带有注意力机制的OCTA视网膜血管分割方法
2023-09-25崔少国张宇楠唐艺菠
崔少国,文 浩,张宇楠,唐艺菠,杜 兴
重庆师范大学计算机与信息科学学院,重庆401331
现代医学中,眼睛对人类的重要性不言而喻。而各种视网膜疾病也成为一个不可忽视的问题。医学影像分割是智能辅助诊断过程中一个重要的处理步骤,它能帮助医生进行以图像为指引的医学干预或更有效的放射科诊断等。在临床医学应用中,视网膜血管提取技术[1]通过对视网膜血管进行一系列的分析,能够辅助医生诊断患者是否患有眼部相关疾病和高血压或糖尿病等一系列疾病。光学相干断层扫描成像(optical coherence tomography angiography,OCTA)是建立在光学相干断层扫描(optical toherence tomography,OCT)上的一种崭新的成像模态,是一种新兴的非侵入式成像技术,能观察不同视网膜层的血管信息。因此,OCTA 逐渐成为眼底相关疾病观测的重要工具之一。但人工手动分割的方法成本高昂,费时费力,分割质量与操作者自身的从业水平息息相关,受主观因素影像较大,效率较低。因此,随着日常眼科疾病患者数量的急剧上升,提出一种高效的视网膜血管分割方法[2]已经迫在眉睫。
近年来,通过组合低层特征进而形成抽象的深层特征,卷积神经网络[3-4]能更好地完成各类视觉任务。深度学习[5]通过从数据中学习的方式去解决各类问题,早期的医学图像分割算法以全卷积神经网络(fully convolutional networks,FCN)[6]为核心,旨在重点解决如何更好地从卷积下采样中恢复丢掉的信息损失。后来的医学图像分割算法逐渐发展为以下三类:首先是以U-net为代表的U形“编解码对称”结构设计[7-8];其次是以DeepLab[9]为代表的引入空洞卷积的设计;最后是基于Transformer编码器中Self-Attention自注意力结构的设计[10-11]。视网膜血管数据集普遍存在样本数量较少的特点,而基于自注意力计算的分割网络和DeepLab 系列都需要大量的数据进行训练才能达到较好的分割结果,只有U-net在数据集样本数量较少的情况下也能取得不错的分割效果。
因此U-net 在医学图像分割领域得到了极大的关注,后来的研究者大多也是基于U-net进行改进的,如肖晓等人[12]通过在U-net 的基础上增加残差学习,提出的Res Unet针对血管细节特征的提取方式进行再优化,但同时也增加了模型的复杂度;周纵苇等人[13]提出的Unet++利用图像分割中的多尺度特征来重新设计跳跃链接达到提高分割质量的目的,并设计一种新的剪枝方案,加快推理的速度,但势必也会增加网络的深度和计算量;Valanarasu 等人[14]提出的Medical Transformer 在编解码器对称结构的基础上引入带门控的轴向注意力机制,并使用“局部全局”的训练策略进一步提高分割性能,但同时也需要大量的数据训练才能达到较好的效果,并且训练和推理时间较长。
