基于GA-LM-BP神经网络的拖拉机可靠性预测
2023-09-20文昌俊邵明颖徐云飞
文昌俊,邵明颖,徐云飞,陈 哲
(1.湖北工业大学机械工程学院,湖北 武汉 430068;2.湖北省现代制造质量工程重点实验室,湖北 武汉 430068)
1 引言
随着农业机械的智能化和自动化发展,拖拉机可靠性逐步提高,但其使用环境复杂,在工作过程中会遇到各种问题,如高温、高湿、高阻力等,这些因素对拖拉机系统可靠性产生重大影响。因此,科学准确地预测拖拉机工作可靠度是现代农业耕作的必然要求。BP神经网络有较强的非线性映射能力和自主适应能力,在回归拟合、可靠性工程等领域得到了广泛应用[1-3]。冯瑞龙[4]等选取RBF和BP两种三层神经网络对低真空管道中运行列车的最大阻力进行预测研究,结果表明RBF神经网络模型能更好地预测列车的最大阻力。李鑫[5]等建立BP神经网络模型来预测刀具磨损和切削阻力,相较于经验公式得到了更优的结果,为刀具结构的优化及加工参数的选择提供了依据。张波[6]等利用DBSCAN聚类算法改进人工神经网络,搭建模糊神经网络模型,将最小二乘法与BP算法相结合对模型进行训练,来预测拖拉机耕作过程中受到的牵引阻力,此模型相较于支持向量机和随机森林有着更好的预测效果。温昌凯[7]等基于大数据的拖拉机田间工作平台构建了BP神经网络模型,对拖拉机田间作业质量进行预测评价。王森[8]等利用LM算法改进BP神经网络,建立LM-BP神经网络模型对弹丸的落地点进行预测,此模型相较于数值分析法能更好地预测到弹丸的降落位置。然而,上述文献中所运用的BP神经网络训练时间过长,网络预测值与真实值的误差较大,而LM算法属于局部优化算法,对初值的要求比较高,若神经网络初值选取不合理,会导致网络训练失败。
针对上述神经网络在预测过程中存在的缺陷,建立GA-LM-BP神经网络拖拉机可靠性预测模型,将遗传算法的全局收敛能力与LM算法的局部寻优能力相结合。首先将现场跟踪实验所获得的数据进行预处理,剔除由人员操作不当引起的无效故障时间,然后建立神经网络模型,进行仿真,最后与经典BP神经网络、LM-BP神经网络进行预测精度对比分析,从而验证遗传算法和LM算法优化BP神经网络的有效性及可行性。
2 BP神经网络模型
BP神经网络是一种按误差逆向传播算法训练的多层前馈神经网络[2]。信号正向传播,通过目标函数计算输出值;误差反向传播,根据模型输出值与期望值之间的误差反向逐层调整各连接权值和阈值。此模型具有优良的非线性逼近能力[9]。
BP神经网络神经元的净激活量为

(1)
神经元节点的输出
yi=f(neti)
(2)
若用X表示输入向量,用W表示权重向量
X=[x0,x1,x2,…,xn],W=[wi0,wi1,wi2,…win]T
(3)
则有
neti=XWyi=f(XW)
(4)
式中wij是神经元j与神经元i之间的连接权值,θ表示阈值,xj为上一个神经元j的输出信号。使用BP神经网络进行训练时,首先要初始化网络参数,样本输入必须是成对出现的,设第k组样本输入:Xk=(X1k,X2k,…,Xnk),则必须有相对应的输出:Yk=(Y1k,Y2k,…,Ymk)。将目标函数定义为
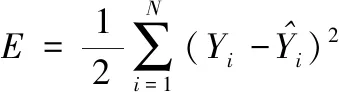
(5)
式中,N为训练样本集,Yi为网络输出的预测值,i为期望值,当二者的误差值达到设定精度时,训练结束,否则进入误差反向传播环节,逐层调整各连接权值

