基于ResNet18与胶囊网络结合的人脸表情识别
2023-09-29冯宇平鞠伯伦
刘 宁, 孙 萍, 冯宇平*, 鞠伯伦
(1.青岛科技大学 自动化与电子工程学院, 山东 青岛 266061;2.青岛海湾化学股份有限公司,山东 青岛 266409;3.中国船舶集团有限公司第七一六研究所,江苏 连云港 222006)
二十世纪七十年代初,著名心理学家EKMAN[1]提出人类6 种基本情感的概念,分别是开心、惊讶、悲伤、生气、恐惧、憎恶,后来又加入中性表情,构成人脸表情识别的7种基本表情。人脸表情识别可以分为两类:传统方法[2-3]和基于深度学习[4-13]的方法。由于传统方法无法提取到人脸面部表情图片的深层特征,因此目前人脸表情识别主要是基于深度学习方法的研究。文献[7]针对实际场景中人脸表情多为复合表情的问题,提出一种深度位置保留(DLP-CNN)的人脸表情识别方法解决这种模糊性情感问题;文献[9]提出一种paCNN 方法,根据相关人脸位置标记,从最后的卷积特征图中裁剪出感兴趣的部分,学习并专注于局部具有区别性和代表性的部分;文献[10]提出一种PAT-CNN方法,是以分层的方式学习和表达相关特征,从而减轻面部表情识别中由特定的人属性引入的变化。虽然CNN 在很多方面都展现出它强大的性能,但也存在弊端,比如CNN 中的池化层会丢失图片的部分特征,这限制了人脸表情识别技术的发展。2017年,HINTON 提出胶囊网络[14],完美保留了卷积模块提取到的图片特征。文献[12]将VGGNet16 网络和胶囊网络进行结合,并添加AU(Action Unit)单元,在RAF-db数据集(图片大小为224×224)上进行实验,识别率达到85.24%;文献[13]将DenseNet网络与胶囊网络结合,针对多视角人脸表情进行识别,在数据集FER2017 达到了平均值为53.9%的F1值。本研究将残差网络和胶囊网络结合进行人脸表情识别,并将所提到的方法在CK+、RAF-db和FER+[15]数据集上进行了实验分析。
1 算法与数据
1.1 ResNet18网络
ResNet18网络的主要结构是4个堆叠的残差块,残差块结构如图1所示,它将输入的特征信息通过一个1×1的卷积连接到残差块的输出端,缓解了深层网络在训练的梯度消失和爆炸的情况。在实验过程中,通过对比ResNet18 与胶囊网络结合和ResNet34与胶囊网络结合的实验结果,发现网络更深的ResNet34与胶囊网络结合后的优势并不大。分析这是由于本研究所采用的数据集尺寸较小,浅层的卷积神经网络就可以提取到丰富的特征信息,且在融入CBAM 注意力机制[16]后特征提取能力进一步提高。
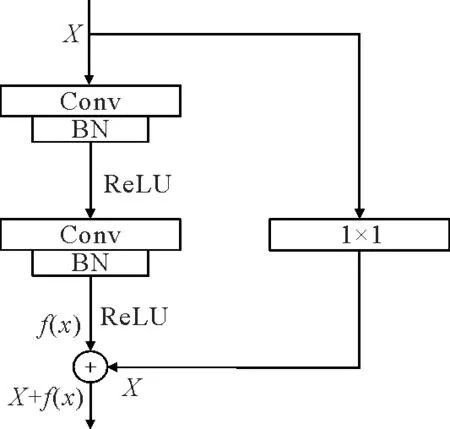
图1 残差块结构图Fig.1 Residual block structure diagram
1.2 胶囊网络
胶囊的概念最早在2011年被HINTON 提出,在文献[17]中,HINTON 团队展示了神经网络如何被用来学习特征,输出整个矢量的实例化参数,并且认为该方法在旋转不变性、尺度不变性和光照变化等方面比目前神经网络中使用的方法更有优势。2017年,HINTON 提出胶囊网络,并在MNIST 手写体数据集上进行了测试,获得业界最佳的效果,随后研究者证明胶囊网络在图像分类方面具有广泛的应用前景。
1.2.1 胶囊网络的结构
胶囊网络框架是一个浅层的框架,主要有3部分:卷积层、初级胶囊层、数字胶囊层,如图2所示。
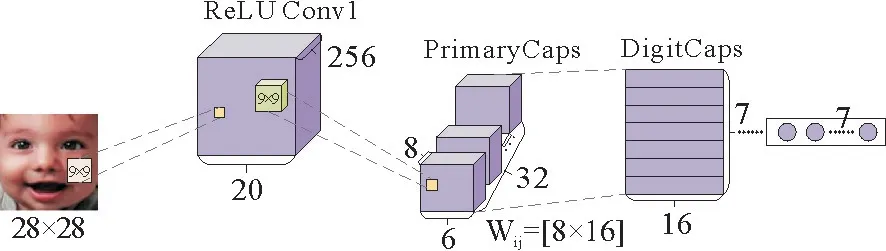
图2 胶囊网络结构图Fig.2 Capsule network structure diagram
其中,卷积层主要用来提取输入数据的特征,它是一个通道数为256,卷积核大小为9×9,步长为1的单卷积层,激活函数采用ReLU 激活函数。初级胶囊层主要分为两个部分:第一部分是一个通道数为256,卷积核大小为9×9,步长为2的单卷积层;第二部分是一个reshape操作,将提取到的特征封装为32个胶囊,每个胶囊含有8个卷积单元。数字胶囊层是初级胶囊层经过路由机制得到的,数字胶囊层有7个胶囊,即将人脸面部表情分为7类。
1.2.2 路由机制
路由机制是胶囊网络的核心,低层特征与高层特征之间是通过路由机制来更新权重系数的,在Hinton提出的胶囊网络中采用的是动态路由机制(dynamic routing),其原理图如图3所示,图3是以路由机制迭代3次,任意个胶囊为例,展示胶囊网络的动态路由机制原理。其中V1~Vi是输入胶囊,W1~Wi是权重矩阵,C11~Ci3是耦合系数,V是输出胶囊,U1~Ui、S1~Si和A1~Ai是中间值,Squashing是一个非线性的“挤压”操作,目的是为了在保持胶囊方向不变的前提下,将胶囊的长度收缩在0~1之间,其公式为

