基于GA-BP神经网络的煤层底板突水量等级预测
2023-10-07刘艳冬卢兰萍刘林林王铁计靳子栋李大屯
刘艳冬, 卢兰萍*, 刘林林, 王铁计, 靳子栋,李大屯
(1.河北工程大学土木工程学院,河北邯郸 056038;2.冀中能源峰峰集团,河北邯郸 056038;3.邯郸市宝峰有限公司九龙矿,河北邯郸 056200)
0 引言
峰峰九龙矿区煤层下伏存在高水压,大水量的灰岩含水层,煤层底板保护层完整性较差。在煤层开采过程中,随着开采的深度、速度、以及规模的增加,煤层底板突水概率也随之增加,矿井突水对生命财产的威胁成为制约九龙矿区煤矿安全生产的主要难题[1]。因此,深入研究九龙矿区的底板突水机理,正确地评价及预测矿区深部开采时底板突水的可能性及突水量等级,对预防矿井水灾害的发生,及时提出科学的风险预防决策,进一步提升煤矿安全生产具有重要意义。
国内外专家学者针对煤层底板突水机理及预测的研究中,提出了悬臂梁假说[2],铰接岩块假说[3],板模型理论等理论方法,为矿井的安全生产提供了大量的经验和参考,为矿井水害防治工作的开展提供了坚实的理论基础和技术支持。但造成矿井水害的原因很多,它们之间存在着很强的非线性关系[4]。因此,运用传统的线性理论与方法来预测煤层底板突水,很难得到令人满意的预测精度。近年来,一些学者采用集对分析、多决策树法、Logistic回归分析法、支持向量机法等新方法对煤层底板突水进行预测。以上几种方法在治理矿井水害方面都有各自的特点,但这些方法对指标权重存在有主观性,在实际应用中受到一定的限制。人工神经网络作为一种非线性动力系统,能够处理复杂的突水因素,为解决矿井底板突水预测提出新的方法。
闫志刚等建立SVM-RF 模型进行矿井突水预测[5],张承斌等提出了将BP 神经网络模型用于煤层底板突水量等级预测的方法[6],但是,BP 神经网络权值和阈值随机产生,易陷入局部最优。遗传算法相较于其它智能算法不仅自适应范围广,还拥有强大的全局搜索能力[7-9]。因此,本文通过将遗传算法优化过的权值、阈值赋值给BP神经网络然后利用BP神经网络进行训练,建立煤层底板突水量等级预测的GA-BP 神经网络模型。将BP 预测模型作为其对比,通过对比不同模型预测精度进行评价。
1 煤矿实测数据采集及处理
1.1 数据来源
