基于BERT和DBSCAN工程项目维保文本数据挖掘
2023-09-27胡学聪
胡学聪
(上海中建东孚投资发展有限公司上海公司,上海 150000)
国内建筑开发公司通过引入明源等系统,采用运维工单的方式记录住宅交付及使用过程中业主的投诉及建议。传统维保工单长度在200字符以内,属于典型的非规范性口语化的文本。同时由于投诉的原因无法事先确定,系统往往通过记录投诉位置来将信息进行分类,由专业客服人员对具体投诉事项进行分析,并派发至维保人员。该人工方式耗时较多,并依赖于客服人员的专业素养。在建筑集中交付前后,维保问题大量上报时,时效性较低,拉长客户的等待时间,容易造成舆情和群诉现象。
自然语言处理(natural language processing,NLP)[1]是计算机科学领域与人工智能领域中的一个重要方向。通过对自然语言的处理,使得计算机可以理解它,并将其可量化为各类具体数据。文献[2]梳理了NLP技术建筑方面的运用情况,发现在施工安全和合同管理方面研究较多,运维管理阶段研究较少。文献[3]通过引入图像分类领域的卷积神经网络(Convolutional Neural Network,CNN)模型完成建筑质量问题的分类,但CNN属于有监督学习,需要利用大量已知分类数据训练模型,同时CNN的卷积和池化操作会丢失词汇顺序和位置信息。文献[4]通过Word2vec算法模型提取建筑维保文本词向量特征,利用分类支持向量机(Support Vector Classification,SVC)完成文本分类,但该方法分类精度对模型参数敏感,同时需要对数据复杂的预处理。
