基于DeeplabV3+的道路图像语义分割方法*
2023-10-09张绪德
张绪德
(凯里学院,贵州黔东南苗族侗族自治州 556011)
语义分割图像就是按照目标种类进行图像分割,帮助人们更好地进行判断。传统的图像分割技术有区域生长方法[1]、图切算法[2]、分水岭分割方法[3]等,但是传统分割方法存在精度值低、分割不准确的情况。随着卷积神经网络CNN 在计算机视觉和语音识别[4]等领域取得不错的效果,采用深度学习方法,应用基于卷积神经网络对目标特征进行学习,按照目标类别输出结果,能很好地对图像目标进行语义分割。
基于深度学习的语义分割算法采用全卷积网络FCN 方式对分割任务进行处理。PSPNet[5]采用独特的金字塔场景解析PSP 模块作为Decoder,PSP 模块为采用不同步长和池化大小的平均池化层进行池化,然后将池化的结果尺寸调整到统一大小,再进行堆叠得到分割图像。DeepLab 系列语义分割算法可以追溯到2015 年谷歌提出的DeepLabV1[6],DeepLabV1 特征提取网络是使用VGG(Visual Geometry Group,视觉几何组),2017 年DeepLabV2 在DeepLabV1 的基础上使用空洞卷积形式,连接空洞空间金字塔池化ASPP 模块,骨干特征网络使用ResNet-101,DeepLabV3+在前面的基础上使用编码-解码器结构,为DeepLabV3 添加有效的解码器模块,使模型提取特征能力得到加强。
1 DeeplabV3+语义分割算法
研究选用DeeplabV3+语义分割算法特征提取网络采用MobileNetV2,MobileNetV2 采用倒置残差模块,输入图像经过1×1 卷积进行通道扩张,方便获得图像中特征信息,然后使用3×3 深度可分离卷积进行特征抽取,采用此方法有利于减少模型参数量,最后使用1×1 卷积减少通道数。
1.1 空洞卷积
进行语义分割,采用普通卷积下采样时会降低分辨率,引起图像中信息丢失。使用卷积时通过引入扩张率dilation rate 将普通3×3 的卷积核在相同参数量和计算量下拥有5×5(dilated rate 为2)或者更大的感受野,从而避免下采样,有效解决分辨率降低造成的信息丢失。图1 左侧展示了普通3×3 的卷积,图1 右侧展示了dilation rate 为2 的空洞卷积。
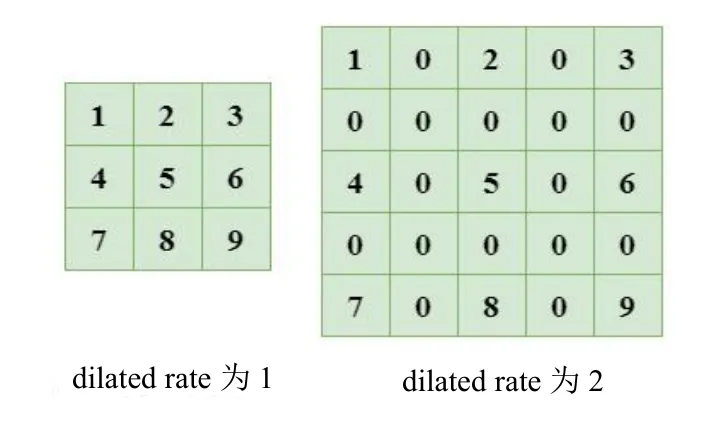
图1 空洞卷积形式
1.2 ASPP 模块
使用空洞卷积可以增大图像感受野,聚合更多的上下文信息。ASPP 模块在多个尺度上对物体进行鲁棒分割,捕获目标与图像上下文多尺度信息[7]。本次使用的空洞卷积dilation rate 分别为1、6、12、18,将分别提取出来的特征层进行堆叠,通过1×1 卷积将图像压缩后进行特征融合,选用的ASPP 模块如图2 所示。
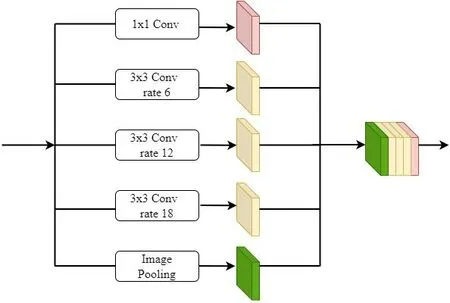
图2 ASPP 模块
1.3 编码-解码器结构
图像语义分割的过程之中使用编码-解码器结构有利于进行特征的提取。编码器在语义分割时主要应用于深度卷积神经网络之中,编码器提取较为深层次的语义信息,使用编码器有助于分辨率低时提取,图像经过编码器得到的深层特征具有更丰富的信息,深层特征输出应该使用较高的权重;解码器指的是能够完全恢复到原图的部分,主要作用在于卷积采样,并对各个层级进行连接处理,在深度神经网络中随着网络层级的加深,特征图像尺寸变得更小,语义分割需要采用高分辨率特征来改善细节,解码器能实现融合层级特征,DeeplabV3+语义分割算法编码-解码器结构如图3 所示。