本文选取峰峰九龙矿区15449S 工作面煤层底板突水实例进行分析。工作面地面标高+115~+130m,井下标高-820~-890m,煤层倾角16°~20°,煤层平均厚度1.2m,上顺槽煤厚和下顺槽煤厚均为1.0~1.4m,切眼煤厚为1.0~1.1m。矿区勘探阶段揭露的断层均为小断层,煤层顶板为野青灰岩,直接底板为粉砂岩。
1.2 变量选择
按照国家煤矿安全监察局出台的《煤矿防治水细则》将突水量分为4 个等级(表1)。分别用1、2、3、4表示简单、中等、复杂、极复杂4个突水等级。

表1 突水量变量取值表Table 1 Surge water volume variable value table
为了在研究区收集到足够多的数据,并且这些数据可以充分地反映出煤层底板突水量等级的相关信息,选取水压、微震个数、煤层倾角、煤层厚度、采高、断层落差、①隔水层厚度(山伏青灰岩含水层与煤层之间隔水层厚度)、②隔水层厚度(大青灰岩含水层与煤层之间隔水层厚度)、山伏青灰岩含水层厚度、大青灰岩含水层厚度10个因素作为煤层底板突水量等级的影响因素。本文选取九龙矿区15449S工作面400份煤层底板突水实测数据进行分析(部分实测数据如表2所示)。

表2 工作面部分现场实测数据Table 2 On-site measured data of the working surface
2 GA-BP神经网络预测模型
2.1 BP模型构建过程
BP(Back Propagation)神经网络是一种误差反向传递学习算法,在传递信息的过程中,既有信息的正向传递又有误差的反向传递[10-11]。一般由输入层、隐含层和输出层三层神经元组成。因为原始数据集中各项数据具有不同的物理意义和量纲,为了避免样本数据直接输入对模型产生不利影响,造成预测误差增大,同时为提高神经网络的学习速率,采用归一化方法处理输入数据,使其取值范围为[0,1]。其转换方式如式(1)所示:
式中:x(p,i)为归一化后的数值;x0(p,i)为归一化处理前数值;xmin(i)、xmax(i)为全部样本中第i个数据的最小值和最大值;p为全部影响因素的整体数据集。
在BP 神经网络的设计中,确定隐含层的层数和结点的数目是一个很重要的问题,Kolmogorov 定理证明,三层BP神经网络能够以任意精度映射非线性输入输出关系[12],所以,本文选择隐含层层数为1层,图1 为本文采用的单层隐含层BP 神经网络模型的结构图。在确定隐含层神经元具体节点数时,本文选择经验公式的方法(公式2),经过多次计算当隐含层的节点个数为12时效果最好。