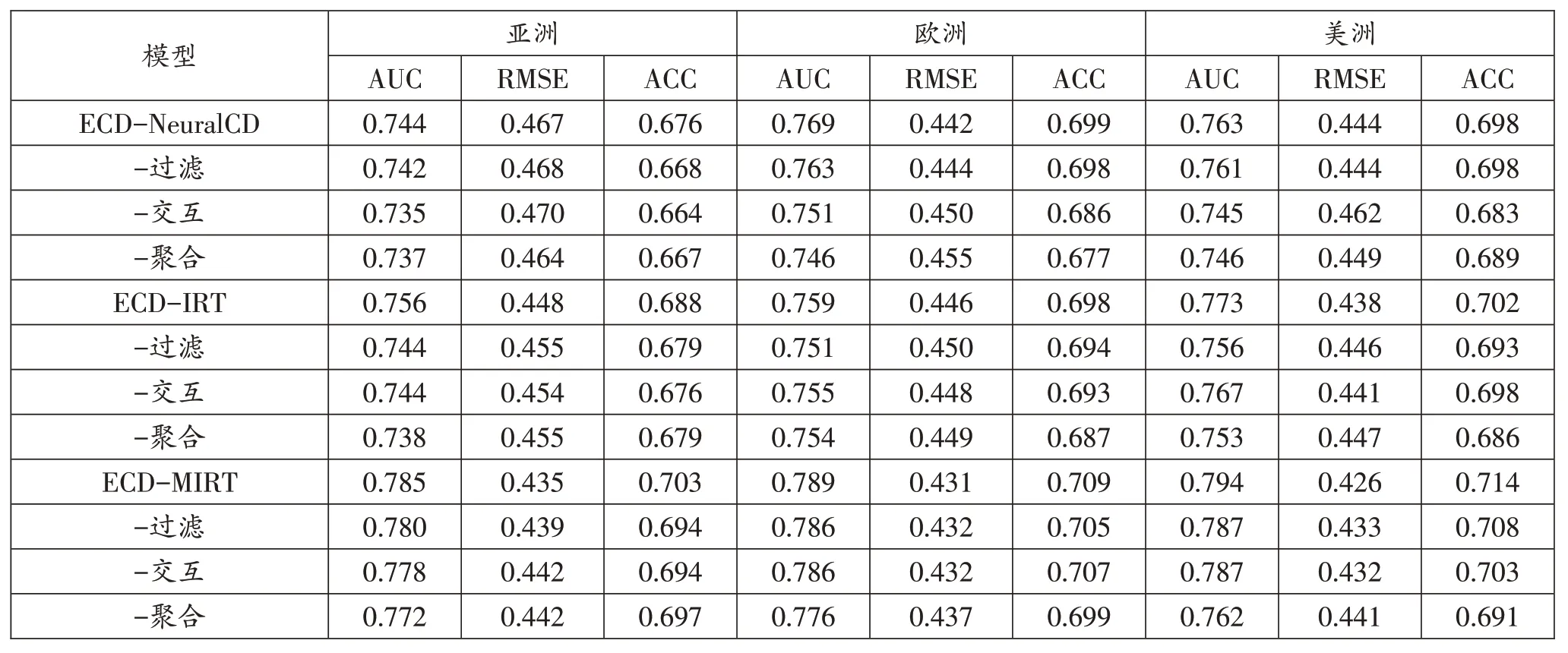
表2 学生成绩预测的总体表现
3 结论
情境和文化通过影响学生的内隐认知状态直接影响学生的学习。因此研究对情境意识特征进行建模,并使其适应于更精确地诊断学生的知识熟练度。研究首先设计了一个两阶段的解决方案,用一个层次化的entive 网络来模拟教育背景的影响,并对学生的特征进行自适应优化。然后,在该框架下用不同的现有方法实现了三个具体模型,即ECD-IRT、ECD-MIRT、ECD-NeuralCD。此外,研究在数据集上进行了大量的实验,证明了ECD 框架的有效性和可解释性。结果显示经模型计算的学生平均知识熟练度与数据集中的报告一致,且ECD模型作为基准的评估方法与学生诊断结果的相关系数为0.83。另外,ECD方法对所有的认知诊断方法都有稳定的巨大改善,从AUC 分值来看,ECD-NeuralCD 的该项分值为0.744,高于其他方法。但是模型还缺乏真实场景的应用结果分析,而现实中的教育情境更为复杂,因此研究还应该在广泛的真实场景测试后进一步对模型进行优化。
