随机森林算法在钓鱼网站检测中的应用
2023-09-25毛红梅张胜
毛红梅 张胜

关键词:钓鱼网站检测;随机森林;网站特征;模型参数优化
0 引言
以淘宝、京东为代表的电子商务平台和以支付宝、微信为主的网络支付方式的高速发展,使得人们的生活方式尤其是消费方式发生了显著变化。网购和支付方式变得越来越普遍化和简单化,但随之而来的网络风险日益严峻。网络钓鱼者经常模仿一些购物网站、银行官方网站、教育网站等常见网站,窃取网络用户账户信息,获取非法利益。
目前,常见的钓鱼网站检测方法主要有:1) 基于浏览器的黑名单列表匹配,通过建立钓鱼网站黑名单列表与待检测网站相匹配,如匹配成功,则检测为钓鱼网站并实施拦截,否则需做进一步判断。该方法检测准确率低,需要较多的人工参与;2) 基于异常特征的检测方法,利用网站地址的一些异常特征来实现钓鱼网站检测,这种方法检测效果优于第一种,能够自动检测未知网站,但是易于出现检测误判;3) 基于网站内容的检测方法[1],通过比对待检测网站与合法网站内容相似度来判断网站属性,这类方法检测准确度较高,但是难以实现,且网站检测不全面。
通过研究,本文提出了结合网站重要特征使用随机森林方法对钓鱼网站进行检测。该方法检测准确度高,实际应用范围广,自动化程度高,能够极大地减少人工参与。
1 随机森林介绍及网站检测流程
1.1 随机森林介绍
随机森林[2]是一种由多颗决策树构成后决策的提升方法。随机森林的构造过程是:首先,随机从原始数据集抽取(有放回的)与原始数据集容量相同的数据,构成子数据集;其次,随机从原始特征中选择一些特征,之后再在这些随机选取的特征中选择最优的分裂特征,利用随机选取的子数据集和随机选择的特征构造单颗子决策树,重复以上过程构造多颗决策子树,从而形成随机森林。随机森林分类结果取决于决策子树的输出,一般采用多数投票规则输出分类结果。
1.2 钓鱼网站检测流程
使用随机森林方法检测钓鱼网站,检测效率高,分类效果明显高于单一分类决策方法。实验具体检测流程如下:
1) 提取实验给定的网站数据集特征,经过初始特征数据集预处理,特征选择,PCA(Principal ComponentAnalysis) 降维和交叉验证,得到处理后的训练特征集和测试特征集。
2) 结合训练特征集与三种基础的机器学习算法模型,验证实验测试特征集,检测未知网站类别。
3) 使用随机森林方法检测未知网站类别,并将其与前面三种方法的分类效果进行对比。
4) 优化随机森林算法模型关键参数,对比不同参数值在实验数据集上的分类效果和未知网站检测准确率。
2 基于随机森林方法的钓鱼网站检测
2.1 网站特征
分析实验数据集和钓鱼网站与合法网站之间的域名区别,总结出关于网站域名的12个主要特征,具体特征如下:
1) 域名年龄:钓鱼网站域名注册时间短,域名年龄较小;
2) 网站排名:钓鱼网站访问量小,网站排名靠后;
3) 敏感词:钓鱼网站网址中常常会包含账户(ac?count)、登录(login)、银行(bank)、安全(security)等词汇,而这些词汇极易联系到虚假诈骗;
4) IP地址:一些钓鱼网站域名中包含IP地址,掩盖真实域名;
5) 顶级域名:常见的顶级域名数量有限,可以枚举出来,而一些钓鱼网站中的顶级域名往往不在枚举列表中;