为解决上诉问题,通过词频-逆文档频率[5](Term Frequency-Inverse Document Frequency,TF-IDF)和具有噪声的基于密度的聚类方法[6](Density-Based Spatial Clustering of Applications with Noise,DBSCAN)搭建文本粗分类器,根据破坏原因对维保文本进行分类,解决原始数据无标签的问题。将粗分类好的文本作为训练集微调预训练语言表征模型[7](Bidirectional Encoder Representation from Transformers,BERT),利用微调后的BERT模型作为细分类器,完成剩余维保文本分类。
1 相关研究方法介绍
TF-IDF是一种常用于文本处理的统计方法,由词频(Term Frequency,TF)和逆文档频率(Inverse Document Frequency,IDF)两部分的得分构成,TF通过计算特定关键词在文本中出现的频率。其定义为
式中,nij表示关键词W在某个文件中出现的次数;∑knkj表示文件中所有此条数目的总和。
IDF计算包含某关键词W的文档总数,如果包含词条t的文档越少,IDF越大,则说明词条具有很好的类别区分能力。其定义为
式中,|D|表示预料库中文档总数;|{j:t1∈dj}|+1表示包含关键词W的文件数目加1。
TF-IDF值即为两者得分相乘
TFIDF=TFij*IDFi
词袋模型(Bag of Words,BoW)是一种将文本向量化的方式,基本思想是将预料库中所有词去重后装在袋子中,对应的文本可以转化为对应词在词袋中位置的向量表示。
