嵌入位置编码的多头注意力机制在堆积脉冲幅度估计中的应用
2023-09-21廖先莉李跃鹏4
唐 琳 周 爽 李 勇 廖先莉 李跃鹏4,
1(成都大学 电子信息与电气工程学院 成都 610106)
2(安徽大学农业生态大数据分析与应用国家工程研究中心 合肥 230039)
3(南洋理工大学 电气与电子工程学院 新加坡 639798)
4(成都理工大学 核技术与自动化工程学院 成都 610059)
在核辐射测量中,感兴趣区域(Region of Interest,ROI)的计数率是非常重要的测量指标,在进行元素含量分析时,计数率的精度决定了元素含量分析的准确度[1-2]。因此,要得到准确的元素含量,每一个核脉冲信号都是至关重要的。近年来,许多学者在脉冲处理领域发表了相应的研究成果,包括采用遗传算法合成具有任意噪声的最优数字成形器[3]、基于双极性尖顶成形的基线恢复[4]、对堆积脉冲的测量和补偿技术等[5-6]。在前期研究中,笔者针对脉冲宽度不够的畸形脉冲提出了脉冲甄别[7]和脉冲修复[8]两种算法,有效降低了测量结果中计数率的统计涨落。上述成果都是采用传统的分析手段对核脉冲进行了分析和处理,在某些领域中也取得了较好的应用效果。但在实际应用中,对于那些严重堆积的脉冲,采用传统的脉冲处理技术难以实现较好的脉冲分离以及脉冲幅度估计,从而导致测量结果中计数率的准确性和稳定性较差。
人工智能的发展为X 射线荧光光谱(X-ray Fluorescence,XRF)分析带来了新的发展空间,国内外学者在该领域都发表了不少研究成果。文献[9]使用U-Net 网络作为脉冲整形器,对脉冲进行滤波并使其展开,在一定程度上解决了脉冲堆积问题;文献[10]基于神经网络和集成学习对核探测器信号的广义不确定性进行了准确估计;笔者所在的团队在前期研究中也已提出基于深度学习的递归神经网络(Recursive Neural Network,RNN)模型[11]对堆积脉冲进行参数估计,但该模型对数据集的要求较高,需要大量的数据样本和较长的训练时间。考虑到深度学习技术已经被广泛应用到生物[12]、控制[13]、医学[14-16]、通信[17]等多个领域,在核脉冲参数识别领域,深度学习的相关应用仍处于初步探索阶段,本文将Vaswani等[18]提出的Transformer模型结构进行优化,并将其应用于核辐射测量的堆积脉冲幅度识别领域,通过嵌入位置编码、执行多头注意力机制来对堆积脉冲的幅度进行准确估计。在堆积脉冲识别领域中,多头注意力机制可以帮助识别并分类不同的脉冲,从而提高堆积脉冲的分析准确性和鲁棒性。
1 原理及方法
X 荧光能谱多采用数字多道谱进行分析,在能谱图中,每一个脉冲幅度估计值都对应着相应道址上的一次计数事件,因此,幅度估计值的准确性就决定了XRF分析的准确率。当脉冲发生堆积时,要得到精确的谱图,堆积分离以及准确的幅值估计就异常重要了。本文提出一种深度学习模型实现堆积脉冲分离及其幅度估计,其原理如图1 所示。输入事件经积分器输出一个堆积上升的阶跃脉冲信号,然后再由CR微分整形器滤除直流成分并将阶跃脉冲整形为如图1所示的负指数脉冲。数字化的负指数脉冲序列作为深度学习模型的输入,经学习模型最终输出为与输入事件对应的脉冲幅度估计事件。

图1 堆积脉冲分离及脉冲幅度估计原理Fig.1 Principle of stacking pulse separation and pulse amplitude estimation
