基于LDA主题模型的多数据库主题词挖掘算法
2023-09-20彭灿华韦晓敏
彭灿华,韦晓敏
(1. 桂林信息科技学院信息工程学院,广西 桂林 541004;2. 桂林电子科技大学计算机学院,广西 桂林 541004)
1 引言
在信息网络不断普及和互联网技术飞速发展的背景下,网络中数据不断增多,各大数据库中的数据量呈直线上升趋势,数据库中存在的数据具有无组织、随意性和口语化等特点,增加了数据检索的时间,用户在数据库中获取所需数据的难度较大[1],主题词挖掘是检索数据库数据的有效方法之一,研究数据库主题词挖掘算法具有重要意义。在此背景下,如何缩短用户在数据库中检索关键信息的时间和难度成为目前亟需解决的问题,针对上述问题,一些专家和学者提出了数据库主题词挖掘算法,通过挖掘数据库主题词获取对应的文档和数据[2]。
辛春花[3]等人计算了数据在数据库中的优先级,根据计算结果建立数据优先级模型,并将强化学习算法引入模型中,建立treap数据结构,采用generateRule程序对treap数据结构展开遍历,获取主题词,该算法的挖掘结果困惑度较高,存在挖掘精度低的问题。张孝飞[4]等人针对数据库中存在的短文本,制定文本扩充策略将其转变为长文本,在此基础上,采用语义词典扩展数据的语义概念,并根据数据在数据库中的结构特点为其分配权重,结合数据共现度提取主题词,该算法在文本扩充过程中容易引入噪声数据,对后续的主题词挖掘产生影响,增加了挖掘时间,存在挖掘效率低的问题。
为了解决上述方法中存在的问题,提出融合LDA主题模型的数据库主题词挖掘算法。
2 数据预处理
2.1 数据去噪
为了避免主题词挖掘过程中受到噪声数据的干扰,需要对数据库中存在的数据展开去噪处理。
在数据分解初期自适应噪声完备集合经验模态分解方法存在虚假模式,为了解决这个问题,对其改进,提出ICEEMDAN方法,对数据库数据展开去噪处理,该方法将特殊的噪声Rm[ξ(i)]加入数据分解后的第m层IMF中,期望数据库中的数据与第一次添加噪声之间具有相同的信噪比。数据在分解后期存在的噪声振幅相对较小,引入经验模态分解方法[5-6]处理剩余模式中存在的噪声,采用ICEEMDAN方法分解数据库数据的过程如下:
1)将白噪声R1[ξ(i)]加入原始数据u中,获得数据u(i):
u(i)=u+χ0R1[ξ(i)]
(1)
式中,χ0代表噪声R1[ξ(i)]对应的信噪比;ξ(i)代表加入数据的第i个白噪声。
2)采用ICEEMDAN方法分解后,获得数据的第1阶分量IMF1:

(2)
式中,r1代表数据的余项;Q(·)代表局部均值函数;K代表在数据中加入噪声的次数。
3)继续分解数据,获得第2阶分量IMF2;
4)同理,获得数据库中数据的第m层分量IMFm。
在数据分解的基础上,进一步对数据进行离散处理,曲波变换与小波变换相比具有方向性和多分辨率等优点[7-8],通过曲波变换可以降低Curvelet算法的速度冗余度,设vD(j,l,k)表示离散Curvelet变换过程中的离散曲波系数,可通过下式计算得到:
(3)

根据离散处理结果通过Wrap算法对数据库中存在的数据展开二维傅里叶变换[9-10],获得二维频域[n1,n2]。通过二维频域[n1,n2]和窗在尺度和角度(j,l)中获得离散曲波系数vD(j,l,k)。
结合曲波变换和ICEEMDAN方法对数据库中的数据u展开去噪处理:
u=c+σ
(4)
式中,σ代表随机噪声;c代表有效数据。
根据数据稀疏去噪特点,将数据库中存在的数据u作为可稀疏的观测数据,将随机噪声σ作为不可稀疏的数据,在数据去噪过程中,将数据中存在的噪声处理为重构数据与观测数据的残差,通过下式完成数据的去噪处理:
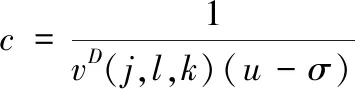
(5)
2.2 数据聚类处理
为了提高数据库主题词挖掘效率,对去噪后的数据展开聚类处理,具体过程如下:
1)设den(c)表示去噪后数据c在数据库中的局部密度,其计算公式如下:
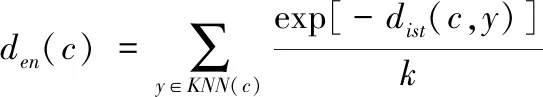
(6)
式中,KNN(c)代表数据c在数据库中的k近邻集合;dist(c,y)代表数据c与数据y之间的距离度量值,den(c)的值越大,表明数据周围存在的数据越密集。
设η(c)代表数据在数据库中的密度权重,其表达式为:
η(c)=den(c)ε(c)
(7)
式中,ε(c)代表数据c在数据库中与高密度数据之间的距离最小值,可通过下式计算得到:

(8)
2)结合残差分析方法[11-12]和线性回归方法根据数据的密度权重η(c)挑选初始聚类中心,建立聚类中心预选集Aset。
根据数据密度权重η(c)对集合Aset中存在的聚类中心展开降序排序,获得集合Aset_D。
3)在集合Aset_D中提取部分对象作为当前数据库的聚类中心。划分集合Aset_D中剩余的聚类中心,将其存储到高密度且距离最近数据所在的簇中。
结合戴维森堡丁指数和轮廓系数建立数据库聚类的聚类中心优化模型:

(9)
式中,Ui代表优化模型在迭代过程中获得的输出值;DCi代表聚类过程中数据聚类结果对应的戴维森堡丁指数;DBi代表轮廓系数,DCi、DBi的计算公式如下:

(10)

(11)
式中,Dn代表数据库的聚类数量;mean(Dt)代表聚类中心与数据j之间的平均距离;center(Dt)代表数据j在数据集的聚类中心;dist(·)代表距离函数;s(j)代表在相同簇中数据j与其它数据之间存在的平均距离;n(j)代表数据j与其它聚类中数据之间的最小距离。

3 数据库主题词挖掘算法设计
在数据预处理的基础上,结合图模型和LDA主题模型实现数据库的主题词挖掘。所提方法通过LDA主题模型获取主题中文档与词的分布,以此获取文档与词、词与词的主题相关性,LDA主题模型如图1所示。
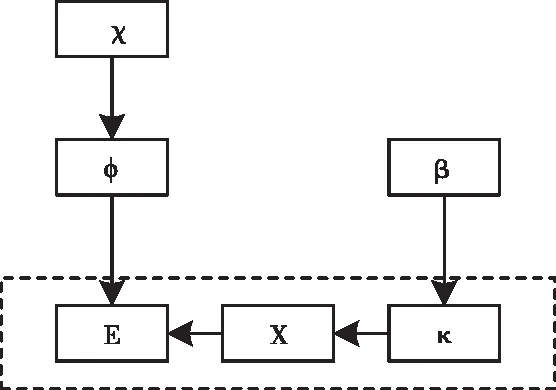
图1 LDA主题模型
在LDA模型中,数据库中的文档可通过词构成的向量得以描述,以此在数据库中挖掘文档的主题信息[13-14],通过下述过程建立LDA模型:针对数据库中存在的文档f,f与主题之间符合多项式分布,词汇表与主题中存在的词也符合多项式分布,上述分布中分别存在超参数χ、β对应的先验分布。随机抽取文档主题分布κ中存在的主题,之后抽取主题词分布φ中存在的词,多次迭代上述抽取过程,获得存在M个词的文章,建立LDA模型的概率模型a(κ,x,e|β,χ):

(12)
式中,a(·|·)代表概率分布函数。
在概率模型的基础上,获得主题中词对应的概率分布a(k|e):

(13)
式中,Vek代表主题k中词e出现的次数。
设a(k|f)表示主题k中文档f对应的概率分布,其表达式如下:

(14)
式中,Vfk代表主题k赋予文档f的数量。
引入余弦相似度根据上述概率分布计算结果,计算文章与词,词与词的相关性sim(e,f)、sim(e1,e2):
(15)
用带权无向网络图G=(V,E)描述数据库中存在的文档,图中的节点V即为文档中存在的词,连接节点之间的边E即为词之间的联系,得分D(bi)可通过下式计算得到:
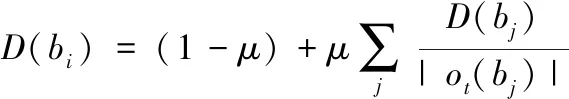
(16)
式中,μ代表阻尼因子;ot(bj)代表节点bi指向的节点构成的集合。
在数据库主题词挖掘过程中,建立的图节点为文档中存在的短语,上述过程计算得到的余弦相似度sim(e1,e2)即为词之间的相关性[15-16],连接两个短语的边对应的权重Qsim(a1,a2)即为余弦相似度sim(e1,e2)的最大值:
Qsim(a1,a2)=max[sim(ei,ej)]
(17)
拆分文档中存在的短语,获得若干个单词,在此基础上,计算文章与节点之间的相关性,通过下式获取节点对应的跳转概率Qsim(a,f):
Qsim(a,f)=max{sim(ei,f)}
(18)
通过上述过程,建立最终的带权无向图D(ai):
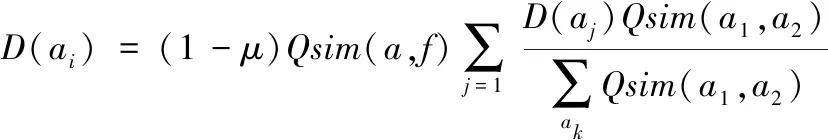
(19)
词语中存在的信息量与长度之间成正比,因此在数据库主题词挖掘过程中需要参考词语的长度。主题词的挖掘同样与词语在文档中出现的位置有关,通常情况下,关键词会出现在一篇文章的前半部分,如首段、摘要和标题等。因此根据词语的长度信息和在文章中的位置信息通过下式计算每个词语在文档中的最终得分LD(ai),选取得分最高的词语,作为主题词,完成数据库主题词挖掘:

(20)
式中,p(ai)代表词语在文档中出现的位置;l(ai)代表词语对应的长度。
4 实验与分析
为了验证融合LDA主题模型的数据库主题词挖掘算法的整体有效性,需要对其展开相关测试。本次测试所用的数据集1和数据集2分别由python爬虫和Google浏览器采集。
为提高数据库主题词的挖掘效率,需要对数据集中的数据展开聚类处理,通过聚类处理便于后期在各个类别中挖掘主题词,可缩短挖掘时间。现采用融合LDA主题模型的数据库主题词挖掘算法、文献[3]算法和文献[4]算法对数据集1和数据集2展开聚类处理,处理结果如图2所示。

图2 不同算法的数据聚类结果
由图2可知,所提算法可准确的完成数据集1和数据集2的聚类处理,而文献[3]算法和文献[4]算法的聚类结果存在误差,说明传统方法的数据聚类能力较差,不利于有效挖掘数据库主题词。
困惑度perplexity是评估数据挖掘结果的指标,perplexity越低,表明挖掘结果模糊程度越小,挖掘精度越高:
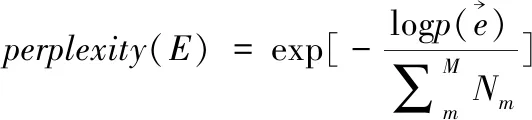
(21)

加速比speedup可以衡量算法挖掘主题词的效率,其计算公式如下:
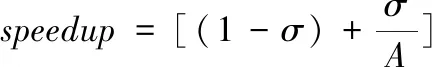
(22)
式中,A代表节点数量;σ代表在整个挖掘过程中算法训练时间所占的比例。
现采用困惑度perplexity和加速比speedup对所提算法、文献[3]算法和文献[4]算法的主题词挖掘性能展开测试,测试结果如表1所示。

表1 不同算法的挖掘性能
分析表1中的数据可知,在数据库主题词挖掘测试过程中,无论是数据集1还是数据集2所提算法均有较高的加速比,表明所提方法可在短时间内在数据库中完成主题词的挖掘,且所提算法的困惑度是三种算法中最低的,表明所提算法的挖掘结果模糊程度较小,具有较高的挖掘精度,因为所提算法在数据库中展开了去噪处理,消除了噪声对主题词挖掘过程产生的影响,提高了挖掘精度。
5 结束语
主题词挖掘可以在数据库海量数据中获取用户所需信息,针对目前数据库主题词挖掘算法存在的数据分类精度低、挖掘结果困惑度高和挖掘效率低的问题,提出一种融合LDA主体模型的数据库主题词挖掘算法,该算法首先对数据库中的数据展开了去噪处理,其次对数据分类,在不同数据类别中利用LDA主体模型实现主题词的挖掘,可有效降低挖掘结果的困惑度,缩短挖掘时间,与目前的数据库主题词挖掘算法相比,具有良好的挖掘性能,主要体现在挖掘效率和挖掘精度等方面,促进了数据库技术的发展。
