基于KH-KELM 的鸟类声音分类识别
2023-09-27沈希忠
沈希忠,陈 菱
(上海应用技术大学 电气与电子工程学院,上海 201418)
鸟类作为环境生态系统不可或缺的指示生物之一,其种类的确定对生物多样性保护和生态平衡优化等起着十分重要的作用。鸟鸣声蕴含了丰富的鸟类生态学信息,其相关的研究成果可应用于鸟类行为分析与监护和生态环境状态监测等领域[1]。20 世纪50 年代开始国内外学者不断提出特征提取算法[2-3]和各个分类模型[4-5]来实现特定声音的识别和分类。各种语音信号处理方法也被应用于鸟类声音特征的提取和分类中[6],并不断有学者提出新的优化算法来提高分类准确率。早在1997 年,McIlraith 等[7]利用反向传播和多元统计数据分析6 种原产于曼尼托巴的鸟类鸟鸣特点,并获得了82%~93%的泛化性能的正确识别率。Lucio 等[8]用支持向量机(support vector machines,SVM)分类器对鸟类鸣声频谱图提取出的3 种纹理特征进行分类识别,实现最佳识别率77.56%。魏静明等[9]在提取纹理特征的算法上增加和差统计法,验证了对鸟鸣声识别的有效性。程龙等[10]在Mel 频率倒谱系数(Mel frequency cepstral coefficient,MFCC)算法对鸟鸣信号进行快速傅里叶变换之前,增加经验模态分解算法,改进后的MFCC 算法算对7 种鸟声的识别率达到70.09%。谢云澄[11]在基于图像识别的传统驱鸟设备中加入基于深度学习的声音检测模块,对包含3 种鸟类和3 种环境声音的6 种声音进行识别,最后得到最高93.9%的识别准确率。
极限学习机(extreme learning machine,ELM)是一种自提出以来一直被很多学者,用来解决生活中的很多回归和分类问题的单隐层前向神经网络训练算法。Yang 等[12]采用局部三元模式提取面部图像特征,并构建面部图像的性别识别极限分类系统,识别准确率达到87.13%。林伟铭等[13]将ELM应用于阿尔茨海默病的诊断,准确率达到87.62%。张婷慧等[14]使用粒子群算法(particle swarm optimization,PSO)优化混合核极限学习机(kernel extreme learning machine,KELM)参数,构建遥感影像信息分类模型,可达到92.67%的分类准确率。