图3 动态路由机制Fig.3 Dynamic routing mechanism
其中‖Si‖是向量Si的模,当‖Si‖2比较大时,Vi的值趋向于1,当‖Si‖2比较小时,Vi的值趋向于0。
1.3 注意力机制
当人进入到一个新场景或者看到某张图片时会有一个重点关注的区域,也就是注意力焦点,人们会分配更多的注意力在这些区域以获得更多的细节,这就是人类所具有的选择性注意力机制。深度学习的注意力机制[18-19]借鉴了人类的注意力机制,使得计算机可以像人类一样可以重点关注图片中的关键信息。目前,注意力机制从关注域方面可以分为3类:空间域注意力机制、通道域注意力机制和混合域注意力机制。
空间域注意力机制如图4(a)所示,它是将输入的数据经过一个空间转换器(spatial transformer)模型,该模型能够对输入图像中的空间域信息进行空间转换,从而提取出关键的特征信息,并赋予不同的权重。通道域注意力机制如图4(b)所示,它是先进行Squeeze操作,将空间维度进行特征压缩,即每个二维的特征图变成一个实数,也就是该通道的权重,这相当于具有全局感受野的池化操作,特征通道数不变。混合域注意力机制是将空间域和通道域注意力机制结合起来,这样就可以同时拥有这两种注意力机制的特性。

图4 注意力机制Fig.4 Attention mechanism
1.4 本研究网络结构
虽然Hinton提出的胶囊网络在手写体识别上取得业界最高的识别率,但是由于胶囊网络前面特征提取部分只有两个单卷积层,在对人脸面部表情特征提取时,特征提取不全,因此,本研究对胶囊网络前的卷积模块进行网络加深。首先对Res Net18进行改进,然后用改进后的ResNet18 替换胶囊网络的单卷积模块,得到本研究的ResCaps Net网络。具体的网络结构如下。
首先,因人脸表情分类工作由胶囊网络中的数字胶囊层来完成,所以去掉ResNet18的全连接层;然后为不损失卷积模块提取到的特征,剔除全局平均池化层;另外还调整原ResNet18 第1 个卷积层的卷积核大小,原3×3的卷积核改为5×5 的;最后,对残差模块(Basic Block)进行改进,其中第1个残差块保持不变,将第2、第3个残差块的步长调整为1,第4个残差块的步长保持不变,但将其通道数改为256。
除此之外,为进一步提升网络性能,在4个残差块中加入CBAM 注意力机制,他是一种混合域的注意力机制,包含空间域和通道域两种注意力模块,其总体结构,如图5所示。