(6)
式中,η为学习速率,η>0。
由于BP神经网络拓扑结构的选择没有统一规则,权值根据局部改进的方向逐步调整,可能会忽视全局极小值点,陷入局部最优,并且,若初值选取不当,网络训练速度就会比较慢。因此,提出利用LM算法和遗传算法来优化经典BP神经网络,以提高网络模型的预测精度和收敛速度。
3 BP神经网络模型的优化设计
3.1 LM算法及遗传算法原理
LM(Levenberg-Marquardt)算法是一种基于标准数值优化技术的快速算法,其阻尼因子可以根据迭代结果动态调整,因此可以动态调整迭代的收敛方向。采用LM算法优化BP神经网络,既能提高网络的训练速度,又能保证其良好的训练精度[10]。下面对LM算法的基本原理进行简单阐述[11]。
网络的性能函数为
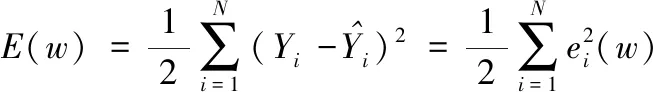
(7)
式中,ei(w)为误差,w为权值和阈值向量。假设第K次的权值和阈值向量为w(k),第k+1次的权值和阈值向量为w(k+1),权值和阈值的修正量如下
Δw=-[JT(w)J(w)+μI]-1JT(w)e(w)
(8)
式中,I为单位矩阵,μ为阻尼因子,J(w)为Jacobian矩阵,其计算方式如下

(9)
LM算法有着较高的精度和较快的收敛速度,但其对初始值尤为敏感,若初始值选择不当,会导致系统迭代误差较大。从本质上来讲,LM 算法属于局部优化算法,进行迭代时仅考虑目标函数的下降方向,并未兼顾目标函数的大小,这就导致LM算法只能收敛至初始值附近的极小点[12],因此神经网络初始值的选取尤为重要,故采用遗传算法迭代寻优后的计算结果作为LM算法的初始值。
遗传算法(GA,Genetic Algorithm)是使用生物学中的进化理论来模拟数据进化的一种智能算法[13,14]。首先选择恰当的适应度函数,对编码后种群个体的适应度值进行计算,然后选择并重复适应度最佳的个体进行基因突变操作,进而计算新种群个体的适应度,若满足初始设定条件,则输出,否则,迭代继续[15]。该算法能在全局范围内搜寻最优估计解,不易陷入局部极值。
3.2 基于GA-LM算法的神经网络模型建立
将收集到的拖拉机故障时间数据进行预处理,确定神经网络的拓扑结构。利用遗传算法全局搜索能力强的优点,将由遗传操作选择出的权值和阈值输入神经网络,作为网络训练的初始值,然后再利用LM算法局部寻优效果好的优点进行小范围的精确求解,从而提高神经网络的收敛速度、准确度和预测精度。
本文采用单隐含层的三层神经网络结构,将拖拉机的故障时间作为网络的输入,可靠度R(t)作为网络的输出。设置网络最大训练次数为10000,目标误差为0.001,学习速率为0.01,选择tansig函数作为输入层到隐含层的传递函数,purelin函数作为隐含层到输出层的传递函数。
网络训练精度、收敛速度与隐含层节点的数目有着重大关系。节点个数选择的常用经验公式为

(10)
式中,l、m、n分别为隐含层、输入层、输出层神经元的个数,c为1~10之间的常数。由式(10)多次调整隐含层节点的个数可知,当l=5时,网络性能最好,因此选择5个隐含层节点。根据上述神经网络拓扑结构建立基于遗传算法和LM算法的BP神经网络模型。GA-LM-BP神经网络拖拉机可靠性预测流程图如图1。

图1 GA-LM-BP神经网络拖拉机可靠性预测流程图
其步骤可总结如下:
1)产生初始化种群,设置变异概率Pm=0.1,交叉概率Pc=0.8,种群规模为M=30,最大遗传代数G=100。
2)个体适应度值计算,网络预测值Ri与期望值i之间的误差平方和被用作适应度函数。适应度值越低,优化效果越好。
3)选择和复制,使用轮盘赌算法优先选择和复制种群中适应度优良的个体。
4)交叉操作,根据交叉概率,交叉互换上一步骤所选个体的等位基因。
5)突变操作,设定合适的突变几率,随机地修改个体中的一个或多个基因值,用来形成全新个体,从而提高群体的生物多样性。
6)返回步骤2),再次计算个体的适应度值,直到适应度值达到最优或者迭代100次之后,进入下一步。
7)解码,经一系列遗传变异寻得了较优的权值和阈值,将其输入神经网络,作为LM算法的初始值。
8)计算神经网络的误差值,利用LM算法对权值和阈值进行微调,当误差达到所设定的精度时停止训练。
4 拖拉机可靠性预测
4.1 数据处理
根据现场跟踪实验,将收集到的23台某轮式拖拉机的117个故障时间数据t按从小到大的顺序排列为t(1)≤t(2)≤…≤t(a)≤…≤t(B),则该拖拉机的经验分布函数FB(t)为

