移动机器人行人避让策略强化学习研究
2023-09-25王唯鉴吕宗喆吴宗毅
王唯鉴,王 勇,杨 骁,吕宗喆,吴宗毅
1.北京机械工业自动化研究所,北京100120
2.北自所(北京)科技发展股份有限公司,北京100120
移动机器人近年来快速发展,其应用场景也在不断扩展[1]。传统移动机器人主要从事物料搬运等简单工作,由于工作场景相对固定,机器人移动过程中只需考虑对固定障碍的避让。服务机器人近年来快速兴起,其中具备自主移动能力的服务机器人需要适应复杂多样的工作场景,例如行人众多的车站、餐厅等。这些人员密集的应用场景对移动机器人对动态障碍的避让能力提出了新的要求。移动机器人需要在时刻与行人保持安全距离的前提下,尽可能高效地到达目标点。基于无碰撞假设提出的动态避障方法,比如RVO或者ORCA[2],采用被动躲避的方式避让动态障碍,由于相对固定的避让方法只依赖于机器人当前与障碍的交互,因此机器人难以做出长远的决策。另外,在面对多行人场景带来的复杂限制时,这类算法无法给出有效动作,导致机器人面临“冻结”问题。
移动机器人如果能够像人一样分析判断行人未来的行动,就可以据此做出更加符合人类行为逻辑的动作。依照这种想法,部分学者提出了通过预测行人轨迹指导移动机器人进行避障的方法,包括一系列人工设计的模型[3]和数据驱动的模型[4-5]。前者由于准确建模的难度过大,对行人动作的预测准确度较低;后者(例如长短期记忆细胞模型,生成对抗网络模型)高度依赖大量真实数据作为训练样本。另外,这类在完成轨迹预测后再进行移动策略规划的方法在具体实施上也存在很多困难。
强化学习适用于智能体在环境中连续或者离散动作的选择,因此近年来被很多学者采用。深度强化学习(deep reinforcement learning,DRL)关心智能体如何从环境中提取有助于决策的关键信息,在机器人对人群的避让问题中,如何对复杂的行人数据进行编码,以有效捕捉数据的潜在特征(比如行人之间的避让关系,行人与机器人间的关联)显得尤为重要。CADRL 是早期利用强化学习解决这一问题的方法[6],但其只是通过简单聚合行人之间的关联特征来建模人群。LSTM-RL[7]采用长短期记忆细胞分析行人的行为规律以指导机器人移动,SARL[8]通过引入自注意力机制生成机器人-行人交互的特征向量,可以有效捕捉机器人与不同距离的行人之间的交互关系,但这些方法并没有充分利用行人之间的交互信息,也只能单纯地通过线性近似模拟行人的下一步动作,因此在多行人的场景下表现尚待提高。
针对当前研究中存在的不足,本文提出了GCN-RL模型,采用图卷积网络(GCN)对包含行人和机器人在内的整个环境进行特征提取。得益于GCN处理图结构数据的优势,该模型不仅可以准确捕捉机器人与行人之间的潜在关联,同时也可以提取行人之间的关联特征,模型中的动作价值估计模块用于准确估计当前的动作-价值函数,行人预测模块配合前向推演策略帮助机器人通过与环境模拟交互更新对当前状态下不同动作价值的评估,能够有效指导移动机器人的下一步动作,在密集行人场景中选择更优的避障路径。
1 问题建模
假设移动机器人需要在存在N名行人的固定环境中完成导航任务,其目标是尽快到达地图中的固定位置并在导航过程中避让所有行人。该问题可以看作一个典型的顺序决策问题[9],即可以通过深度强化学习框架进行建模。具备环境感知能力的自主移动机器人作为强化学习智能体,在每个离散的时间节点选择动作;环境信息包括机器人自身信息和周围行人信息;机器人在离散的时刻读取环境的状态特征,并评估当前状态下自身的动作-状态价值,从而选取最优动作直至到达目标点。
