基于集成学习的PE恶意代码静态特征检测研究
2023-10-09李佟鸿
李佟鸿,冷 静
(湖北警官学院,武汉 430032)
1 引言
随着网络技术的飞速发展,恶意代码在各种各样的恶意意图中急剧增长。根据AV-TEST发布的最新报告,每天都会监测到超过45万个新的恶意代码,截至2023年5月,累计捕获12.55亿恶意样本。[1]应对快速增长的恶意代码的数量、复杂性和可变性要求,研究和开发新的智能化、自动化的恶意代码检测方法,已成为网络安全行业的研究热点。目前较为流行的方法是从文件中提取相应特征,如字节序列、API调用、操作码序列和硬件事件等,使用机器学习技术来检测恶意代码。利用可移植的可执行文件头(Portable Executable header,PE Header)提取特征,并用机器学习的方法来研究恶意代码,是该领域一种广泛采用的方法。恶意代码和正常程序的目的不同,导致它们的PE文件格式存在结构性差异,这种差异表现出包含不同的特征,可用于区分恶意代码和良性程序。本文对PE文件提取文件头信息,使用可视化方法分析恶意代码和良性程序突出特征的差异,设计了一个基于stacking结合策略的机器学习检测模型,获得了较高的恶意代码检测率,以期实现一个有效的、低成本的恶意代码识别途径。
2 相关研究
研究人员通过提取PE恶意代码的静态和动态特征,使用机器学习方法研究PE文件进行恶意代码的分类和检验,是目前网络安全领域非常热门的研究热点,并取得了大量的研究成果。Rezaei T(2020)提出了一个基于PE 头信息的混合机器学习和基于签名的技术来检测恶意代码的研究方法,总体准确率达到99.70%以上;[2]他随后的研究(2021)又提出了一种新的深度学习方法,[3]利用了PE文件头的原始字节,在深度神经网络训练过程中使用聚类算法,学习恶意代码和良性程序的不同嵌入表示,该方法具有速度快、计算开销低等突出特点。