(11)
式中,a为按照从小到大顺序排列好的故障时间顺序号,B为故障时间总数,B=117。
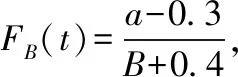
将排列好的117个故障时间数据分为19组,前18组每组6条数据,最后一组9条数据,每组的第6条数据作为测试样本,其余98条数据作为训练样本训练神经网络。为了预测的准确性,对数据进行归一化处理,将其转化为[0,1]之间

(12)
式中input(xa)为故障时间进行归一化之后,神经网络的第a个输入,ta为第a个故障发生的时间,tmax为所收集到的样本中故障时间最大值,tmin为故障时间最小值。根据式(11)和(12)对数据进行处理,处理后的部分数据见表1。

表1 处理后的部分数据
4.2 仿真与分析
首先由训练样本训练神经网络,然后输入测试样本进行拖拉机可靠性预测。使用遗传算法初步优化神经网络的权值和阈值,其适应度曲线先呈现下降的趋势,迭代18次之后收敛,而后逐渐趋向平稳状态,迭代过程如图2。
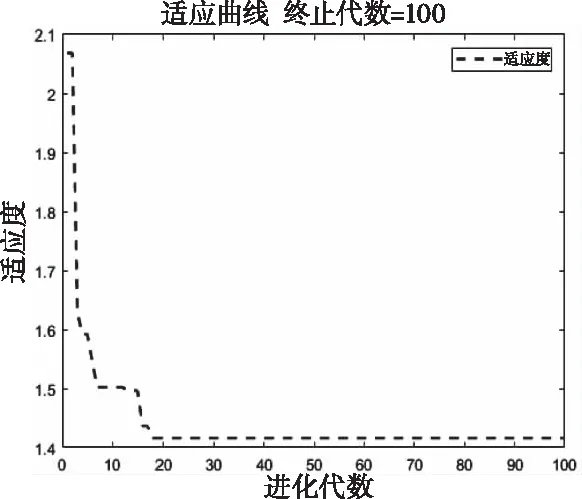
图2 遗传算法收敛曲线
将遗传算法迭代后的权值和阈值输入BP神经网络,再由LM算法进行局部优化,BP神经网络的网络训练性能曲线如图3。

图3 网络训练性能曲线
由图3可知,网络迭代6次后的训练精度为0.00038,达到并超过设定值0.001,结果表明,优化后的BP神经网络模型收敛速度较快,能很快达到所设定的误差精度。模型预测值与期望值之间的可靠度对比曲线如图4,网络训练的绝对误差如图5。
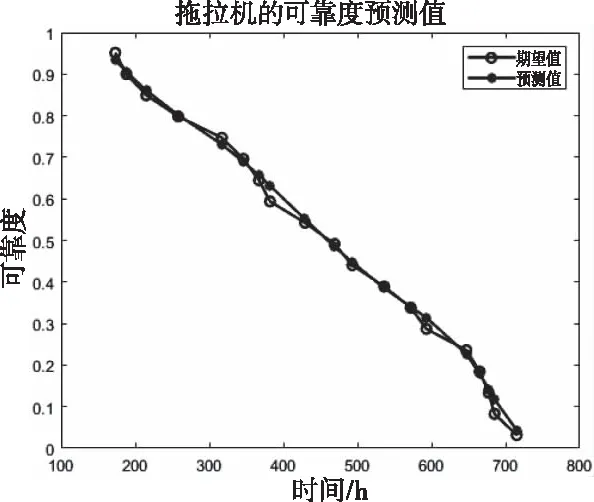
图4 GA-LM-BP神经网络模型可靠度预测值
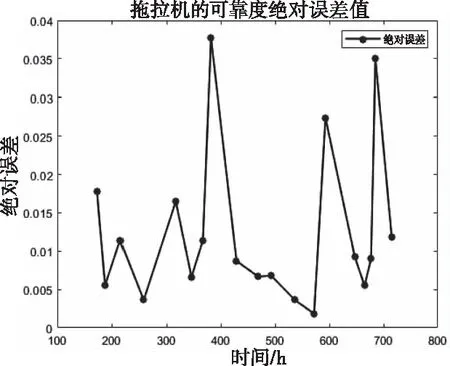
图5 GA-LM-BP神经网络模型绝对误差值
由图4和图5可知,网络预测的输出值与期望值之间的拟合效果较好,绝对误差波动幅度较低,最高不超过0.038。表明该模型有较高的预测精度和网络训练质量。
4.3 网络模型验证
为了验证采用遗传算法和LM算法优化BP神经网络,能提高网络性能,使其达到更好的预测效果,使用相同的训练样本、测试样本以及网络参数,建立经典BP神经网络模型和LM-BP神经网络模型。选取平均绝对误差MAE、均方根误差RMSE、相对均方根误差NRMSE作为神经网络模型的主要评价参数,定量分析三种模型预测拖拉机可靠度的准确性。评价指标的计算结果见表2。