鸟类对环境质量的变化很敏感,通过户外放置拾音器采集飞过的鸟类声音并识别其种类,分析鸟类种类的变化从而反馈环境质量的变化,并对变化做出相应措施,更好保护生态环境。为了验证KELM 在鸟类声音识别方面的效果,本文在ELM理论的研究基础上,结合核函数理论和磷虾群算法(krill herd algorithm,KHA)对使用MFCC 算法特征提取的上海常出现的30 种鸟类鸟鸣信号进行识别和分类,最后与ELM、反向传播神经网络(back propagation,BP)、SVM、KELM 分类模型进行对比研究,通过识别的准确率来确定其结果的可靠性。
1 KELM 原理
1.1 KELM
ELM 是Huang 等[15]提出的一种单隐层前向神经网络(single-hidden layer feed forward network,SLFN)的训练算法,它随机分配隐藏层并分析确定SLFN 的输出权重。ELM 训练指对输入数据先进行随机特征映射,再进行线性参数求解从而得出分类或预测结果。相比于传统的很多模型训练算法,ELM 是一种具有竞争力的机器学习技术,ELM 理论简单,实现速度快,有较强的泛化性能和鲁棒性,提出的框架可以使用多种特征映射函数或内核,而且所提出的方法可以直接应用于多分类任务。SLFN 网络结构如图1 所示。
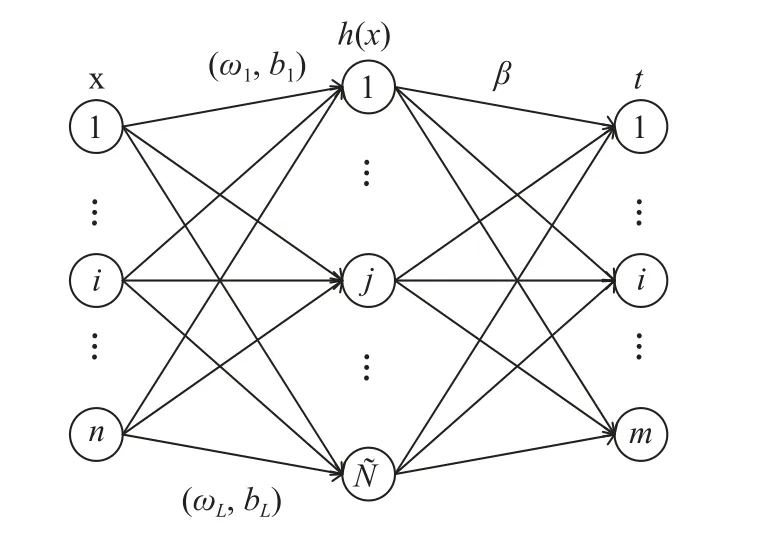
图1 SLFN 网络结构Fig. 1 Network structure of SLFN
对于N个不同的训练数据{xi,ti},i=1,2,···,N,xi是一个 1×n(n为输入数据的维度)输入向量,ti是一个1×m(m为类的数量)的条目等于1 的输出向量。含有Ñ个隐藏节点且激活函数为g(x)的数学模型可表示为:
式中:βi为第i个隐藏节点的权值;(ωi,bi)是随机产生的隐藏节点参数。式(1)也可表达为:Hβ=T。
其中:
式中:H为隐藏层输出矩阵;g(ωi,bi,xi)是激活函数,通常用Sigmoid 函数;T是训练数据的目标矩阵。
ELM 明显不同于传统的前馈神经网络的是,训练过程中唯一需要优化的参数是隐藏节点和输出节点之间的输出权重β。在数学上,通过ELM 训练SLFN 可以转化为解决正则化最小二乘问题,不需要额外的迭代步骤来调整SLFN 的参数,这比BP 类算法更有效。