如果测量系统得到的堆积脉冲幅度没能被准确估计,那么在最终获取的X 荧光能谱ROI 中的有效计数就会降低。因此,堆积脉冲幅度的准确估计对X荧光能谱的精细分析是非常重要的。采用基于深度学习模型对堆积脉冲幅值进行估计的第一步就是数据集的制作。
1.1 数据集制作
数据集的来源包括成形后的脉冲幅度采样值以及每个脉冲样本的参数,为了对本文提出的嵌入位置编码的Transformer模型进行训练,定义了负指数堆积脉冲的数学模型如式(1)所示:
式中:u(t)表示阶跃脉冲;Ai为第i个核脉冲的幅值系数;Ti表示第i个核脉冲的发生时间;τ为时间常数;ν(t)表示噪声。以采样周期Tclk对其进行离散化且Tclk为50 ns,则离散化后的脉冲序列如式(2)所示:
负指数脉冲序列Ve(kTclk)经过数字成形后将会得到一个新的脉冲幅度序列Vo(nTclk)。常用的数字成形方法包括三角成形、梯形成形、高斯成形,这里以三角成形为例,其数学模型如式(3)所示:
其中:na=tup/Tclk。
本文建立的数据集由脉冲幅度采样值以及成形前负指数脉冲的真实幅值A构成。根据需要,在对堆积脉冲的三角成形结果进行采样时,采样点数是可以调整的,为了实现快速谱分析,减小数据集规模,本文选择的是64 点采样,其中包括63 个成形结果的幅值采样点以及一个脉冲真实幅值的采样点。数据集的矩阵表示形式如式(4)所示:
式(4)中的数据集包含m个成形后的脉冲幅度序列,每个脉冲幅度序列对应矩阵中的一行;每一行中包含的前63 列代表堆积脉冲三角成形结果的幅度采样值,第64列代表该脉冲的真实幅值。本文按照7∶2∶1 的比例把数据集分割为训练集、测试集和验证集。
1.2 Transformer建模
1.2.1 编码器-解码器框架
基于深度学习的Transformer 模型其网络结构如图2所示,该模型是一个基于编码器(Encoder)-解码器(Decoder)框架的模型,不使用循环神经网络(Recurrent Neural Network,RNN)结构,完全基于注意力(Attention)机制[18],使得并行性更好。在采用Transformer 模型对堆积脉冲进行参数估计时,为了把位置编码信息传输到编码器,在编码器和解码器的输入中嵌入了位置编码(Positional Encoding)来对脉冲序列中样本的位置进行标记。

图2 Transformer模型结构图Fig.2 Structure diagram of the transformer model
如图2 所示,编码器的输入是一个嵌入了位置编码的脉冲幅度序列,内部由6 个相同的编码器层组成,每个层的内部结构如图3所示,包括一个多头自注意力层(Multi-Head Self-Attention)和一个前馈层(Feed Forward),每一个层产生的输出都传递给解码器对应的层。为了让不同的层之间便于连接,输入嵌入层、位置编码层以及编码器层、解码器层都保持着相同的维度64。
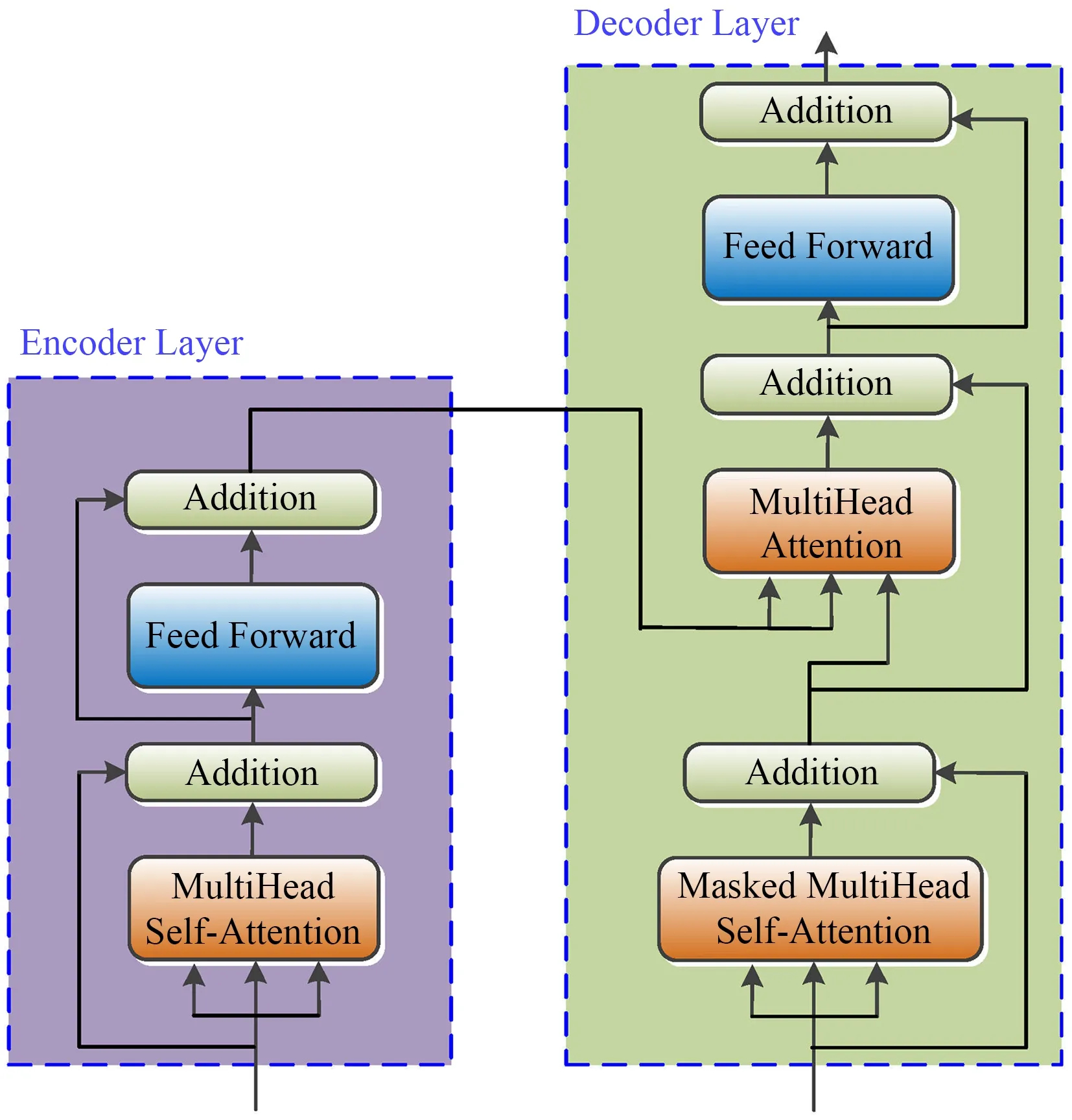
图3 编码器和解码器内部结构图Fig.3 Internal structures of the encoder and decoder
解码器将训练集中的脉冲参数集A作为输入,其内部结构与编码器类似,也是由6 个相同的层构成,如图3 所示。它区别于编码器的地方在于每个解码器有三个子层,除了一个带掩码的多头自注意力层、一个前馈层,还有一个多头注意力层。在训练时将脉冲参数集A输入到解码器中,对于一个序列,在时间为t的时刻,解码输出应该只能依赖于t时刻之前的输出,而不能依赖t之后的输出,因此需要一个掩码把t之后的输出隐藏起来。掩码的实质是一个下三角矩阵,即上三角的值全为0,把这个矩阵作用在每一个序列上,就可以达到把t之后的输出隐藏起来的目的。这种掩码的设置,加上输出嵌入位置偏移的事实,确保了位置i的预测只能依赖于小于i的位置处的已知输出。