表2 网络模型评价指标对比
对这三种模型的仿真结果进行对比。其预测值与期望值的可靠度拟合曲线如图6。预测值与期望值的绝对误差对比曲线如图7。

图6 三种网络模型可靠度预测值
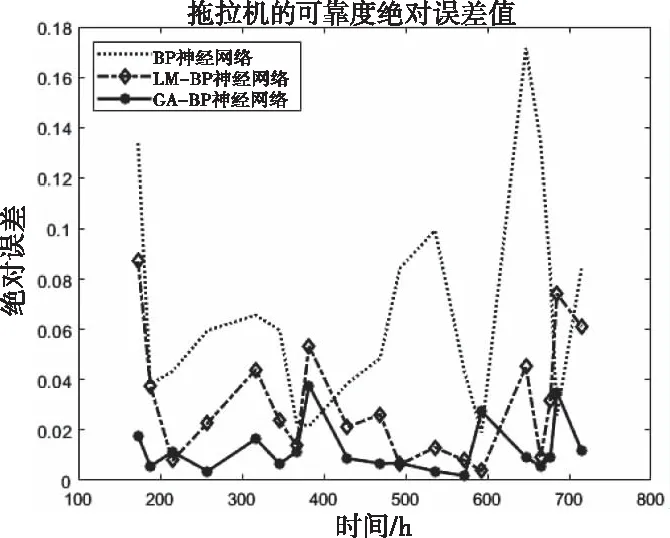
图7 三种网络模型绝对误差值
由表2、图6和图7可知,基于遗传算法和LM算法的BP神经网络模型可靠度预测值与期望值的拟合精度最高,误差值波动幅度最小,其平均绝对误差为1.24%,均方根误差为1.59%,相对均方根误差为2.82%;基于LM算法的BP神经网络模型拟合精度和误差波动幅度次之,其平均绝对误差为3.11%,均方根误差为6.91%,相对均方根误差为9.10%;经典BP神经网络模型拟合精度最差,误差波动幅度也最大,其平均绝对误差为6.71%,均方根误差为7.90%,相对均方根误差为13.97%。
在训练速度方面,基于遗传算法和LM算法的BP神经网络训练6次后,网络精度即可达到0.00038,超过所设定的网络精度;仅使用LM算法改进的BP神经网络训练17次网络精度可达到0.00096,同样超过设定的网络精度,只是训练速度和精度仍不及LM算法和GA算法共同优化后的神经网络;经典BP神经网络训练速度比较慢,训练了10000次,达到所设定的最大训练次数,此时模型的精度为0.00604,仍未达到设定的网络精度,由此可知GA-LM-BP神经网络模型的可靠度预测性能最好。
4.4 模型拟合精度检验
为了进一步验证模型的预测精度是否符合上述结论,采用皮尔逊相关系数法对三种网络模型进行解析。用相关系数ρ来表示网络预测值与期望值的相关程度,ρ越大表示二者相关性越强,拟合程度越高。公式如式(13)所示
(13)
计算结果表明,经典BP神经网络的相关系数为0.9275,LM-BP神经网络的相关系数为0.9841,GA-LM-BP神经网络的相关系数为0.9973,可知,GA-LM-BP神经网络模型的相关系数最大,进一步证明了LM算法与GA算法共同优化后的BP神经网络模型的拟合精度最高。
5 结论
本文使用遗传算法与LM算法优化BP神经网络,建立了GA-LM-BP神经网络模型对拖拉机进行可靠度预测,并与经典BP神经网络模型、LM-BP神经网络模型在迭代次数、执行时间及拟合精确度等方面进行了仿真结果对比,试验证明经两种算法共同优化后的BP神经网络有更好的预测精度和更快的收敛速度。此模型为实现拖拉机可靠性精准预测提供了新的方法,为拖拉机的使用及后续维修提供了重要参考依据,同时为其它类型农业机械产品的可靠性预测提供了思路。