而基于U-net改进的视网膜血管分割方法中[2],Fu等人[15]将条件随机场引入卷积神经网络(convolutional neural networks,CNN)中用于血管分割优化分割结果。Eladawi等人[16]将马尔可夫随机场和CNN相结合用于提升OCTA 视网膜血管分割的精度。Gu 等人[17]提出带有残差结构和空洞卷积的U 形网络用于血管分割并提高分割效果。Li 等人[18]提出一种图像投影网络(IPN),用于进行有效的特征选择和降维,实现3D输出到2D的端对端结构的OCTA血管分割。Wu等人[19]提出一种结合形态学特征的连通性分析算法,是用于消除噪声和伪影的OCTA 微血管算法。蒋芸等人[20]提出使用条件深度卷积生成对抗网络的方法对视网膜进行分割提高分割能力。Ma 等人[21]提出一种先分别分割粗血管和细血管,再将分割结果融合并优化最终分割结果的OCTA血管分割方法。Boudegga 等人[22]提出基于轻量级卷积块的U-net,并针对视网膜图像和血管特征提出预处理和数据增强步骤,提高分割效果。
视网膜血管末端细小、形状不规则、分布不均匀且易与背景混淆是导致用U-net及其改进对视网膜血管进行分割准确率下降的主要原因。然而U-net及其改进在增加模型复杂度的同时也增加了额外的计算量,所耗费的计算机资源较高,分割时间也相对较长。
针对上述问题,本文提出一种将深度可分离卷积和卷积块注意力机制相结合的视网膜血管分割算法。首先,用步长为2的卷积层来代替最大池化层进行特征选择。随后,在每个采样层中用深度可分离卷积代替常规的卷积进行特征学习的同时降低参数量。最后,添加一个轻量级高效的卷积块注意力加权模块,采用学习的方式获取特征图中通道信息和空间信息的重要程度,并且按照学习到的重要程度自适应地调整每个特征图的权重,完成对特征图的重新标定。最终本文方法更注重细微处的分割,提高了分割的精度,同时占用较少的计算资源。
1 本文方法
1.1 模型总述
本文以U-net 为基准模型,提出一种基于深度可分离卷积与卷积块注意力模块(convolutional block attention module,CBAM)的视网膜血管分割算法。在特征编码阶段,每层使用一个深度可分离卷积块进行特征提取,然后增加一个CBAM 模块,采用学习的方式获取每个特征图中通道信息和空间信息的重要程度,并且按照学习到的重要程度全自动自适应地调整每个特征图的权重,提高对模型存在积极影响参数的权值,降低对模型存在消极影响参数的权值,完成对特征图的重新标定,随后使用步长为2 的卷积层进行下采样缩小特征图大小。在特征解码阶段,编码阶段的高分辨率特征与上采样特征进行拼接,后接一个可分离卷积块和一个CBAM模块,在最后一层使用普通的卷积用于输出最后的预测图。模型采用双线插值对特征图进行上采样。同时,在卷积运算后都执行ReLU 函数使输出变为非线性。具体的结构图如图1所示。
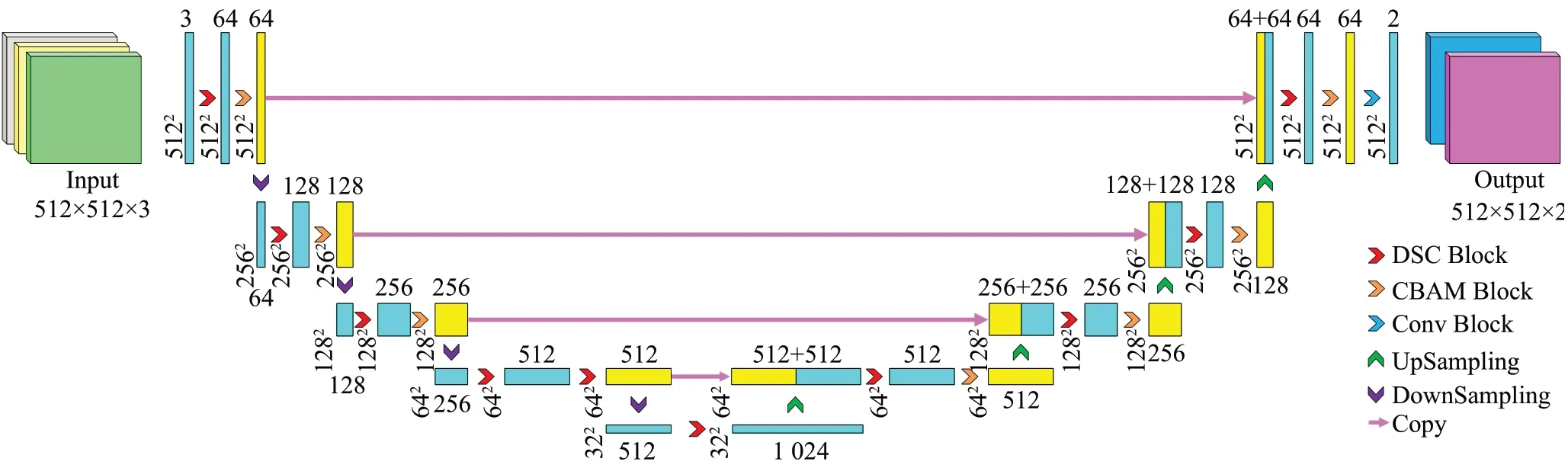
图1 本文方法结构图Fig.1 Architecture of proposed method
其中,网络输入的通道数为3,输出通道数为2,分别对应需要预测的两种类别,即划分为前景的视网膜血管区域和划分为背景的非血管区域。图中,DSC Block是深度可分离卷积块,CBAM Block 是CBAM 模块,Conv Block 是常规卷积块,UpSampling 是上采样层,DownSampling是下采样层,Copy是跳跃连接。
1.2 去池化的U-net
U-net是Ronneberger等人[23]提出的一种对称的网络结构,它的对称编解码结构和跳跃连接结构,将图像的高维特征与低维特征相结合,提高图像从小尺寸到大尺寸还原过程中填补缺失和空白值的能力,有助于提升网络模型进行像素级分类的能力。并且U-net 具有简单、灵活并且在中小型训练数据集上也能取得不错的分割效果等优点。