1.1 状态编码
在机器人导航问题中,环境信息包括场景中所有行人的信息以及机器人自身信息。由于实际场景下,行人的实时位置和实时速度可以通过固定摄像头或者移动机器人搭载的摄像头获取,而机器人自身的状态除去实时位置速度外,还有目标点坐标(gx,gy),以及当前时刻机器人的首选速度(vpref,φ),包含速度大小和偏航角。因此,在任意时刻对于机器人自身以及每个行人的状态序列建模如下:
其中,px和py代表当前世界坐标系下行人和机器人的坐标,vx、vy代表世界坐标系下的速度,r表示机器人和行人的碰撞半径。
1.2 动作选择
基于值函数估计的强化学习问题中,智能体通过与环境交互更新对自身所处状态价值的估计和当前行为策略。移动机器人与人群环境在每个离散的决策时刻通过执行动作进行交互,决策时刻的时间间隔设置为Δt=0.25 s。假设机器人在二维空间上的所有自由度均可控,由于强化学习范式的约束以及实际应用的限制,机器人需要从离散的动作空间中选择要执行的动作。具体来说,机器人在每个决策时刻选择自身移动速度及移动方向。设置了[0,2π]之间的16个方向和[0,Vmax]之间的五档速度,组合成共包含80个动作的离散动作空间。
1.3 奖励计算
机器人在虚拟环境中从起始位置出发,行走至目标点则获得最高奖励,为训练机器人在到达目标点的过程中尽量避让行人,设立奖励函数如下:
其中,引入了dt=0.2 m 作为行人舒适距离,以保证机器人在选择路径时既不会撞到行人,也不会因距离过近而引起行人不适。同时,引入舒适距离dt计算奖励有效避免奖励过于稀疏,从而提升训练效果。
2 GCN-RL算法模型
通过将行人避障问题划归为强化学习范式,可以采用值函数更新的方式指导机器人动态避障。GCN-RL模型利用图卷积网络高效提取机器人和行人的深度交互特征,随后将这些特征用于估计状态-动作价值。同时,模型针对环境中全部行人信息提取行人之间的深度交互特征,用于预测行人下一时刻状态。模型在实时运行过程中通过模拟执行动作和预测行人状态来与未来环境模拟交互,根据交互结果更新对当前动作价值的估计,并依据更新后动作价值的估计值从离散动作空间中选择动作,指导机器人做出更加长远的避障决策,使其在导航至目标点的过程中自主避让环境中的行人。
2.1 强化学习建模
GCN-RL 模型的主要工作原理如图1 所示,环境信息包括机器人的状态以及全部行人的状态,为充分表征机器人和行人之间、行人与行人之间的关联信息,环境信息作为图结构数据输入GCN-RL模型,其中机器人和行人的潜特征作为图的节点,机器人与行人、行人与行人之间的潜在关联信息则作为图的边。模型中的价值估计模块接收来自全部节点的状态编码,并对当前环境加以评估。同时,状态预测模块接收全部行人的状态编码,通过预测模型输出对环境未来状态的预估。随后,GCN-RL采用了一种多步推演的方式与环境模拟交互,从而评估机器人在当前状态下采用不同动作会产生的预期收益,并根据预期收益指导机器人选择要执行的动作。在动作执行完毕的下一个离散决策时刻,环境信息得以更新,机器人重新获取环境信息,进入下一个决策周期。
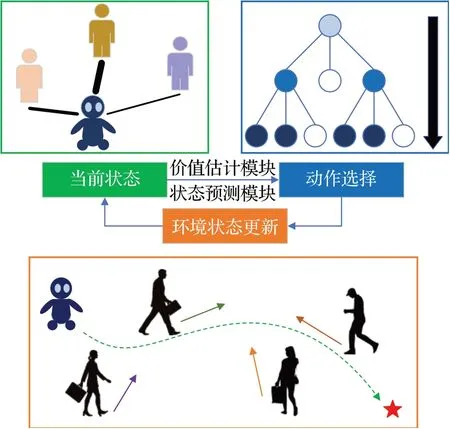
