基于改进的三维卷积神经网络的动作识别
2023-09-25刘岩石张君秋李溶真刘贵锁赵建光
刘岩石 张君秋 李溶真 刘贵锁 赵建光


关键词:卷积神经网络;3D CNN;残差网络; 双流网络;动作识别
0 引言
近年来,计算机视觉领域在人体动作识别方面的研究进展迅速。传统的特征提取方式逐漸被基于深度学习的神经网络识别方法所取代。传统方式主要依靠人体几何信息、运动信息、时空兴趣点信息等提取特征来完成动作识别。人体几何特征可以通过人体四肢关系或光流场进行提取,运动信息特征可以通过运动历史图像或运动能量图像等进行提取,提取时空兴趣点特征可以利用Harris3D 时空兴趣点、SURF3D时空兴趣点、HOG3D时空兴趣点等方式。
因为深度学习的飞速发展和大规模视频数据集的出现,采用深度学习的方法进行人体行为识别被科研人员重视起来,很多使用深度学习方法的模型被开发出来。由于深度学习的算法能够实现端到端的训练,可以自己从海量的数据集中学习相同的特征,因此利用深度学习来进行行为动作的识别会具有更好的泛化能力,具有比传统方法更好的识别效果。
当下得益于计算机软硬件的飞速发展,建立一套智能的人体动作识别系统的条件已经越来越成熟。智能的人体动作识别系统应用场景非常广泛,如果能够得到较好的使用,将极大地提高目前视频监控系统的质量,节约大量的安保力量和经费支出。
1 相关研究
为了实现视频中人体动作的识别,最主要的是从图片序列中提取特征。在传统人体动作识别方法中,主要有两种特征提取的方法:全局特征提取以及局部特征提取。全局特征提取方法可以看作是一种自上而下的方法,这种方法通常是通过背景减图或者是对运动目标的跟踪最终实现对人体的检测,然后对检测出来的人体目标进行编码,从而形成全局的特征。局部特征提取的方法是一种自下而上的方法,这种方法首先对视频中感兴趣点的特征进行提取,然后再提取这些点旁边的图像,最终将这些信息融合在一起从而表征某个特定的动作。
Davis等人[1]是最先使用全局特征提取方法来实现人体动作识别的。在他们的研究中提出了著名的MEI(运动能量图像)和MHI(运动历史图像)[2],其中MEI用来标识运动发生的位置,MHI既能标识运动发生的空间位置也能标识运动发生的时间顺序。Li等人[3]提出一种超图内聚类搜索算法,同时进行多人跟踪与行为识别。包括单人行为识别,成对交互关系识别和群组行为识别。Deng等人[4]提出一种基于概率图模型的深度神经网络结构,用于分析养老院走廊和食堂中是否有老人跌倒的情况。Ramanathan等人提出一种基于注意力机制的群组行为识别方法,通过检测活动场景中每个人的动作,为每个人分配不同权重,并重点关注 活动中的关键人物,使用LSTM网络捕获关键人物的时序信息,最后对群组行为进行识别。Vahora等人[5]提出一种基于关系内容的学习模型,采用自下而上的方法从活动场景中依次学习单人行为和群组行为。底层采用CNN提取场景中每个人的动作特征;高层采用RNN模型捕获时间信息;最后通过一个推断机制进行群组行为识别。Singh等人[6]提出一种基于Scatter Net的混合深度学习网络模型,用于分析无人机拍摄视频中的暴力行为。
当前基于神经网络的人体动作识别技术主要包括双流网络[7]、LSTM以及3D卷积网络[8]等,本文通过对3D卷积核进行修改,改善网络结构来保证准确率和提升运算效率。
2 理论方法
针对目前所存在的问题,我们提出了一种改进的三维卷积神经网络融合的动作识别新算法。该网络结构由拆分后的三维卷积网络模型分为时间数据流和空间数据流架构组成。其网络结构如图1所示。
2.1 改进的3D 卷积神经网络
二维的卷积网络更适用于提取空间维度的特征,三维卷积虽然增加了对视频连续帧中时序信息的卷积操作,但是导致了神经网络模型参数较2D成倍增加,训练时间加长。本文将大小为h×t×w 的3D卷积核拆分成了1×h×w 和t×1×1的卷积核,其中h和w分别代表卷积核的高和宽,t为时间维度,这样就分别提取了二维图像的空间特征和多帧视频流的时间信息,再将二者特征进行融合来完成分类预测。双流网络是基于深度学习的行为识别算法中的三种主流算法之一,根据视频的时空信息,将网络分为空间流和时间流两个分支。相较传统的3D CNN,本文改进后的网络模型借鉴双流卷积网络结构,将单流向的网络框架拆分为空间域和时间域。空间域参考ResNet网络及其Bottleneck结构的设计思想,采用1×1×1和1×3×3 的卷积核,时间域采用3×1×1的卷积核,然后相加进行特征融合。