U-net中池化层主要有三个作用,分别是:增加卷积神经网络特征的平移不变性;池化层的降采样使得高层特征具有更大的感受野;池化层的逐点操作相比卷积层的加权和更有利于优化求解。但池化操作在跳格平移过程中势必会出现忽视或丢失细节特征等问题。由于OCTA-500分割数据集中视网膜血管并不是集中分布在视网膜血管图像的某一个区域中,而是不规则且不均匀的分布在整张图像中。如果采用池化操作势必会出现丢失部分区域的血管微小处的细节特征,从而导致Unet 不能精确分割。因此本文用步长为2 的卷积层代替池化层,可以将其视为是参数可训的池化层,有效地弥补了传统U-net分割过程中因池化操作而丢失细节特征的问题。让网络通过学习的方式自动选择哪些是分割过程中的冗杂无关信息需要被抛弃,哪些是血管的细节特征不能被抛弃。
1.3 深度可分离卷积
深度可分离卷积(depthwise separable convolutions)是Chollet等人[24]提出的一种卷积方式,如图2所示。卷积的主要作用是特征提取。常规卷积操作是实现通道和空间相关性的联合映射。而深度可分离卷积操作是将常规卷积操作分解为一个深度卷积加上一个逐点卷积的过程,使其在执行空间卷积的同时,并保持通道之间分离,然后按照深度方向进行卷积。
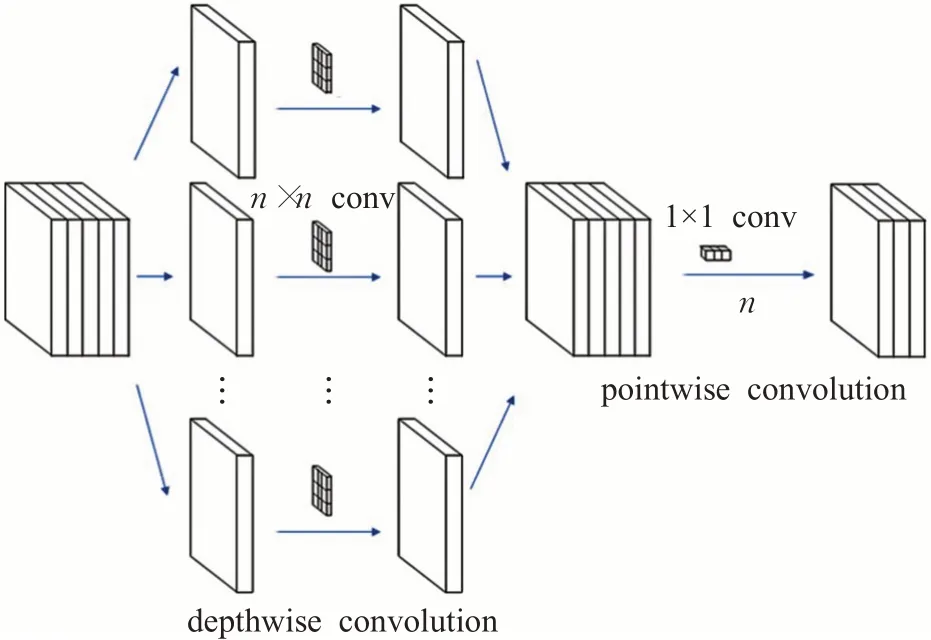
图2 深度可分离卷积结构图Fig.2 Deep separable convolutional architecture
与常规卷积操作相比,深度可分离卷积操作如图3所示,具有能降低计算复杂度,减少参数量等优点。深度可分离卷积分为逐通道卷积和逐点卷积先后两个步骤,分别如图4所示。

图3 常规卷积操作Fig.3 Normal convolution
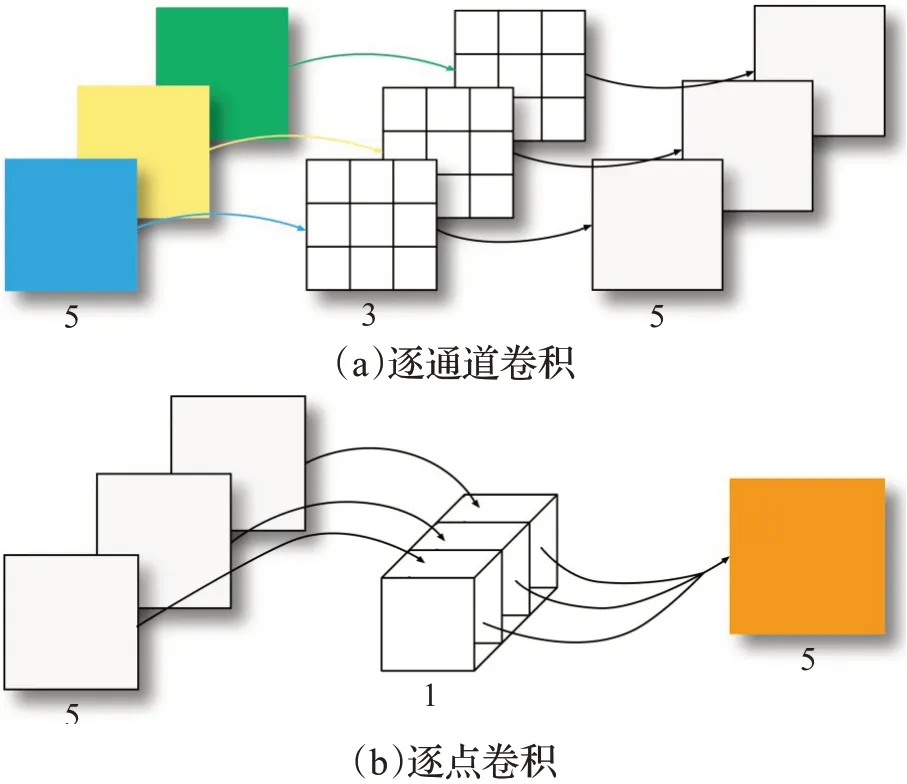
图4 逐通道卷积操作和逐点卷积操作Fig.4 Depthwise convolution and pointwise convolution
深度可分离卷积和常规卷积操作相比其扩宽了网络宽度的同时,也极大地减少了网络的参数量和降低了计算过程中所耗费的资源。已有实验证明深度可分离卷积能在保证任务精度的同时降低参数量[24-27]。由于OCTA-500 用于分割的数据集存在样本数量偏少的特点,所以深度可分离卷积操作和常规卷积操作相比,势必在降低网络参数量、计算复杂度的同时也能获得更好的学习效果。因此本文提出用深度可分离卷积操作代替U-net 每个采样层中的常规卷积操作,将每层中用于特征提取的两次常规卷积操作替换为一个深度可分离卷积块。
1.4 卷积块注意力机制
CBAM 模块是Woo 等人[28]提出,与Hu 等人[29]提出的通道注意力SE模块(squeeze-and-excitation block)相似,是一种简单且适用于卷积神经网络的通道空间注意力模块。虽然SE 模块对提升模型性能有效果,但是通常会忽略特征图的位置信息,而位置信息对于生成空间选择性特征图是非常重要的。CBAM 提取空间和通道重要信息并结合,它提出给定一个中间特征映射,沿着两个独立的维度即通道和空间顺序推断注意力映射,然后将注意力映射乘以输入特征映射以进行自适应特征细化。CBAM模块也适用于分割任务[30],该模块能够自适应的细化特征图的映射,关注重要的特征信息并抑制不重要的特征信息,提升分割性能,其结构如图5所示。