图5 CBAM 注意力机制Fig.5 CBAM attention mechanism
其中,通道域注意力模块如图6所示,它是在输入特征F1上分别进行全局最大池化和全局平均池化得到两个一维向量,经过共享的MLP层,然后相加再经过Sigmoid激活函数,得到通道注意力权重Mc(F1),Mc(F1)与输入特征F1相乘后得到特征F2。

图6 通道域注意力模块Fig.6 Channel domain attention mechanism
空间域注意力模块如图7所示,它是在特征F2上进行最大池化和平均池化,得到两个特征图,然后经过一个7×7的卷积,得到一个新的特征图,再经过BN层和Sigmoid激活函数,得到空间注意力权重Mc(F2),Mc(F2)与特征F2相乘后得到输出特征F3。

图7 空间域注意力模块Fig.7 Spatial domain attention mechanism
最后将上述搭建的网络与胶囊网络进行结合。由改进后的ResNet18 来提取人脸面部表情的特征,再将提取到的特征图送入胶囊网络进行训练和分类,具体网络结构如图8所示。
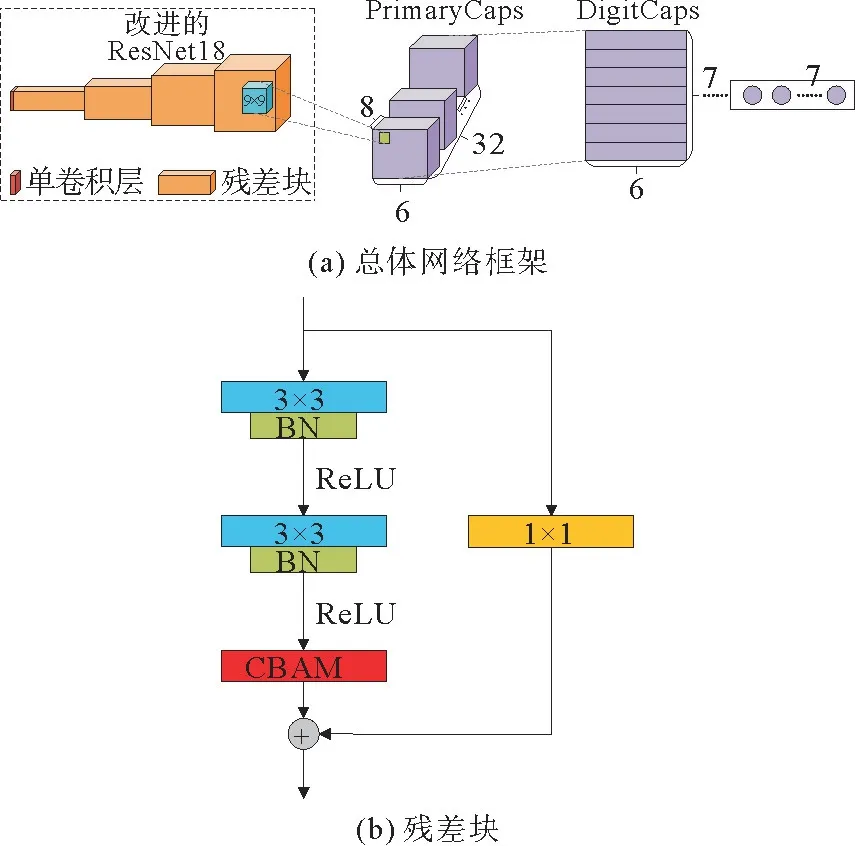
图8 改进的网络结构图Fig.8 Improved network structure diagram
1.5 数据集
本研究所用到的数据集有:CK+、RAF-db 和FER+。
CK+:该数据集是在实验室条件下建立的数据集,发布于2010 年,共有981 张48×48 大小的图片,该数据集共分为7类表情。
RAF-db:该数据集制作是目前最严苛的人脸表情数据集,该数据集中的每张图片都是通过40个标注者投票,然后取最高票数的那一类表情作为该图片的标签,图片大小是100×100。
FER+:该数据集是英特尔公司在2017年时对FER2013数据集重新标注而来,图片大小是48×48。它将数据分为10类,实验仅使用其中7类表情。
2 结果与分析
为验证本研究所提出的人脸表情识别方法的可行性和有效性,在CK+、RAF-db和FER+数据集上进行一系列实验。其中在使用FER+数据集时,采用两种方法:一种是单标签,即选用最大概率的表情作为该图片的标签;二是考虑到数据集存在两种等概率表情的图片,如一张图片中性和悲伤表情的概率均为40%等,因此采用双标签来对数据进行标注。测试时,选择分类概率最高的作为识别结果,然后与标签进行对比,所有识别正确的图片数与总数相比算出识别率。
2.1 改进的ResNet18与胶囊网络结合实验分析
表1是3个数据集在不同网络下的识别率,从中可以看出在CK+数据集上,单独的CapsNet对于人脸表情识别的准确率是非常低的。这是因为CapsNet只有单卷积层,对复杂的人脸表情特征提取不足,再加上该网络的鲁棒性要比卷积神经网络差一些,导致其在人脸表情识别方面比Res Net18差很多,但是Caps Net在训练时收敛比较快,训练50代左右就可以达到最高准确率,而ResNet18需要训练200代左右才能达到最高准确率。本研究将二者进行结合使其优势互补,ResCapsNet网络仅需训练50 代左右就可以达到最高准确率,而且在CK+、RAF-db和FER+3个数据集上识别率分别提升了3.03%、6.30%、3.35%。
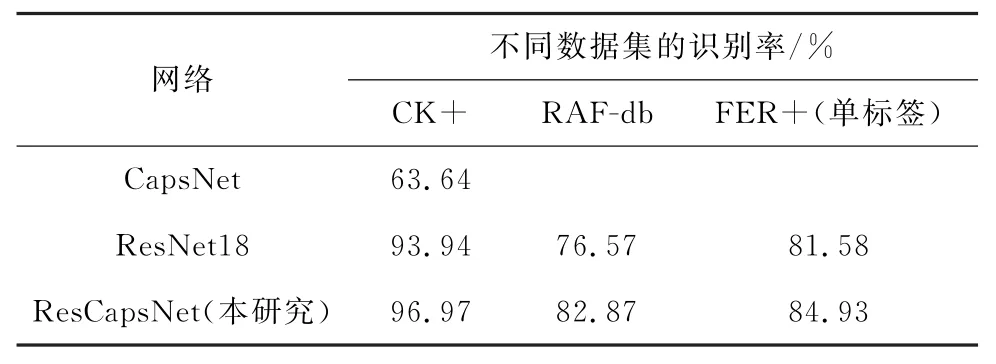
表1 3个数据集在不同网络下的识别率Table 1 The recognition rate of three data sets in different networks
2.2 注意力机制对网络性能影响分析
为进一步提高网络性能,本研究在ResCapsNet中采用两种方式添加不同的注意力机制,如图9所示,并在RAF-db、FER+数据集上进行对比实验,具体实验结果如表2、3所示。