图1 GCN-RL工作原理Fig.1 Principle of GCN-RL
2.2 动作价值估计
强化学习中最重要的环节是如何通过环境的信息评估当前智能体所处状态的价值[10]。GCN-RL 模型采用了一个由图卷积网络和多层感知机组合而成的动作价值估计模块,用于学习机器人和行人之间关联状态的深度交互信息,并以此估计当前状态下的动作价值。动作价值估计模块的组成如图2所示。
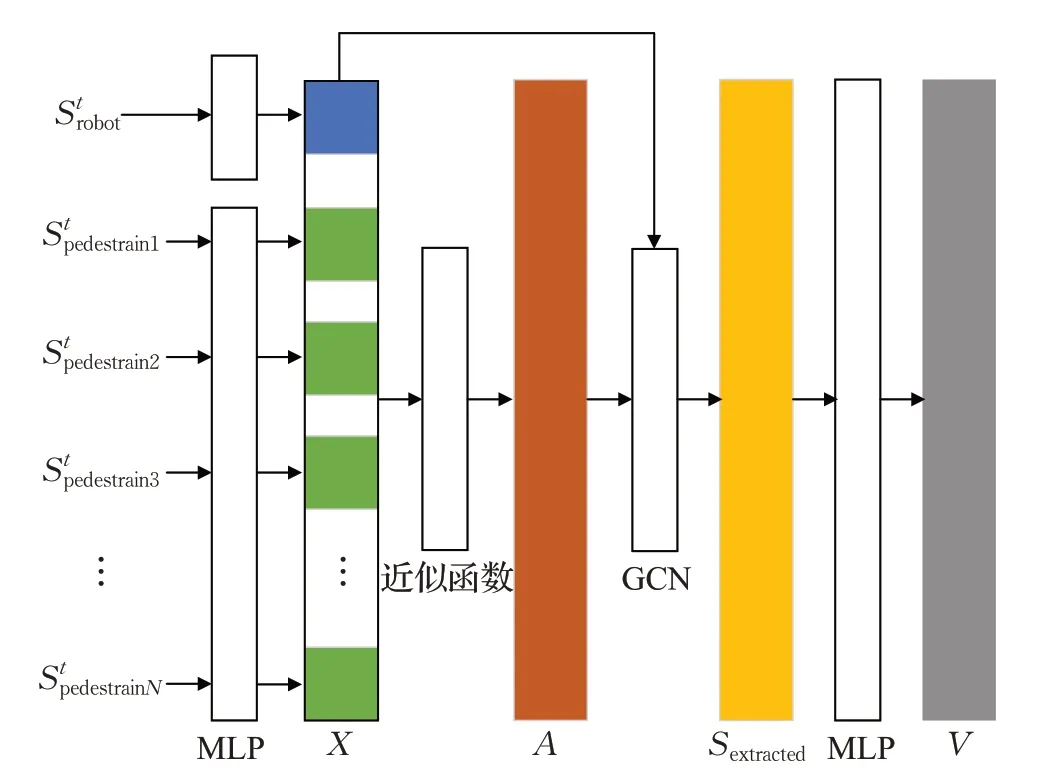
图2 动作价值估计模块Fig.2 Value predict module
图卷积网络能够充分利用图结构信息[11],提取图数据的深度特征,但需要各节点数据具备相同的结构。在机器人行人避让问题模型中,行人状态与机器人状态具有不同的维度,因此首先通过一个多层感知机(multilayer perceptron,MLP)将不同状态编码为潜空间中固定长度的向量,所有这些向量组成了矩阵X=[xr,xp1,xp2,…,xpn]T,其中xr为机器人的潜在特征,xp1,xp2,…,xpn为行人的潜在特征。通过成对近似函数计算该特征矩阵的关联特征矩阵,模型采用嵌入式高斯函数作为近似函数[12],计算得到的A=softmax(XWaXT)矩阵记录了节点之间的潜在关联特征,其中xi=X[i,:],θ(xi)=Wθ xi,ϕ(xi)=Wϕxi,Wa=WθWTϕ。
以上方式分别提取了环境中每个节点的潜在特征以及任意两个节点之间的直接关联特征,然而对于在人群中导航的机器人而言,单纯获取每一时刻其他行人的特征和行人与自身、行人之间的关联特征并不能充分指导自身动作。比如,在某一时刻距离机器人很近的行人A由于附近并没有其他行人,因此会倾向于维持原速度继续前进;而同一时刻距离机器人相对较远的行人B行进前方有其他行人,因此可能会向机器人方向做出避让动作。在这种情况下,简单整合节点特征和关联特征难以完成对环境当前信息的充分提取。
正因如此,GCN-RL采用图卷积网络处理节点特征和关联特征,由于图卷积网络可以利用图的连通结构通过边传递特征,并在节点聚合特征,经由图卷积网络正向传播后的节点特征包含了更多机器人与人群环境的深层特征(比如行人之间的躲避导致的潜在障碍),其中第i行的数据代表了节点i对其自身与整个环境交互所产生的深度关联特征的编码。节点信息按照H(l+1)=σ(AH(l)W(l))+H(l)进行传递,其中W(l)代表了网络第l层可训练的参数,σ为激活函数Relu。GCN 通过节点原始特征X和节点关联特征A完成节点特征的更新。本文采用了一个2 层的GCN 以保证每个节点能够充分从图的关联中学习到环境中潜藏的深度交互特征,GCN输出当前包含这些特征的全部节点状态Sextracted,输入一个MLP以计算动作-状态价值。
2.3 行人状态预测
行人状态预测模块通过当前时刻全部行人的行为状态预测他们下一时刻的状态。一些其他的机器人导航模型[6,8]使用传统算法预测人群在下一时刻的动作状态(比如对行人动作做线性近似其下一时刻位置),这种方法并没有利用端到端的学习模型,无法准确估计下一时刻行人的行为策略。另外一些关于行人轨迹预测的研究将行人轨迹看作序列数据,采用长短期记忆细胞等方式对未来数据进行预测[13],尽管从历史数据中学习提升了对行人移动预测的准确率,但在预测过程中忽略了行人之间的关联,且往往需要大量真实数据对模型进行预训练。