图5 CBAM块结构图Fig.5 CBAM block architecture
CBAM 模块是一个融合了两种注意力机制的轻量级通用模块,可以将其添加在任意网络的卷积层后面。该模块具体计算过程如以下公式所示:
其中,F表示特征图(C×H×W) 的输入,Mc是一维(C×1×1)的通道注意力图,Ms是二维(1×H×W)的空间注意力图,⊗表示乘法操作,F′是中间输出(C×H×W),F″是最终的输出(C×H×W) ,MLP 是多层感知机,AvgPool 是平均池化操作,MaxPool 是最大池化操作,σ是sigmoid激活函数,f7×7是卷积核大小为7×7 的卷积操作,[;]是通道维度的拼接操作。
图6是通道注意力子模块的操作过程,它比SE 模块多了一个全局最大池化,而池化操作本身是提取高层次特征,不同的池化意味着提取的高层次特征更加丰富。首先,通过平均池化和最大池化操作聚合一个特征图的空间信息,生成两个空间上下文描述符:AvgPool(F)和MaxPool(F),这两个描述符分别表示平均池化后的特征和最大池化后的特征。然后,这两个描述符被前向送入一个由二者共享的网络来生成通道注意力图。具有一个隐藏层的多层感知机组成了这个共享网络。每个空间上下文描述符经过共享网络处理之后,使用按位加法融合输出特征向量通过sigmoid激活后得到Mc(F),将其和原输入特征图相乘生成通道注意力特征F′作为通道注意力子模块的输出。

图6 通道注意力块Fig.6 Channel attention module
图7是空间注意力子模块的操作过程。该子模块将通道注意力子模块的输出特征图作为输入,首先完成基于通道的全局最大池化和全局平均池化操作,然后将这2 个结果基于通道进行拼接,合并成一个通道数为2的特征图,然后经过一个卷积核大小为7×7 的标准卷积层后变为1个通道。紧接着经过sigmoid激活生成空间注意力特征(spatial attention feature)Ms(F),最后将该特征和空间注意力子模块的输入特征做乘法,生成的特征图F″作为空间注意力子模块的输出,同时也是CBAM模块最终的输出。
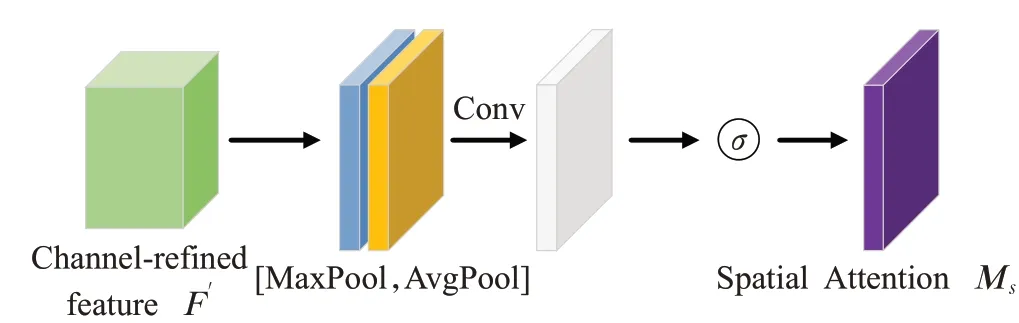
图7 空间注意力块Fig.7 Spatial attention module
CBAM 模块能以极小的计算代价实现放大特征图中对模型训练有利的参数的权重,缩小对模型不利的参数的权重,提取空间和通道重要信息并结合。由于OCTA-500中的视网膜血管图像普遍存在血管末端细小且易于背景混淆的问题,而使用传统U-net 分割过程中部分区域会出现血管末端丢失和血管细小处错误分为背景的问题。因此本文在每个深度可分离卷积块后(previous convolutional block)、下个卷积块(next convolutional block)之前增加一个CBAM 模块,继续学习特征图的空间信息和通道信息,提高网络分割的精度。将CBAM模块插入到两个相邻的卷积块中的示意图如图8所示。

图8 CBAM插入到相邻的两个卷积块中Fig.8 Insert into two adjacent convolutional blocks