6) 域名长度和网址长度:钓鱼网站地址或者域名往往較长;
7) 子域名数量:合法网站除了真正域名外,子域名个数不会超过2,二级网站中子域名数量也只有1个;
8) 四种特殊字符:“@”“ -”“ ; ”“ //”,钓鱼网址或者域名中的特征字符常常用来迷惑大意的用户,使网页重定向至钓鱼页面,而钓鱼网站的网址中一般会包含四种特殊字符中的一种。
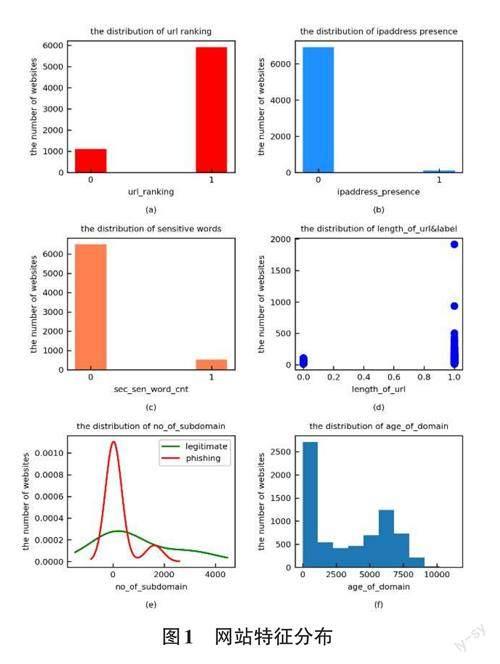
实验钓鱼网站数据集来源于phishingtank,合法网站数据集来自互联网,实验数据集总共7029个。实验中运用python以及常见的数据分析包 (包括numpy、pandas和matplotlib)编程提取这些重要特征。其中,网站排名特征、IP地址特征、敏感词特征、网址长度、子域名数量特征和域名特征分布如图1所示。(建议图1中的x, y轴标题及图标题均用中文给出,并在本段给出简单的解释)
2.2 实验设计与结果分析
提取网站初始特征集,经过特征标准化预处理;以L1惩罚项的逻辑回归作为基模型的集成法和输出,以(建议给出具体的方法或概念)作为分类模型的特征,重要比例两种特征选择[3-4]方法相结合;采用PCA进行降维处理和交叉验证方法[5]处理;最后运用训练特征集去训练随机森林模型,将训练好的模型用于验证测试特征集和检测未知网站类别。
使用随机森林模型分类未知网站(例如:http://sourcepage-paypal. dojofit. si/webapps-account/2a0b4/websrc) ,得到未知网站特征数据,表1是对某网站进行分析得到的特征数据。对该网站分类其输出结果为钓鱼网站,检测结果如图2所示。
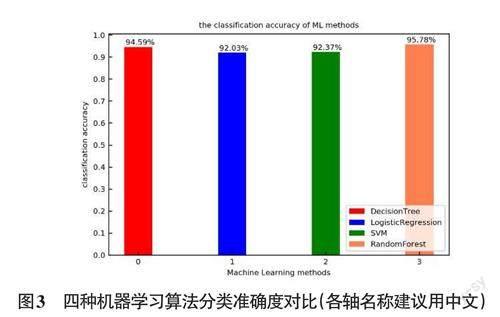
图3是采用随机森林模型、决策树、逻辑回归和支持向量机对实验数据集进行分类的结果。该结果显示:随机森林模型初始分类准确度达95.87%,高于决策树、逻辑回归和支持向量机。
2.3 随机森林模型参数优化
实验中通过调节随机森林模型参数(分类器个数和最大特征数),对比不同参数值对模型分类准确度的影响,同时采用查准率、召回率和F1值三种度量评价不同参数下模型分类的效果。实验中固定分类器的个数大小,调节参数最大特征数,输出对应的三种评价度量值。其中,表2为分类器个数分别为10,20,50时,不同最大特征数的模型度量对比,表3为分类器个数分别为70,100,1200时,不同最大特征数的模型度量对比。
实验结果显示:随机森林模型参数分类器个数和最大特征数分别为120和sqrt时,模型分类效果最佳,优化后的模型分类准确度最高达96.63%,显著地高于初始模型分类准确性(最佳结果建议加粗显示)。
3 结束语
本文提出的提取网站复杂特征与随机森林方法相结合的检测方法,检测未知网站准确,智能化程度高,应用广泛广,可以嵌入web浏览器中,替代基于黑名单列表的识别方法,实现对钓鱼网站的自动检测和拦截。然而,受实验数据量和特征数量的限制,实验中随机森林模型的分类准确度并没有达到最佳,后续需要进一步提取更为细致的、效果显著的特征和改进相应的算法,使得算法检测钓鱼网站准确度更高。