Raff 等人使用PE 头字节来检测恶意代码,从报头的原始字节中提取特征来训练多个机器学习模型,检测效果非常好。[4]Manavi 等人研究勒索软件的检测,使用可执行文件头创建一个图,然后使用“幂迭代”方法,将该图映射到特征空间中使用模型分析,获得了较高的检测率。[5]Kim 等人提出了一种使用机器学习算法的基于PE 头的恶意代码检测技术,准确率达到99%。[6]Darshan 等人使用一个PE 文件混合特征集来训练多个机器学习模型来检测恶意代码。[7]Azeez 等人提出了一种基于Stacking 集成学习(一维卷积神经网络+机器学习)的恶意代码检测方法,在Windows 可移植可执行(PE)恶意代码数据集上进行实验,取得了良好的检测效果。[8]
国内使用PE文件特征集检测恶意代码,研究起步较早,也取得很多突出的成果,如樊震等提出了一种基于静态文件和PE文件结构的未知病毒检测方法。[9]该方法具有较高的检测率和较低的误检率。徐国天等提出一种基于XGBoost与Stacking融合模型,通过获取目标恶意代码对外通信流量自动化生成高级特征集,实现恶意代码多分类检测方法。[10]贾立鹏提出一种基于PE文件多特征融合的恶意代码分类方法,利用恶意代码的多种特征和集成学习思想实现对恶意代码家族的分类。[11]韩科研究了CNN在PE恶意代码检测中的应用,并尝试分析对加壳程序的检测效果。[12]
2.1 PE文件格式及恶意代码检测应用
PE文件格式是一种通用对象文件格式(COFF),是一种数据结构,封装了Windows OS loader 包装好的可执行代码所需的信息。PE文件的格式信息如图1所示。[13]
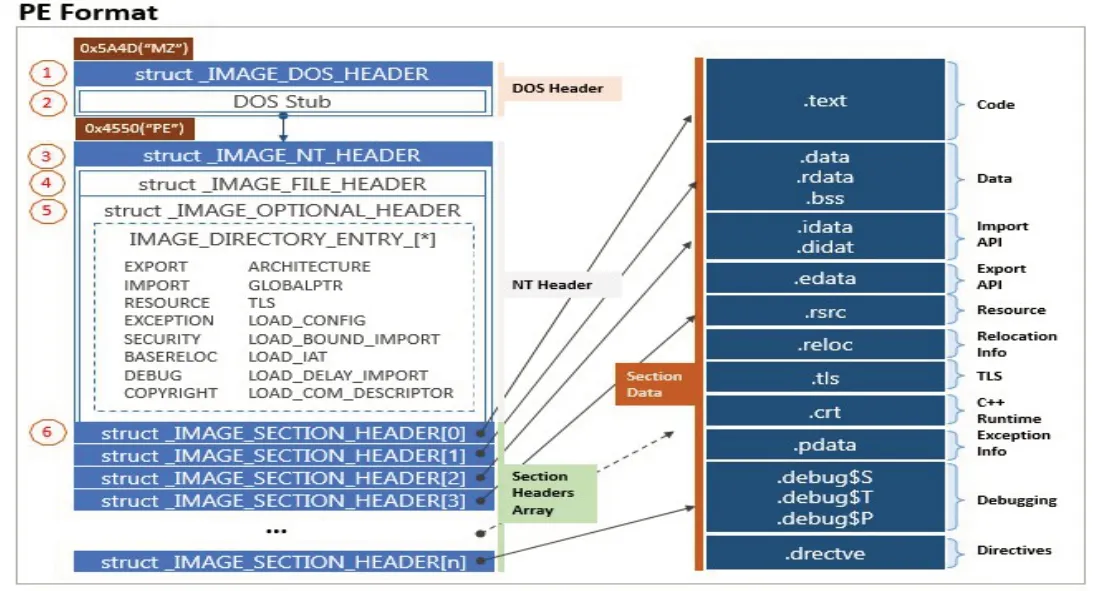
图1 PE文件格式