1.2.2 位置编码
常见的位置编码包括可学习的编码和固定位置编码[19]。文献[18]证明了可学习编码与固定编码得到的结果相差不大,而最简单的固定编码莫过于二进制位置编码,其编码原理如图4(a)所示。为了对序列中的数据进行排序,给每个数据嵌入一个二进制的位置编码,如果有16个数据需要编码,那么从0开始,编码到15 结束,可以发现0~15 的不同比特之间的变化率是不同的,最低位在每个数字上都会发生交替,次低位则在每两个数字上发生一次交替,依此类推。但是当所需的位置编码位数非常大时,使用二进制值就会浪费空间,占用内存。因此,本文考虑使用它们的浮点连续对应函数-正弦函数来进行位置编码。从本质上来说,正弦函数也相当于一种交替变化的比特流,y2所在的编码曲线中,1 000 个采样点内每个比特出现了6次,而通过调整频率后,y1所在的编码曲线中,1 000个采样点内每个比特仅出现了1 次。从而可以得出,通过调整频率能够实现类似于二进制编码中从红色比特变为橙色比特的编码效果,如图4(b)所示。

图4 位置编码原理(彩图见网络版)(a) 二进制编码,(b) 正弦函数编码Fig.4 Principle of positional encoding (color online) (a) Binary encoding, (b) Sine function encoding
本文使用正弦函数来进行位置编码,为了与输入数据进行匹配,编码维度为64,输入矩阵嵌入64维的位置编码后得到新的编码矩阵如式(5)所示:
1.2.3 多头注意力机制
注意力函数本质上可以被描述为将查询向量(query)、键向量(key)、值向量(value)映射到一个输出向量的过程,输出向量是value 的加权和,其中分配给每个value 的权重由query 与对应key 的兼容性
函数计算,其计算公式如式(6)所示:
式中:dk为键向量的维度。
多头注意力的计算涉及多个模块,在图5中以6个不同的Block进行呈现。Block A中脉冲幅度形成的数据集嵌入64 个维度的正弦位置编码后得到编码器的输入矩阵S,Block B 中展示了8 个权重矩阵W Q、W K、W V的组合,输入矩阵S与权重矩阵W Q、W K、W V进行点积得到Block C所示的8组Q、K、V矩阵,然后将8 组变换后的Q、K、V进行注意力池化输出Block D中的8个注意力头Z0~Z7,将8个注意力头拼接在一起并通过与Block E 中的另一个可学习的权重矩阵进行变换,以产生Block F 中的输出矩阵Z。在图5 所示的多头注意力计算过程示意图中每个Block的内容以及矩阵计算过程如表1所示。

表1 Block的具体特征Table 1 Specific characteristics of the blocks

图5 多头注意力计算过程Fig.5 Calculation process of Multi-head attention
2 仿真与实验
2.1 模型训练