本研究采用的行人状态预测模块由两个部分组成,第一部分用于提取当前人机交互环境状态特征,其具体组成方式与价值估计模块中的状态估计模块类似:使用多层感知机对环境编码得到各节点特征潜向量,之后利用近似函数计算关联矩阵,再根据图卷积网络正向传播,得到全部行人和机器人当前深层交互状态的特征表达;模块的第二部分通过另一个多层感知机接收行人当前时刻深度交互特征并预测下一时刻行人状态。即GCN-RL 并不会显式地预测行人在下一时刻的行动轨迹,而是直接预测行人未来状态。由于这些特征本身包含了行人与环境交互的深度信息,而本研究中,机器人正是通过环境的状态特征计算状态-动作价值,因此对行人状态的预测能够帮助机器人更准确地评估当前时刻执行不同动作的收益。
2.4 机器人动作选择
在具体的行人避让过程中,机器人每隔0.25 s 就需要从80 个离散动作中做出选择,解空间非常庞大。本研究借鉴了N步自举法[14]和蒙特卡洛树搜索[15]的思想,将学习到的深度价值估计模型与前向推演相结合,采用一种在当前状态模拟执行最优动作并与预测的环境状态交互以取得回报的方式更新当前状态下不同动作的价值估计,其推演流程如图3所示。机器人根据推演结果更新当前状态下的动作价值,并以此为依据选择动作。动作价值按照以下公式更新:

图3 K 步推演更新动作价值Fig.3 K-step rollout update action value
实验中前向推演的步数为K,推演的广度设置为W。当K取1时,机器人只能根据当前环境已知信息计算动作预期收益,不能利用到行人状态预测模块对未来状态的预估。更大的K值则意味着机器人能够在动作选择时考虑的更加长远。机器人探索环境的过程中,奖励非常稀疏,因此采用更大的K值也可以提高一次推演中到达目标点的概率,从而提升模型的学习效果。然而,增加的K会大幅增加计算成本。因此设置W对推演的动作空间进行剪枝,即每次前向推演仅考虑尝试预期收益排名前W的动作。这种在线推演的方式兼顾了避障模型的性能与效率,可以在相对低的采样次数中对任意状态下的动作价值有较为准确的估计。
3 模型训练
3.1 模型初始化
机器人在移动过程中获得的奖励较为稀疏,因此从零开始训练会导致模型无法收敛。为加快模型收敛,采用模仿学习[16]对模型进行初始化。在模仿学习过程中,机器人依照ORCA 避障算法实现CrowdNav 下的导航。经过模仿学习对网络参数的初始化,机器人初步具备了对障碍的避让能力,可以在后续训练过程中侧重于导航路径的优化,避免大量无意义的动作尝试。
3.2 训练流程
算法1展示了模型的训练流程。
算法1 模型训练流程
输入:模仿学习经验池D
输出:训练后的价值估计模型Mv和动作预测模型Mp

经过模仿学习后,经验池E中保存了一系列元组(St,at,rt,St+1),对于每一次从起点出发的训练,随机初始化行人与机器人的状态,随后,机器人采用ε-greedy策略选择动作获得收益,并将探索获取的经验存入经验池。随后采用经验回放机制从E中随机选取一批(St,at,rt,St+1)用于更新价值估计模块以及状态估计模块的参数。一次完整训练流程模拟了机器人从起点到目标点(产生碰撞或超时)的整个流程。通过利用经验回放机制[17]训练模型,机器人记忆池中的数据被高效利用,同时避免了相邻数据的强关联性对训练效果的负面影响。在每次训练达到终点状态后,价值估计模块和状态预测模块同步更新。