DBSCAN不同于传统的K-均值聚类(K-means)等算法,无需预先指定簇数K,对任意形状的类可以达到较好的聚类效果,仅需预先给定E邻域阈值(eps)和核心对象最小数量(min Pts)。若有大于min Pts个数量的样本点与某一样本点的距离小于eps时,称该样本点为核心点(Core)。若某一样本点不满足成为核心点条件,但距离内至少有一个核心点,则称该样本点为边界点(Border)。若都不满足则称该样本点为噪声点(Noise),如图1所示,eps和min Pts两个参数共同决定了聚类的簇数,当取值较小时簇数较多,每个类别中样本点数量少;当取值较大时簇数较少,每个类别中样本点的数量多。
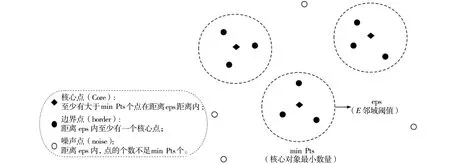
图1 DBSCAN算法图解
BERT是由Google在2018年论文提出的预训练语言表征模型。该模型以大量无标注的文本作为训练材料,通过完形填空(Masked Language Model)和下个句子预测(Next Sentence Prediction)两个任务预训练模型,让BERT模型可以学习到词元(Token)之间的相关关系,最终在11项自然语言处理任务中创造了最佳的记录。
BERT模型的架构是由多个Transformer模型[8]的编码器(Encoder)堆叠而成,通过针对特定的问题添加输出层微调(Finetune)。在BERT模型的输入中,通过词元嵌入张量(Token Em bedding)、语句分块张量(Segment Em bedding)、位置编码张量(Position Em bedding)3部分将文本编码向量化。