表2 RAF-db数据集上的实验结果Table 2 Experimental results of RAF-db data set

表3 FER+(单标签)数据集上的实验结果Table 3 Experimental results of FER+(single label)data set

图9 两种注意力机制添加方式Fig.9 Add attention mechanism with two ways
ResCaps Net中共有4个残差块,图9中展示的是在一个残差块中如何添加CBAM 注意力机制。从表2、3中的实验结果不难看出方式二的准确率普遍比方式一高,而且在3 种注意力机制中,添加CBAM 的效果最好。从表4中可以看出ResCaps-Net在采用方式二添加CBAM 注意力机制后,比未添加时,CK+数据集识别准确率提升1.01%,RAF-db数据集提升1.24%,FER+数据集识别提升1.28%,由此可以说明在残差块中添加CBAM注意力机制是非常有效的。

表4 有无CBAM 注意力机制实验结果对比Table 4 Comparison of experimental results with or without CBAM attention mechanism
2.3 不同方法实验结果对比分析
表5、6是加入CBAM 注意力机制的ResCaps-Net网络在RAF-db和FER+数据集上与其他文献中方法的实验结果对比。从2个表中可以看出与目前人脸表情识别方法相比,本研究所提出的方法是具有一定优势的。并且从表6 中可以明显看出,FER+ 数据集采用双标签识别准确率达到94.14%,远高于单标签准确率,由此在一定程度上说明生活中人脸面部表情并不是单一表情,而是多种表情复合而成。

表5 RAF-db数据集在不同方法下的实验结果Table 5 Experimental results of RAF-db data set under different methods

表6 FER+数据集在不同方法下的实验结果Table 6 Experimental results of FER+data set under different method
3 结 语
提出一种改进的Res Net18与胶囊网络结合的方法,并应用于人脸表情识别。改进的方法与仅用卷积神经网络提取人脸表情特征相比,提取到的图像特征更丰富,并且训练迭代次数少,仅需要迭代五十几次就可以拟合,要远少于传统的卷积神经网络。在CK+、RAF-db和FER+数据集上进行实验后,实验结果表明该网络在人脸表情识别方面具有较高的准确率。本研究后续的工作将从如何优化网络模型,减少网络参数量,提高识别速度方面进行研究。