ELM 通过最小化以下损失函数来确定输出权重:
推导可得式(3)的最优解为:
式中,H-1为H的逆矩阵。
实际问题中,训练样本的数量N明显大于隐藏节点的数量Ñ,这种情况下,不存在H方阵,故也不存在H的逆矩阵。Huang 等[16]提供了另一种寻找最小范数最小二乘解的方法:
由于ELM 在训练前随机选择参数,难以保证其稳定性和持续性,此时可以定义1 个核函数:
式中:K(xi,xj)为 核函数;h(·)为隐藏层神经元输出函数。
KELM 的分类模型的输出可表达为:
KELM 模型无需使用随机参数,即不需要知道隐藏层输出矩阵H,可有效增加模型的鲁棒性和稳定性。
1.2 核函数选择
针对鸟类声音识别问题,核函数的选取很重要,对比多项式核函数、径向基(radial basis function,RBF)核函数、线性核函数和Sigmoid 核函数,发现RBF 核函数的ELM 的分类模型对鸟类识别有更好表现。RBF 核函数是一种学习能力强、所需确定的参数比较少的局部性核函数[17],其定义如下:
式中:xi为核函数中心;γ为函数宽度参数。
2 磷虾群寻优算法
KHA 是Gandomi 等[18]提出的一种优化算法,以磷虾群中每只磷虾觅食过程中的活动和状态的更新创建KHA 的寻优过程。KHA 中,磷虾个体i的第k次移动速度Mi(k)由 诱导运动Ni(k)、觅食运动Fi(k)以 及随机扩散Ri(k)组成,可以表示为:
(1)磷虾个体i的 诱导运动Ni(k)定义为:
(2)磷虾个体i的 觅食运动Fi(k)定义为:
(3)磷虾个体i的 随机扩散过程:
式中:Rmax为最大扩散速度;δi(k)为随机方向向量,是区间[ -1,1]的 随机数;Imax为最大迭代次数。
(4)磷虾i从t时刻经 ∆t时 间后的状态更新:
式中:∆t为 速度矢量比例因子;Mi为磷虾i的移动速度。
磷虾在附近磷虾和食物位置影响下不断更新位置,直到移动到最优位置或者达到算法中设置的最大迭代次数后寻优停止。将KHA 优化后得到的食物位置对应的最优值设置为KELM 分类器的参数,达到分类模型最优的识别效果。
3 实验仿真
3.1 鸟鸣信号预处理