PE文件由一个PE文件头和一个节表(节头)组成,后跟节的数据。PE文件头由MS DOS头、PE签名、NT映像头和可选头组成。PE文件中有许多冗余字段和空格,为恶意代码的传播和隐藏创造了机会。这也使得恶意代码和良性软件的格式信息表现出许多差异。虽然格式信息不是很先进,但研究这些格式信息的差异是检测已知和未知恶意代码的一种可行、有效方法。如Size Of D-ebugData是调试信息的大小,恶意代码为了防止调试而保留的调试数据较少,恶意代码的调试数据明显少于良性软件;Number Of Sections 指节表的大小,此功能在恶意代码和非恶意代码文件中都不同;Number Of Symbols 表示符号表中的条目数,良性软件将符号信息保留在符号表中,恶意代码中的符号数量远远大于良性软件中的符号数量。恶意可执行文件在资源部分的条目(如消息表、组图标和版本)少于良性软件中的条目。95%的良性软件有版本信息,但只有40.8%的恶意代码有版本信息。90%的情况下,当文件的校验和Major Image Version 和DLL Characteristics 等于零时,会发现该文件是恶意的。
我们选择了一些重要特征,通过绘制直方图和核密度估计图,进行可视化比对分析,用直观的方式展示了这些特征在恶意和良性PE文件有明显的不同,如图2所示。
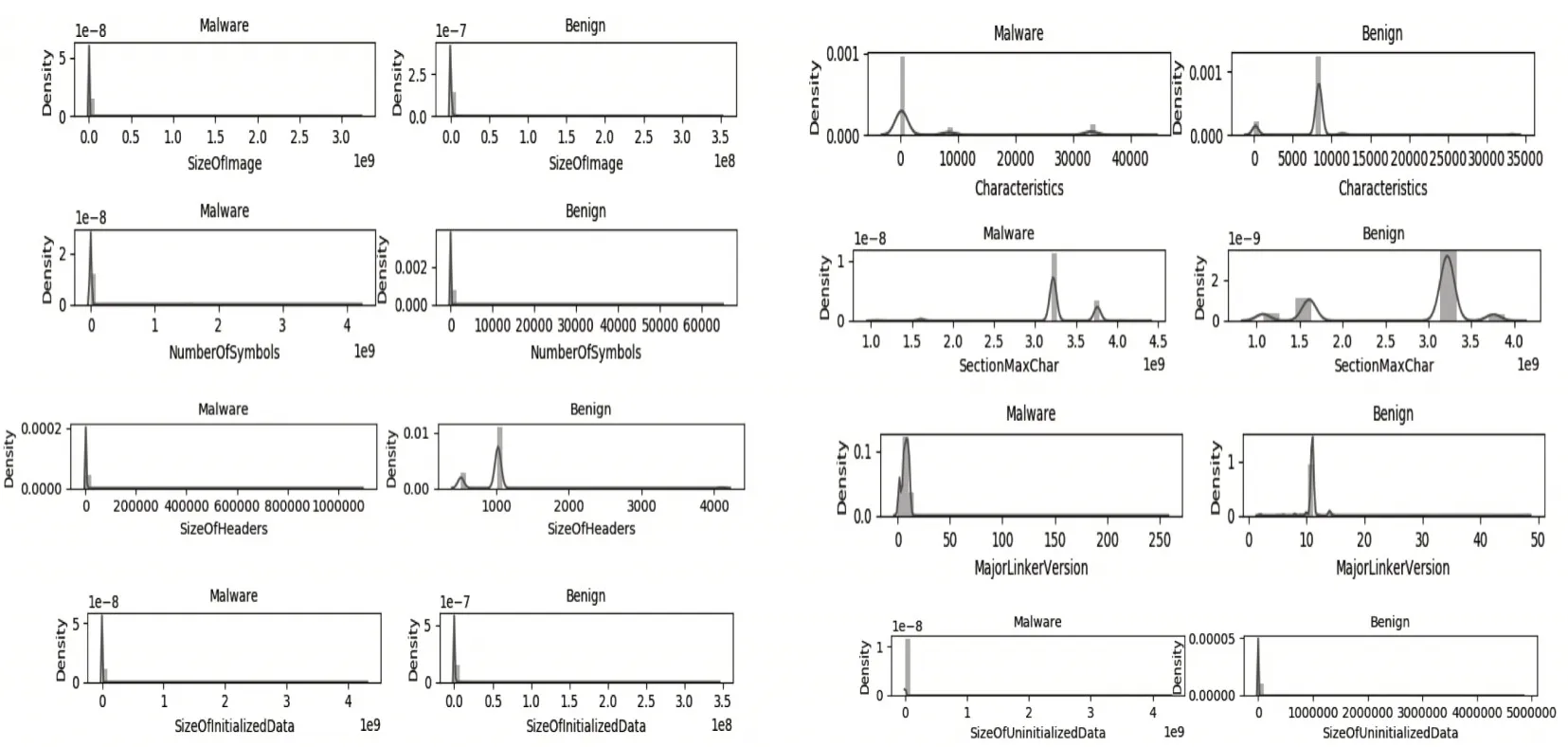
图2 特征的可视化分析
2.2 机器学习用于恶意代码检测
机器学习(Machine Learning,ML)在计算机安全领域有着非常广泛的应用,比如恶意URL检测、入侵检测和恶意代码检测。ML 成为当前恶意代码分类和聚类中的主要技术之一。使用各种工具IDA Pro、Lida、Peview、PeStudio分析恶意代码样本,并提取动态或静态特征,用于使用传统算法或机器学习算法训练恶意代码检测器,如图3所示,展示了使用静态特征分析开发基于特征码的恶意代码分类器的所有可能方法。它涵盖了设计恶意代码检测器的各种工具、静态特性和方法。