在定义Transformer 时,三个矩阵W Q、W K、W V的初值是随机的,为了得到最优的权重参数矩阵,验证模型对堆积脉冲进行参数估计的效果,以前文所述的堆积脉冲数学模型产生一系列堆积的负指数脉冲序列制作数据集。应用反向传播算法将LMSE与损失函数的梯度一起反馈给网络来更新权重,实现减少后续迭代误差的目的。单次前向传播迭代输出的预测脉冲参数集A'i与训练集中的实际脉冲参数集Ai的误差则可以通过损失函数来计算。对于有N个样本的训练集,将参数集Ai的平均绝对误差值作为损失函数的函数值LMSE,即损失函数的计算式为:
模型在训练集和验证集上得到的损失值的迭代变化过程如图6所示,不管是训练集还是验证集,损失值在第25 个epoch 之后就几乎趋近于零,并未出现过拟合现象,因此也无须再添加drop out层,在训练集和验证集上得到的准确率都趋近于100%。

图6 模型训练过程中在训练集和验证集上的损失值的迭代图Fig.6 Iterative graph of the loss and accuracy for the training and validation sets during model training
2.2 实验验证
本文训练的深度学习模型在测试集和验证集都取得了较好的效果,为了进一步验证模型的泛化能力并对模型进行进一步评估,在测量过程中激发源采用的是上海科颐维2000A 型X 光管(额定管压50 kV、额定管流为0~1 mA),样品使用的是粉末铁矿样品(主要元素成为铁、锶、锡等),测量采用的探测器为AMPTEK 公司的高性能硅漂移探测器(FAST Silicon Drift Detector,FAST-SDD),其有效探测面积为25 mm2,探测器厚度为500 µm。取测量得到的堆积脉冲序列作为分析对象,验证模型对随机截取的脉冲序列幅度值的估计效果,如图7所示。
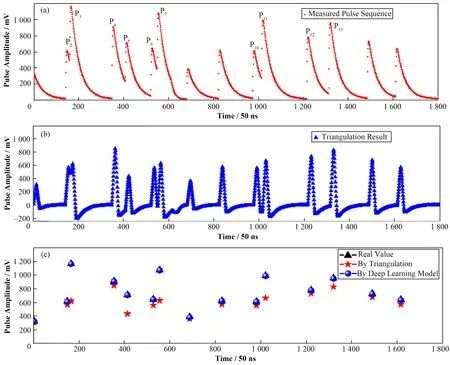
图7 (a) 实测脉冲序列图,(b) 三角成形结果,(c) 随机脉冲幅度估计值对照图(彩图见网络版)Fig.7 (a) Measured pulse sequence diagram, (b) Triangulation results for the pulse sequence, (c) Comparison chart of the estimated random pulse amplitude (color online)
图7(a)所示的随机脉冲序列中包含多个堆积脉冲,在采用三角成形对堆积脉冲序列进行脉冲分离及幅度估计时,堆积脉冲的分离效果较差,成形结果的幅度也存在较大的损失,如图7(b)所示。对该脉冲序列调用深度学习模型进行参数估计,将模型输出结果与传统的成形方法得到的幅度估计值进行对比,得到如图7(c)所示的随机脉冲幅度估计值对照图,实测脉冲幅度的真实值(黑色),采用三角成形得到的脉冲幅度(红色),采用深度学习模型获得的脉冲幅度(蓝色)。由图7(c)所示的随机脉冲幅度估计值对照图中可以看出,对于那些没有堆积或者堆积不太严重的脉冲,不管是传统的三角成形方式还是深度学习模型都能够比较准确地估计出脉冲幅度。为了量化幅值估计效果,用Δ表示绝对误差,δ表示相对误差,A表示脉冲幅度,从而得出三角成形以及多头注意力估计模型对堆积脉冲幅值估计的绝对误差和相对误差的计算公式分别如式(8)和式(9)所示:
实验采用的实测脉冲序列如图7(a)所示,该序列包含15个脉冲,其中堆积率为66%且堆积类型为双脉冲堆积。对图7(a)所示的15 个脉冲采用不同方式计算得到的幅度值进行对比分析,结果如表2所示。