由于气候差异,不同地区有各自的生物群落,鸟的种类也有差异,由于鸟鸣采集在上海进行,故选择上海具有代表性的30 种鸟类作为研究对象,30 种鸟的鸟鸣声音音频来自实地录制的部分鸟类音频和鸟类鸣声数据网xeno-canto 上下载的鸟鸣音频,使用GoldWave 音频处理软件初步筛选各个鸟鸣样本,并对噪声杂音大、鸟鸣音频音量小、多鸟鸣杂音干扰大的样本进行预处理,构建鸣声特征明显的有效鸟鸣信号样本音频数据库。预处理后的样本,再裁剪无声区较长的音频样本,只保留有效鸣声信号区域,以便提取MFCC 特征。四声杜鹃的一段鸣声信号处理前后样本状态,如图2 所示。
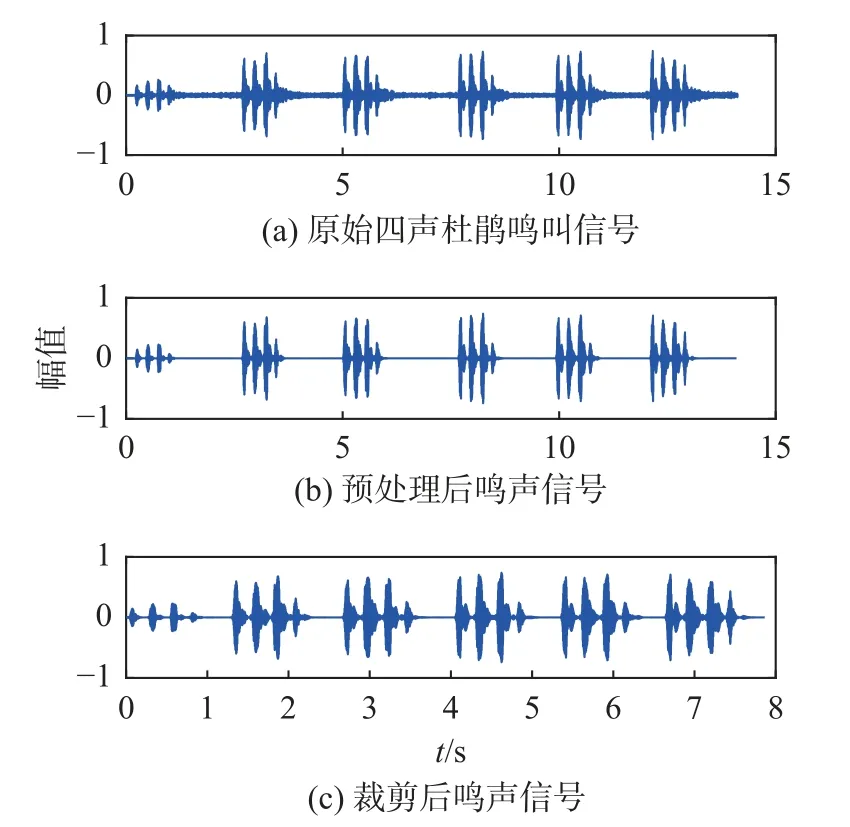
图2 一段四声杜鹃鸣声信号样本Fig. 2 Birdsong signal sample of a cuculus micropteru
3.2 鸟鸣信号特征提取
使用MFCC 特征提取函数提取信号的特征参数,输入需要分析的语音信号的音频帧和采样频率,选择输出12、24 或36 阶MFCC 参数。如图3 所示,将鸟鸣信号进行预加重和分帧,再进行快速傅里叶变换(fast fourier transform,FFT)得到信号的幅度谱,然后将变换得到的谱信号通过一组Mel滤波器组,之后将Mel 滤波器输出的能量取对数得到对数能量谱,最后将对数能量谱进行离散余弦变换(discrete cosine transformation,DCT),得 到MFCC 参数:

图3 MFCC 特征提取过程Fig. 3 Feature extraction process of MFCC
式中:i为第i帧;n为离散余弦变换后的谱线;M为Mel 滤波器组中滤波器的数量;S(i,m)为通过Mel 滤波器后的对数能量,m为第几个滤波器。
建立30 种鸟类鸣声样本集,使用MFCC 算法提取各类鸟类声音信号的特征参数,图4 为本文采集的30 种鸟类声音信号集某个样本中一帧的MFCC 特征参数。提取30 类鸟鸣信号的12 维静态MFCC 参数,再提取30 类鸟鸣信号包含12 维静态和其一阶差分后得到的12 维动态的24 阶MFCC 参数,对比2 次提取到的参数可知,12 维静态MFCC 参数差异比较明显,12 维动态MFCC 参数差异很小,特征很难分辨。故选取12 维静态MFCC 参数表示30 类鸟类声音信号的特征参数。
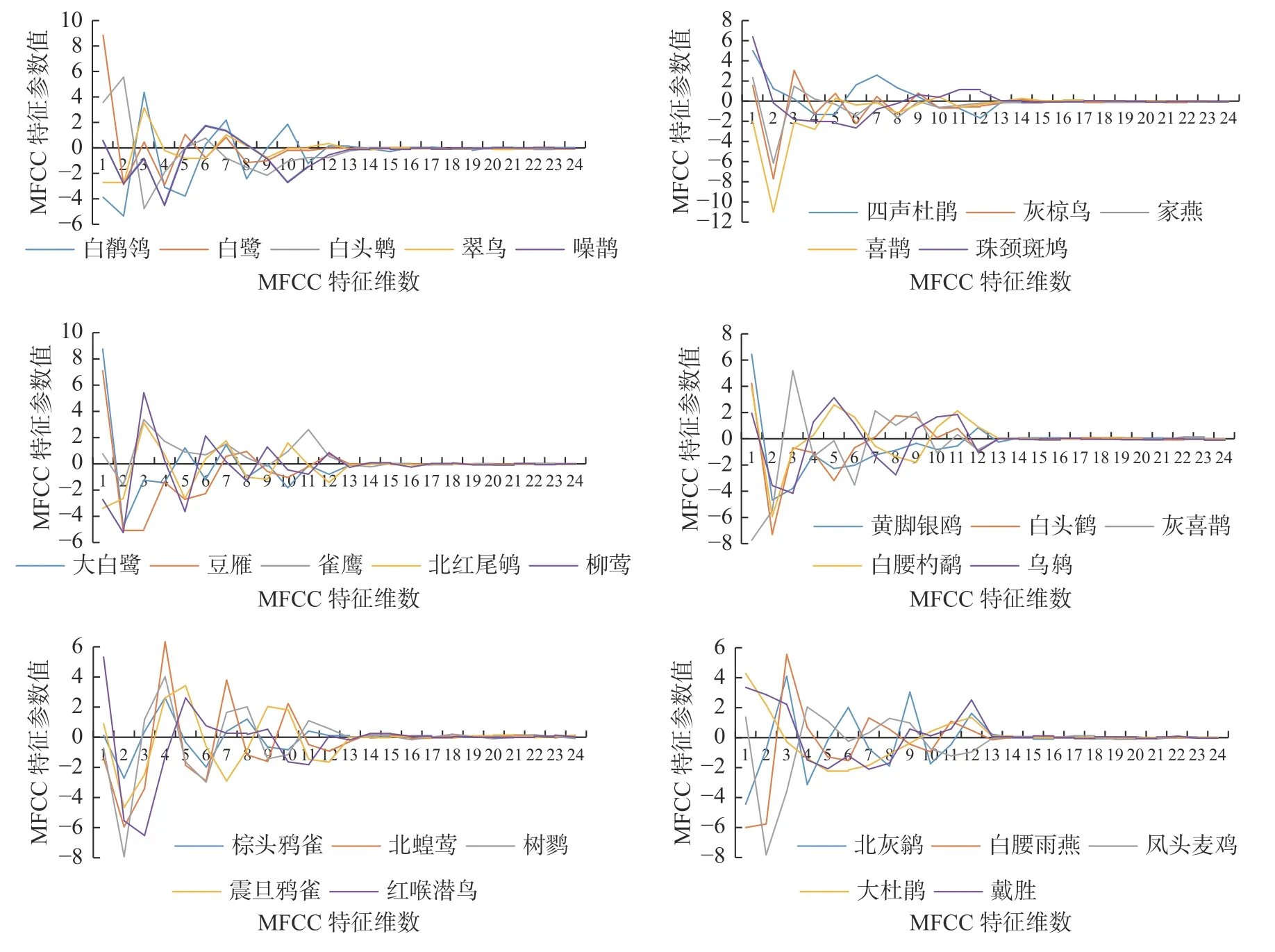