2 本文方法
为充分利用数据资源,本文提出了一种基于TF-IDF、DBSCAN和BERT的文本分类挖掘方案,通过TF-IDF和DBSCAN构成的粗分类器将短文本聚类划分,利用特征明显的聚类结果作为样本微调BERT模型,并利用微调好的BERT模型处理在粗分类阶段无法聚类的短文本,该方法的具体流程如图2所示。
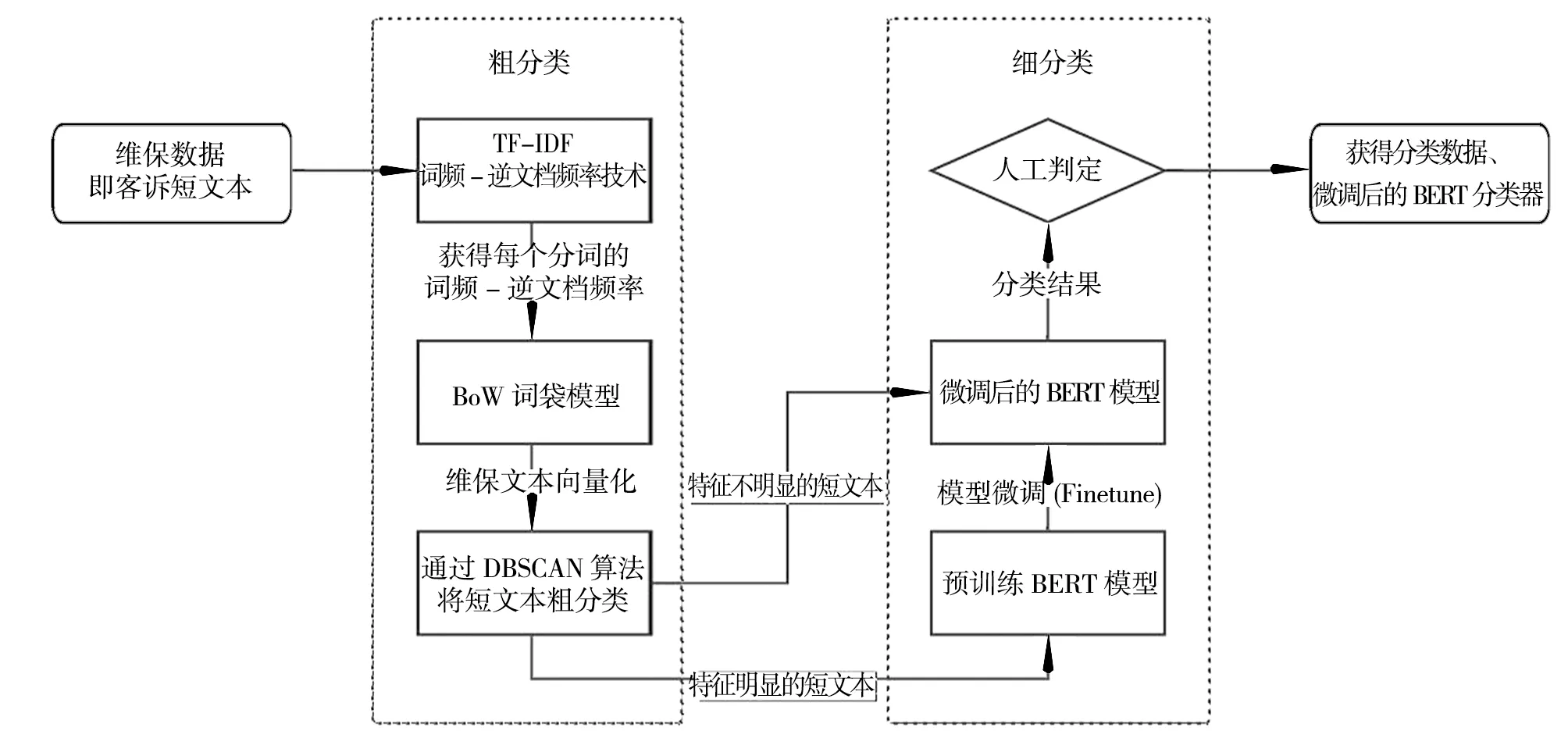
图2 基于DBSCAN和BERT的文本分类流程图
3 案例验证
以某公司上海地区项目为例对本文方法进行验证。通过分析该项目维保数据可知,截止目前报修问题共有6 203条,共涉及100处构件。为方便对比,将各构件按报修频率从大到小排序并编号为1至100,所有构件的累计报修频次占比结果如图3所示,前20处构件报修问题累计占比77.35%。
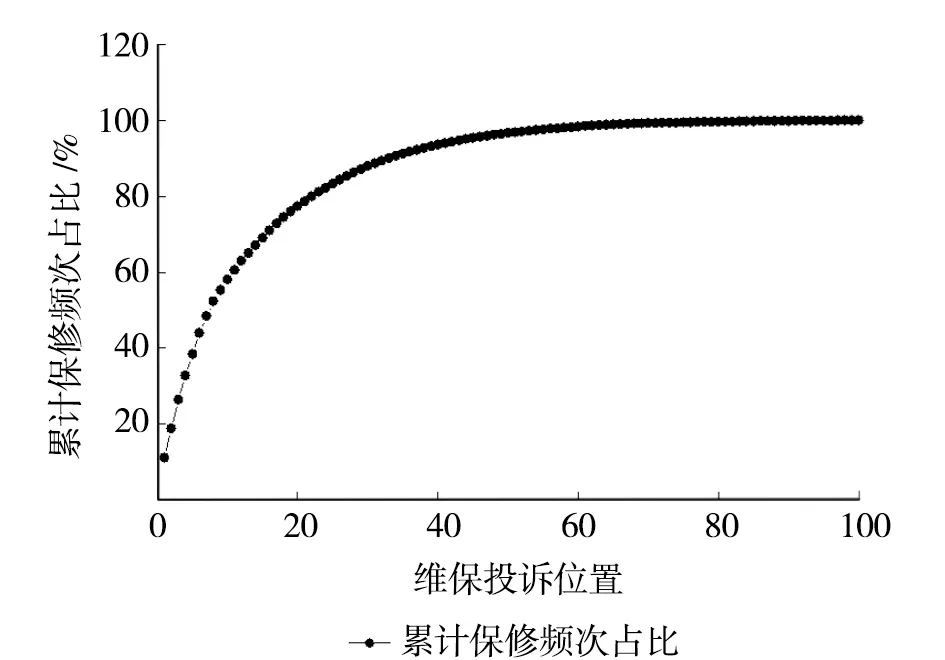
图3 各位置报修频次占比
以报修频次最多的1号构件“户内门”为例,该类别下共有报修文本720条。
3.1 粗分类
TF-IDF文本粗分类为:通过Python的中文第三方分词库jiaba,将短文本划分为独立的词元,并去除无意义的停用词如:“一个、一直、诶、啊、¥、@”等(停用词库采用了哈工大停用词表[9])。计算每个词的逆文档频率,通过one-hot编码将段文本转化为固定长度的数值向量。