表2 深度学习模型对堆积脉冲的估计值与真实值的对比(堆积率为66%)Table 2 Comparison of estimated and real values of overlapping pulses in the deep learning model
没有发生明显堆积的脉冲包括P1、P8、P9、P14以及P15,这些脉冲采用三角成形进行幅度计算得到的相对误差约在10%以内;而对于发生了堆积的脉冲,如图7中标注的P2和P3,类似的还有P4和P5、P6和P7、P10和P11以及P12和P13,对于这种发生了双脉冲堆积的堆积脉冲三角成形,通常第一个脉冲的幅度不会受到较大影响,而堆积上去的第二个脉冲则无法得出准确的成形结果,如P3、P5、P7、P11以及P13,这些脉冲采用三角成形进行幅度计算得到的相对误差成倍增长,最大相对误差高达47%,严重影响了脉冲幅度的估计。采用嵌入位置编码的多头注意力模型对幅值进行估计时,估计结果并不会受到脉冲堆积程度的影响,平均相对误差约为0.55%。
为了进一步验证本文训练的模型在相同样品不同堆积程度的脉冲序列以及不同样品相同堆积程度的脉冲序列中的参数估计效果,在实验环节中截取堆积率为10%、30%、60%和90%,堆积类型为双脉冲堆积的粉末岩石样品和粉末铁矿样品的实测脉冲序列进行分析,分析结果如表3 所示。从两种样品不同堆积程度得到的平均相对误差来看,深度学习模型对脉冲幅度估计的相对误差与样品类型并无直接关联,但与脉冲堆积程度却有一定的相关性,可以粗略估计随着堆积程度加深,模型对脉冲幅度估计的相对误差也会略有上升。表3 所示的8 组脉冲序列中,比较明显的一个“异常点”是第三组,该脉冲序列包含10个脉冲,其中双脉冲堆积的数量为6个,堆积程度为60%,按照理论分析深度学习模型对该序列进行幅度估计的相对误差应低于1%,但模型测试结果的相对误差高达3.42%。通过对堆积脉冲进一步分析发现,虽然该序列仅包含6个堆积脉冲,但其中两个脉冲发生了严重堆积,导致模型对堆积上去的第二个脉冲的幅度估计产生了较大误差。即便是这种极端情况下,本文训练的深度学习模型依然获得了远优于传统脉冲估计方法的性能,在两种样品、8组离线脉冲序列的幅度估计中得到的平均相对误差为0.89%。

表3 深度学习模型的参数估计效果对照Table 3 Comparison table of parameter estimation effects of the deep learning model
3 结语
本文提出了一种嵌入位置编码的多头注意力Transformer 神经网络模型,并将其应用于堆积脉冲的幅度估计。该模型是一个基于Encoder-Decoder框架的模型,采用多头注意力机制,以预定义的数学模型产生负指数脉冲序列以及三角成形后的幅值序列来制作数据集进行训练,模拟和实验结果验证了所提模型的脉冲幅度估计性能。采用相对误差作为堆积脉冲幅度估计精度的指标,得出在粉末铁矿样品和粉末岩石样品的8组离线脉冲序列中得到的平均相对误差为0.89%。结果表明:采用嵌入位置编码的多头注意力模型成功地从具有堆积效应的脉冲序列中估计出了脉冲幅度,且估计结果并不受脉冲堆积程度的影响。未来对深度学习模型在核辐射测量中的应用研究将旨在优化学习模型和数据集,此外,作者所在团队正在对HPGe和LaBr3(Ce)探测器应用类似方法进行研究,希望推广本模型在X 射线荧光光谱学中的应用。
作者贡献声明唐琳直接参与论文研究,负责神经网络模拟搭建并撰写论文;周爽负责实验测试结果分析;李勇负责模型训练;廖先莉负责资料的收集及整理;李跃鹏负责实验测试。