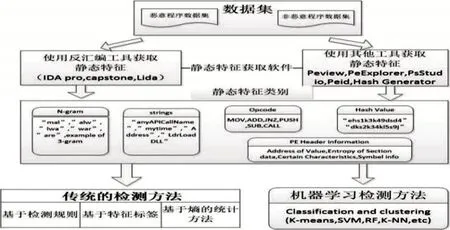
图3 恶意代码静态分析方法
3 应用的理论和算法
3.1 集成学习分类模型
本文采用的ML算法通过考虑恶意代码和良性样本的更多特征,为开发更精确的模型提供了更多选择和空间。如图4所示,使用机器学习算法的恶意代码检测系统示意图,展示了机器学习分类器的基本架构。首先提取特征,再进行特征选择和分析,最后应用集成学习分类模型对恶意代码分类器进行训练。

图4 恶意代码检测基本架构
在有监督的机器学习分类或回归任务中,往往希望通过学习模型得到准确且稳定的学习结果。然而,由于训练样本的质量、学习模型的复杂度等问题,可能存在稳定性不高或效果不理想等问题,研究人员往往采用集成学习的方法解决这些问题。集成学习指的是将多个基础学习模型按照集成策略组合在一起共同完成学习任务,[14]与仅使用单一学习模型相比,集成模型可以取得更好、更稳定的学习效果。集成学习的结合策略主要有Boosting、Bagging 和Stacking等三种架构。[15]
本文使用的ML 算法如GBDT(Gradient Boosting Decision Tree)就是采取Boosting 结合策略,随机森林(Random Forest,RF)算法采取的是Bagging 结合策略,都取得了较好的分类效果。根据Stacking 结合策略原理,我们设计了一个两层的Stacking Classifier 学习模型组,如图5 所示,第一层由RandomForest 和Gradient-Boosting对数据集进行初始训练和测试,第二层采用DecisionTree作为Meta-Model,对第一层生成的数据进行训练和测试,生成最终检测结果。该设计模型能够取得较好的检测效果。