由1.2节变量选择可知本文选取10 个煤层底板突水量等级影响因素,所以输入层神经元节点数为10,突水量等级分为四个等级,所以输出层神经元节点数为4。最终确定网络结构为10-12-4。经过对模型的多次试运行确定网络具体参数:最大训练次数1 000 次,学习速率0.01,训练函数选用trainlm 函数,显示频率每训练25 次显示一次。总体数据集中的340 组数据用于训练,60组数据用于测试。
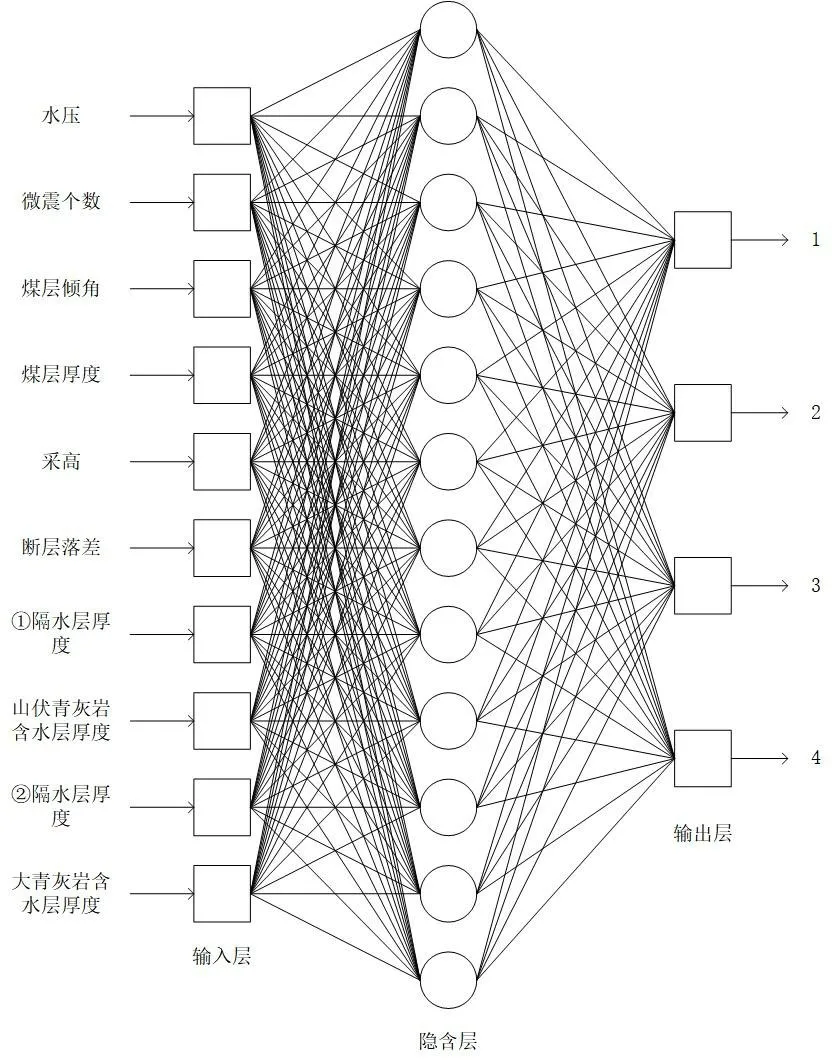
图1 BP神经网络模型结构Figure 1 Structure of BP neural network model
隐含层节点数经验公式:
式中:y为隐含层节点个数;e为输入层节点数;h为输出层节点数;l为[1,10]之间的整数。
在该三层神经网络模型中各层信号间的传递和计算关系如下,其中函数f称为激活函数,采用tansig 函数作为隐含层的激活函数,purelin 函数[13-14]为输出层的激活函数。
隐含层节点的输出:
输出节点的计算公式:
式中:Yj表示隐含层第j个节点的输出;f为激活函数;Wij表示第i个输入节点和第j个隐含层节点的权值;Xi表示第i个输入节点的输入数据;θj表示第j个隐含层节点的阈值;Pk表示输出层第k个节点的输出;Hjk表示第j个隐含层节点和第k个输出层节点的权值;λk表示第k个输出节点的阈值。
2.2 遗传算法原理
20 世纪70 年代,美国著名学者HOLLAND J H提出了遗传算法(GA),这是一种仿照达尔文进化论优胜劣汰的计算模型,采用了一种并行的、随机的、可扩展的,能更好地模拟生物进化过程的方法[15]。该方法能够模拟生物在自然界中适者生存、自然进化,能更好地寻求最优解,既能更好地扩展问题的解的覆盖面,又能更好地解决各类非线性问题。种群中,每一个个体都有可能会出现选择、交叉、变异,从而让个体适应度值持续提升,随着进化的进行,个体适应度好的将被保留,剔除适应性差的个体,从而提升个体质量。通过这种迭代进化的方式,不断优化问题的解,从而取得最佳值。
遗传算法的基本步骤:
1)编码及种群初始化。遗传算法首先将解数据表达为基因型序列,然后再执行搜索。遗传算法拥有多种编码方式,常见的有实数编码、二进制编码等,其中二进制编码可读性差,容易受到多维度问题的影响,实数编码具有精度高,搜索能力强的优点,因此本文选用实数编码进行染色体编码,染色体长度N计算公式如下所示:
式中:n、m、l分别为输入层、隐含层、输出层神经元个数。
2)计算适应度值。
3)选择。按照一定规则,一般选用轮盘赌法,依据个体适应度值在总适应度值中的占比判断被选择的概率,占比约大,被选择概率越大。
4)交叉。随机选取种群中个体进行相同位置编码的交叉操作,从而产生新的个体。
5)变异。在种群进化过程中设定变异概率,对被选中个体按照概率将某些基因值更改为其它等位基因。
6)重复执行2~5步骤,直到满足停止准则(例如达到一定的迭代次数,或者适应度已经满足约束条件等)。
2.3 GA-BP神经网络实现原理
在遗传算法中,目标函数不必是连续的或可微分的,只需要确保问题是能够计算的,遗传算法搜索方式是在整个解空间中进行搜索,所以很容易获得全局最优解。为了解决BP 神经网络随机生成初始权值、阈值参数的缺陷,首先根据BP 神经网络结构确定网络权值和阈值个数并随机生成初始权值和阈值,然后通过运用遗传算法的全局寻优能力,找出次优解所对应的权值和阈值,并将其作为BP网络的初始权值和阈值,再使用BP算法对网络进行训练,最终获得模型所需的最优解。正式训练网络前还需要对遗传算法各参数进行设置,常用参数设置方法如下:①种群规模:种群数量越多,则搜索空间越广,找到最优解的可能性也越大。但同时,种群规模越大,计算成本也越高。通常,种群大小可以根据实际情况选择,在20~200个较为合适。②交叉概率:交叉概率太小,则新生成个体数量会比较有限,影响种群多样性;如果交叉概率过大,则易降低收敛速度,通常可以设置在0.5~0.9。③变异概率:变异概率太小,则可能导致算法出现局部最优解问题,如果变异概率太大,则容易破坏已经找到的好的个体,通常设置为0.05 左右。通过选取各参数的不同数值进行组合并对模型进行多次训练,在综合考虑模型的预测准确率及收敛速度的前提下,正式训练网络前各参数设置为:种群规模为30,遗传代数为50,变异概率为0.8,交叉概率为0.2。GA-BP神经网络模型流程如图2所示。

图2 GA-BP神经网络流程Figure 2 Flow of GA-BP neural network
3 两种网络模型预测结果与实测值对比