网络的基本结构如图2所示,采用1×1×1和1×3×3的卷积核处理空间信息,采用3×1×1的卷积核处理时序信息,对视频流进行卷积,然后送入池化层采用最大池化并保留图片的纹理,将二者相加进行特征融合后分别送入下一层网络。
调整后的网络参数数量为1×3×3+1×1×1+1×1×1=11,改进前的参数数量为3×3×3=27,参数量减少了59.3%。可见,改进后的网络模型训练参数量得到大幅减少,加快了神经网络的运算速度。
2.2 网络模型框架
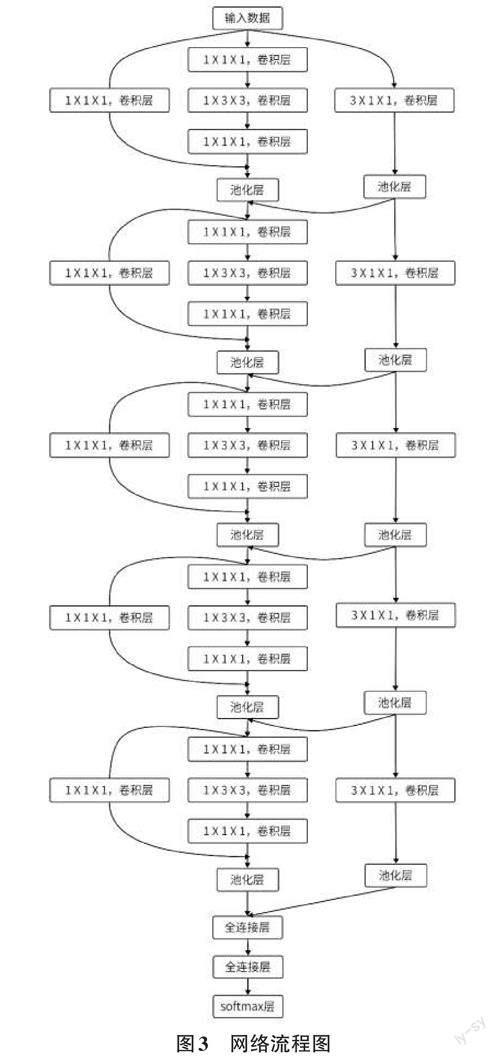
网络流程图如图3所示,图中有5个基础卷积结构以及两个全连接层,最后用softmax做分类预测。
网络模型流程说明:
1) 数据预处理过程中对每个视频取16帧,每帧图像尺寸设置为48×48。处理后生成16×48×48×3的数据大小作为数据输入。
2) 空间数据流采用1×1×1、1×3×3、1×1×1的3D卷积核卷积,并使用1×1×1的卷积核作为残差结构,输入数据经首个1×1×1的卷积核后生成个数为32的特征图,经后两个卷积核特征图的个数保持不变。时间数据流采用3×1×1的三维卷积核。之后各自经过尺寸为1×2×2,步长为1×2×2的池化层,时间维度仍保持为16帧,生成16×24×24×32大小的输出。之后将两个数据流输出相加作为下一层基础卷积结构空间流的输入,时间流输出作为下一层基础卷积结构时间流的输入。
3) 后四个网络基础结构使用相同的空间流+时间流卷积和ResNet结构,卷积后的特征图数量从32依次上升为64、128、256、512。使用尺寸为1×1×1,步长为2×2×2 的池化层进行最大池化,降低了空间分辨率,同时使时间维度的数据量减半,最终输出数据维度为1×2×2×512。随后进行数据平坦化,生成一维数据后输入到两层节点数为2 048的全连接层,每个全连接层后使用dropout随机丢弃部分参数防止网络过拟合,最后利用softmax层完成分类预测。
3 实验
3.1 数据集
为了验证该网络模型的有效性,本文选用的行为识别数据集为UCF101,对数据进行打乱后选取其中的70%作为训练集,其余部分作为测试集。UCF101 数据集内含13 320个短视频,视频来源为YouTube,视频背景存在杂波、相机抖动、部分遮挡等;视频种类有101种,主要包含人和物体交互、只有肢体动作、人与人交互、玩音乐器材和各类运动5大类动作。
3.2 实验环境及参数设置
实验中的硬件环境如表1所示。
网络训练采用小批量样本迭代的方式,由于考虑到显卡的性能以及收敛速度等多方面的因素影响,设置mini-batch值为36,Relu作为激活函数,迭代轮数大小为1000,偏置初始化为0.01。网络模型训练参数设置详见表2。
3.3 学习率的选取
本文选取了0.0001、0.0002、0.0003三种学习率进行实验,预测准确值如图四所示,当学习率选用0.0001时,模型损失率的震荡频率更低,收敛速度更快,准确率的上升更早。选用0.0002和0.0003的学习率时,前期收敛较慢,需要更多次的迭代。为加快网络训练速度,选用0.0001作为初始的学习率。
3.4 评价
为了能直观地展示本文算法的优势,与目前在行为识别领域先进的深度学习算法进行了比较,Top-1 精度和Top-5 精度通常用于评价行为识别模型。Top-1准确性是指模型预测得分最高的类别与实际类别一致的准确性,Top-5是指模型预测得分的前5个类别包含实际结果的准确性。表3比较了UCF101数据集上各种行为识别算法的Top-1精度。可见,本文的方法在一定程度上取得了更好的识别效果。
4 结论
本文研究了基于改进的三维卷积神经网络的动作识别算法。首先对视频数据进行预处理,分别进行空间维度和时间维度的卷积操作,同时引入残差网络,最后在UCF101行为识别数据集上进行验证并对模型进行了评估,实验表明,該方法具有较好的识别效果并大幅降低了训练周期。
虽然动作识别目前已经取得了一定的研究成果,但仍没有非常成熟的识别框架。由于样本差异性和实际应用复杂性等因素,本文提出的方法尚难以应用于生产生活的实际场景。下一步工作将采用更多数据集进行网络优化,提高网络识别效果,使研究可以在多种实际场景中得到应用。