图3 编码-解码器结构
由图可知DeeplabV3+语义分割算法编码器由DCNN 和ASPP 模块组成,图像经过DCNN 分别进行深层和浅层特征提取,深层特征提取信息通过ASPP后将不同空洞卷积的输出层经过1×1卷积进行信息融合,解码器包括编码器输出信息上采样后与浅层特征信息进行融合,再通过分类网络将每个像素点按照目标进行分类,通过上采样到与原图同样大小尺寸,就能实现语义分割[8]。
2 实验与分析
2.1 实验环境配置
基于DeeplabV3+的道路图像语义分割方法采用实验环境Windows10,训练时GPU 采用NVIDIA GeForce RTX 2080Ti,显卡显存为11 GB,软件环境选择pycharm 脚本编辑器,学习框架为PyTorch。
2.2 CamVid 数据集
在进行图像语义分割方法研究时,数据集的选取是进行研究的基础,经过语义分割后图像中的每个像素点会按照类别进行分类,最终图像会按照类别呈现不同的板块。研究采用的数据集是CamVid 语义分割数据集,数据集使用11 种常用的类别来进行分割精度的评估,分别为Road、Symbol、Car、Sky、Sidewalk、Pole、Fence、Pedestrian、Building、Bicyclist、Tree,数据集在进行语义分割算法使用时加上Background 共分为12 类。
CamVid 语义分割数据集中提供的训练图片和标签图片是PNG 格式,为方便区分和进行训练,将训练图片格式修改成JPG,标签文件格式保持PNG 格式。经过格式转变后训练图片和标签文件的信息依旧存在一一对应形式。
2.3 模型训练和评价指标
DeeplabV3+语义分割算法在进行训练时,将训练过程分为50 个epoch 进行训练,Batchsize 设置为8,训练时为加快模型收敛,以模型加载预训练权重方式进行。
DeeplabV3+语义分割算法评价指标采用模型准确率Accuracy、类别平均像素准确率MPA、平均交并比MIoU 判断语义分割算法性能的好坏。
模型准确率Accuracy 表示预测结果中正确的占总预测值的比例。类别平均像素准确率MPA 是指分别计算每个类被正确分类像素数的比例,将所有类进行累加求平均。
平均交并比MIoU 是指每个类计算真实标签和预测结果的交并比IoU,然后再对所有类别的IoU 求其均值。
2.4 结果与分析
分别使用传统 PSPNet 语义分割算法、MobileNetV2+PSPNet 算法和本文中的DeeplabV3+语义分割算法在CamVid 语义分割数据集进行训练,模型通过数据集训练完成后参数指标准确率Accuracy、类别平均像素准确率MPA、平均交并比MIoU 结果如表1 所示。

表1 不同算法在CamVid 数据集语义分割结果
模型训练完成后选取CamVid 进行语义分割数据集预测,分割前后图片显示如图4 所示,经过语义分割模型前后图片显示能很好根据真实目标轮廓进行分割。

图4 语义分割效果图
通过结果进行分析,利用DeeplabV3+语义分割算法,图片能将真实目标轮廓进行分割,与传统PSPNet语义分割算法、MobileNetV2+PSPNet 算法相比,MPA值分别提升1.11%和1.64%,MIoU 值分别提升2.02%和2.52%。模型参数量与MobileNetV2+PSPNet 算法相比,参数量多13.12 MB。
3 结束语
本研究基于DeeplabV3+语义分割算法进行道路图像语义分割,通过数据集选取、数据集训练、测试结果验证语义分割模型在实际图像中的应用。实验表明,DeeplabV3+语义分割算法在道路图像语义分割中取得良好的效果,准确率Accuracy 为92.11%、类别平均像素准确率MPA 为71.88%、平均交并比MIoU 为63.97%。本文算法和传统PSPNet 语义分割算法、MobileNetV2+PSPNet 算法相比,MPA 和MIoU 值得到提高,模型参数量比MobileNetV2+PSPNet 多13.12 MB,仅为ResNet-50+PSPNet 参数量的12.4%。道路图像语义分割依然面临着随道路环境复杂多变而图像中存在类别之间相互遮挡、相互重叠的问题,精确进行语义分割仍存在非常大的挑战。