图4 30 种鸟鸣信号的MFCC 特征参数Fig. 4 MFCC characteristic parameters of 30 birdsong signals
3.3 鸟鸣分类识别
鸟类鸣声分类识别流程如图5 所示,将各类鸟鸣样本提取的特征参数作为每类鸟鸣样本特征数据集,特征数据集随机选取70%样本数据构成训练样本数据集,剩余30%数据构成测试样本数据集。核函数ELM 模型对训练样本数据集进行训练,运用KHA 有限次迭代寻找最佳适应度优化核函数ELM 的参数C和γ,并将最优参数更新到模型中,对测试数据样本进行分类。
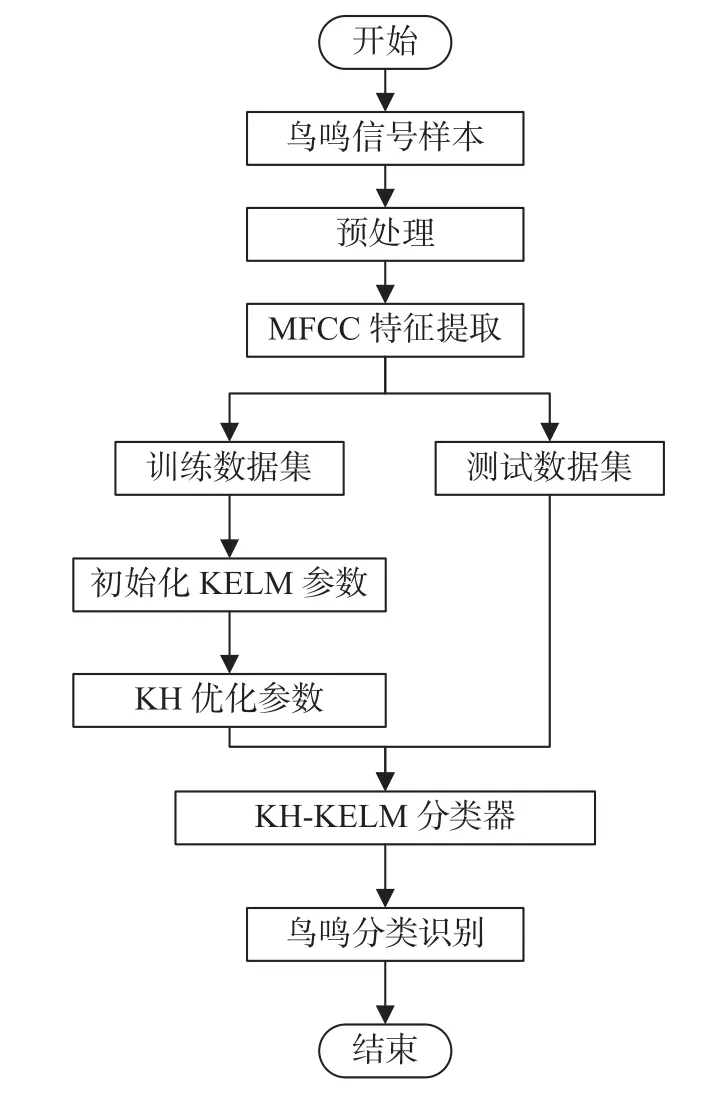
图5 鸟鸣信号分类识别流程Fig. 5 Birdsong signals recognition process
选取的上海周边30 种鸟类名称、各种鸟类的语音段、特征提取后的训练数据和测试数据如表1所示。

表1 鸟类样本数据集Tab.1 Bird sample datasets
基于鸟鸣信号识别与分类实验,对比10 种鸟类的测试数据集识别分类中Polynomial 核函数、RBF 核函数、Linear 核函数和Sigmoid 核函数的分类准确率,如图6 所示,RBF 核函数的识别准确率最高。
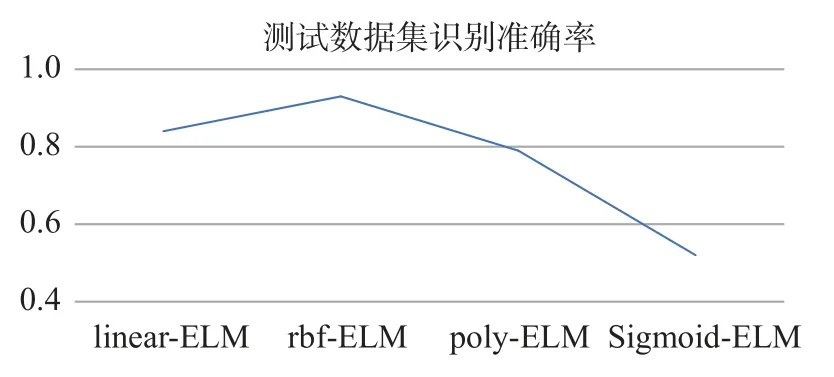
图6 鸟鸣信号ELM 分类器不同核函数比较Fig. 6 Comparison of different kernel functions of ELM classifiers for Birdsong signals
对KH-KELM 分类模型使用训练样本数据集进行模型训练,使用测试样本数据集验证模型的分类效果。其中,磷虾群优化算法的迭代次数设置为迭代100 次,磷虾种群数量设置为30 个,参数C和γ搜索区间为[ 1,100]。由于ELM 模型的参数具有随机性,所以ELM 相关分类模型分类准确率取20 次实验的准确率平均值。为验证KH-KELM 分类模型分类性能,将其与ELM、BP、SVM、KELM 分类模型比较,并与用遗传算法(genetic algorithm,GA)、PSO、蚁群算法(ant colony optimization,ACO)分别优化KELM 的分类模型比较,分析分类效果。