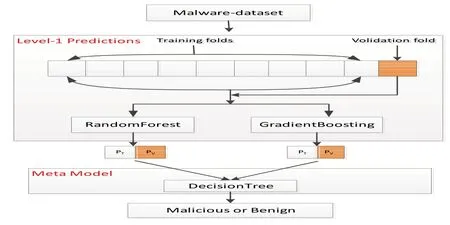
图5 Stacking分类模型
3.2 GBDT算法
在本文采用的机器学习算法中,GBDT是一个重要的取得良好检测效果的算法模型,这里我们重点讨论该算法的基本理论。GBDT是一种迭代的决策树算法,由多棵决策树组成,所有树的结论累加起来作为最终答案。该算法是在BDT(Boosting Decision Tree,提升决策树)的基础上改进得到的,BDT是一种以CART决策树为基础学习模型的集成学习方法,算法原理如图6所示。
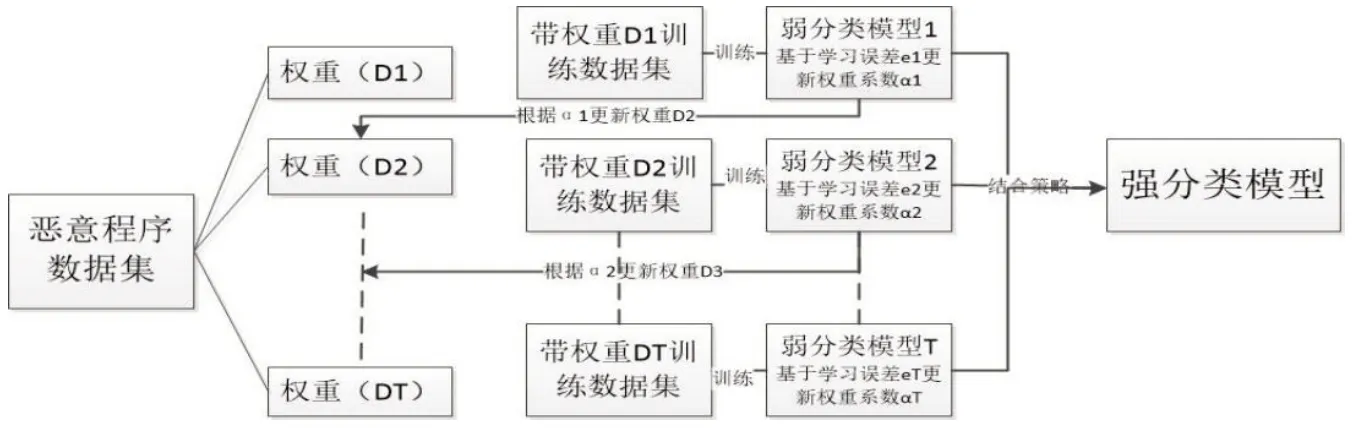
图6 BDT算法原理
GDBT算法流程如下所示:
Input:训练数据集T={(x1,y1) ,(x2,y2),…(xm,ym)};Loss函数L(Y,f(X))
(1)初始化(最大迭代次数为N,c的均值可以设置为样本y的均值)
(2)for t=1 to N:do
(3)得到强学习器f(x)表达式
4 实验分析
4.1 实验环境
所有实验均在以下规格的系统上进行:Intel(R)Core(TM)i7-8570CPU@3.10GHz,8GB 内存,操作系统为ubuntu18.04,该实验使用python V3.6和Tensorflow V1.13.1实现。PE头字节是使用python一个第三方库pefile作为工具来提取,提取方法的实现是公开的。
4.2 数据集