4 实验验证
4.1 实验设置
实验采用的场景基于开源框架CrowdNav 构建,场景设置为circle-crossing,即环境中有五名行人随机分布在半径为4 m的圆上,他们的终点位置为起点在圆周上的对应位置,所有行人按照ORCA 避障策略移动,机器人的最大速度设置为1 m/s。为保证行为策略的差异化,算法参数按照高斯分布采样得到。机器人的起始位置和终点位置也在圆周上并关于圆心对称。在没有行人干扰的情况下,机器人需要花费8 s 行驶到目标点。仿真实验中,机器人被设置为对所有的行人而言不可见,即行人不会主动躲避机器人。这样设置有助于充分体现机器人自主躲避行人的效果。用于编码机器人和行人状态的MLP维度为(64,32),用于价值估计的MLP维度为(150,100,100),用于行人状态预测的MLP维度为(64,32),Wa的输出维度设置为32。模型的所有参数通过强化学习流程进行训练,并使用引入权重机制的AdamW[18]算法更新参数,AdamW 的权重衰减率为0.1。在ε-greedy 策略中,探索率ε最初设置为0.5,在初始的5 000 次迭代训练后线性降低至0.1,并在后5 000 次迭代中保持在0.1。模仿学习次数设置为2 000,训练周期总数设置为10 000。使用Adam 以及AdamW 算法更新模型,在K步推演阶段,K设置为2,W设置为2。实验平台为搭载i7-11850H的手提电脑,训练时长约为16 h。
4.2 模型训练结果
模型在10 000 次训练过程中的累计折扣奖励曲线如图4 所示。Adam 作为当前主流的优化算法,在很多模型中广泛应用,然而面对过拟合问题时,Adam算法因其权重更新机制,不适合像随机梯度下降方法一样使用L2 正则化权重惩罚项进行权重更新。AdamW 优化算法在Adam 算法的基础上设置了权重衰减方法[18],能有效避免模型过拟合。实验分别采用Adam和AdamW对GCN-RL 模型进行训练,从图4 的训练累计折扣奖励中可以看出,使用Adam 训练的模型在6 000 个训练周期后达到最佳性能,但随后模型的性能由于过拟合而出现了一定程度的下降。在使用AdamW 对模型进行训练时,虽然权重衰减导致模型在前4 000 个训练周期的收敛的速度相对于使用Adam 算法较慢,但在6 000 个训练周期后AdamW 算法的训练效果已经与Adam 相当,且在之后的训练过程中,AdamW 能够帮助模型收敛到更优性能,且并未遭遇因模型过拟合而导致的性能下降。因此选用AdamW算法以保证GCN-RL模型的训练效果。
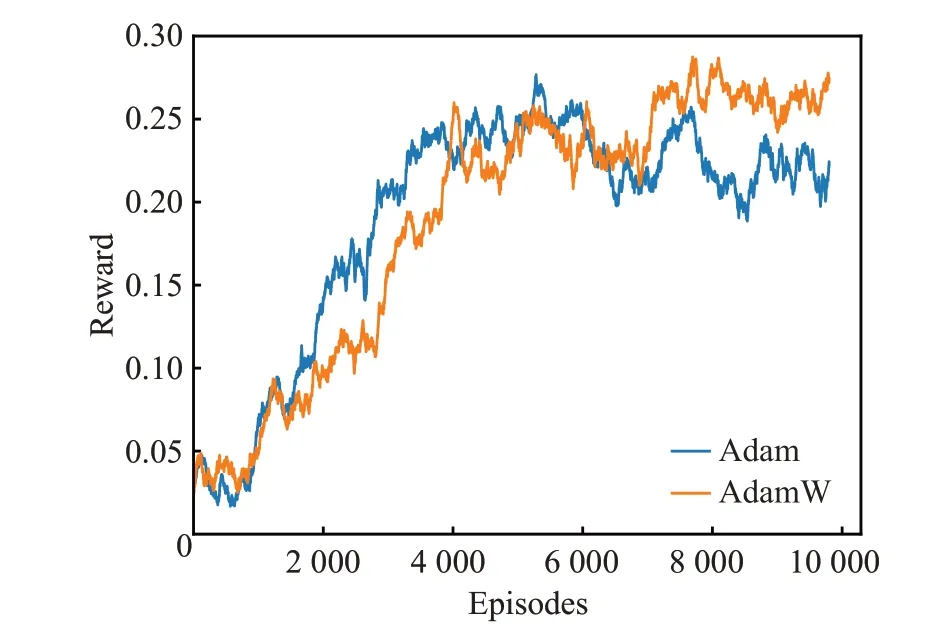
图4 训练累计折扣奖励Fig.4 Cumulative discounted reward
4.3 模型性能对比
不同避障方法在Crowd-Nav 仿真场景下的性能表现如表1 所示。由于GCN-RL 首先基于ORCA 进行有监督的预训练,因此引入ORCA用于模型性能对比。可以看出,尽管ORCA采用线性规划计算机器人动作的方式使其运行速度很快,但由于其不具备从环境中学习的能力,导航过程中的避障成功率和平均导航时间都不理想。SARL使用注意力机制提取环境特征,是当前表现最佳的模型,然而注意力机制的应用增加了模型的复杂程度,导致特征计算需要更大的开销。