2 实验
2.1 实验数据集
本实验采用的数据集是由陈强教授及其团队在IEEE-DataPort 上公开的2020 版视网膜血管数据集OCTA-500[31],它是目前最大的OCTA图像数据集。OCTA-500包含500 名具有6 mm×6 mm 和3 mm×3 mm 两种视野类型的测试者,该数据集共包含36万张图像,大小约为80 GB。OCTA-500 根据视野类型划分为两个子集OCTA_6M 和OCTA_3M,其中一个子集OCTA_6M 包含了300 名视野为6 mm×6 mm 的测试者;另一个子集OCTA_3M 包含了200 名视野为3 mm×3 mm 的测试者。每个子集都包含了六种不同区域的视网膜血管投影类型图像,分别是整个眼睛(FULL)的OCTA图像、整个眼睛的OCT图像、内界膜(ILM)和外丛状层(OPL)的OCTA 图像、内界膜和外丛状层的OCT 图像、外丛状层和布鲁赫膜(BM)的OCTA图像和外丛状层和布鲁赫膜的OCT图像;还包含了年龄、性别、左右眼和疾病类型4种文本标签以及视网膜血管和无血管区两种像素级分类标签,每个子数据集共包含三种不同的数据。
本次实验只选用了OCTA_6M 子集中用于分割的数据集,其中选用的原始图像是整个眼睛的OCTA 图像,选用的标签是视网膜血管分割标签,原始图像和真实标签各300幅,原始图像和真实标签的示例如图9所示。

图9 原始图片和真实标签Fig.9 Input image and ground truth
2.2 数据预处理
本实验将数据集按照7∶3 的比例通过随机抽样的方式将其划分为训练集和测试集,分别包含210幅训练图像和90幅测试图像。为统一后续对比实验中不同网络的输入尺寸,因此在送入网络前统一将像素大小调整为512×512,如表1所示。

表1 数据集分布情况Table 1 Dataset distribution
在训练过程中,训练集数据量偏少是造成模型欠拟合的重要因素之一。由于OCTA图像较为稀缺,OCTA-500视网膜血管分割数据集中数据量较少。因此为降低欠拟合的影响,本文采取对输入图像进行随机裁剪、翻转、缩放、平移等方式对输入图像进行在线数据增强,使数据更加丰富多样。
2.3 性能指标
本实验为了对模型性能进行定量比较,因此引入四种量化统计指标:(1)真阳性(true positives)指实际是血管也被准确识别为血管的像素点;(2)假阴性(false negatives)指实际是血管却被识别为非血管的像素点;(3)真阴性(true negatives)指实际是非血管也被准确识别为非血管的像素点;(4)假阳性(false positives)指实际是非血管却被识别为血管的像素点。在此基础上为准确评价模型分割性能,本文使用综合评价指标F1 分数(F-measure,F1)、交并比(intersection over union,IoU)、均交并比(mean intersection over union,mIoU)、灵敏度(sensitivity,Se)、特异性(specificity,Sp)、精确率(precision,Pre)和准确率(accuracy,Acc)作为模型的评价指标,具体见参考文献[7]。