采用实测数据对GA-BP 神经网络模型和BP 神经网络模型进行测试(部分测试结果见表3),同时为避免预测结果存在偶然性,选取10次测试结果准确率的平均值进行对比分析,结果表明BP神经网络识别的准确率平均值为84%,GA-BP 神经网络识别的准确率平均值为95%。对于预测精度不变的情况下,选择预测精度更好的BP神经网络可以更好的体现出遗传算法的优化效果。图3 是用BP 神经网络与GA-BP 算法计算出的煤层底板突水量等级预测值与实际测量结果的比较,由图3知,经过遗传算法优化后的BP 神经网络的预测准确率有了很大的提高。由图4遗传算法优化前后预测值与实测值误差可知,与BP 神经网络的预测结果相比,GA-BP 神经网络的预测结果与测量结果的吻合程度更高,误差较小。

图3 模型预测效果对比Figure 3 Comparison of model prediction effects

图4 误差对比Figure 4 Error comparison
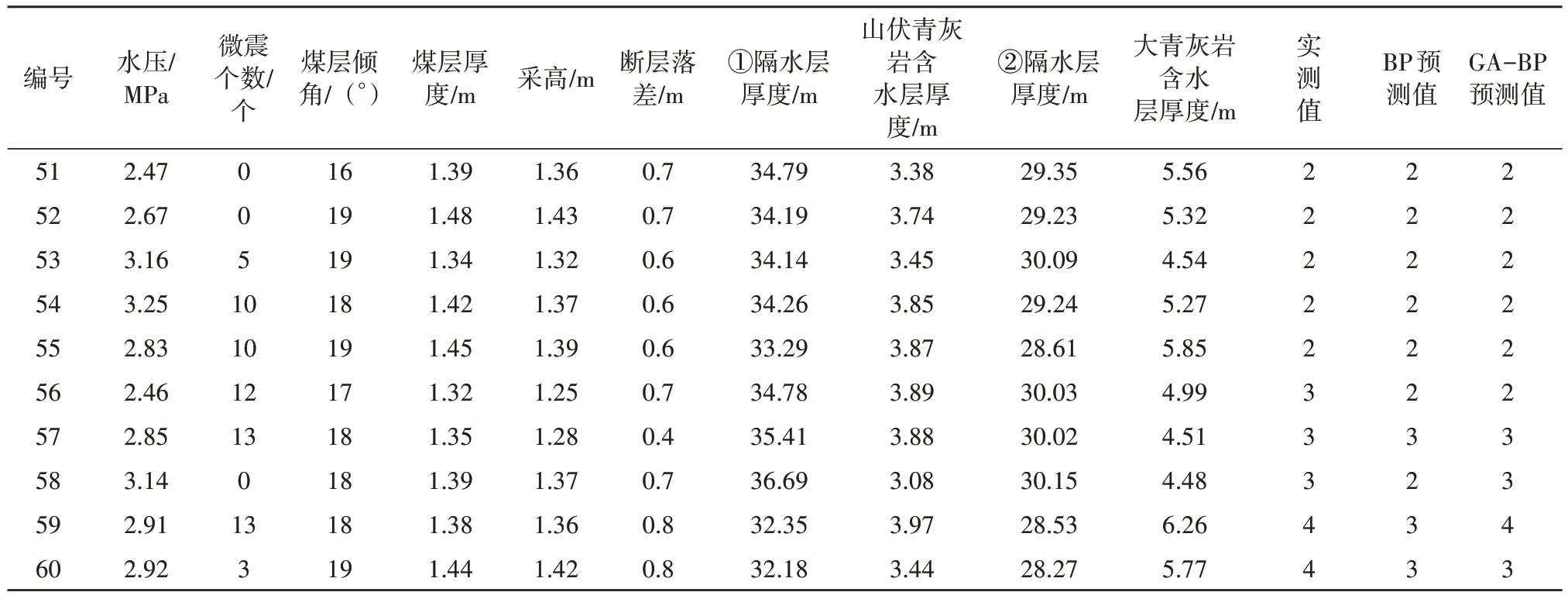
表3 模型测试结果Table 3 Model test results
由图5 和图6 可知,GA-BP 神经网络模型在训练的第5 次达到最佳验证性能MSE=0.028 454,BP神经网络在训练的第14次达到最佳验证性能MSE=0.033 505,表明遗传算法优化BP 神经网络是有效的,可以明显加快训练收敛速度,提高训练精度。
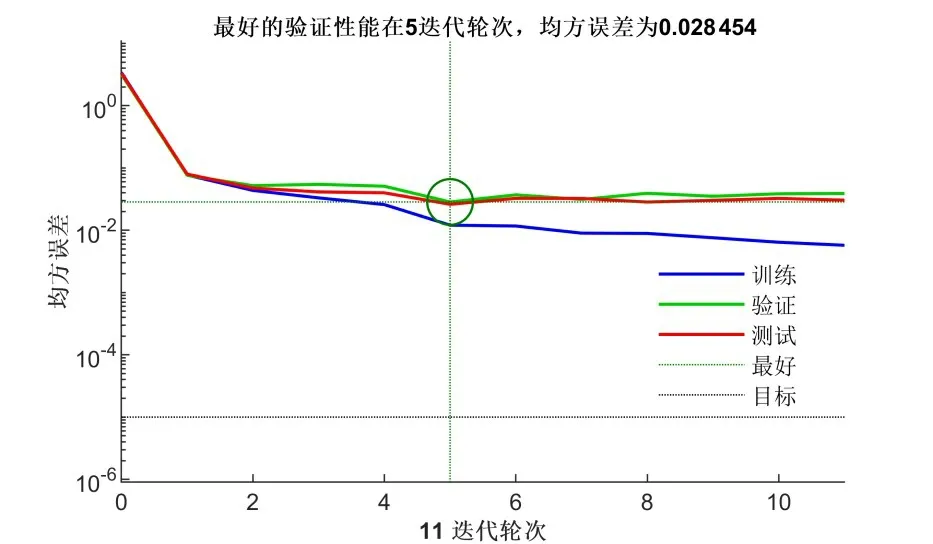

图5 BP神经网络训练过程Figure 5 BP neural network training process
在网络训练过程中,GA-BP 网络的相关系数R值在训练集、测试集、验证集分别为0.963、0.946、0.938,BP网络的相关系数R值在训练集、测试集、验证集分别为0.949、0.911、0.938。可知GA-BP 网络的相关系数R值在训练集、测试集、验证集均大于BP 网络,所以GA-BP 神经网络模型相比BP 神经网络模型的拟合程度更好。
4 结论
1)通过将GA-BP 神经网络和BP 神经网络实验结果进行对比可知GA-BP 神经网络模型性能更优,其预测准确率95%高于BP 神经网络的84%,所以GA-BP 神经网络可以更好的进行煤层底板突水量等级预测。
2)相比与BP 神经网络在训练的第14 次达到最佳,GA-BP神经网络在训练的第5次便达到最佳,且GA-BP 神经网络在训练集、测试集、验证集的相关系数均小于BP 神经网络的在训练集、测试集、验证集的相关系数,表明遗传算法可以有效提高BP神经网络的预测精度及拟合程度。