通过对720条户内门报修文本分词,可以得到由418个有效的词元构成的词元表(Word-List)和每个有效词元的TF-IDF值。例如,原维保文本“门套线拼缝不齐;南次卧门破损,划痕”,通过jieba分词可划分为“门套/拼缝/不齐/南次/卧门/破损/划痕”,每个有效词元在词元表中的位置及TF-IDF值如表1所示。

表1 案例维保文本TF-IDF结果
通过BoW模型将每条维保文本都转化为固定长度的向量,便于后续聚类计算,向量长度为词元表内词元的数量。例如原维保文本“门套线拼缝不齐;南次卧门破损,划痕”被向量化成长度418的向量,除词元表对应序号位置的数为对应的TF-IDF值,其余位置均为0。
通过DBSCAN算法对向量化的报修短文本聚类,因BoW模型在向量化文本数据时仅考虑词元出现的频率,无法考虑词元含义之间的相关关系,因此本文建议设定较小的eps值和min Pts值,再人为判定聚类结果间各簇的含义,将相同含义的簇人工合并到相同类别。
在兼顾聚类效果和人工判别效率的基础上,本文推荐设定eps值为0.95,min Pts值为5,根据计算可将文本粗略分为12类报修原因(11类有效分类,1类噪音文本),具体聚类结果如表2所示。
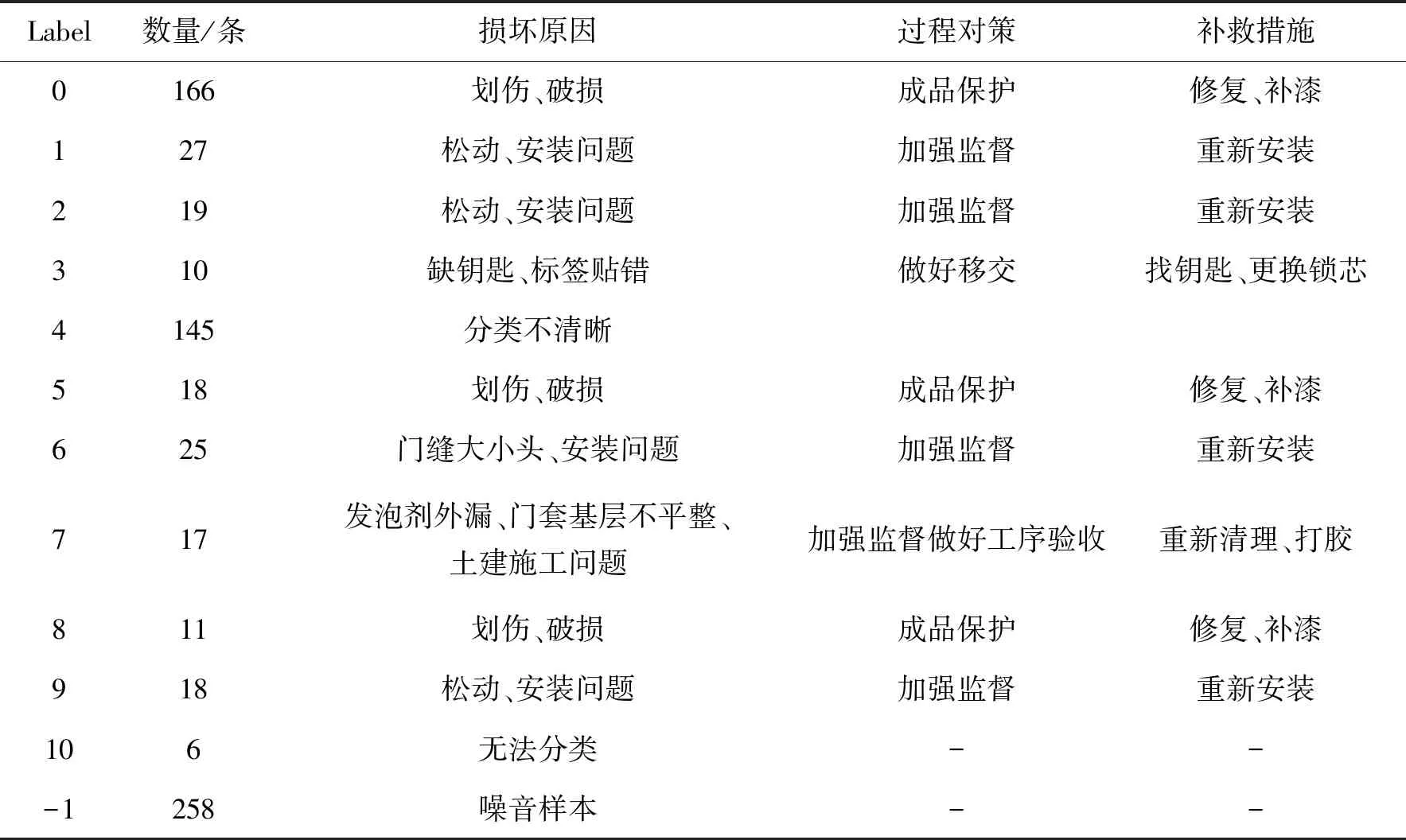
表2 维保文本粗聚类结果
可见在原720条维保文本中,label为0、1、2、3、5、6、7、8、9、10的317条文本聚类较好,有明显的损坏含义。label为-1、4的403条文本聚类效果较差。根据损坏含义重新组织文本,划分为6类不同的损坏类型并用作训练数据,1类待分类数据,如表3所示。