本实验为了对模型参数的复杂度和训练过程中所耗费的计算资源进行定量比较,因此引入五种量化统计指标,分别是模型总参数量(params)、浮点运算次数(FLOPs)所占空间大小(memory),模型读取和写入内存的总消耗(Mem R+W)和乘法加法操作(MAdds)。
2.4 实验环境和超参数
本实验是使用惠普(HP)台式电脑在Windows 10操作系统下完成的,处理器为Intel®CoreTMi9-10920X CPU@3.50 GHz,运行内存为32 GB,显卡为NVIDIA GeForce RTX 3080Ti(12 GB显存),实验的仿真平台为PyCharm,使用的Python 3.8编程语言,开源深度学习计算框架采用的版本是Pytorch 1.7.1。
训练过程中选用的优化器为Adam,损失函数设置为交叉熵损失,学习率设置为0.000 5,根据显卡性能选择送入网络的图片批量大小为2,并根据训练结果保存最优模型。
2.5 分割效果对比实验
将本文方法与常见的视网膜血管分割方法FCN[6]、U-net[23]、SegNet[32]、U-net++[13]、Res Unet[12]和Medical Transformer[14](M Trans)一起在OCTA-500 数据集上进行对比实验。除了Batch_size大小根据显卡性能统一设置为2 以外,其余参数均使用各自论文中的最优参数。分割结果如表2所示,训练损失函数变化曲线图如图10所示。
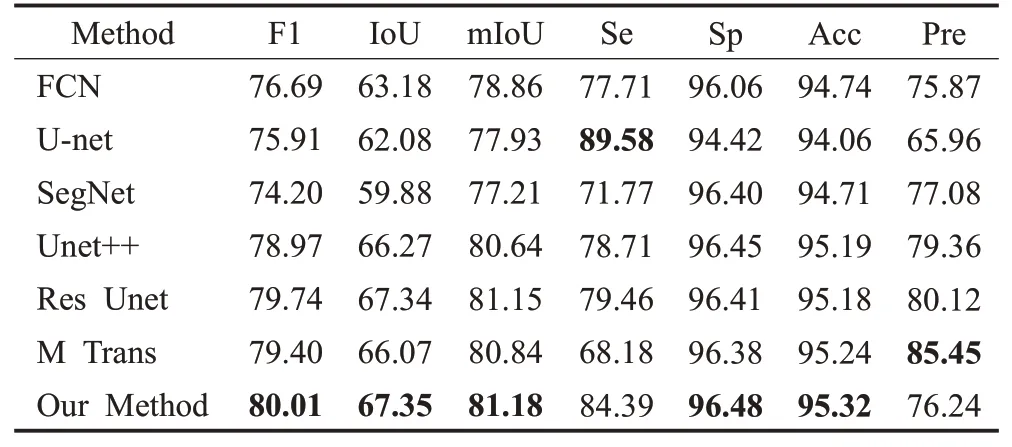
表2 不同网络在OCTA-500的分割结果Table 2 Segmentation results of different networks单位:%

图10 训练损失函数变化曲线图Fig.10 Training loss function change results size
由图10 可知,本文方法(图中红点曲线)在OCTA-500这种小型数据集上训练具有较快的收敛速度。本文方法和U-net 以及基于U-net 改进的网络(即Unet++和Res Unet)相比,训练中具有更小的损失值,并趋于最优表现。从图10可以看出,Unet++的训练损失较高,可能是由于文献[13]中使用的数据集和本文的数据集在数据特性和样本数量上有较大差异,因此直接将其参数运用于本数据集并不合适,造成训练损失较大。而Medical Transformer(M Trans)由于网络架构的不同,虽然能有更小的训练损失值,但训练时间较长,训练轮次较多。并经实验发现,M Trans 要训练近1 200 轮才能达到和本文方法训练20轮相近的分割效果。
由表2可知,本文方法与FCN、U-net和Res Unet等网络相比能得到更好的分割效果。本文方法的F1分数和U-net 的F1 分数相比提升至80.01%,而IoU、mIoU、Sp、Acc、Pre 各项指标也如表2 所示分别提升了5.27、3.25、2.06、1.26、10.27 个百分点。由于OCTA-500 视网膜血管数据集普遍存在图像背景噪声多、信噪比低等问题,所以导致U-net和FCN等网络最后的分类结果比较粗糙,容易将血管末端局部区域错分为背景或将部分背景错分为血管。