而GCN-RL采用图网络进行顺序交互特征提取,计算方式相当于矩阵乘法,所需的开销更小,模型的运行时间也明显更少。为证明GCN-RL 模型中采用的状态预测模块为模型带来的性能提升,设计了线性预测对比模型GCN-RL-Linear,其中行人下一时刻的状态由线性拟合函数近似,即默认行人在0.25 s的时间间隔后会延续上一时刻的动作。从表1 可以看出其性能低于GCN-RL,这说明通过状态预估模块的使用让机器人能更准确地预测行人状态,从而帮助机器人更好地在导航过程中实现对行人的避让。

表1 不同避障策略性能比较Table 1 Comparison of different strategy
4.4 K 步推演对模型性能的影响
为验证GCN-RL 模型中采用的动作选择策略对模型性能的提升作用,设计了多组对比实验以测试不同推演深度K和不同剪枝数W的模型在500个不同场景下的实际运行表现,测试结果如表2 所示。从中可以看出,更多的前向推演步数缩短了机器人的导航时间,同时降低了机器人与行人距离过近的概率。然而,当K=3时,继续增加的前向推演步数对于模型性能的提升相对有限。同时,增加预剪枝的宽度也对模型性能有提升,但会伴随着显著增加的算法运行时间,因此模型采用W=2 以平衡性能和运行成本。值得注意的是,任何一组参数下的实验其导航成功率都未达到100%,这是因为机器人被设置为对行人不可见,部分极端场景下行人会“包围”机器人,导致无法躲避的碰撞。另外,K和W的增加都会增加导致机器人导航过程中的计算负荷,在真实场景中需要根据硬件性能限制设置能平衡模型性能和计算开销的推演参数。

表2 不同参数下模型性能Table 2 Model performance with different parameters
如图5 中所示,在环境相同,行人移动轨迹一致的情况下,不同的推演参数使机器人选择了不同的导航路径。从图5中可以看出,t=4 s 时行人位置较为集中,当K=1 时,机器人短视地向右转向以躲避路径上的红色行人,从而选择了从行人密集处穿行的路线,导航时间为10.5 s。当K=2 时,机器人初步具备了预估行人动作的能力,做出了从红色行人身后绕行的尝试。然而由于其只进行了单步前向推演,对行人未来动作的预测不够准确,最后还是选择了从行人密集处穿过,导航时间也因此增加了0.3 s。而当K=3 时,机器人通过前向推演有效预测了行人的未来动作,选择了从红色行人身后绕行的路线,有效规避了行走路径上的人群密集区域。虽然选择的路径相对远,但由于做出的避让动作更少,机器人只用了10.2 s即到达目标。实验结果表明前向推演策略帮助机器人选择了更优的行驶路径,导航时间更短,对行人的避让效果更好。
5 结束语
本文提出了一种利用图卷积网络的强化学习避障方法GCN-RL,用于解决仿真环境中机器人对行人的避让问题。GCN-RL 模型相较于传统避障模型有更好的表现,基本达到了当前同一问题下最优模型的性能,同时运行时间更短。模型采用GCN架构提取环境的深层关联特征,并利用提取到的特征同时对动作价值和行人状态进行估计以指导避障,从而使得算法的复杂度降低,运行时间更短。在模型的训练阶段,实验应用了AdamW 算法使得价值估计模块能够收敛到更好的性能。另外,模型通过采用K步推演实现了对动作价值的更精准评估。通过实验分析了不同参数下的模型表现,体现了该方法对机器人行人避让性能的提升。