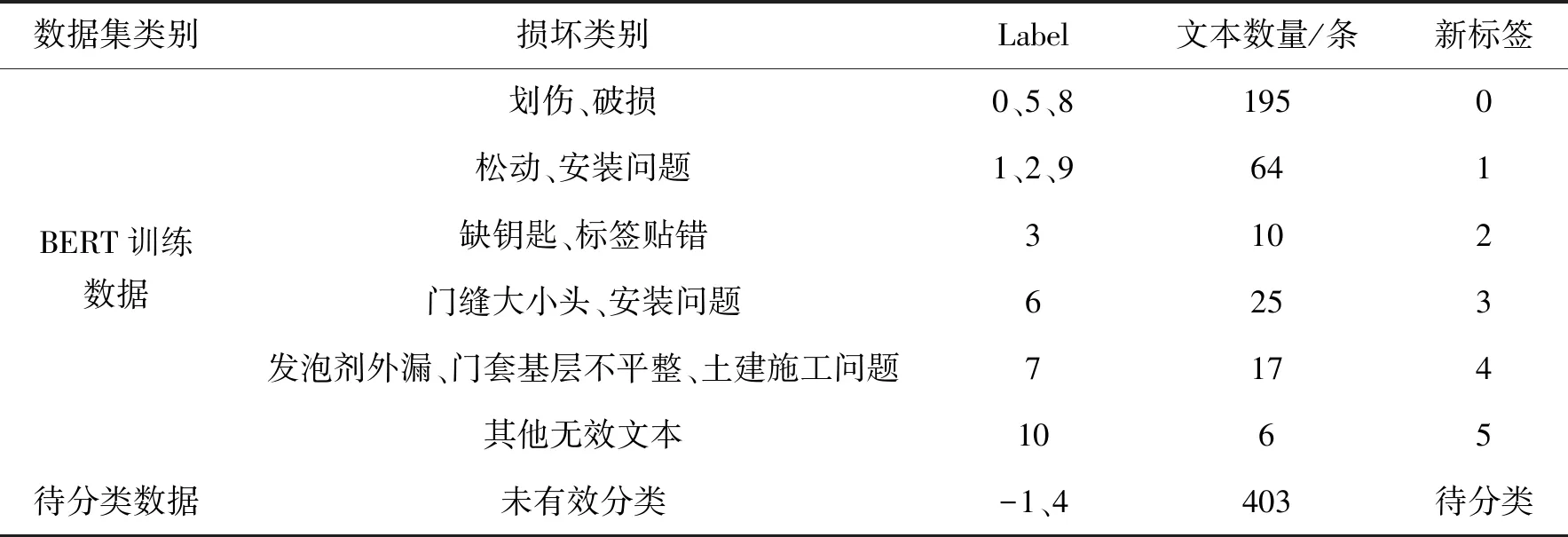
表3 按损坏类别分类重划分维保文本
3.2 细分类
将6类不同的损坏类型数据根据类别比例随机抽样,将80%的文本当作训练集,20%的文本当作测试集。通过pytorch搭建模型,预训练BERT模型采用哈工大讯飞联合实验室推出的“BERT-wwm”[10],因本项任务接近句对匹配,学习率(Learning Rate,LR)设置为模型推荐的最优学习率2×10-5,考虑到计算机性能限制每批次训练数量(Batch_size)设置为64。
随机抽取一条待分类的数据:划伤、掉漆;门吸松动,门不平整,外墙滴水槽不通,清理打胶收口,窗户开起其打胶。可以看出,该投诉文本同时包含多项标签,因此是一个多标签分类的任务。将BERT输出的结果通过全连接方式连接到由6个二元分类神经元构成的线型输出层,选择sigmoid函数,损失函数选择二元交叉熵损失函数。通过观察训练集数据分布可知,数据的类别不平衡(class imbalance),常用的方法有[11]:①对数据量较多的类别进行欠采样;②对较少的类别进行过采样;③阈值调整。前两种方案会对数据的分布产生影响,因此本文采用第三种方式,通过绘制ROC曲线,计算最优阈值(Threshold)[12]。模型评价指标选择loss评价训练集中预测值与实际值的偏离程度,准确率计算测试集中预测正确的标签数目,最终结果如图4所示,可以看到BERT的分类结果收敛程度较好。将每个神经网络输出分类视为二分类,分别绘制ROC曲线,计算对应的AUC值和最优阈值th-optimal,计算结果如图5所示,调整后各标签阈值如表4所示。