本文使用的数据集是从Kaggle获取。[16]属于PE文件的良性和恶意样本有19611个,如图7所示。数据集最初有77个特征,包括PE header中DOS_HEADER、NT_HEADER、FILE_HEADER和OPTIONAL_HEADER 中的全部字段。去除不重要的特征可以确保算法的最佳性能,如避免数据拟合过度或拟合不足,并提高运算速度。本文采用主成分分析(PCA)进行特征降维,选择了55个特征(代表95%的可变性)传递到机器学习模型中,因为这些特征被证明与被检测文件是恶意还是良性相关。
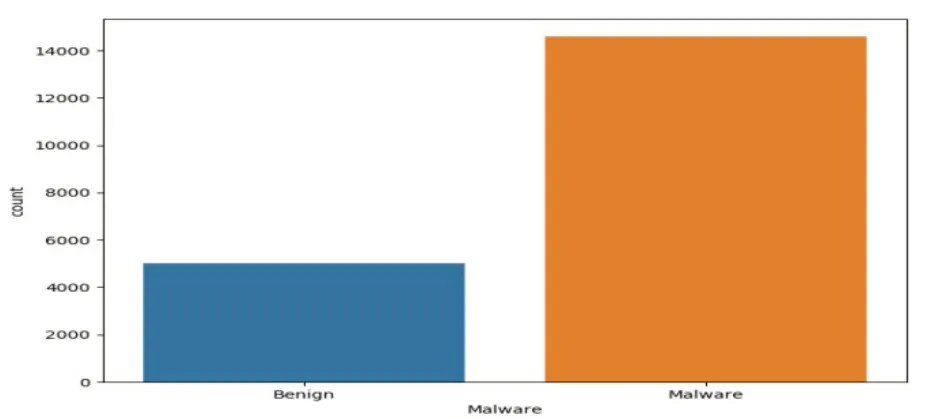
图7 数据集样本分布
4.3 实验仿真分析
(1)实验评价指标
为了对实验效果进行评估,本文使用准确率(Accuracy)、查准率(Presision)、查全率(Recall)、F1-score 作为实验的评价指标。计算过程如公式所示其中,TP是实际为正预测为正,TN是实际为正预测为负,FP是实际为负预测为正,FN是实际为负预测为负。
另一个评价方法是ROC曲线下的面积AUC(Area Under Curve),是二分类器的评价指标,它主要反映的是一个分类器的排序能力。对于给定一个正例和一个负例,它的值代表了将给定正例排在给定负例前面的概率。它的计算方式是通过TPR(True Positive Rate)、FPR(False Positive Rate)来分别作为横纵坐标画出曲线,再计算曲线下面积。
(2)实验结果分析
在本次实验中,主要检验基于上述设计的Stacking集成学习模型的分类效果。作为实验比对的机器学习算法主要有高斯朴素贝叶斯(Gaussian Naive Bayes)、多项式朴素贝叶斯(Multinomial Naive Bayes)、伯努利分布朴素贝叶斯(Bernoulli Naive Bayes)、决策树(Decision Tree)、随机森林(Random Forest)、Gradient Boosting(简称为GBDT)等基础算法模型。实验结果如表1所示。