图11和12 为两个分割实例,分别展示了U-net 和Res Unet 针对上述两类问题错分的情况以及本文方法的分割结果。图11中,U-net和Res Unet将血管末端细小处的部分区域误分为背景,导致假阴性值增大。图12中,U-net和Res Unet分割过程中将背景错分为血管,导致假阳性值增大。而本文方法针对将血管末端错分为背景或将部分背景错分为血管这两类问题都有明显的改善。

图11 假阴性(FN)示意图Fig.11 Example diagram of false negative
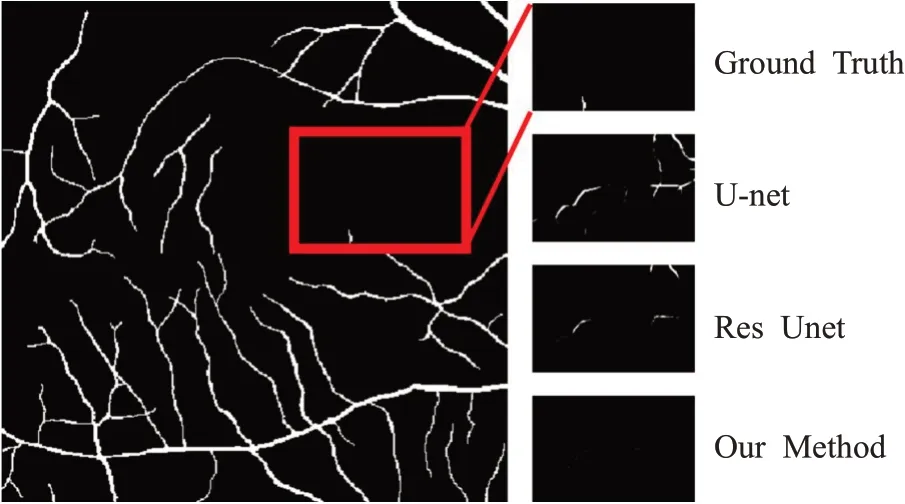
图12 假阳性(FP)示意图Fig.12 Example diagram of false positive
所有网络的分割结果如图13 所示。一方面,各个网络的分割结果中会出现把部分背景错误分类为血管的情况,如图13 中case1 和case2 中圈出的部分所示。在case1中所有网络的分割结果中都有将背景和血管发生不同程度错分的情况,而本文方法错分情况相对较少;在case2 中FCN、SegNet 和Unet++的分割结果中错分情况较为明显。另一方面,在各个网络的分割结果中,血管末端细小处会发生不同程度的丢失,如case3、case4 和case5 中圈出的部分所示。case3 中本文方法对血管末端的丢失较少;case4中U-net和Res Unet对血管末端丢失较为严重;case5 中SegNet、Res Unet 和M Trans的分割结果中血管末端丢失情况较为明显。总体上本文方法能更好地改善上述两类问题,和其他网络相比,本文方法的分割结果更接近真实结果。

图13 不同网络的分割结果图Fig.13 Segmentation results with different networks
2.6 消融实验
该消融实验为寻找网络的最优结构,在网络结构上做出改进,使用不同的网络结构进行对比实验。分别从深度可分离卷积块的个数和不同的注意力模块两个角度进行测试,并根据结果得到最优的结构。
2.6.1 深度可分离卷积块
本文方法首先在U-net 基础上增加一个CBAM 模块;然后用一个深度可分离卷积块(DSC Block)来代替每个采样层中的两次常规卷积操作进行特征提取;最后用两个深度可分离卷积块来代替每个采样层中的两次常规卷积操作进行特征提取。具体见表3。
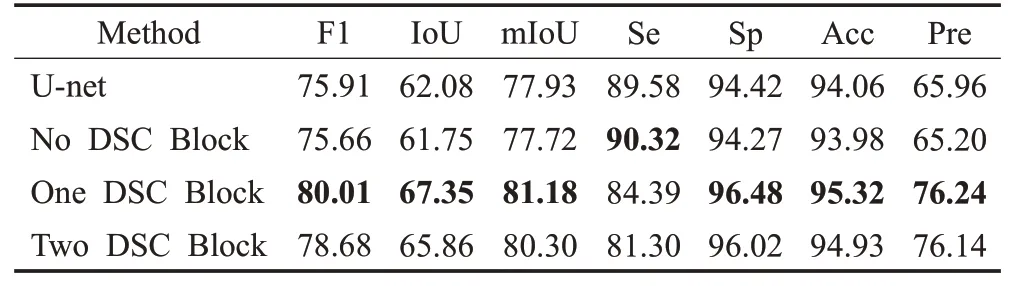
表3 使用不同数量的深度可分离卷积块的分割结果Table 3 Results of different numbers of DSC-Block单位:%
由表3可以发现U-net和CBAM模块相结合的网络与传统的U-net相比,分割性能有轻微的下降,这是因为OCTA-500数据集本身样本数量偏小的特性导致参数量较大的U-net可能欠拟合。而用深度可分离卷积块代替传统的卷积操作大幅度降低了参数量,所以带深度可分离卷积块的U-net 比传统的U-net 在数据量较少的OCTA-500上的分割效果更好。而使用两个深度可分离卷积块的网络结构所得到的分割效果又有所降低。因此,将一个深度可分离卷积块和一个CBAM 模块相结合的网络结构优于其他三种网络结构,这种网络结构在各项指标上均能取得较好的结果。
2.6.2 注意力模块