表2 为 ELM、BP、SVM、KELM 和 KHKELM 分别对鸟类进行分类识别测试的准确率结果。由表2 可知,KH-KELM 对5、10、20 和30 种鸟类分类测试的准确率分别达到99.65%,97.79%,94.48%和89.21%,20 次的实验结果范围为±0.5%;分类准确率比ELM、BP、SVM 和KELM 分类模型的分类准确率都高,从分类5 类扩展到分类30类鸟,分类效果稳定且分类性能较好。
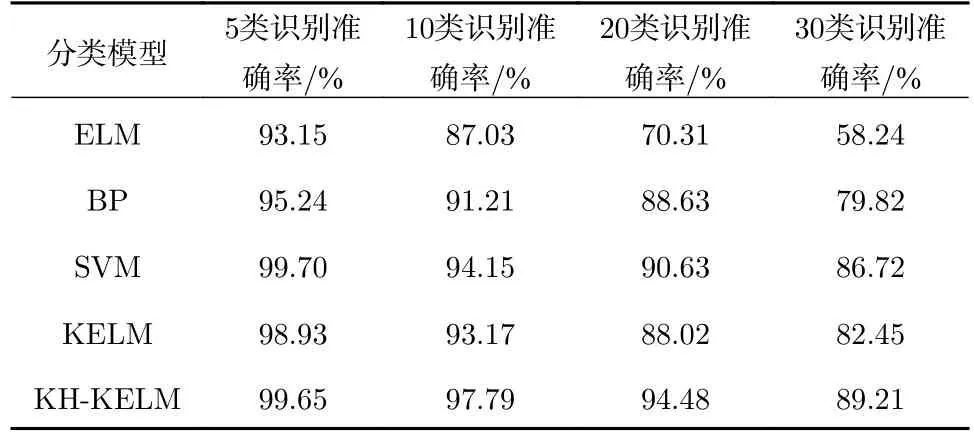
表2 KH-KELM 和其他分类模型识别准确率比较Tab.2 Comparison of recognition accuracy between KH-KELM and other classification models
表3 为GA、PSO、ACO 和KH分别优化KELM 模型对鸟鸣信号识别的准确率结果。由表3可知,从分类5 类扩展到分类30 类鸟,KH 优化的KELM 分类模型的识别准确率最高。

表3 KH-KELM 和其他优化算法识别准确率比较Tab.3 Comparison of recognition accuracy between KHKELM and other optimization algorithms
4 结语
本文在KELM 的基础上提出基于磷虾群优化的KELM 模型对鸟类声音进行识别与分类。通过MFCC 算法提取30 种上海周边常栖息鸟类的声音信号的差异较明显的12 阶特征参数作为待分类识别的鸟类特征参数,建立KH-KELM 分类模型,即通过KHA 迭代优化核函数极限学习机的惩罚系数和核函数宽度参数,提高模型泛化性能和分类准确率。分析实验结果可知:与ELM、BP、SVM 和KELM 分类模型相比,KH-KELM 分类模型能够快速完成学习任务,且分类效果最好,准确率最高;与基于GA、PSO、ACO 优化KELM 分类模型相比,KH-KELM 分类模型的优化效果最好。从5 类扩展到30 类,KH-KELM 模型具有较明显的优越性和稳定性,其分类效果能满足对鸟类声音识别分类的预期效果。在今后的研究中,会对鸟类声音的特征因素更多的研究和提取,并继续优化分类模型的识别效果和算法的稳定性,使得更好的应用于大自然生物多样性监测。