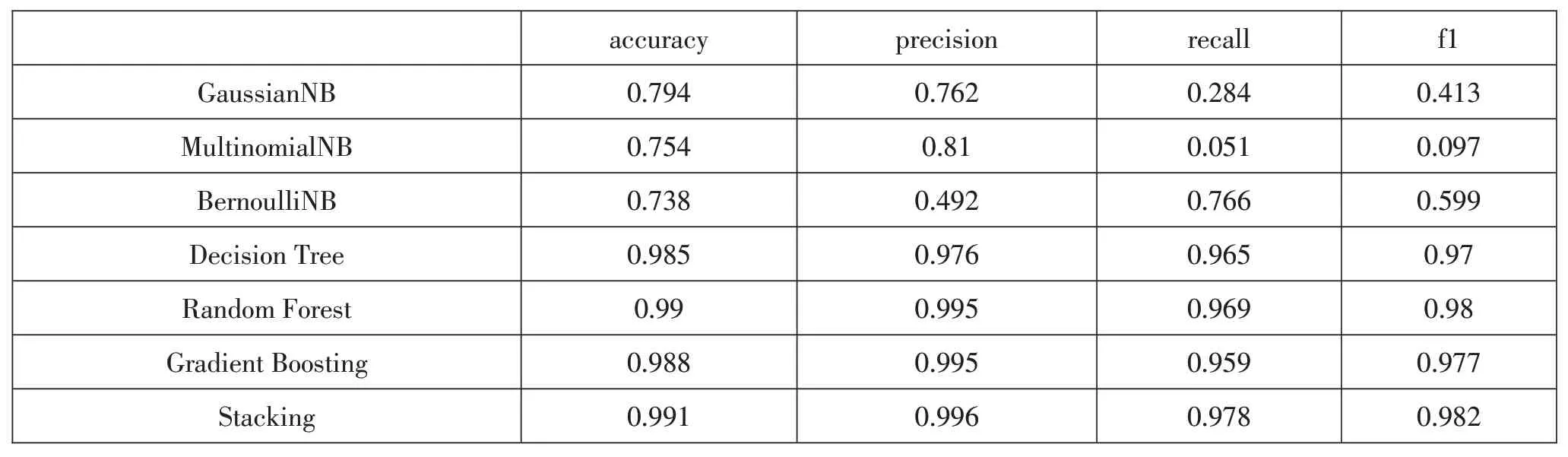
表1 集成学习模型实验结果
在实验中,Decision Tree、Random Forest、Gradient Boosting都取得较好的分类效果,Stacking分类模型取得的分类效果最好,准确率达到了99.1%。
各分类模型的学习曲线如图8所示。
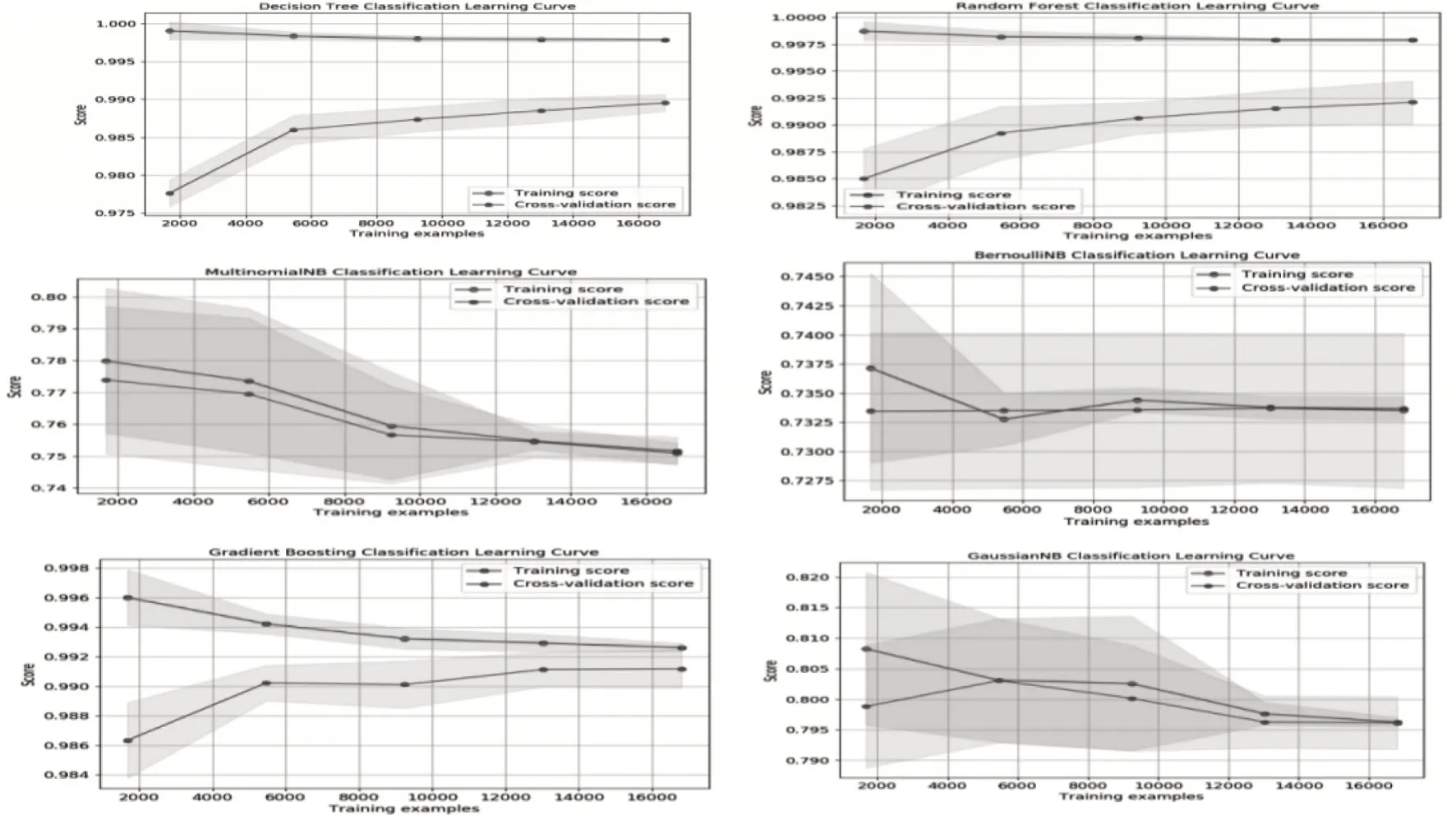
图8 基础算法学习曲线
Stacking分类模型的学习曲线和ROC曲线如图9所示。
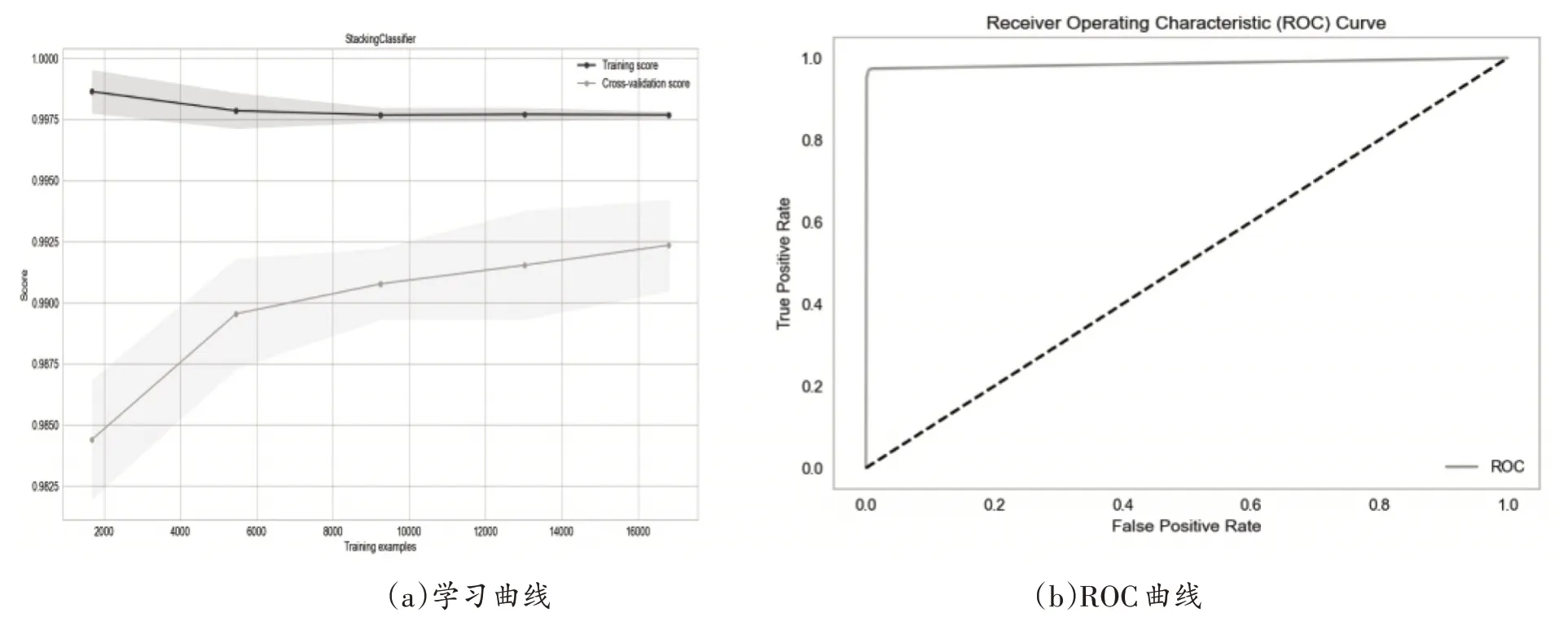
图9 Stacking分类模型学习曲线与ROC曲线
各算法模型分类效果综合对比如图10所示。
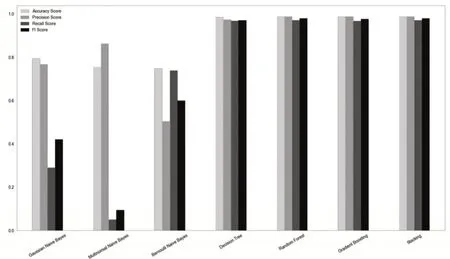
图10 算法模型分类效果对比
(3)对比验证
对于本次实验,我们又使用了一个更大的PE文件数据集来进一步检验该模型的分类效果。该数据集有138148个样本,这些样本来自各种恶意代码存储库,包括96724个恶意样本和41424个良性样本。
获得的实验结果如下。一是MultinomialNB、BermoulliNB 等算法欠拟合情况得到明显改善,实验准确度有所提高。如图11所示。
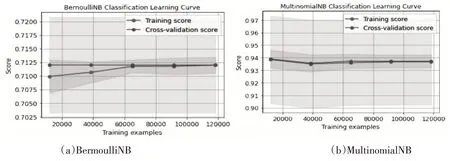
图11 MultinomialNB和BermoulliNB学习曲线
二是Decision Tree、Gradient Boosting等依然保持较好的实验效果,如图12所示。
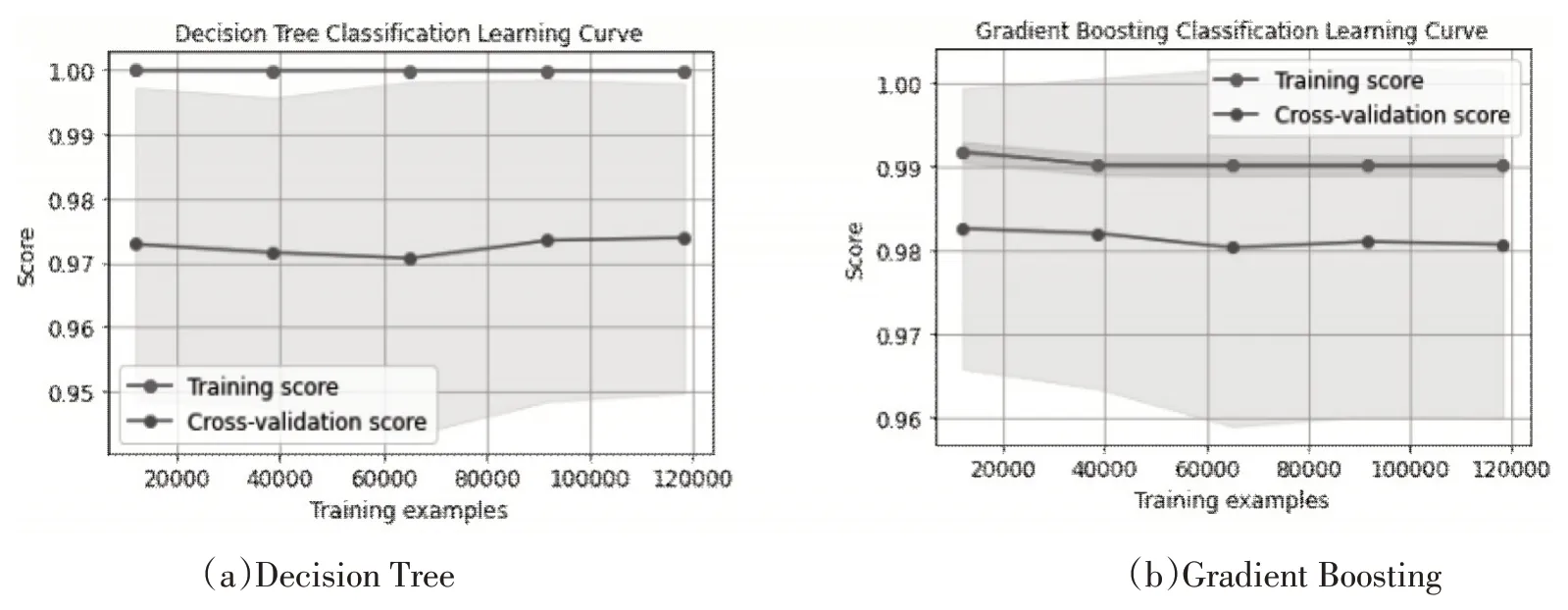
图12 决策树和GDBT学习曲线
三是Stacking模型效果。所设计的堆叠算法(Stacking)分类模型,ROC曲线下的面积几乎接近于1,学习曲线依然能够保持很好的分类效果。如图13所示。