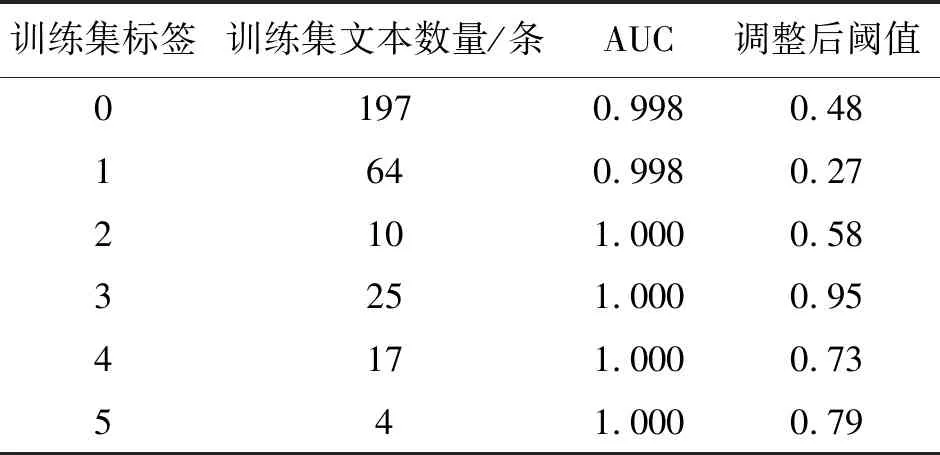
表4 调整后各标签阈值
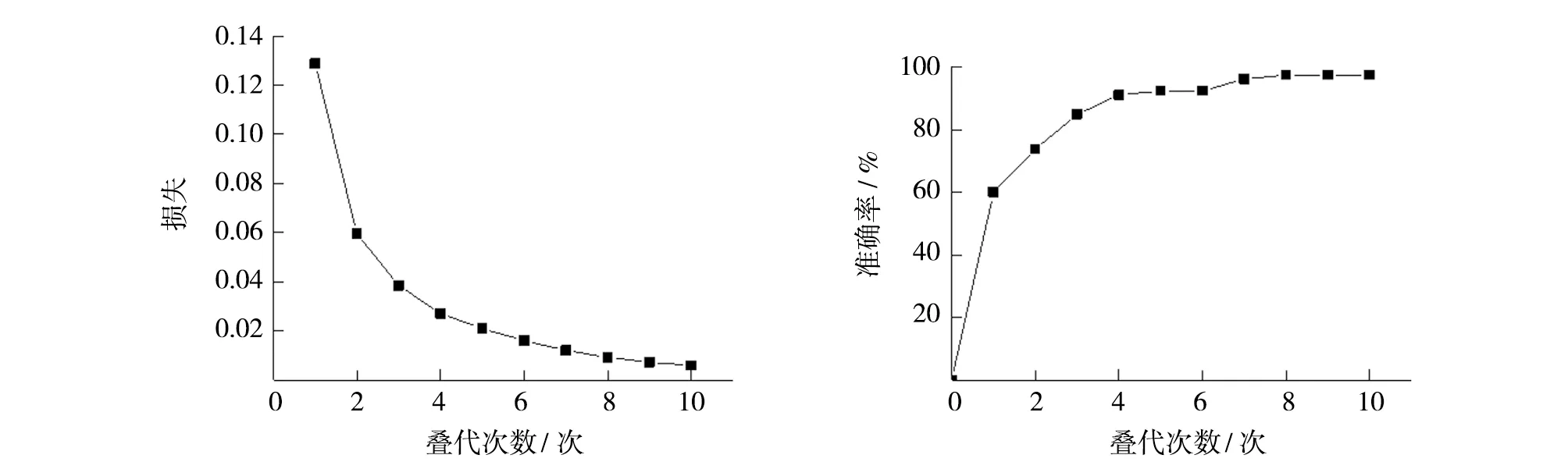
(a)损失值 (b)准确率
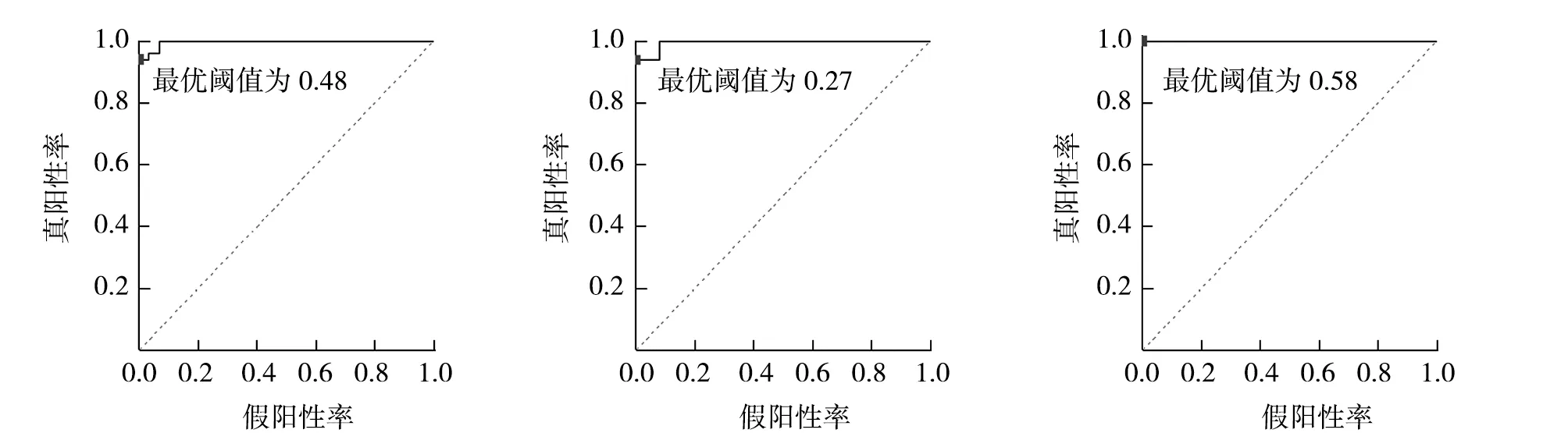
(a) label-0 (b)label-1 (c) label-2
将微调好的BERT模型和调整后阈值作为多标签分类器,划分待分类的403条数据,分类具体结果如表5所示。

表5 每类标签内文本数量
4 结论与展望
入户门类别下原始无标签文本720条,通过粗分类器后有效分类317条,有效分类率44.03%,通过细分类器后累计有效分类文本603条,累计有效分类率83.75%。
虽然本文提到的方案可以有效完成文本分类、特征提取,但依然存在部分局限:
(1)初始的分类划分依赖于DBSCAN算法的聚类,该分类器通过关键词和词频分类文本,建议选择较小的eps和min Pts值,通过人工合并同类关键词,让BERT模型可有效学习到不同敏感词之间的相关关系;
(2)通过TF-IDF方案粗聚类效果仅考虑了关键词的重要性,建议通过大量的无标签行业内维保语料,进行BERT的无监督预训练,根据相关研究文本[13]的表层信息如句子长度、词元等在Encoder的浅层进行输出,词元顺序、语法等在Encoder的中间层进行输出,时态、动名词、主语等信息在Encoder顶层进行输出,推荐采用预训练BERT模型的第4、第6、第9层Encoder的输出文本作为特征进行文本聚类。