本文首先在U-net上用深度可分离卷积操作代替常规的卷积操作作为该部分实验的基准模型(no attention module,NAM);然后在以此为基础增加一个通道注意力模块(channel attention module,CAM);最后将通道注意力模块替换为通道空间注意力模块(convolutional block attention module,OM)。具体实验结果见表4。
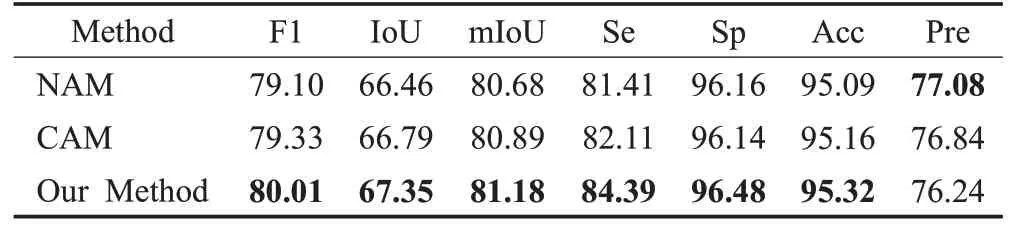
表4 模型改进前后分割结果Table 4 Results of different method 单位:%
实验结果表明,增加了通道空间注意力CBAM 模块的模型与没有添加注意力模块和只有通道注意力模块的两种模型相比,前者更注重视网膜血管末端细微处的分割;且在OCTA-500数据集上的分割效果更好。
2.7 复杂度对比实验
借助Python 提供的工具包ptflops(https://pypi.org/project/ptflops/)计算并评估不同网络的参数量、FLOPs、内存占用量等参数,不同网络的复杂度对比如表5 所示。其中,表中缺失数据是由于该工具包只能统计基于卷积操作的相关参数。
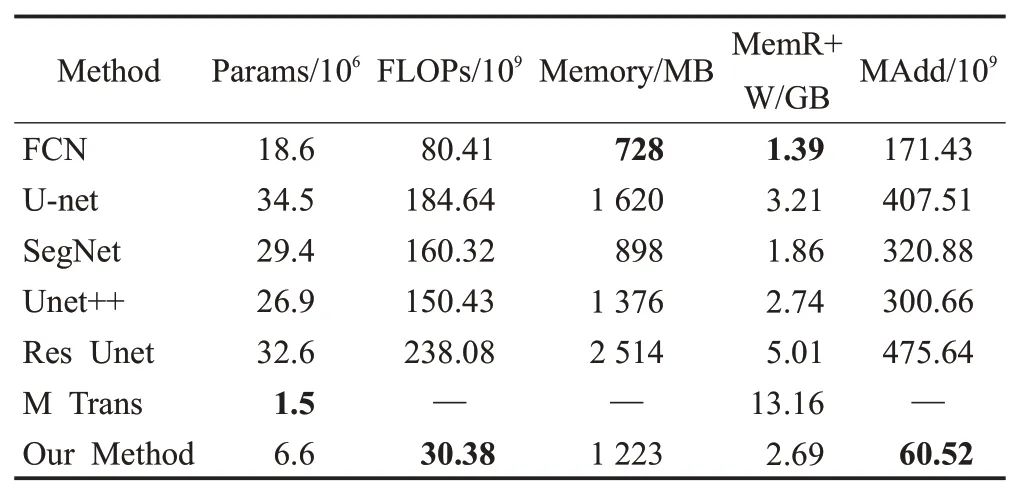
表5 不同网络的复杂度对比Table 5 Network complexity results of different models
由表5可知,本方法的参数量和FLOPs都有显著的降低,也减少了训练所耗费的计算资源。本文方法与U-net 相比,其参数量以及FLOPs 分别只有U-net 的19.2%和16.5%。本文方法与Res Unet和U-net++相比,它的参数量分别减少了79.7%和75.4%;它的FLOPs 也分别减少了87.5%和79.8%。并且本文方法所占用的总内存为1 223 MB,读取和写入所耗费的总内存为2.69 GB,乘法加法操作数量(×109)为60.52,和基于U-net改进的网络相比,都有不错的表现。而M Trans由于网络构架的不同,它更多是采用参数量较少的自注意力计算代替传统的卷积进行特征提取,虽然模型的参数量较少,但读写内存远远高于本文方法,耗费更多的资源。本文方法具有较低的模型复杂度,能更好地解决在训练样本有限的情况下,训练不充分或训练时间过长等问题。
3 结束语
本文提出一种将可分离卷积和CBAM 模块相结合的U-net语义分割模型。视网膜血管分割由于血管末端细小且易与背景混淆导致难以进行精确分割。为了解决该问题,提高视网膜血管的分割精度,本文首先使用深度可分离卷积代替常规的卷积;然后在深度可分离卷积块后增加一个CBAM模块,使其能在U-net的基础上更好地提取视网膜血管的细节特征;最后,将编码器和解码器中对称的特征图进行跳跃连接,融合上下文的多重语义信息,提高模型的分割性能。在OCTA-500分割数据集上使用本文方法和常见的方法进行大量对比实验,结果表明本文方法能达到较高分割性能的同时,占用较少的计算资源。
由于OCTA 视网膜血管图像普遍存在血管连续且不均匀分布在整张图像中的特性。因此,分割结果中可能会出现图像边框处的血管被错分为背景的情况,或是出现血管断裂的情况。后续的研究一方面是注重于对图像边框处的特征提取,改进网络架构,能更好的融合各层特征,减少因为下采样和上采样过程而导致图像边框处的血管等重要信息的丢失;另一方面,考虑添加诸如条件随机场等后处理方法,用以捕获整张图像中完整的血管结构,从而避免分割结果中出现血管断裂的情况。