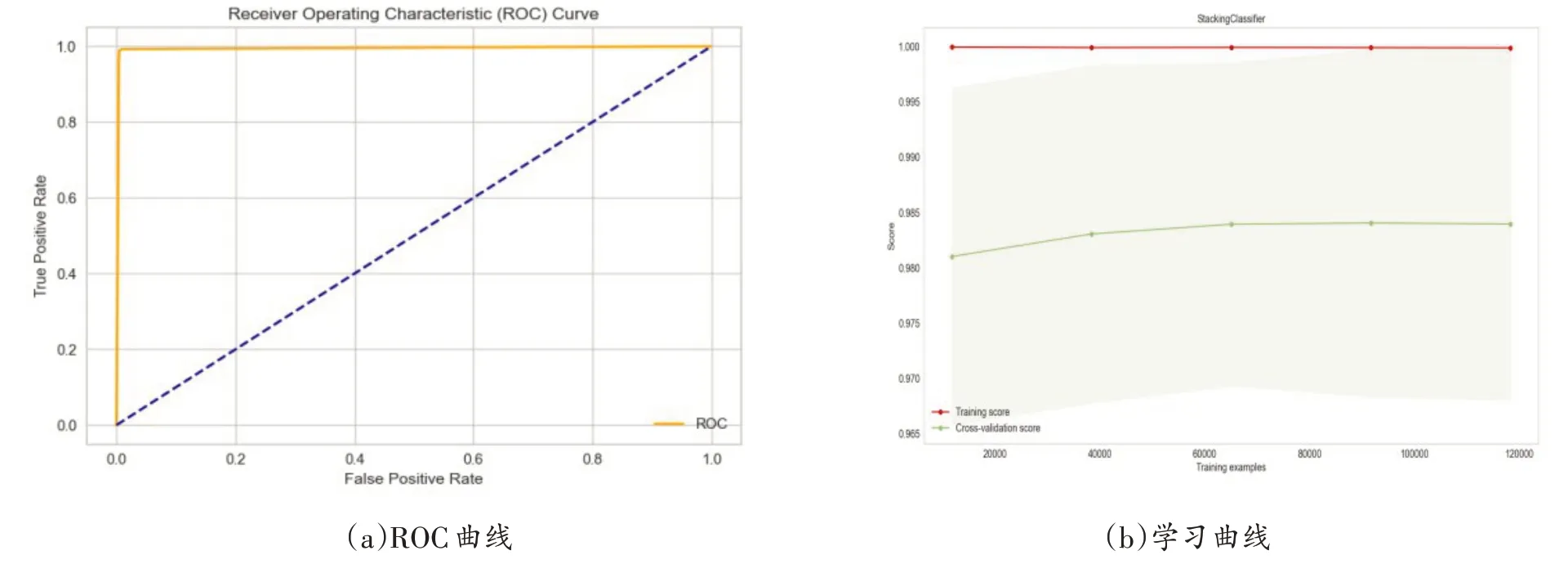
图13 Stacking模型的ROC曲线和学习曲线
但通过比对实验,也发现存在的一些问题,如增加数据集,对于Stacking模型、Decision Tree、GDBT等检测准确率高效果好的模型,改善过拟合的情况效果不明显,还需要进一步改进模型,优化参数或提高模型的复杂度以改善过拟合问题。
5 结语
本文对PE文件提取文件头信息,对重要特征信息进行可视化分析,直观地展示了恶意代码与良性程序之间的特征差异。将机器学习的集成学习思想应用到恶意代码检测分析,使用几种典型的集成学习模型对恶意代码特征进行学习,取得了较好的检测效果。设计的Stacking 组合模型能够达到99.13%的分类准确率和98.22%的F1-Score,有效实现了恶意代码的检测。Gradient Boosting 同样取得了99%以上的准确率,与Stacking组合模型相比,Gradient Boosting 能够在更短的时间内完成实验训练。实验结果表明,本文提出的恶意代码检测方法具有较强的检测能力,是一种有效的、低成本的检测方法。该方法的不足之处,一是分类效果比较好的模型,存在过拟合情况;二是针对复杂的恶意代码(如加壳程序)仅采用获取的文件头信息进行检测,方法较单一。下一步研究的重点,将设计更为复杂的检测模型,改善过拟合情况;同时对PE文件进行多特征提取,如API、字节码等,结合PE文件头信息,实现多特征融合研究,并进一步应用深度学习模型,提高恶意代码检测的准确度。
注释:
①该图片引自“Kevin,PE File Format,http://dandylife.net/blog/archives/category/attack-defense”.
